Les bases de données doivent fonctionner de manière optimale, mais ce n'est pas une tâche si facile. La base de données INFORMATION SCHEMA peut être votre arme secrète dans la guerre de l'optimisation des bases de données.
Nous sommes habitués à créer des bases de données à l'aide d'une interface graphique ou d'une série de commandes SQL. C'est très bien, mais c'est aussi bien de comprendre un peu ce qui se passe en arrière-plan. Ceci est important pour la création, la maintenance et l'optimisation d'une base de données, et c'est aussi un bon moyen de suivre les changements qui se produisent "en coulisses".
Dans cet article, nous examinerons une poignée de requêtes SQL qui peuvent vous aider à scruter le fonctionnement d'une base de données MySQL.
La base de données INFORMATION_SCHEMA
Nous avons déjà discuté du INFORMATION_SCHEMA base de données dans cet article. Si vous ne l'avez pas déjà lu, je vous suggérerais certainement de le faire avant de continuer.
Si vous avez besoin d'un rappel sur le INFORMATION_SCHEMA base de données - ou si vous décidez de ne pas lire le premier article - voici quelques faits de base que vous devez savoir :
- Le
INFORMATION_SCHEMALa base de données fait partie de la norme ANSI. Nous travaillerons avec MySQL, mais d'autres RDBMS ont leurs variantes. Vous pouvez trouver des versions pour la base de données H2, HSQLDB, MariaDB, Microsoft SQL Server et PostgreSQL. - Il s'agit de la base de données qui assure le suivi de toutes les autres bases de données sur le serveur ; nous trouverons ici les descriptions de tous les objets.
- Comme toute autre base de données, le
INFORMATION_SCHEMAla base de données contient un certain nombre de tables connexes et d'informations sur différents objets. - Vous pouvez interroger cette base de données à l'aide de SQL et utiliser les résultats pour :
- Surveiller l'état et les performances de la base de données, et
- Générez automatiquement du code en fonction des résultats de la requête.
Passons maintenant à l'interrogation de la base de données INFORMATION_SCHEMA. Nous allons commencer par examiner le modèle de données que nous allons utiliser.
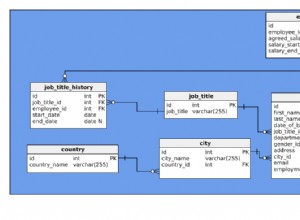
Le modèle de données
Le modèle que nous utiliserons dans cet article est illustré ci-dessous.
Il s'agit d'un modèle simplifié qui nous permet de stocker des informations sur les cours, les instructeurs, les étudiants et d'autres détails connexes. Passons brièvement en revue les tableaux.
Nous stockerons la liste des instructeurs dans le lecturer table. Pour chaque conférencier, nous enregistrerons un first_name et un last_name .
La class tableau répertorie toutes les classes que nous avons dans notre école. Pour chaque enregistrement de cette table, nous stockerons le class_name , l'identifiant de l'enseignant, une start_date planifiée et end_date , et tout élément class_details supplémentaire . Par souci de simplicité, je supposerai que nous n'avons qu'un seul enseignant par classe.
Les cours sont généralement organisés en une série de conférences. Ils nécessitent généralement un ou plusieurs examens. Nous stockerons des listes de cours et d'examens associés dans le lecture et exam les tables. Les deux auront l'ID de la classe associée et le start_time attendu et end_time .
Maintenant, nous avons besoin d'étudiants pour nos cours. Une liste de tous les étudiants est stockée dans le student table. Encore une fois, nous ne stockerons que le first_name et le last_name de chaque élève.
La dernière chose que nous devons faire est de suivre les activités des élèves. Nous conserverons une liste de chaque classe à laquelle un étudiant s'est inscrit, le registre de présence de l'étudiant et ses résultats d'examen. Chacune des trois tables restantes – on_class , on_lecture et on_exam – aura une référence à l'étudiant et une référence à la table appropriée. Seul le on_exam table aura une valeur supplémentaire :grade.
Oui, ce modèle est très simple. Nous pourrions ajouter de nombreux autres détails sur les étudiants, les professeurs et les classes. Nous pourrions stocker des valeurs historiques lorsque des enregistrements sont mis à jour ou supprimés. Pourtant, ce modèle sera suffisant pour les besoins de cet article.
Création d'une base de données
Nous sommes prêts à créer une base de données sur notre serveur local et à examiner ce qui s'y passe. Nous allons exporter le modèle (dans Vertabelo) en utilisant le "Generate SQL script " bouton.
Ensuite, nous allons créer une base de données sur l'instance MySQL Server. J'ai appelé ma base de données "classes_and_students ”.
La prochaine chose que nous devons faire est d'exécuter un script SQL généré précédemment.
Nous avons maintenant la base de données avec tous ses objets (tables, clés primaires et étrangères, clés alternatives).
