Cet article est la 7e partie d'une série sur les expressions de table nommées. Dans les parties 5 et 6, j'ai couvert les aspects conceptuels des expressions de table communes (CTE). Ce mois-ci et le suivant, je me concentre sur les considérations d'optimisation des CTE.
Je vais commencer par revoir rapidement le concept de désimbrication des expressions de table nommées et démontrer son applicabilité aux CTE. Je me concentrerai ensuite sur des considérations de persistance. Je parlerai des aspects de persistance des CTE récursifs et non récursifs. J'expliquerai quand il est logique de s'en tenir aux CTE par rapport à quand il est plus logique de travailler avec des tables temporaires.
Dans mes exemples, je vais continuer à utiliser les exemples de bases de données TSQLV5 et PerformanceV5. Vous pouvez trouver le script qui crée et remplit TSQLV5 ici , et son diagramme ER ici. Vous pouvez trouver le script qui crée et remplit PerformanceV5 ici.
Substitution/désimbrication
Dans la partie 4 de la série, qui portait sur l'optimisation des tables dérivées, j'ai décrit un processus de désimbrication/substitution d'expressions de table. J'ai expliqué que lorsque SQL Server optimise une requête impliquant des tables dérivées, il applique des règles de transformation à l'arborescence initiale d'opérateurs logiques produite par l'analyseur, en déplaçant éventuellement les choses à travers ce qui était à l'origine des limites d'expression de table. Cela se produit à un degré tel que lorsque vous comparez un plan pour une requête utilisant des tables dérivées avec un plan pour une requête qui va directement sur les tables de base sous-jacentes où vous avez vous-même appliqué la logique de désimbrication, ils se ressemblent. J'ai également décrit une technique pour empêcher la désimbrication en utilisant le filtre TOP avec un très grand nombre de lignes en entrée. J'ai montré quelques cas où cette technique s'est avérée très pratique :l'un où le but était d'éviter les erreurs et l'autre pour des raisons d'optimisation.
La version TL; DR de la substitution/désimbrication des CTE est que le processus est le même qu'avec les tables dérivées. Si vous êtes satisfait de cette déclaration, vous pouvez ignorer cette section et passer directement à la section suivante sur la persistance. Vous ne manquerez rien d'important que vous n'avez pas lu auparavant. Cependant, si vous êtes comme moi, vous voulez probablement la preuve que c'est bien le cas. Ensuite, vous voudrez probablement continuer à lire cette section et tester le code que j'utilise en revisitant les exemples clés de désimbrication que j'ai précédemment démontrés avec des tables dérivées et les convertir pour utiliser des CTE.
Dans la partie 4, j'ai démontré la requête suivante (nous l'appellerons la requête 1) :
UTILISER TSQLV5 ; SELECT ID de commande, date de commande FROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE date de commande>='20180101' ) AS D1 WHERE date de commande>='20180201' ) AS D2 WHERE date de commande>='20180301' ) AS D3 WHERE date de commande>='20180401';
La requête implique trois niveaux d'imbrication de tables dérivées, plus une requête externe. Chaque niveau filtre une plage différente de dates de commande. Le plan pour la requête 1 est illustré à la figure 1.
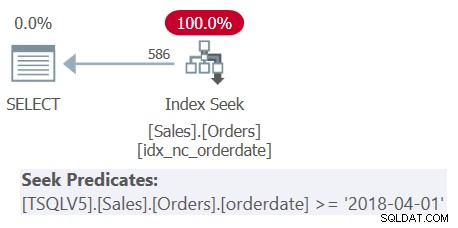 Figure 1 :Plan d'exécution pour la requête 1
Figure 1 :Plan d'exécution pour la requête 1
Le plan de la figure 1 montre clairement que la désimbrication des tables dérivées a eu lieu puisque tous les prédicats de filtre ont été fusionnés en un seul prédicat de filtre englobant.
J'ai expliqué que vous pouvez empêcher le processus de désimbrication en utilisant un filtre TOP significatif (par opposition à TOP 100 PERCENT) avec un très grand nombre de lignes en entrée, comme le montre la requête suivante (nous l'appellerons Requête 2) :
SELECT orderid, orderdate FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>=' 20180201' ) AS D2 WHERE date de commande>='20180301' ) AS D3 WHERE date de commande>='20180401';
Le plan pour la requête 2 est illustré à la figure 2.
