La mise en œuvre d'une recherche conviviale peut être délicate, mais elle peut également être effectuée de manière très efficace. Comment puis-je le savoir ? Il n'y a pas si longtemps, j'avais besoin d'implémenter un moteur de recherche sur une application mobile. L'application a été construite sur le framework Ionic et se connecterait à un backend CakePHP 2. L'idée était d'afficher les résultats au fur et à mesure que l'utilisateur tapait. Il y avait plusieurs options pour cela, mais toutes ne répondaient pas aux exigences de mon projet.
Pour illustrer ce qu'implique ce genre de tâche, imaginons la recherche de chansons et leurs relations possibles (comme des artistes, des albums, etc.).
Les enregistrements devraient être triés par pertinence, ce qui dépendrait si le mot recherché correspondait aux champs de l'enregistrement lui-même ou d'autres colonnes dans des tables associées. En outre, la recherche doit implémenter au moins une recherche de mot de base. (La racine est utilisée pour obtenir la forme racine d'un mot. "Stems", "stemmer", "stemming" et "stemmed" ont tous la même racine :"stem".)
L'approche présentée ici a été testée avec plusieurs centaines de milliers d'enregistrements et a pu récupérer des résultats utiles au fur et à mesure que l'utilisateur tapait.
Produits de recherche en texte intégral à envisager
Il existe plusieurs façons de mettre en œuvre ce type de recherche. Notre projet avait des contraintes en termes de temps et de ressources serveur, nous avons donc dû garder la solution aussi simple que possible. Quelques prétendants ont finalement émergé :
Elasticsearch
Elasticsearch fournit des recherches en texte intégral dans un service orienté document. Il est conçu pour gérer d'énormes quantités de charge de manière distribuée :il peut classer les résultats par pertinence, effectuer des agrégations et travailler avec la racine des mots et synonymes. Cet outil est destiné aux recherches en temps réel. Depuis leur site Web :
Elasticsearch construit des fonctionnalités distribuées sur Apache Lucene pour fournir les fonctionnalités de recherche en texte intégral les plus puissantes disponibles. Une API de requête puissante et conviviale pour les développeurs prend en charge la recherche multilingue, la géolocalisation, les suggestions contextuelles, la saisie semi-automatique et les extraits de résultats.
Elasticsearch peut fonctionner comme un service REST, répondant aux requêtes http, et il peut être configuré très rapidement. Cependant, le démarrage du moteur en tant que service nécessite que vous disposiez de certains privilèges d'accès au serveur. Et si votre fournisseur d'hébergement ne prend pas en charge Elasticsearch par défaut, vous devrez installer certains packages.
L'essentiel est que ce produit est une excellente option si vous voulez une solution de recherche solide comme le roc. (Remarque :Vous aurez peut-être besoin d'un VPS ou d'un serveur dédié car la configuration matérielle requise est assez exigeante.)
Sphinx
Comme Elasticsearch, Sphinx fournit également un produit de recherche en texte intégral très solide :Craigslist sert plus de 300 000 000 de requêtes par jour avec lui. Sphinx ne fournit pas d'interface RESTful native. Il est implémenté en C, avec une empreinte matérielle plus petite qu'Elasticsearch (qui est implémenté en Java et peut s'exécuter sur n'importe quel système d'exploitation avec une jvm). Vous aurez également besoin d'un accès root au serveur avec de la RAM/CPU dédiée pour exécuter Sphinx correctement.
Recherche en texte intégral MySQL
Historiquement, les recherches en texte intégral étaient prises en charge dans les moteurs MyISAM. Après la version 5.6, MySQL a également pris en charge les recherches en texte intégral dans les moteurs de stockage InnoDB. C'est une excellente nouvelle, car cela permet aux développeurs de bénéficier de l'intégrité référentielle d'InnoDB, de sa capacité à effectuer des transactions et des verrous au niveau des lignes.
Il existe essentiellement deux approches pour les recherches en texte intégral dans MySQL :le langage naturel et le mode booléen. (Une troisième option augmente la recherche en langage naturel avec une deuxième requête d'expansion.)
La principale différence entre les modes naturel et booléen est que le booléen autorise certains opérateurs dans le cadre de la recherche. Par exemple, les opérateurs booléens peuvent être utilisés si un mot est plus pertinent que d'autres dans la requête ou si un mot spécifique doit être présent dans les résultats, etc. Il convient de noter que dans les deux cas, les résultats peuvent être triés en fonction de la pertinence calculée par MySQL pendant la recherche.
Prendre les décisions
La solution la mieux adaptée à notre problème consistait à utiliser les recherches en texte intégral InnoDb en mode booléen. Pourquoi?