Taille de la base de données
Après l'exécution du script, les données sur les "classes and students ” la base de données est stockée dans le INFORMATION_SCHEMA base de données. Ces données se trouvent dans de nombreuses tables différentes. Je ne les énumérerai pas tous ici; nous l'avons fait dans l'article précédent.
Voyons comment utiliser le SQL standard sur cette base de données. Je vais commencer par une question très importante :
SET @table_schema = "classes_and_students";
SELECT
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) AS "DB Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)"
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema;
Nous n'interrogeons que le INFORMATION_SCHEMA.TABLES tableau ici. Ce tableau devrait nous donner suffisamment de détails sur toutes les tables du serveur. Veuillez noter que j'ai filtré uniquement les tables de "classes_and_students " base de données en utilisant le SET variable dans la première ligne et plus tard en utilisant cette valeur dans la requête. La plupart des tables contiennent les colonnes TABLE_NAME et TABLE_SCHEMA , qui désignent la table et le schéma/la base de données auxquels appartiennent ces données.
Cette requête renverra la taille actuelle de notre base de données et l'espace libre réservé à notre base de données. Voici le résultat réel :

Comme prévu, la taille de notre base de données vide est inférieure à 1 Mo et l'espace libre réservé est beaucoup plus important.
Tailles et propriétés des tableaux
La prochaine chose intéressante à faire serait de regarder les tailles des tables dans notre base de données. Pour ce faire, nous utiliserons la requête suivante :
SET @table_schema = "classes_and_students";
SELECT
INFORMATION_SCHEMA.TABLES.TABLE_NAME,
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) "Table Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)",
MAX( INFORMATION_SCHEMA.TABLES.TABLE_ROWS) AS table_rows_number,
MAX( INFORMATION_SCHEMA.TABLES.AUTO_INCREMENT) AS auto_increment_value
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema
GROUP BY INFORMATION_SCHEMA.TABLES.TABLE_NAME
ORDER BY 2 DESC;
La requête est quasiment identique à la précédente, à une exception près :le résultat est regroupé au niveau de la table.
Voici une image du résultat renvoyé par cette requête :
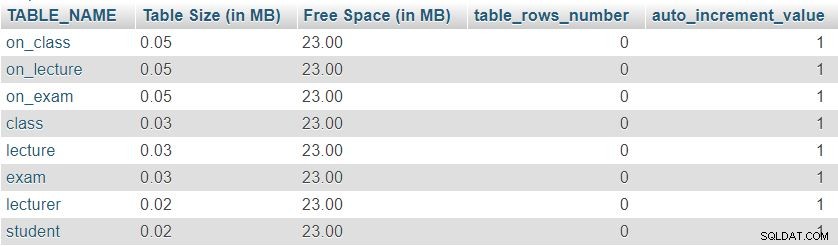
Tout d'abord, nous pouvons remarquer que les huit tables ont une "Taille de table" minimale réservé à la définition de table, qui inclut les colonnes, la clé primaire et l'index. L'"espace libre" est également réparti entre toutes les tables.
Nous pouvons également voir le nombre de lignes actuellement dans chaque table et la valeur actuelle de auto_increment propriété pour chaque table. Comme toutes les tables sont complètement vides, nous n'avons pas de données et auto_increment est défini sur 1 (une valeur qui sera affectée à la prochaine ligne insérée).
Clés primaires
Chaque table doit avoir une valeur de clé primaire définie, il est donc sage de vérifier si cela est vrai pour notre base de données. Une façon de faire est de joindre une liste de toutes les tables avec une liste de contraintes. Cela devrait nous donner les informations dont nous avons besoin.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
COUNT(*) AS PRI_number
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN (
SELECT
INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA,
INFORMATION_SCHEMA.COLUMNS.TABLE_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.COLUMNS.COLUMN_KEY = 'PRI'
) col
ON tab.TABLE_SCHEMA = col.TABLE_SCHEMA
AND tab.TABLE_NAME = col.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema
GROUP BY
tab.TABLE_NAME;
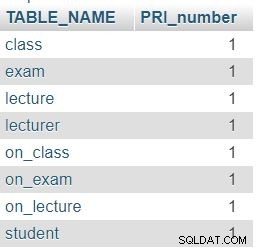
Nous avons également utilisé le INFORMATION_SCHEMA.COLUMNS table dans cette requête. Alors que la première partie de la requête renverra simplement toutes les tables de la base de données, la seconde partie (après LEFT JOIN ) comptera le nombre de PRI dans ces tableaux. Nous avons utilisé LEFT JOIN car nous voulons voir si une table a 0 PRI dans les COLUMNS tableau.
Comme prévu, chaque table de notre base de données contient exactement une colonne de clé primaire (PRI).
"Îles" ?