 Figure 2 :Plan d'exécution pour la requête 2
Figure 2 :Plan d'exécution pour la requête 2
Le plan montre clairement que la désimbrication n'a pas eu lieu car vous pouvez effectivement voir les limites de la table dérivée.
Essayons les mêmes exemples en utilisant des CTE. Voici la requête 1 convertie pour utiliser les CTE :
WITH C1 AS ( SELECT * FROM Sales.Orders WHERE date_commande>='20180101' ), C2 AS ( SELECT * FROM C1 WHERE date_commande>='20180201' ), C3 AS ( SELECT * FROM C2 WHERE date_commande>=' 20180301' ) SELECT orderid, orderdate FROM C3 WHERE orderdate>='20180401';
Vous obtenez exactement le même plan illustré plus tôt dans la figure 1, où vous pouvez voir que la désimbrication a eu lieu.
Voici la requête 2 convertie pour utiliser les CTE :
WITH C1 AS ( SELECT TOP (9223372036854775807) * FROM Sales.Orders WHERE orderdate>='20180101' ), C2 AS (SELECT TOP (9223372036854775807) * FROM C1 WHERE orderdate>='20180201' ), C3 AS ( SELECT TOP (9223372036854775807) * FROM C2 WHERE orderdate>='20180301' ) SELECT orderid, orderdate FROM C3 WHERE orderdate>='20180401';
Vous obtenez le même plan que celui illustré précédemment dans la figure 2, où vous pouvez voir que la désimbrication n'a pas eu lieu.
Ensuite, revoyons les deux exemples que j'ai utilisés pour démontrer le caractère pratique de la technique pour empêcher le désimbrication, mais cette fois en utilisant des CTE.
Commençons par la requête erronée. La requête suivante tente de renvoyer des lignes de commande avec une remise supérieure à la remise minimale et où l'inverse de la remise est supérieur à 10 :
SELECT orderid, productid, discount FROM Sales.OrderDetails WHERE discount> (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount> 10.0 ;
La remise minimale ne peut pas être négative, elle est plutôt nulle ou supérieure. Donc, vous pensez probablement que si une ligne a une remise nulle, le premier prédicat devrait être évalué à faux, et qu'un court-circuit devrait empêcher la tentative d'évaluation du deuxième prédicat, évitant ainsi une erreur. Cependant, lorsque vous exécutez ce code, vous obtenez une erreur de division par zéro :
Msg 8134, niveau 16, état 1, ligne 99, erreur de division par zéro rencontrée.
Le problème est que même si SQL Server prend en charge un concept de court-circuit au niveau du traitement physique, rien ne garantit qu'il évaluera les prédicats de filtre dans l'ordre écrit de gauche à droite. Une tentative courante pour éviter de telles erreurs consiste à utiliser une expression de table nommée qui gère la partie de la logique de filtrage que vous souhaitez évaluer en premier, et à ce que la requête externe gère la logique de filtrage que vous souhaitez évaluer en second. Voici la solution tentée à l'aide d'un CTE :
WITH C AS ( SELECT * FROM Sales.OrderDetails WHERE discount> (SELECT MIN(discount) FROM Sales.OrderDetails) ) SELECT orderid, productid, discount FROM C WHERE 1.0 / discount> 10.0;
Malheureusement, la désimbrication de l'expression de table donne un équivalent logique à la requête de solution d'origine, et lorsque vous essayez d'exécuter ce code, vous obtenez à nouveau une erreur de division par zéro :
Msg 8134, niveau 16, état 1, ligne 108, erreur de division par zéro rencontrée.
En utilisant notre astuce avec le filtre TOP dans la requête interne, vous empêchez la désimbrication de l'expression de table, comme ceci :
WITH C AS ( SELECT TOP (9223372036854775807) * FROM Sales.OrderDetails WHERE discount> (SELECT MIN(discount) FROM Sales.OrderDetails) ) SELECT orderid, productid, discount FROM C WHERE 1.0 / discount> 10.0;
Cette fois, le code s'exécute avec succès sans aucune erreur.
