Dans mon article précédent de cette série, j'ai démontré que tous les scénarios de requête ne peuvent pas bénéficier des technologies OLTP en mémoire. En fait, l'utilisation d'Hekaton dans certains cas d'utilisation peut avoir un effet néfaste sur les performances (cliquez pour agrandir) :

Profil de surveillance des performances lors de l'exécution de la procédure stockée
Cependant, j'aurais peut-être empilé le jeu contre Hekaton dans ce scénario, de deux manières :
- Le type de table à mémoire optimisée que j'ai créé avait un nombre de buckets de 256, mais je transmettais jusqu'à 2 000 valeurs à comparer. Dans un article de blog plus récent de l'équipe SQL Server, ils ont expliqué qu'il est préférable de surdimensionner le nombre de compartiments que de le sous-dimensionner - quelque chose que je savais en général, mais que je n'avais pas réalisé avait également des effets significatifs sur les variables de table :à l'esprit que pour un index de hachage, bucket_count doit être d'environ 1 à 2 fois le nombre de clés d'index uniques attendues. Le surdimensionnement est généralement préférable au sous-dimensionnement :si parfois vous n'insérez que 2 valeurs dans les variables, mais que vous insérez parfois jusqu'à 1 000 valeurs, il est généralement préférable de spécifier
BUCKET_COUNT=1000.Ils ne discutent pas explicitement de la raison réelle de cela, et je suis sûr qu'il y a beaucoup de détails techniques dans lesquels nous pourrions nous plonger, mais les conseils normatifs semblent être surdimensionnés.
- La clé primaire était un index de hachage sur deux colonnes, alors que le paramètre de table tentait uniquement de faire correspondre les valeurs dans l'une de ces colonnes. Tout simplement, cela signifiait que l'index de hachage ne pouvait pas être utilisé. Tony Rogerson l'explique un peu plus en détail dans un article de blog récent :Le hachage est généré sur toutes les colonnes contenues dans l'index, vous devez également spécifier toutes les colonnes de l'index de hachage sur votre expression de contrôle d'égalité, sinon l'index ne peut pas être utilisé. .
Je ne l'ai pas montré auparavant, mais notez que le plan contre la table optimisée en mémoire avec l'index de hachage à deux colonnes effectue en fait une analyse de table plutôt que la recherche d'index que vous pourriez attendre contre l'index de hachage non clusterisé (puisque le principal la colonne était
SalesOrderID):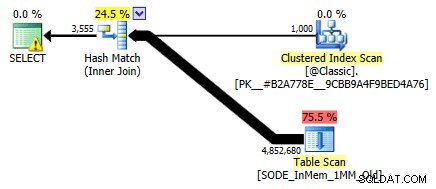
Plan de requête impliquant une table en mémoire avec une colonne à deux index de hachagePour être plus précis, dans un index de hachage, la colonne de tête ne signifie pas une colline de haricots à elle seule ; le hachage est toujours mis en correspondance dans toutes les colonnes, il ne fonctionne donc pas du tout comme un index B-tree traditionnel (avec un index traditionnel, un prédicat impliquant uniquement la colonne de tête peut toujours être très utile pour éliminer les lignes).
Que faire ?
Eh bien, d'abord, j'ai créé un index de hachage secondaire uniquement sur le SalesOrderID colonne. Un exemple d'une telle table, avec un million de buckets :
CREATE TABLE [dbo].[SODE_InMem_1MM]
(
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] [numeric](38, 6) NOT NULL,
[rowguid] [uniqueidentifier] NOT NULL,
[ModifiedDate] [datetime] NOT NULL
PRIMARY KEY NONCLUSTERED HASH
(
[SalesOrderID],
[SalesOrderDetailID]
) WITH (BUCKET_COUNT = 1048576),
/* I added this secondary non-clustered hash index: */
INDEX x NONCLUSTERED HASH
(
[SalesOrderID]
) WITH (BUCKET_COUNT = 1048576)
/* I used the same bucket count to minimize testing permutations */
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); N'oubliez pas que nos types de tableaux sont configurés de cette manière :
CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
Une fois que j'ai rempli les nouvelles tables avec des données et créé une nouvelle procédure stockée pour référencer les nouvelles tables, le plan que nous obtenons montre correctement une recherche d'index par rapport à l'index de hachage à une seule colonne :

