Apache Hadoop est une infrastructure logicielle qui traite et stocke les données volumineuses sur le cluster de matériel de base. Hadoop est basé sur le modèle MapReduce pour traiter d'énormes quantités de données de manière distribuée.
Ce didacticiel MapReduce a enrôlé plusieurs fonctionnalités de MapReduce. Après avoir lu ceci, vous comprendrez clairement pourquoi MapReduce est la meilleure solution pour traiter de grandes quantités de données.
Dans un premier temps, nous verrons une petite introduction au framework MapReduce. Ensuite, nous explorerons diverses fonctionnalités de MapReduce.
Commençons par l'introduction au framework MapReduce.
Introduction à MapReduce
MapReduce est un framework logiciel pour écrire des applications qui peuvent traiter d'énormes quantités de données sur les clusters de nœuds peu coûteux. Hadoop MapReduce est la partie traitement d'Apache Hadoop.
Il est également connu comme le cœur de Hadoop. C'est l'application de traitement de données préférée. Plusieurs acteurs du secteur du e-commerce tels qu'Amazon, Yahoo, Zuventus, etc. utilisent le framework MapReduce pour le traitement de données à grand volume.
Étudions maintenant les différentes fonctionnalités de Hadoop MapReduce.
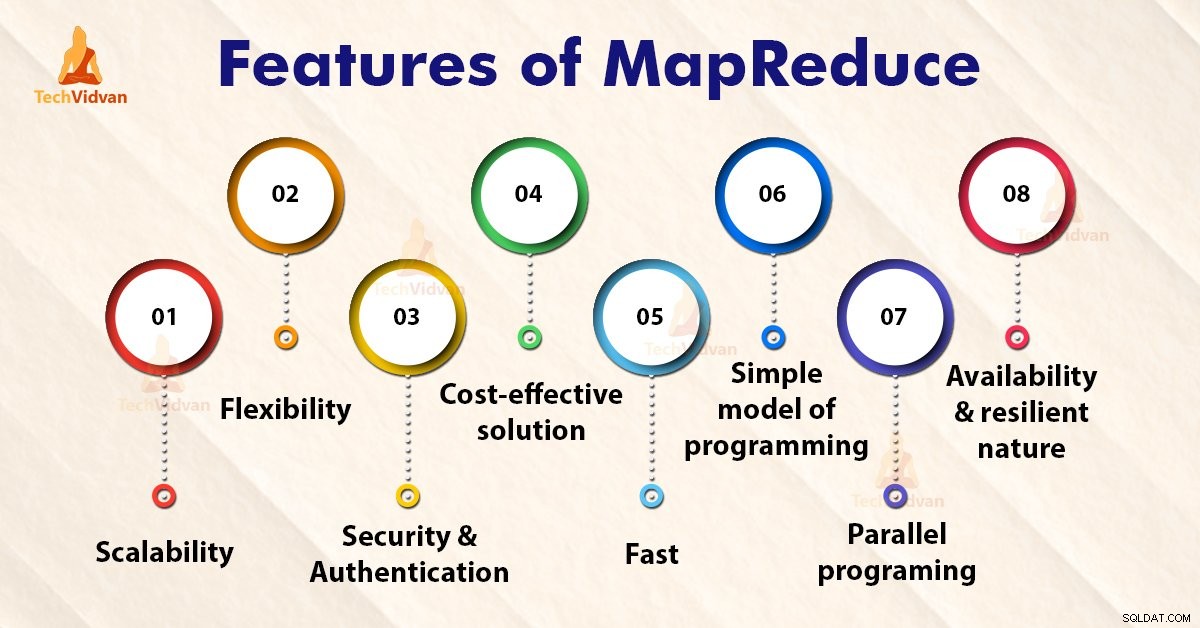
Fonctionnalités de MapReduce
1. Évolutivité
Apache Hadoop est un framework hautement évolutif. Cela est dû à sa capacité à stocker et à distribuer d'énormes données sur de nombreux serveurs. Tous ces serveurs étaient peu coûteux et peuvent fonctionner en parallèle. Nous pouvons facilement faire évoluer la puissance de stockage et de calcul en ajoutant des serveurs au cluster.