Passons à l'exemple où vous utilisez la technique pour empêcher la désimbrication pour des raisons d'optimisation. Le code suivant renvoie uniquement les expéditeurs dont la date de commande maximale est le 1er janvier 2018 ou une date ultérieure :
UTILISER PerformanceV5 ; WITH C AS ( SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) SELECT shipperid, maxod FROM C WHERE maxod> ='20180101';
Si vous vous demandez pourquoi ne pas utiliser une solution beaucoup plus simple avec une requête groupée et un filtre HAVING, cela a à voir avec la densité de la colonne shipperid. Le tableau Commandes contient 1 000 000 de commandes, et les expéditions de ces commandes ont été traitées par cinq expéditeurs, ce qui signifie qu'en moyenne, chaque expéditeur a traité 20 % des commandes. Le plan d'une requête groupée calculant la date de commande maximale par expéditeur analyserait les 1 000 000 de lignes, ce qui entraînerait des milliers de lectures de pages. En effet, si vous mettez en surbrillance uniquement la requête interne du CTE (nous l'appellerons la requête 3) calculant la date de commande maximale par expéditeur et vérifiez son plan d'exécution, vous obtiendrez le plan illustré à la figure 3.
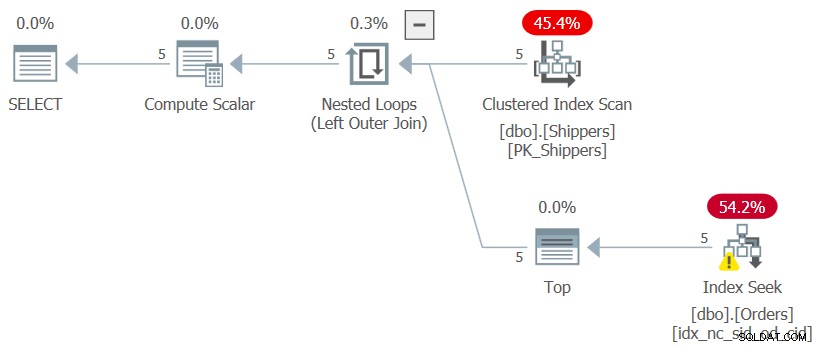 Figure 3 :Plan d'exécution pour la requête 3
Figure 3 :Plan d'exécution pour la requête 3
Le plan analyse cinq lignes dans l'index clusterisé sur les expéditeurs. Par expéditeur, le plan applique une recherche par rapport à un index de couverture sur les commandes, où (expéditeur, date de commande) sont les clés principales de l'index, en allant directement à la dernière ligne de chaque section d'expéditeur au niveau feuille pour extraire la date de commande maximale pour le courant. expéditeur. Comme nous n'avons que cinq expéditeurs, il n'y a que cinq opérations de recherche d'index, ce qui donne un plan très efficace. Voici les mesures de performance que j'ai obtenues lorsque j'ai exécuté la requête interne du CTE :
durée :0 ms, CPU :0 ms, lectures :15
Cependant, lorsque vous exécutez la solution complète (nous l'appellerons la requête 4), vous obtenez un plan complètement différent, comme illustré à la figure 4.
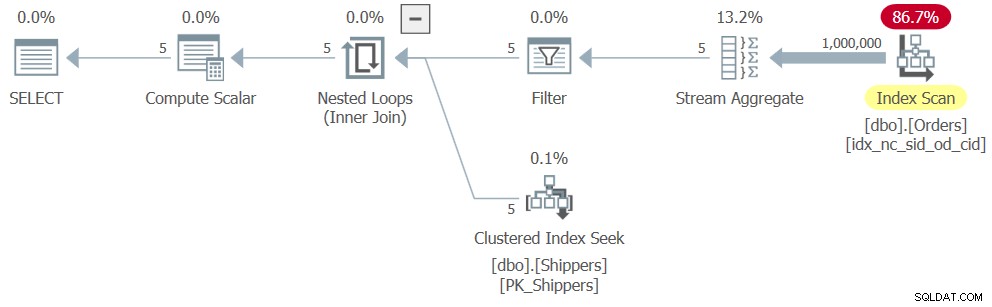 Figure 4 :Plan d'exécution pour la requête 4
Figure 4 :Plan d'exécution pour la requête 4
Ce qui s'est passé, c'est que SQL Server a désimbriqué l'expression de table, convertissant la solution en un équivalent logique d'une requête groupée, ce qui a entraîné une analyse complète de l'index sur Orders. Voici les chiffres de performance que j'ai obtenus pour cette solution :
durée :316 ms, CPU :281 ms, lectures :3854
Ce dont nous avons besoin ici, c'est d'empêcher la désimbrication de l'expression de table, de sorte que la requête interne soit optimisée avec des recherches par rapport à l'index sur Orders, et pour que la requête externe aboutisse simplement à l'ajout d'un opérateur de filtre dans le plan. Vous y parvenez en utilisant notre astuce en ajoutant un filtre TOP à la requête interne, comme ceci (nous appellerons cette solution Requête 5) :
WITH C AS ( SELECT TOP (9223372036854775807) S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) SELECT shipperid , maxod FROM C WHERE maxod>='20180101';
Le plan de cette solution est illustré à la figure 5.