- Nous avons eu peu de temps pour mettre en œuvre la fonction de recherche.
- À ce stade, nous n'avions pas de données volumineuses à analyser ni une charge massive pour exiger quelque chose comme Elasticsearch ou Sphinx.
- Nous avons utilisé un hébergement mutualisé qui ne prend pas en charge Elasticsearch ou Sphinx et le matériel était assez limité à ce stade.
- Bien que nous voulions rechercher des mots dans notre fonction de recherche, ce n'était pas un facteur décisif :nous pouvions l'implémenter (dans les limites des contraintes) au moyen d'un simple codage PHP et d'une dénormalisation des données
- Les recherches en texte intégral en mode booléen peuvent rechercher des mots avec des caractères génériques (pour la racine du mot) et trier les résultats en fonction de leur pertinence.
Recherches en texte intégral en mode booléen
Comme mentionné précédemment, la recherche en langage naturel est l'approche la plus simple :recherchez simplement une phrase ou un mot dans les colonnes où vous avez défini un index de texte intégral et vous obtiendrez des résultats triés par pertinence.
Dans le modèle Vertabelo normalisé
Voyons comment une simple recherche fonctionnerait. Nous allons d'abord créer un exemple de tableau :
-- Créé par Vertabelo (https://vertabelo.com)-- Date de dernière modification :2016-04-25 15:01:22.153-- tables-- Table :artistsCREATE TABLE artists ( id int(11) NOT NULL AUTO_INCREMENT, name varchar(255) NOT NULL, bio text NOT NULL, CONSTRAINT artists_pk PRIMARY KEY (id)) ENGINE InnoDB;CREATE FULLTEXT INDEX artists_idx_1 ON artists (name);-- End of file.
En mode langage naturel
Vous pouvez insérer des exemples de données et commencer les tests. (Ce serait bien de l'ajouter à votre exemple de jeu de données.) Par exemple, nous allons essayer de rechercher Michael Jackson :
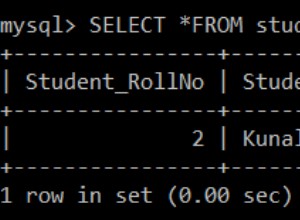
SELECT *FROM artistsWHERE MATCH (artists.name) AGAINST ('Michael Jackson' IN NATURAL LANGUAGE MODE) Cette requête trouvera les enregistrements qui correspondent aux termes de recherche et triera les enregistrements correspondants par pertinence ; plus la correspondance est bonne, plus elle est pertinente et plus le résultat apparaîtra haut dans la liste.
En mode booléen
Nous pouvons effectuer la même recherche en mode booléen. Si nous n'appliquons aucun opérateur à notre requête, la seule différence sera que les résultats ne le seront pas triés par pertinence :
SELECT *FROM artistsWHERE MATCH (artists.name) AGAINST ('Michael Jackson' IN BOOLEAN MODE) L'opérateur générique en mode booléen
Puisque nous voulons rechercher des mots radicaux et partiels, nous aurons besoin de l'opérateur générique (*). Cet opérateur peut être utilisé dans les recherches en mode booléen, c'est pourquoi nous avons choisi ce mode.
Alors, libérons le pouvoir de la recherche booléenne et essayons de rechercher une partie du nom de l'artiste. Nous utiliserons l'opérateur générique pour faire correspondre tout artiste dont le nom commence par "Mich" :
SELECT *FROM artistsWHERE MATCH (name) AGAINST ('Mich*' IN BOOLEAN MODE) Tri par pertinence en mode booléen
Voyons maintenant la pertinence calculée pour la recherche. Cela nous aidera à comprendre le tri que nous ferons plus tard avec Cake :
SELECT *, MATCH (name) AGAINST ('mich*' IN BOOLEAN MODE) AS rankFROM artistsWHERE MATCH (name) AGAINST ('mich*' IN BOOLEAN MODE)ORDER BY rank DESC Cette requête récupère les correspondances de recherche et la valeur de pertinence calculée par MySQL pour chaque enregistrement. L'optimiseur de moteur détectera que nous sélectionnons la pertinence, il ne prendra donc pas la peine de recalculer le classement.
Recherche de mot dans la recherche de texte intégral
Lorsque nous incorporons la racine d'un mot dans une recherche, la recherche devient plus conviviale. Même si le résultat n'est pas un mot en soi, les algorithmes essaient de générer la même racine pour les mots dérivés. Par exemple, le radical "argu" n'est pas un mot anglais, mais il peut être utilisé comme radical pour "argue", "argued", "argues", "arguing","Argus" et d'autres mots.
