J'ai brièvement mentionné que les données en mode batch sont normalisées dans mon dernier article Bitmaps en mode batch dans SQL Server. Toutes les données d'un lot sont représentées par une valeur de huit octets dans ce format normalisé particulier, quel que soit le type de données sous-jacent.
Cette déclaration soulève sans aucun doute quelques questions, notamment sur la manière dont les données d'une longueur bien supérieure à huit octets peuvent éventuellement être stockées de cette façon. Cet article explore la représentation normalisée des données par lots, explique pourquoi tous les types de données à huit octets ne peuvent pas tenir dans 64 bits et montre un exemple de la façon dont tout cela affecte les performances du mode par lots.
Démo
Je vais commencer par un exemple qui montre que le format de données par lots fait une différence importante dans un plan d'exécution. Vous aurez besoin de SQL Server 2016 (ou version ultérieure) et Developer Edition (ou équivalent) pour reproduire les résultats présentés ici.
La première chose dont nous aurons besoin est une table de bigint nombres de 1 à 102 400 inclus. Ces nombres seront utilisés pour remplir une table columnstore sous peu (le nombre de lignes est le minimum nécessaire pour obtenir un seul segment compressé).
DROP TABLE IF EXISTS #Numbers;
GO
CREATE TABLE #Numbers (n bigint NOT NULL PRIMARY KEY);
GO
INSERT #Numbers (n)
SELECT
n = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
n
OFFSET 0 ROWS
FETCH FIRST 102400 ROWS ONLY
OPTION (MAXDOP 1); Réduction agrégée réussie
Le script suivant utilise la table des nombres pour créer une autre table contenant les mêmes nombres décalés par une valeur spécifique. Cette table utilise columnstore pour son stockage principal afin de produire ultérieurement une exécution en mode batch.
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
@Start bigint = CONVERT(bigint, -4611686018427387905);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Exécutez les requêtes de test suivantes sur la nouvelle table columnstore :
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
L'addition à l'intérieur du SUM est d'éviter les débordements. Vous pouvez ignorer le WHERE clauses (pour éviter un plan trivial) si vous exécutez SQL Server 2017.
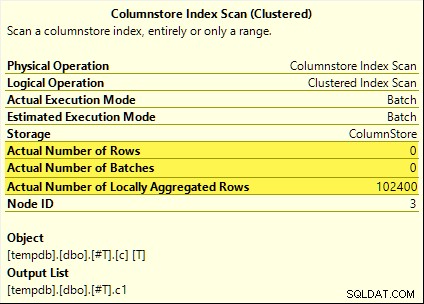
Ces requêtes bénéficient toutes du refoulement agrégé. L'agrégat est calculé au Columnstore Index Scan plutôt que le mode batch Hash Aggregate opérateur. Les plans de post-exécution affichent zéro ligne émise par l'analyse. Les 102 400 lignes ont toutes été « agrégées localement ».
La SUM plan est présenté ci-dessous à titre d'exemple :

Échec du refoulement agrégé
Maintenant, déposez puis recréez la table de test columnstore avec le décalage diminué de un :
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
-- Note this value has decreased by one
@Start bigint = CONVERT(bigint, -4611686018427387906);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Exécutez exactement les mêmes requêtes de test pushdown agrégées qu'auparavant :
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Cette fois, seuls les COUNT_BIG l'agrégat atteint le refoulement d'agrégat (SQL Server 2017 uniquement). Le MAX et SUM pas les agrégats. Voici la nouvelle SUM prévoir une comparaison avec celui du premier test :

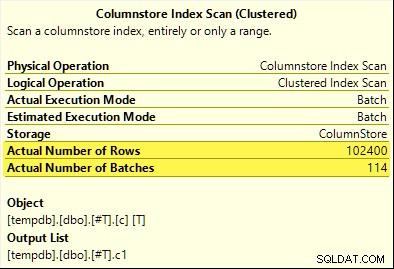
Les 102 400 lignes (en 114 lots) sont émises par le Columnstore Index Scan , traité par le Compute Scalar , et envoyé à l'agrégat de hachage .