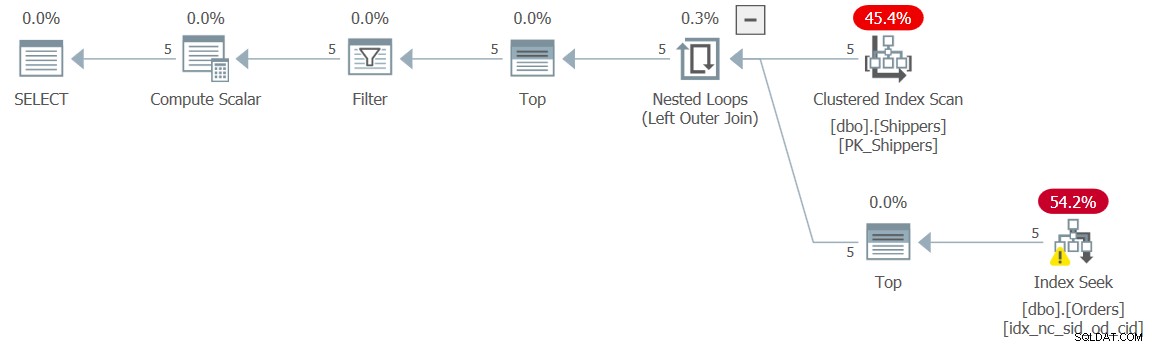 Figure 5 :Plan d'exécution pour la requête 5
Figure 5 :Plan d'exécution pour la requête 5
Le plan montre que l'effet souhaité a été atteint et, par conséquent, les chiffres de performance le confirment :
durée :0 ms, CPU :0 ms, lectures :15
Ainsi, nos tests confirment que SQL Server gère la substitution/désimbrication des CTE comme il le fait pour les tables dérivées. Cela signifie que vous ne devriez pas préférer l'un à l'autre pour des raisons d'optimisation, mais plutôt en raison de différences conceptuelles importantes pour vous, comme indiqué dans la partie 5.
Persistance
Une idée fausse courante concernant les CTE et les expressions de table nommées en général est qu'elles servent en quelque sorte de véhicule de persistance. Certains pensent que SQL Server conserve le jeu de résultats de la requête interne dans une table de travail et que la requête externe interagit réellement avec cette table de travail. En pratique, les CTE non récursifs réguliers et les tables dérivées ne sont pas persistants. J'ai décrit la logique de désimbrication que SQL Server applique lors de l'optimisation d'une requête impliquant des expressions de table, résultant en un plan qui interagit directement avec les tables de base sous-jacentes. Notez que l'optimiseur peut choisir d'utiliser des tables de travail pour conserver les ensembles de résultats intermédiaires s'il est logique de le faire pour des raisons de performances ou autres, telles que la protection Halloween. Lorsque c'est le cas, vous voyez les opérateurs Spool ou Index Spool dans le plan. Cependant, ces choix ne sont pas liés à l'utilisation d'expressions de table dans la requête.
CTE récursifs
Il existe quelques exceptions dans lesquelles SQL Server conserve les données de l'expression de table. L'une est l'utilisation de vues indexées. Si vous créez un index clusterisé sur une vue, SQL Server conserve le jeu de résultats de la requête interne dans l'index clusterisé de la vue et le synchronise avec toutes les modifications apportées aux tables de base sous-jacentes. L'autre exception est lorsque vous utilisez des requêtes récursives. SQL Server doit conserver les jeux de résultats intermédiaires des requêtes d'ancrage et récursives dans un spool afin qu'il puisse accéder au jeu de résultats du dernier tour représenté par la référence récursive au nom CTE chaque fois que le membre récursif est exécuté.