La racine améliore les résultats, car l'utilisateur peut entrer un mot qui n'a pas de correspondance exacte, mais sa « racine » en a. Bien que le stemmer PHP ou le stemmer Python de Snowball puisse être une option (si vous avez un accès root SSH à votre serveur), nous utiliserons la classe PorterStemmer.php.
Cette classe implémente l'algorithme proposé par Martin Porter pour radicaliser les mots en anglais. Comme indiqué par l'auteur sur son site Web, son utilisation est gratuite à toutes fins. Déposez simplement le fichier dans votre répertoire Vendors dans CakePHP, incluez la bibliothèque dans votre modèle et appelez la méthode statique pour radicaliser un mot :
//inclure la bibliothèque (devrait s'appeler PorterStemmer.php) dans le dossier VendorsApp de CakePHP ::import('Vendor', 'PorterStemmer'); //stem un mot (les mots doivent être radicalisés un par un)echo PorterStemmer::Stem(‘stemming’); //la sortie sera 'stem' Notre objectif est de rendre la recherche rapide et efficace et de pouvoir trier les résultats en fonction de leur pertinence en texte intégral. Pour ce faire, nous aurons besoin d'employer la racine des mots de deux manières :
- Les mots saisis par l'utilisateur
- Données relatives aux chansons (que nous stockerons dans des colonnes et trierons les résultats en fonction de leur pertinence)
Le premier type de radical de mot peut être réalisé comme ceci :
App ::import('Vendor', 'PorterStemmer');$search =trim(preg_replace('/[^A-Za-z0-9_\s]/', '', $search));/ /supprimer les caractères indésirables$words =exploser(" ", trim($search));$stemmedSearch ="";$unstemmedSearch ="";foreach ($words as $word) { $stemmedSearch .=PorterStemmer::Stem($ mot) . "*" ;//nous ajoutons le caractère générique après chaque mot $unstemmedSearch =$word . "* " ;//pour rechercher la colonne de l'artiste qui n'est pas stemmed}$stemmedSearch =trim($stemmedSearch);$unstemmedSearch =trim($unstemmedSearch);if ($stemmedSearch =="*" || $unstemmedSearch==" *") { // sinon mySql se plaindra, car vous ne pouvez pas utiliser le joker seul $stemmedSearch =""; $unstemmedSearch ="";} Nous avons créé deux chaînes :une pour rechercher le nom de l'artiste (sans radical) et une pour rechercher dans les autres colonnes avec radical. Cela nous aidera plus tard à construire notre "contre" partie de la requête de texte intégral. Voyons maintenant comment extraire et trier les données de la chanson.
Dénormalisation des données de morceau
Nos critères de tri seront basés sur la correspondance de l'artiste de la chanson (sans stemming) en premier. Vient ensuite le nom de la chanson, l'album et les catégories associées. La radicalisation sera utilisée sur tous les critères de recherche secondaires.
Pour illustrer cela, supposons que je recherche "nirvana" et qu'il y ait une chanson intitulée "Nirvana Games" de "XYZ", et une autre chanson intitulée "Polly" de l'artiste "Nirvana". Les résultats doivent indiquer "Polly" en premier, car la correspondance sur le nom de l'artiste est plus importante qu'une correspondance sur le nom de la chanson (basé sur mes critères).
Pour ce faire, j'ai ajouté 4 champs dans le songs tableau, un pour chacun des critères de recherche/tri que nous voulons :
ALTER TABLE `songs` ADD `denorm_artist` VARCHAR(255) NOT NULL AFTER`trackname`, ADD `denorm_trackname` VARCHAR(500) NOT NULL AFTER`denorm_artist`, ADD `denorm_album` VARCHAR(255) NOT NULL AFTER` denorm_trackname`, AJOUTER `denorm_categories` VARCHAR(500) NOT NULL AFTER`denorm_album`, AJOUTER TEXTE COMPLET (`denorm_artist`), AJOUTER TEXTE COMPLET(`denorm_trackname`), AJOUTER TEXTE COMPLET (`denorm_album`), AJOUTER TEXTE COMPLET(`denorm_categories`);
Notre modèle de base de données complet ressemblerait à ceci :
Chaque fois que vous enregistrez une chanson en utilisant add/edit dans CakePHP, il vous suffit de stocker le nom de l'artiste dans la colonne denorm_artist sans l'endiguer. Ensuite, ajoutez le nom de la piste radicale dans le denorm_trackname champ (similaire à ce que nous avons fait dans le texte recherché) et enregistrez le nom de l'album radical dans le denorm_album colonne. Enfin, stockez la catégorie radicale définie pour la chanson dans le denorm_categories champ, en concaténant les mots et en ajoutant un espace entre chaque nom de catégorie radical.