Pourquoi la différence ? Tout ce que nous avons fait était de décaler de un la plage de nombres stockés dans la table columnstore !
Explication
J'ai mentionné dans l'introduction que tous les types de données à huit octets ne peuvent pas tenir en 64 bits. Ce fait est important car de nombreuses optimisations des performances du columnstore et du mode batch ne fonctionnent qu'avec des données de taille 64 bits. Le refoulement agrégé est l'une de ces choses. Il existe de nombreuses autres fonctionnalités de performance (pas toutes documentées) qui fonctionnent mieux (ou pas du tout) uniquement lorsque les données tiennent en 64 bits.
Dans notre exemple spécifique, le refoulement agrégé est désactivé pour un segment columnstore lorsqu'il en contient même un valeur de données qui ne rentre pas dans 64 bits. SQL Server peut déterminer cela à partir des métadonnées de valeur minimale et maximale associées à chaque segment sans vérifier toutes les données. Chaque segment est évalué séparément.
Le refoulement agrégé fonctionne toujours pour le COUNT_BIG agrégées uniquement dans le second test. Il s'agit d'une optimisation ajoutée à un moment donné dans SQL Server 2017 (mes tests ont été exécutés sur CU16). Il est logique de ne pas désactiver le refoulement agrégé lorsque nous ne comptons que les lignes et que nous ne faisons rien avec les valeurs de données spécifiques. Je n'ai trouvé aucune documentation pour cette amélioration, mais ce n'est pas si inhabituel de nos jours.
En remarque, j'ai remarqué que SQL Server 2017 CU16 permet le refoulement agrégé pour les types de données précédemment non pris en charge real , float , datetimeoffset , et numeric avec une précision supérieure à 18 — lorsque les données tiennent sur 64 bits. Ceci est également non documenté au moment de la rédaction.
D'accord, mais pourquoi ?
Vous vous posez peut-être la question très raisonnable :pourquoi un ensemble de bigint les valeurs de test tiennent apparemment en 64 bits mais pas l'autre ?
Si vous avez deviné que la raison était liée à NULL , donnez-vous une tique. Même si la colonne de la table de test est définie comme NOT NULL , SQL Server utilise la même disposition de données normalisée pour bigint si les données autorisent les valeurs nulles ou non. Il y a des raisons à cela, que je vais détailler petit à petit.
Permettez-moi de commencer par quelques observations :
- Chaque valeur de colonne d'un lot est stockée sur exactement huit octets (64 bits), quel que soit le type de données sous-jacent. Cette mise en page à taille fixe rend tout plus facile et plus rapide. L'exécution en mode batch est une question de vitesse.
- Un lot a une taille de 64 Ko et contient entre 64 et 900 lignes, selon le nombre de colonnes projetées. Cela a du sens étant donné que les tailles de données de colonne sont fixées à 64 bits. Plus de colonnes signifie que moins de lignes peuvent tenir dans chaque lot de 64 Ko.
- Tous les types de données SQL Server ne peuvent pas tenir en 64 bits, même en principe. Une longue chaîne (pour prendre un exemple) peut même ne pas tenir dans un lot entier de 64 Ko (si cela était autorisé), sans parler d'une seule entrée de 64 bits.
SQL Server résout ce dernier problème en stockant une référence de 8 octets aux données supérieures à 64 bits. La "grande" valeur de données est stockée ailleurs dans la mémoire. Vous pouvez appeler cet arrangement un stockage « hors ligne » ou « hors lot ». En interne, on parle de données profondes .
Désormais, les types de données à huit octets ne peuvent pas tenir dans 64 bits lorsqu'ils sont nullables. Prenez bigint NULL par exemple . La plage de données non nulle peut nécessiter les 64 bits complets, et nous avons encore besoin d'un autre bit pour indiquer nul ou non.