Pour illustrer cela, je vais utiliser l'une des requêtes récursives de la partie 6 de la série.
Utilisez le code suivant pour créer la table Employees dans la base de données tempdb, la remplir avec des exemples de données et créer un index de prise en charge :
SET NOCOUNT ON ; UTILISER tempdb ; SUPPRIMER LA TABLE SI EXISTE dbo.Employees ; GO CREATE TABLE dbo.Employees ( empid INT NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, mgrid INT NULL CONSTRAINT FK_Employees_Employees REFERENCES dbo.Employees, empname VARCHAR(25) NOT NULL, salaire MONEY NOT NULL, CHECK (empid <> mgrid) ); INSERT INTO dbo.Employees(empid, mgrid, empname, employee) VALUES(1, NULL, 'David' , $10000.00), (2, 1, 'Eitan' , $7000.00), (3, 1, 'Ina' , $7500.00) , (4, 2, 'Seraph' , 5000.00$), (5, 2, 'Jiru' , 5500.00$), (6, 2, 'Steve' , 4500.00$), (7, 3, 'Aaron' , 5000.00$), ( 8, 5, 'Lilach' , $3500.00), (9, 7, 'Rita' , $3000.00), (10, 5, 'Sean' , $3000.00), (11, 7, 'Gabriel', $3000.00), (12, 9, 'Emilia' , 2000.00$), (13, 9, 'Michael', 2000.00$), (14, 9, 'Didi' , 1500.00$); CRÉER UN INDEX UNIQUE idx_unc_mgrid_empid ON dbo.Employees(mgrid, empid) INCLUDE(nom_emp, salaire); ALLER
J'ai utilisé le CTE récursif suivant pour renvoyer tous les subordonnés d'un gestionnaire racine de sous-arborescence d'entrée, en utilisant l'employé 3 comme gestionnaire d'entrée dans cet exemple :
DECLARER @root AS INT =3 ; WITH C AS ( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid ) SELECT empid, mgrid, empname FROM C;
Le plan de cette requête (nous l'appellerons requête 6) est illustré à la figure 6.
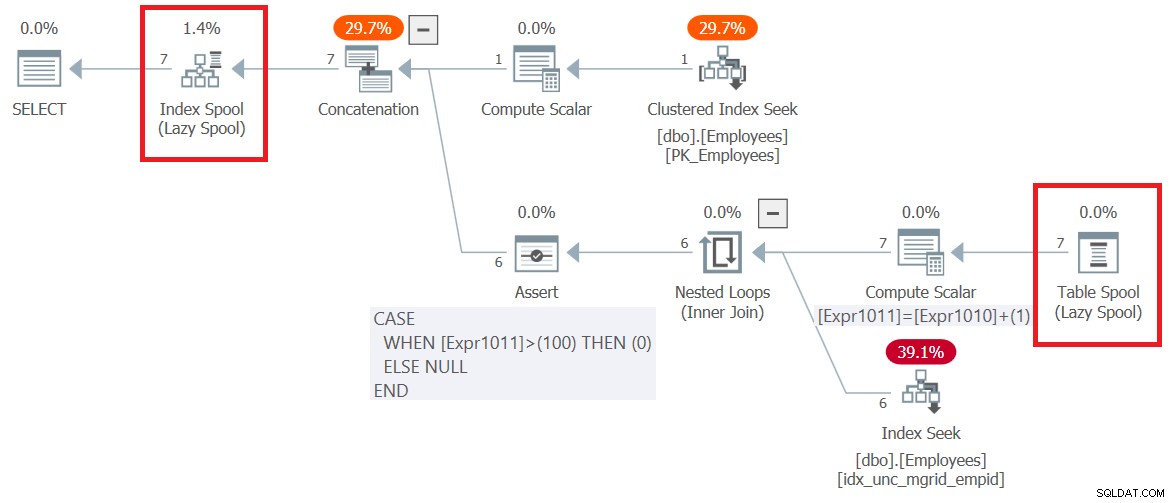 Figure 6 :Plan d'exécution pour la requête 6
Figure 6 :Plan d'exécution pour la requête 6
Observez que la toute première chose qui se produit dans le plan, à droite du nœud racine SELECT, est la création d'une table de travail basée sur un arbre B représentée par l'opérateur Index Spool. La partie supérieure du plan gère la logique du membre d'ancrage. Il extrait les lignes d'entrée des employés de l'index clusterisé sur Employees et les écrit dans le spool. La partie inférieure du plan représente la logique du membre récursif. Il est exécuté à plusieurs reprises jusqu'à ce qu'il renvoie un jeu de résultats vide. L'entrée externe de l'opérateur Nested Loops obtient les gestionnaires du tour précédent à partir du spool (opérateur Table Spool). L'entrée interne utilise un opérateur Index Seek sur un index non clusterisé créé sur Employees(mgrid, empid) pour obtenir les subordonnés directs des managers du tour précédent. Le jeu de résultats de chaque exécution de la partie inférieure du plan est également écrit dans le spool d'index. Notez qu'au total, 7 lignes ont été écrites dans le spool. Un renvoyé par le membre d'ancrage et 6 autres renvoyés par toutes les exécutions du membre récursif.
