Tout architecte de base de données qui conçoit une base de données MySQL est confronté au problème de la sélection du moteur de stockage approprié. Généralement, une application n'utilise qu'un seul moteur :MyISAM ou InnoDB . Mais essayons d'être un peu plus flexibles et imaginons comment différents moteurs de stockage peuvent être utilisés.
Le modèle de données initial
Pour commencer, construisons un modèle de données simplifié pour un système CRM (gestion de la relation client) que nous utiliserons pour illustrer ce point. La conception couvrira les principales fonctions CRM :données de vente, définitions de produits et informations pour l'analyse. Il ne contiendra pas les détails généralement utilisés dans les systèmes CRM.
Comme vous pouvez le voir, ce modèle de données contient des tables qui stockent des informations transactionnelles appelées sale et sale_item . Lorsqu'un client achète quelque chose, l'application crée une nouvelle ligne dans le sale table. Chaque produit acheté sera reflété dans le sale_item table. Une table associée, sale_status , sert à stocker les statuts possibles (par exemple, en attente, terminé, etc.).
Le product table stocke des informations sur les marchandises. Il définit chaque produit et ses descripteurs de base. Dans un diagramme plus détaillé, j'ajouterais plus de tableaux pour gérer les spécifications et la catégorisation des produits. Mais pour nos besoins actuels, ce n'est pas nécessaire.
La table des clients conserve les données sur les clients. Ceci fait partie intégrante de tout système CRM et suit généralement l'activité individuelle de tous les utilisateurs. De toute évidence, il contient souvent des informations très détaillées. Mais comme je l'ai noté, nous n'avons pas besoin de ces détails pour le moment.
Le log table stocke ce que chaque client a fait dans l'application. Et le report_sales table est conçue pour l'utilisation de l'analyse de données.
Ensuite, je décrirai les moteurs de stockage MySQL qui pourraient éventuellement être utilisés dans cette conception. Et plus tard, nous verrons quel moteur convient à chaque type de table.
Un aperçu des moteurs de stockage MySQL
Un moteur de stockage est un module logiciel utilisé par MySQL pour créer, lire ou mettre à jour des données à partir d'une base de données. Il n'est pas recommandé de choisir un moteur au hasard, mais de nombreux développeurs sont heureux d'utiliser MyISAM ou InnoDB, bien que d'autres options soient également disponibles. Chaque moteur a ses propres avantages et inconvénients, et le bon choix de moteur dépend de plusieurs facteurs. Jetons un coup d'œil aux moteurs les plus populaires.
- MonISAM a une longue histoire avec MySQL. C'était le moteur par défaut des bases de données MySQL avant la version 5.5. MyISAM ne prend pas en charge les transactions et n'a qu'un verrouillage au niveau de la table. Il est principalement utilisé pour les applications à lecture intensive.
- InnoDB est un moteur de stockage général qui allie haute fiabilité et bonnes performances. Il prend en charge les transactions, le verrouillage au niveau des lignes, la récupération sur incident et le contrôle de la concurrence multi-versions. En outre, il fournit une contrainte d'intégrité référentielle de clé étrangère.
- La mémoire moteur stocke toutes les données dans la RAM. Il peut être utilisé pour stocker des références de recherche.
- Un autre moteur, CSV , conserve les données dans des fichiers texte avec des valeurs séparées par des virgules. Ce format est principalement utilisé pour l'intégration avec d'autres systèmes.
- Fusionner est un bon choix pour les systèmes de reporting, comme dans l'entreposage de données. Il permet le regroupement logique d'un ensemble de tables MyISAM identiques, qui peuvent également être référencées comme un seul objet.
- Archive est optimisé pour l'insertion à grande vitesse. Il stocke les informations dans des tables compactes et non indexées et ne prend pas en charge les transactions. Le moteur de stockage Archive est idéal pour conserver de grandes quantités de données historiques ou archivées rarement référencées.
- La fédération offre la possibilité de séparer les serveurs MySQL ou de créer une base de données logique à partir de plusieurs serveurs physiques. Aucune donnée n'est stockée sur les tables locales et les requêtes sont automatiquement exécutées sur les tables distantes (fédérées).
- Le trou noir moteur agit comme un "trou noir" qui accepte les données mais ne les stocke pas. Toutes les sélections renvoient un jeu de données vide.
- Le moteur Exemple est utilisé pour montrer comment développer de nouveaux moteurs de stockage.
Il ne s'agit pas d'une liste complète des moteurs de stockage. MySQL 5.x prend en charge neuf d'entre eux dès la sortie de la boîte, ainsi que des dizaines d'autres développés par la communauté MySQL. Vous trouverez plus de détails sur les moteurs de stockage dans la documentation officielle de MySQL.