Plan amélioré à l'aide de l'index de hachage à une seule colonne
Mais qu'est-ce que cela signifierait vraiment pour les performances? J'ai exécuté à nouveau le même ensemble de tests - des requêtes sur cette table avec des nombres de compartiments de 16K, 131K et 1MM ; en utilisant à la fois des TVP classiques et en mémoire avec des valeurs de 100, 1 000 et 2 000 ; et dans le cas TVP en mémoire, en utilisant à la fois une procédure stockée traditionnelle et une procédure stockée compilée en mode natif. Voici comment les performances se sont déroulées pour 10 000 itérations par combinaison :

Profil de performances pour 10 000 itérations par rapport à un index de hachage à une seule colonne, à l'aide d'un TVP à 256 compartiments
Vous pensez peut-être, hé, que le profil de performance n'a pas l'air génial; au contraire, c'est bien mieux que mon test précédent le mois dernier. Cela démontre simplement que le nombre de compartiments pour la table peut avoir un impact considérable sur la capacité de SQL Server à utiliser efficacement l'index de hachage. Dans ce cas, l'utilisation d'un nombre de buckets de 16 000 n'est clairement pas optimale pour aucun de ces cas, et la situation s'aggrave de manière exponentielle à mesure que le nombre de valeurs dans le TVP augmente.
Maintenant, rappelez-vous, le nombre de compartiments du TVP était de 256. Que se passerait-il donc si j'augmentais cela, conformément aux instructions de Microsoft ? J'ai créé un deuxième type de table avec une taille de bucket plus appropriée. Comme je testais des valeurs de 100, 1 000 et 2 000, j'ai utilisé la prochaine puissance de 2 pour le nombre de compartiments (2 048) :
CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 2048) ) WITH (MEMORY_OPTIMIZED = ON);
J'ai créé des procédures de support pour cela et j'ai exécuté à nouveau la même batterie de tests. Voici les profils de performances côte à côte :

Comparaison des profils de performances avec des TVP à 256 et 2 048 compartiments
La modification du nombre de compartiments pour le type de table n'a pas eu l'impact auquel je m'attendais, compte tenu de la déclaration de Microsoft sur le dimensionnement. Cela n'a vraiment pas eu beaucoup d'effet positif du tout; en fait, pour certains scénarios, c'était un peu pire. Mais dans l'ensemble, les profils de performance sont, à toutes fins utiles, les mêmes.
Ce qui a eu un effet énorme, cependant, a été de créer l'index de hachage *right* pour prendre en charge le modèle de requête. J'étais reconnaissant d'avoir pu démontrer que - malgré mes tests précédents qui indiquaient le contraire - une table en mémoire et un TVP en mémoire pouvaient battre la méthode traditionnelle pour accomplir la même chose. Prenons simplement le cas le plus extrême de mon exemple précédent, lorsque la table n'avait qu'un index de hachage à deux colonnes :

Profil de performance pour 10 itérations par rapport à un index de hachage à deux colonnes
La barre la plus à droite montre la durée de seulement 10 itérations de la procédure stockée native correspondant à un index de hachage inapproprié - des temps de requête allant de 735 à 1 601 millisecondes. Maintenant, cependant, avec le bon index de hachage en place, les mêmes requêtes s'exécutent dans une plage beaucoup plus petite - de 0,076 millisecondes à 51,55 millisecondes. Si nous laissons de côté le pire des cas (16 000 compartiments), l'écart est encore plus prononcé. Dans tous les cas, c'est au moins deux fois plus efficace (au moins en termes de durée) que l'une ou l'autre des méthodes, sans procédure stockée naïvement compilée, par rapport à la même table optimisée en mémoire ; et des centaines de fois mieux que n'importe laquelle des approches contre notre ancienne table optimisée en mémoire avec le seul index de hachage à deux colonnes.
Conclusion
J'espère avoir démontré qu'il faut faire très attention lors de l'implémentation de tables à mémoire optimisée de tout type, et que dans de nombreux cas, l'utilisation d'un TVP à mémoire optimisée à lui seul peut ne pas générer le gain de performances le plus important. Vous voudrez peut-être envisager d'utiliser des procédures stockées compilées en mode natif pour en avoir le plus pour votre argent, et pour mieux évoluer, vous voudrez vraiment faire attention au nombre de compartiments pour les index de hachage dans vos tables optimisées en mémoire (mais peut-être pas tant d'attention à vos types de table optimisés en mémoire).
Pour en savoir plus sur la technologie OLTP en mémoire en général, vous pouvez consulter ces ressources :
- Le blog de l'équipe SQL Server (balise :Hekaton et balise :OLTP en mémoire :les noms de code ne sont-ils pas amusants ?)
- Blog de Bob Beauchemin
- Blog de Klaus Aschenbrenner