En passant, il est intéressant de remarquer comment le plan gère la limite de maxrecursion par défaut, qui est de 100. Observez que l'opérateur Compute Scalar du bas continue d'augmenter un compteur interne appelé Expr1011 de 1 à chaque exécution du membre récursif. Ensuite, l'opérateur Assert définit un indicateur sur zéro si ce compteur dépasse 100. Si cela se produit, SQL Server arrête l'exécution de la requête et génère une erreur.
Quand ne pas persister
Pour en revenir aux CTE non récursifs, qui ne sont normalement pas persistants, c'est à vous de déterminer du point de vue de l'optimisation quand il est bon de les utiliser par rapport aux outils de persistance réels comme les tables temporaires et les variables de table à la place. Je vais passer en revue quelques exemples pour montrer quand chaque approche est la plus optimale.
Commençons par un exemple où les CTE font mieux que les tables temporaires. C'est souvent le cas lorsque vous n'avez pas plusieurs évaluations du même CTE, mais plutôt une solution modulaire où chaque CTE n'est évalué qu'une seule fois. Le code suivant (nous l'appellerons Requête 7) interroge la table Commandes de la base de données Performance, qui contient 1 000 000 lignes, pour renvoyer les années de commande au cours desquelles plus de 70 clients distincts ont passé des commandes :
UTILISER PerformanceV5 ; WITH C1 AS ( SELECT YEAR(orderdate) AS orderyear, custid FROM dbo.Orders ), C2 AS ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts FROM C1 GROUP BY orderyear ) SELECT orderyear, numcusts FROM C2 WHERE numcusts> 70;Cette requête génère la sortie suivante :
orderyear numcusts ----------- ----------- 2015 992 2017 20000 2018 20000 2019 20000 2016 20000J'ai exécuté ce code à l'aide de SQL Server 2019 Developer Edition et j'ai obtenu le plan illustré à la figure 7.
Figure 7 :Plan d'exécution pour la requête 7
Notez que la désimbrication du CTE a entraîné un plan qui extrait les données d'un index sur la table Orders et n'implique aucune mise en file d'attente de l'ensemble de résultats de requête interne du CTE. J'ai obtenu les performances suivantes lors de l'exécution de cette requête sur ma machine :
durée :265 ms, CPU :828 ms, lectures :3970, écritures :0Essayons maintenant une solution qui utilise des tables temporaires au lieu de CTE (nous l'appellerons Solution 8), comme ceci :
SELECT YEAR(orderdate) AS orderyear, custid INTO #T1 FROM dbo.Orders; SELECT orderyear, COUNT(DISTINCT custid) AS numcusts INTO #T2 FROM #T1 GROUP BY orderyear ; SELECT orderyear, numcusts FROM #T2 WHERE numcusts> 70 ; SUPPRIMER TABLE #T1, #T2 ;Les plans de cette solution sont illustrés à la figure 8.
Figure 8 :Plans pour la solution 8
Remarquez les opérateurs d'insertion de table qui écrivent les ensembles de résultats dans les tables temporaires #T1 et #T2. Le premier est particulièrement coûteux car il écrit 1 000 000 de lignes dans #T1. Voici les chiffres de performance que j'ai obtenus pour cette exécution :
durée :454 ms, CPU :1 517 ms, lectures :14 359, écritures :359Comme vous pouvez le voir, la solution avec les CTE est beaucoup plus optimale.