La programmation Hadoop MapReduce permet aux organisations d'exécuter des applications à partir de grands ensembles de nœuds qui pourraient impliquer l'utilisation de milliers de téraoctets de données.
La programmation Hadoop MapReduce permet aux entreprises d'exécuter des applications à partir de grands ensembles de nœuds. Cela peut utiliser des milliers de téraoctets de données.
2. Flexibilité
La programmation MapReduce permet aux entreprises d'accéder à de nouvelles sources de données. Il permet aux entreprises d'opérer sur différents types de données. Il permet aux entreprises d'accéder à des données structurées et non structurées et de tirer une valeur significative en obtenant des informations à partir de multiples sources de données.
En outre, le framework MapReduce prend également en charge plusieurs langues et données provenant de sources allant des e-mails aux médias sociaux en passant par le flux de clics.
Le MapReduce traite les données dans de simples paires clé-valeur prend ainsi en charge le type de données, y compris les métadonnées, les images et les fichiers volumineux. Par conséquent, MapReduce est flexible pour traiter les données plutôt que le SGBD traditionnel.
3. Sécurité et authentification
Le modèle de programmation MapReduce utilise la plate-forme de sécurité HBase et HDFS qui permet l'accès uniquement aux utilisateurs authentifiés pour opérer sur les données. Ainsi, il protège l'accès non autorisé aux données du système et améliore la sécurité du système.
4. Solution rentable
L'architecture évolutive d'Hadoop avec le cadre de programmation MapReduce permet le stockage et le traitement de grands ensembles de données de manière très abordable.
5. Rapide
Hadoop utilise une méthode de stockage distribué appelée Hadoop Distributed File System qui implémente essentiellement un système de mappage pour localiser les données dans un cluster.
Les outils utilisés pour le traitement des données, tels que la programmation MapReduce, sont généralement situés sur les mêmes serveurs qui permettent un traitement plus rapide des données.
Ainsi, même si nous traitons de gros volumes de données non structurées, Hadoop MapReduce ne prend que quelques minutes pour traiter des téraoctets de données. Il peut traiter des pétaoctets de données en une heure seulement.
6. Modèle simple de programmation
Parmi les différentes fonctionnalités de Hadoop MapReduce, l'une des caractéristiques les plus importantes est qu'il est basé sur un modèle de programmation simple. Fondamentalement, cela permet aux programmeurs de développer les programmes MapReduce qui peuvent gérer les tâches facilement et efficacement.
Les programmes MapReduce peuvent être écrits en Java, ce qui n'est pas très difficile à comprendre et est également largement utilisé. Ainsi, n'importe qui peut facilement apprendre et écrire des programmes MapReduce et répondre à ses besoins de traitement de données.
7. Programmation parallèle
L'un des aspects majeurs du fonctionnement de la programmation MapReduce est son traitement parallèle. Il divise les tâches d'une manière qui permet leur exécution en parallèle.
Le traitement parallèle permet à plusieurs processeurs d'exécuter ces tâches divisées. Ainsi, l'ensemble du programme est exécuté en moins de temps.
8. Disponibilité et nature résiliente
Chaque fois que les données sont envoyées à un nœud individuel, le même ensemble de données est transmis à d'autres nœuds d'un cluster. Ainsi, si un nœud particulier souffre d'une défaillance, il y a toujours d'autres copies présentes sur d'autres nœuds auxquelles il est toujours possible d'accéder en cas de besoin. Cela garantit une haute disponibilité des données.
L'une des principales fonctionnalités offertes par Apache Hadoop est sa tolérance aux pannes. Le framework Hadoop MapReduce a la capacité de reconnaître rapidement les défauts qui se produisent.
Il applique alors une solution de récupération rapide et automatique. Cette fonctionnalité en fait un élément qui change la donne dans le monde du traitement du Big Data.
Résumé
J'espère qu'après avoir lu cet article, vous avez bien compris les différentes fonctionnalités de Hadoop MapReduce. L'article a répertorié diverses fonctionnalités de MapReduce. Le framework MapReduce est un système de traitement évolutif, flexible, rentable et rapide.
Il offre sécurité, tolérance aux pannes et authentification. MapReduce est un modèle de programmation simple et propose une programmation parallèle.



