Tous mes articles de cette année ont porté sur les réactions instinctives aux statistiques d'attente, mais dans cet article, je m'écarte de ce thème pour parler d'un de mes bogues en particulier :le compteur de performances d'espérance de vie de la page (que j'appellerai PLE ).
Que signifie PLE ?
Il existe toutes sortes de déclarations incorrectes sur l'espérance de vie des pages sur Internet, et les plus flagrantes sont celles qui spécifient que la valeur 300 est le seuil auquel vous devriez vous inquiéter.
Pour comprendre pourquoi cette affirmation est si trompeuse, vous devez comprendre ce qu'est réellement PLE.
La définition de PLE est le temps attendu, en secondes, pendant lequel une page de fichier de données lue dans le pool de mémoire tampon (le cache en mémoire des pages de fichiers de données) restera en mémoire avant d'être poussée hors de la mémoire pour faire de la place pour une autre donnée. fiche fichier. Une autre façon de penser à PLE est une mesure instantanée de la pression exercée sur le pool de mémoire tampon pour libérer de l'espace pour les pages lues à partir du disque. Pour ces deux définitions, un nombre plus élevé est préférable.
Qu'est-ce qu'un bon seuil PLE ?
Un PLE de 300 signifie que l'ensemble de votre pool de mémoire tampon est effectivement vidé et relu toutes les cinq minutes. Lorsque le seuil de 300 pour le PLE a été donné pour la première fois par Microsoft, vers 2005/2006, ce nombre était peut-être plus logique car la quantité moyenne de mémoire sur un serveur était beaucoup plus faible.
De nos jours, où les serveurs ont régulièrement 64 Go, 128 Go et des quantités de mémoire supérieures, le fait d'avoir à peu près autant de données lues sur le disque toutes les cinq minutes serait probablement la cause d'un problème de performances paralysant
En réalité, au moment où le PLE se situe à 300 ou en dessous, votre serveur est déjà dans une situation désespérée. Vous commenceriez à vous inquiéter bien avant que le PLE ne soit aussi bas.
Alors, quel est le seuil à utiliser quand vous devriez vous inquiéter ?
Eh bien, c'est juste le point. Je ne peux pas vous donner de seuil, car ce nombre va varier pour tout le monde. Si vous voulez vraiment, vraiment un nombre à utiliser, mon collègue Jonathan Kehayias a trouvé une formule :
( Mémoire du pool de tampons en Go / 4 ) x 300Même ce nombre est quelque peu arbitraire, et votre kilométrage va varier.
Je n'aime pas recommander de chiffres. Mon conseil est que vous mesuriez votre PLE lorsque la performance est au niveau souhaité - c'est le seuil que vous utilisez.
Alors, commencez-vous à vous inquiéter dès que le PLE descend en dessous de ce seuil ? Non. Vous commencez à vous inquiéter lorsque le PLE tombe en dessous de ce seuil et reste en dessous de ce seuil, ou s'il chute précipitamment et vous ne savez pas pourquoi.
En effet, certaines opérations entraîneront une suppression PLE (par exemple, l'exécution de DBCC CHECKDB ou les reconstructions d'index peuvent le faire parfois) et ne sont pas préoccupantes. Mais si vous constatez une baisse importante du PLE et que vous ne savez pas ce qui en est la cause, c'est à ce moment-là que vous devriez vous inquiéter.
Vous vous demandez peut-être comment DBCC CHECKDB peut provoquer une chute de PLE lorsqu'il est défavorable et s'efforce d'éviter de vider le pool de mémoire tampon avec les données qu'il utilise (voir ce billet de blog pour une explication). C'est parce que la mémoire d'exécution de la requête accorde pour DBCC CHECKDB est mal calculé par l'optimiseur de requête et peut entraîner une forte réduction de la taille du pool de mémoire tampon (la mémoire pour l'octroi est volée du pool de mémoire tampon) et une baisse conséquente du PLE.
Comment surveillez-vous le PLE ?
C'est le plus délicat. La plupart des gens iront directement au Buffer Manager objet de performance dans PerfMon et surveillez l'Page life expectancy compteur. Est-ce la bonne approche ? Probablement pas.
Je dirais qu'une grande majorité de serveurs utilisent aujourd'hui l'architecture NUMA, et cela a un effet profond sur la façon dont vous surveillez PLE.
Lorsque NUMA est impliqué, le pool de mémoire tampon est divisé en nœuds de mémoire tampon, avec un nœud de mémoire tampon par nœud NUMA que SQL Server peut « voir ». Chaque nœud de tampon suit PLE séparément et le Buffer Manager:Page life expectancy compteur est la moyenne des PLE du nœud tampon. Si vous surveillez simplement le pool de mémoire tampon global PLE, la pression sur l'un des nœuds de mémoire tampon peut être masquée par la moyenne (j'en parle dans un article de blog ici).