Quand persister
Alors est-il toujours préférable d'utiliser une solution modulaire n'impliquant qu'une seule évaluation de chaque CTE à l'utilisation de tables temporaires ? Pas nécessairement. Dans les solutions basées sur CTE qui impliquent de nombreuses étapes et aboutissent à des plans élaborés où l'optimiseur doit appliquer de nombreuses estimations de cardinalité à de nombreux points différents du plan, vous pouvez vous retrouver avec des inexactitudes accumulées qui entraînent des choix sous-optimaux. L'une des techniques pour tenter de résoudre de tels cas consiste à conserver vous-même certains ensembles de résultats intermédiaires dans des tables temporaires, et même à créer des index dessus si nécessaire, donnant à l'optimiseur un nouveau départ avec de nouvelles statistiques, augmentant la probabilité d'estimations de cardinalité de meilleure qualité qui nous espérons conduire à des choix plus optimaux. Vous devrez tester si c'est mieux qu'une solution qui n'utilise pas de tables temporaires. Parfois, le compromis de coût supplémentaire pour les ensembles de résultats intermédiaires persistants dans le but d'obtenir des estimations de cardinalité de meilleure qualité en vaudra la peine.
Un autre cas typique où l'utilisation de tables temporaires est l'approche préférée est lorsque la solution basée sur CTE a plusieurs évaluations du même CTE, et la requête interne du CTE est assez coûteuse. Considérez la solution suivante basée sur CTE (nous l'appellerons Requête 9), qui associe à chaque année et mois de commande une année et un mois de commande différents qui ont le nombre de commandes le plus proche :
WITH OrdCount AS ( SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth, COUNT(*) AS numorders FROM dbo.Orders GROUP BY YEAR(orderdate), MONTH(orderdate) ) SELECT O1.orderyear, O1 .ordermonth, O1.numorders, O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2, O2.numorders AS numorders2 FROM OrdCount AS O1 CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth, O2.numorders FROM OrdCount AS O2 WHERE O2.orderyear <> O1.orderyear OR O2.ordermonth <> O1.ordermonth ORDER BY ABS(O1.numorders - O2.ordermonth), O2.orderyear, O2.ordermonth ) AS O2;Cette requête génère la sortie suivante :
année de commande mois de commande nombre de commandes année de commande2 mois de commande2 nombre de commandes2 ----------- ----------- ----------- -------- --- ----------- ----------- 2016 1 21262 2017 3 21267 2019 1 21227 2016 5 21229 2019 2 19145 2018 2 19125 2018 4 20561 2016 9 20554 2018 5 21209 2019 5 21210 2018 6 20515 2016 11 20513 2018 7 21194 2018 10 21197 2017 9 20542 2017 11 20539 2017 10 21234 2019 3 21235 2017 11 20539 2019 4 20537 2017 12 21183 2016 8 21185 2018 1 21241 2019 7 21238 2016 2 19644. 2019 12 20184 2018 3 21222 2016 10 21222 2016 4 20526 2019 9 20527 2019 4 20537 2017 11 20539 2017 5 21203 2017 8 21199 2019 6 20531 2019 9 20527 2017 7 21217 2016 7 21218 2018 8 21283 2017 3 21267 2018 10 21197 2017 8 21283 2017 3 21267 2018 101197 2017 8 21283 2016 11 20513 2018 6 20515 2019 11 20494 2017 4 20498 2018 2 19125 2019 2 19145 2016 3 21211 2016 12 21212 2019 3 21235 2017 10 21234 2016 5 21229 2019 1 21227 2019 5 21210 201. 6 3 21211 2017 6 20551 2016 9 20554 2017 8 21199 2018 10 21197 2018 9 20487 2019 11 20494 2016 10 21222 2018 3 21222 2018 11 20575 2016 6 20571 2016 12 21212 2016 3 21211 2019 12 20184 2018 9 20487 2017 1 21223 2016 10 10 21222 2017 2 19174 2019 2 19145 2017 3 21267 2016 1 21262 2017 4 20498 2019 11 20494 2016 6 20571 2018 11 20575 2016 7 21218 2017 7 21217 2019 7 21238 2018 1 21241 2016 8 21185 2017 12 21183 2019 8 21189 2016 8 21185 2016 9 20554 2017 6 20551 2019 9 20527 2016 4 20526 2019 10 21254 2016 1 21262 2015 12 1018 2018 2 19125 2018 12 21225 2017 1 21223 (49 rangées touchées)2018Le plan de la requête 9 est illustré à la figure 9.