Les « îlots » sont des tables complètement séparées du reste du modèle. Ils se produisent lorsqu'une table ne contient aucune clé étrangère et n'est référencée dans aucune autre table. Cela ne devrait vraiment pas se produire à moins qu'il n'y ait une très bonne raison, par ex. lorsque les tables contiennent des paramètres ou stockent des résultats ou des rapports dans le modèle.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
(CASE WHEN f1.number_referenced IS NULL THEN 0 ELSE f1.number_referenced END) AS number_referenced,
(CASE WHEN f2.number_referencing IS NULL THEN 0 ELSE f2.number_referencing END) AS number_referencing
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN
-- # table was used as a reference
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME,
COUNT(*) AS number_referenced
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME
) f1
ON tab.TABLE_SCHEMA = f1.REFERENCED_TABLE_SCHEMA
AND tab.TABLE_NAME = f1.REFERENCED_TABLE_NAME
LEFT JOIN
-- # of references in the table
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME,
COUNT(*) AS number_referencing
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME IS NOT NULL
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME
) f2
ON tab.TABLE_SCHEMA = f2.TABLE_SCHEMA
AND tab.TABLE_NAME = f2.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema;
Quelle est l'idée derrière cette requête ? Eh bien, nous utilisons le INFORMATION_SCHEMA.KEY_COLUMN_USAGE table pour tester si une colonne de la table est une référence à une autre table ou si une colonne est utilisée comme référence dans une autre table. La première partie de la requête sélectionne toutes les tables. Après le premier LEFT JOIN, nous comptons le nombre de fois qu'une colonne de cette table a été utilisée comme référence. Après le deuxième LEFT JOIN, nous comptons le nombre de fois qu'une colonne de cette table a fait référence à une autre table.
Le résultat renvoyé est :
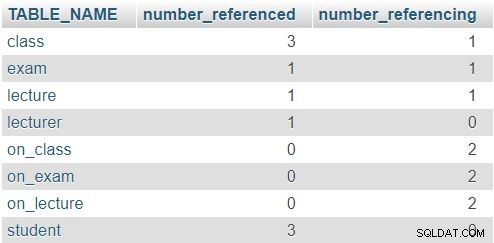
Dans la ligne de la class tableau, les chiffres 3 et 1 indiquent que ce tableau a été référencé trois fois (dans le lecture , exam , et on_class tables) et qu'il contient un attribut faisant référence à une autre table (lecturer_id ). Les autres tableaux suivent un schéma similaire, bien que les chiffres réels soient bien sûr différents. La règle ici est qu'aucune ligne ne doit avoir un 0 dans les deux colonnes.
Ajouter des lignes
Jusqu'à présent, tout s'est passé comme prévu. Nous avons importé avec succès notre modèle de données de Vertabelo vers le serveur MySQL local. Toutes les tables contiennent des clés, comme nous le souhaitons, et toutes les tables sont liées les unes aux autres - il n'y a pas d'"îlots" dans notre modèle.
Nous allons maintenant insérer des lignes dans nos tables et utiliser les requêtes présentées précédemment pour suivre les modifications dans notre base de données.
Après avoir ajouté 1 000 lignes dans la table du conférencier, nous allons à nouveau exécuter la requête à partir de "Table Sizes and Properties " section. Il renverra le résultat suivant :
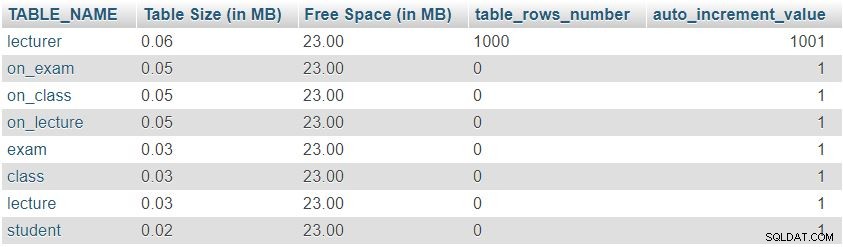
Nous pouvons facilement remarquer que le nombre de lignes et les valeurs auto_increment ont changé comme prévu, mais il n'y a pas eu de changement significatif dans la taille de la table.
Ce n'était qu'un exemple de test; dans des situations réelles, nous remarquerions des changements importants. Le nombre de lignes changera radicalement dans les tables remplies par les utilisateurs ou les processus automatisés (c'est-à-dire les tables qui ne sont pas des dictionnaires). Vérifier la taille et les valeurs de ces tables est un très bon moyen de trouver et de corriger rapidement les comportements indésirables.
Envie de partager ?
Travailler avec des bases de données est une recherche constante de performances optimales. Pour mieux réussir dans cette poursuite, vous devez utiliser n'importe quel outil disponible. Aujourd'hui, nous avons vu quelques requêtes utiles dans notre lutte pour de meilleures performances. Avez-vous trouvé autre chose d'utile ? Avez-vous joué avec le INFORMATION_SCHEMA base de données avant? Partagez votre expérience dans les commentaires ci-dessous.