Donc, si votre serveur utilise NUMA, vous devez surveiller l'espérance de vie individuelle de Buffer Node:Page life expectancy compteurs (il y aura un objet de performance Buffer Node pour chaque nœud NUMA), sinon vous surveillez bien le Buffer Manager:Page life expectancy compteur.
Mieux encore, utilisez un outil de surveillance comme SQL Sentry Performance Advisor, qui affichera ce compteur dans le cadre du tableau de bord, en tenant compte des nœuds NUMA sur le serveur, et vous permettra de configurer facilement des alertes.
Exemples d'utilisation de Performance Advisor
Vous trouverez ci-dessous un exemple de capture d'écran de Performance Advisor pour un système avec un seul nœud NUMA :
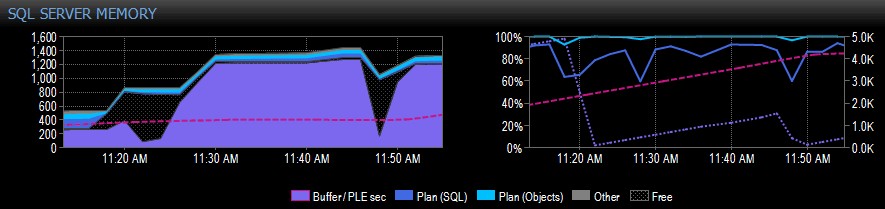
Sur le côté droit de la capture, la ligne pointillée rose est le PLE entre 10h30 et environ 11h20 – il grimpe régulièrement jusqu'à 5 000 environ, un nombre vraiment sain. Juste avant 11h20, il y a une énorme chute, puis ça recommence à grimper jusqu'à 11h45, où ça redescend.
C'est généralement ce que vous verriez si le pool de mémoire tampon est plein, avec toutes les pages utilisées, puis une requête s'exécute qui provoque la lecture d'une énorme quantité de données différentes à partir du disque, déplaçant une grande partie de ce qui est déjà en mémoire et provoquant un chute brutale du PLE. Si vous ne saviez pas ce qui a causé quelque chose comme ça, vous voudriez enquêter, comme je le décris plus loin.
Comme deuxième exemple, la capture d'écran ci-dessous provient de l'un de nos clients DBA distants où le serveur a deux nœuds NUMA (vous pouvez voir qu'il y a deux lignes PLE violettes), et où nous utilisons intensivement Performance Advisor :

Sur le serveur de ce client, tous les matins vers 5 heures du matin, un travail de maintenance d'index et de vérification de cohérence démarre, ce qui entraîne la chute du PLE dans les deux nœuds de tampon. Ce comportement est normal, il n'est donc pas nécessaire d'enquêter tant que le PLE augmente à nouveau pendant la journée.
Que pouvez-vous faire à propos de l'abandon du PLE ?
Si la cause de la chute du PLE n'est pas connue, vous pouvez faire plusieurs choses :
- Si le problème se produit maintenant, recherchez les requêtes à l'origine des lectures à l'aide de
sys.dm_os_waiting_tasksDMV pour voir quels threads attendent que les pages soient lues à partir du disque (c'est-à-dire ceux qui attendentPAGEIOLATCH_SH), puis corrigez ces requêtes. - Si le problème s'est produit dans le passé, recherchez dans la DMV sys.dm_exec_query_stats les requêtes avec un nombre élevé de lectures physiques, ou utilisez un outil de surveillance qui peut vous fournir ces informations (par exemple, la vue Top SQL dans Performance Advisor), et puis corrigez ces requêtes.
- Mettez en corrélation la suppression PLE avec les tâches d'agent planifiées qui effectuent la maintenance de la base de données.
- Recherchez les requêtes avec de très grandes allocations de mémoire de mémoire d'exécution de requête à l'aide de
sys.dm_exec_query_memory_grantsDMV, puis corrigez ces requêtes.
Mon article précédent ici explique plus en détail les points 1 et 2, et un script pour enquêter sur les attentes se produisant sur un serveur et un lien vers leurs plans de requête est ici.
Le "corriger ces requêtes" dépasse le cadre de cet article, je vais donc laisser cela pour une autre fois ou comme exercice pour le lecteur ☺
Résumé
Ne tombez pas dans le piège de croire à tout seuil PLE recommandé que vous pourriez lire en ligne. La meilleure façon de réagir aux changements de PLE est lorsque le PLE tombe en dessous de n'importe quel votre le niveau de confort est et reste là - c'est l'indication d'un problème de performances sur lequel vous devez enquêter.
Dans le prochain article de la série, je discuterai d'une autre cause fréquente de réglage des performances par réflexe. En attendant, bon dépannage !