Figure 9 :Plan d'exécution pour la requête 9
La partie supérieure du plan correspond à l'instance du CTE OrdCount dont l'alias est O1. Cette référence donne lieu à une évaluation du CTE OrdCount. Cette partie du plan extrait les lignes d'un index de la table Commandes, les regroupe par année et par mois, et agrège le nombre de commandes par groupe, ce qui donne 49 lignes. La partie inférieure du plan correspond à la table dérivée corrélée O2, qui est appliquée ligne par ligne à partir de O1, donc exécutée 49 fois. Chaque exécution interroge le CTE OrdCount et entraîne donc une évaluation distincte de la requête interne du CTE. Vous pouvez voir que la partie inférieure du plan analyse toutes les lignes de l'index sur les commandes, les regroupe et les agrège. Vous obtenez essentiellement un total de 50 évaluations du CTE, ce qui entraîne 50 fois l'analyse des 1 000 000 de lignes de Orders, en les regroupant et en les agrégeant. Cela ne semble pas être une solution très efficace. Voici les mesures de performances que j'ai obtenues lors de l'exécution de cette solution sur ma machine :
durée :16 secondes, CPU :56 secondes, lectures :130404, écritures :0Étant donné qu'il ne s'agit que de quelques dizaines de mois, il serait beaucoup plus efficace d'utiliser une table temporaire pour stocker le résultat d'une seule activité qui regroupe et agrège les lignes de Orders, puis dispose à la fois des entrées externes et internes de l'opérateur APPLY interagit avec la table temporaire. Voici la solution (nous l'appellerons Solution 10) en utilisant une table temporaire au lieu du CTE :
SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth, COUNT(*) AS numorders INTO #OrdCount FROM dbo.Orders GROUP BY YEAR(orderdate), MONTH(orderdate); SELECT O1.orderyear, O1.ordermonth, O1.numorders, O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2, O2.numorders AS numorders2 FROM #OrdCount AS O1 CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth , O2.numorders FROM #OrdCount AS O2 WHERE O2.orderyear <> O1.orderyear OR O2.ordermonth <> O1.ordermonth ORDER BY ABS(O1.nombreordres - O2.numorders), O2.orderyear, O2.ordermonth ) AS O2; SUPPRIMER TABLE #OrdCount;Ici, il n'y a pas grand intérêt à indexer la table temporaire, puisque le filtre TOP est basé sur un calcul dans sa spécification d'ordre, et donc un tri est inévitable. Cependant, il se pourrait très bien que dans d'autres cas, avec d'autres solutions, il soit aussi pertinent que vous envisagiez d'indexer vos tables temporaires. Quoi qu'il en soit, le plan de cette solution est illustré à la figure 10.
Figure 10 :Plans d'exécution pour la solution 10
Observez dans le plan supérieur comment le gros du travail impliquant la numérisation de 1 000 000 de lignes, leur regroupement et leur agrégation, ne se produit qu'une seule fois. 49 lignes sont écrites dans la table temporaire #OrdCount, puis le plan inférieur interagit avec la table temporaire pour les entrées externes et internes de l'opérateur Nested Loops, qui gère la logique de l'opérateur APPLY.
Voici les chiffres de performance que j'ai obtenus pour l'exécution de cette solution :
durée :0,392 seconde, CPU :0,5 seconde, lectures :3 636, écritures :3C'est plus rapide en ordre de grandeur que la solution basée sur CTE.
Quelle est la prochaine ?
Dans cet article, j'ai commencé la couverture des considérations d'optimisation liées aux CTE. J'ai montré que le processus de désimbrication/substitution qui a lieu avec les tables dérivées fonctionne de la même manière avec les CTE. J'ai également discuté du fait que les CTE non récursifs ne sont pas persistants et expliqué que lorsque la persistance est un facteur important pour les performances de votre solution, vous devez le gérer vous-même en utilisant des outils tels que des tables temporaires et des variables de table. Le mois prochain, je poursuivrai la discussion en abordant d'autres aspects de l'optimisation CTE.