Recherche en texte intégral et tri par pertinence dans CakePHP
En continuant avec l'exemple de la recherche de "Nirvana", voyons ce qu'une requête similaire à celle-ci peut accomplir :
SELECT trackname, MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank1, MATCH(denorm_trackname) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank2, MATCH(denorm_album) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank3, MATCH(denorm_categories) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank4 FROM chansons WHERE MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR MATCH(denorm_trackname) AGAINST ('Nirvana* ' EN MODE BOOLÉEN) OU MATCH(denorm_album) CONTRE ('Nirvana*' EN MODE BOOLÉEN) OU MATCH(denorm_categories) CONTRE ('Nirvana*' EN MODE BOOLÉEN) ORDER BY rank1 DESC, rank2 DESC, rank3 DESC, rank4 DESC Nous obtiendrions le résultat suivant :
| nom de la piste | rang1 | rang2 | rang3 | rang4 |
| Polly | 0.0906190574169159 | 0 | 0 | 0 |
| jeux de nirvana | 0 | 0.0906190574169159 | 0 | 0 |
Pour ce faire dans CakePHP, le trouver La méthode doit être appelée à l'aide d'une combinaison de paramètres "champs", "conditions" et "ordre". Continuer avec l'ancien exemple de code PHP :
//dans le fichier modèle Song.php $fields =array( "Song.trackname", "MATCH(Song.denorm_artist) AGAINST ({$unstemmedSearch} IN BOOLEAN MODE) as `rank1`", "MATCH(Song. denorm_trackname) CONTRE ({$stemmedSearch} EN MODE BOOLÉEN) comme `rank2`", "MATCH(Song.denorm_album) CONTRE ({$stemmedSearch} EN MODE BOOLÉEN) comme `rank3`", "MATCH(Song.denorm_categories) CONTRE ( {$stemmedSearch} IN BOOLEAN MODE) as `rank4`" );$order ="`rank1` DESC,`rank2` DESC,`rank3` DESC,`rank4` DESC,Song.trackname ASC";$conditions =array( "OR" => array( "MATCH(Song.denorm_artist) CONTRE ({$unstemmedSearch} EN MODE BOOLÉEN)", "MATCH(Song.denorm_trackname) CONTRE ({$stemmedSearch} EN MODE BOOLÉEN)", "MATCH(Song. denorm_album) CONTRE ({$stemmedSearch} EN MODE BOOLÉEN)", "MATCH(Song.denorm_categories) CONTRE ({$stemmedSearch} EN MODE BOOLÉEN)" ) );$results =$this->find (‘all’,array(‘conditions’=>$conditions,’fields’=>$fields,’order’=>$order); $résultats sera le tableau des chansons triées avec les critères que nous avons définis précédemment.
Cette solution peut être utilisée pour générer des recherches significatives pour l'utilisateur - sans demander trop de temps aux développeurs ni ajouter de complexité majeure au code.
Améliorer les recherches CakePHP
Il convient de mentionner que « pimenter » les colonnes dénormalisées avec plus de données peut conduire à de meilleurs résultats.
Par "épicer", je veux dire que vous pourriez inclure, dans les colonnes dénormalisées, plus de données provenant de colonnes supplémentaires que vous jugez utiles dans le but de rendre les résultats plus pertinents, par exemple si vous saviez que le pays d'un artiste pouvait figurer dans les termes de recherche, vous pourrait ajouter le pays avec le nom de l'artiste dans le denorm_artist colonne. Cela améliorerait la qualité des résultats de recherche.
D'après mon expérience (en fonction des données réelles que vous utilisez et des colonnes que vous dénormalisez), les résultats les plus élevés ont tendance à être très précis. C'est idéal pour les applications mobiles, car faire défiler une longue liste peut être frustrant pour l'utilisateur.
Enfin, si vous avez besoin d'obtenir plus de données des tables auxquelles la chanson se rapporte, vous pouvez toujours faire une jointure et obtenir l'artiste, les catégories, les albums, les commentaires de la chanson, etc. Si vous utilisez le filtre de comportement confinable de CakePHP, je ferais suggérons d'ajouter le plugin EagerLoader pour accomplir les jointures efficacement.
Si vous avez votre propre approche pour mettre en œuvre la recherche en texte intégral, veuillez la partager dans les commentaires ci-dessous. Nous pouvons tous apprendre de l'expérience des autres.