Mettre à jour la conception du modèle de données
Regardez à nouveau notre modèle de données. Évidemment, différentes tables seront utilisées de différentes manières. La sale table doit prendre en charge les transactions. D'autre part, le log et report_sales les tables ne nécessitent pas cette fonctionnalité. La mission principale du log table stocke les données avec une efficacité maximale. La récupération rapide est la principale exigence pour le report_sales table.
Gardons à l'esprit les points ci-dessus et modifions notre schéma de base de données. Dans Vertabelo, vous pouvez définir le "Moteur de stockage" dans les Propriétés de la table panneau. Veuillez regarder les images ci-dessous.

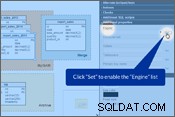
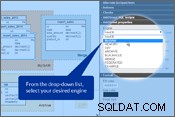
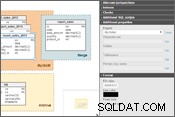
Configuration du moteur de stockage
Voyons donc la mise à jour de la conception de la base de données.
J'ai spécifié des moteurs de stockage pour les tables existantes et réorganisé le report_sales table. Comme vous pouvez le voir, les tableaux sont divisés en trois groupes :
- Tables de transactions, qui sont utilisées avec l'application principale
- Tableaux de rapport pour l'analyse BI
- Tableau de journal pour stocker toutes les activités des utilisateurs
Parlons de chacun d'eux séparément.
Tableaux des transactions
Ces tableaux contiennent des données saisies par les utilisateurs lors des opérations de routine quotidiennes. Dans notre cas, il y aurait des informations sur la vente, telles que :
- quel employé a réalisé la vente
- qui a acheté le produit
- ce qui a été vendu
- combien ça coûte
Dans la majorité des cas, InnoDB est la meilleure solution pour les tables de transactions. Ce moteur de stockage prend en charge le verrouillage des lignes et certains utilisateurs peuvent travailler ensemble. De même, InnoDB permet l'utilisation de transactions et de clés étrangères. Mais, comme vous le savez, ces avantages ne sont pas gratuits; le moteur peut exécuter des instructions de sélection plus lentement que MyISAM et enregistrer les données avec moins d'efficacité que Archive.
Tous les moteurs décrits ci-dessus ont des protections en place, de sorte que les développeurs n'ont pas à écrire des fonctions de restauration complexes pour chaque opération. Dans une application de vente typique, la cohérence des données est plus importante que les éventuels problèmes de performances.
Tableaux de rapport
Dans le nouveau design, j'ai divisé une table en deux tables plus petites. Cela permet d'économiser des efforts lorsque vient le temps de gérer les données et d'effectuer la maintenance des tables et des index. Cela nous permet également de créer la table MERGE sale_report pour combiner d'autres tableaux de rapport. Par conséquent, l'outil de BI récupère toujours les données d'une immense table (à des fins d'analyse), mais nous avons l'avantage de travailler avec des tables plus petites.
Le Report_sale_{year} les tables sont des tables MyISAM. Ce moteur de stockage ne prend pas en charge les transactions et ne peut que verrouiller la table dans son ensemble. Parce que MyISAM ne se soucie pas de ces éléments complexes, il effectue des opérations de manipulation de données à grande vitesse. En raison de sa structure de fichiers, ce moteur de stockage lit les données plus rapidement que le plus populaire InnoDB.
Le tableau des journaux
Le moteur de stockage Archive est un bon choix pour stocker les données de journal. Il peut insérer des lignes et compresser rapidement les données stockées. La conservation des informations sur les activités des utilisateurs présente de grands avantages. Cependant, Archive a certaines restrictions. Il ne prend pas en charge les opérations de mise à jour et récupère les données lentement. Mais dans une table de log, les avantages décrits sont plus importants que les inconvénients.
Intégration des moteurs de stockage
Chaque système doit être intégré à la vie extérieure. Pour les applications, il peut s'agir d'utilisateurs qui renseignent les tables de référence et de transaction. Il peut s'agir de services et d'intégration via REST, SOAP, WCF ou quelque chose comme ça. Et enfin, il peut s'agir d'une intégration de base de données.
MySQL et Oracle ont développé deux moteurs de stockage très utiles :Federated et CSV . Le premier, Fédéré , doit être utilisé pour charger des données à partir d'une base de données MySQL externe. Le deuxième moteur de stockage, CSV , permet aux bases de données d'enregistrer des enregistrements au format CSV et de lire des fichiers séparés par des virgules à la volée, sans aucun effort supplémentaire.
Comme vous pouvez le constater, l'utilisation de différents moteurs de stockage à des fins différentes donne à votre base de données une plus grande flexibilité. Si un architecte de base de données prend sa décision après avoir examiné tous les avantages et inconvénients, le résultat peut être vraiment impressionnant.
Avez-vous de l'expérience dans l'utilisation de différents moteurs de stockage dans la conception de bases de données ? J'aimerais voir vos conseils et suggestions. Veuillez les partager dans la section des commentaires.