Résoudre les problèmes
La solution créative et efficace à ces défis est de réserver le bit significatif le plus bas (LSB) de la valeur 64 bits comme indicateur. Le drapeau indique en lot stockage des données lorsque le LSB est vide (mis à zéro). Lorsque le LSB est défini (à un), cela peut signifier l'une des deux choses :
- La valeur est nulle ; ou
- La valeur est stockée hors lot (il s'agit de données approfondies).
Ces deux cas se distinguent par l'état des 63 bits restants. Quand ils sont tous nuls , la valeur est NULL . Sinon, la "valeur" est un pointeur vers des données profondes stockées ailleurs.
Lorsqu'il est considéré comme un entier, la définition du LSB signifie que les pointeurs vers des données approfondies seront toujours impairs Nombres. Les valeurs nulles sont représentées par le nombre (impair) 1 (tous les autres bits sont nuls). Les données en lot sont représentées par pair nombres car le LSB est égal à zéro.
Cela n'est pas signifie que SQL Server ne peut stocker que des nombres pairs dans un lot ! Cela signifie simplement que la représentation normalisée des valeurs de colonne sous-jacentes auront toujours un LSB de zéro lorsqu'elles sont stockées "en lot". Cela aura plus de sens dans un instant.
Normalisation des données par lots
La normalisation est effectuée de différentes manières, selon le type de données sous-jacent. Pour bigint le processus est :
- Si les données sont null , stockez la valeur 1 (uniquement LSB défini).
- Si la valeur peut être représentée en 63 bits , décalez tous les bits d'une place vers la gauche et mettez à zéro le LSB. Lorsque vous considérez la valeur comme un entier, cela signifie doubler la valeur. Par exemple le
bigintla valeur 1 est normalisée à la valeur 2. En binaire, c'est-à-dire sept octets entièrement nuls suivis de00000010. Le LSB étant nul indique qu'il s'agit de données stockées en ligne. Lorsque SQL Server a besoin de la valeur d'origine, il décale vers la droite la valeur 64 bits d'une position (en supprimant l'indicateur LSB). - Si la valeur ne peut pas être représenté en 63 bits, la valeur est stockée hors lot en tant que données profondes . Le pointeur in-batch a le LSB défini (ce qui en fait un nombre impair).
Le processus de test si un bigint la valeur peut tenir sur 63 bits est :
- Stocker le raw*
bigintvaleur dans le registre du processeur 64 bitsr8. - Mémoriser le double de la valeur de
r8dans le registrerax. - Décaler les bits de
raxun endroit à droite. - Tester si les valeurs dans
raxetr8sont égaux.
* Notez que la valeur brute ne peut pas être déterminée de manière fiable pour tous les types de données par une conversion T-SQL en un type binaire. Le résultat T-SQL peut avoir un ordre d'octet différent et peut également contenir des métadonnées, par ex. time précision à la fraction de seconde.
Si le test de l'étape 4 réussit, nous savons que la valeur peut être doublée puis réduite de moitié dans les 64 bits, en préservant la valeur d'origine.
Une gamme réduite
Le résultat de tout cela est que la plage de bigint les valeurs pouvant être stockées par lots sont réduites d'un bit (parce que le LSB n'est pas disponible). Les plages inclusives suivantes de bigint les valeurs seront stockées hors lot en tant que données approfondies :
- -4 611 686 018 427 387 905 à -9 223 372 036 854 775 808
- +4 611 686 018 427 387 904 à +9 223 372 036 854 775 807
En échange de l'acceptation que ces bigint limitations de plage, la normalisation permet à SQL Server de stocker (la plupart) bigint valeurs, valeurs nulles et références de données approfondies en lot . C'est beaucoup plus simple et plus économe en espace que d'avoir des structures séparées pour la nullabilité et les références de données profondes. Cela facilite également le traitement des données par lots avec les instructions du processeur SIMD.
Normalisation d'autres types de données
SQL Server contient une normalisation code pour chacun des types de données pris en charge par l'exécution en mode batch. Chaque routine est optimisée pour gérer efficacement la disposition binaire entrante et pour ne créer des données approfondies que lorsque cela est nécessaire. La normalisation entraîne toujours la réservation du LSB pour indiquer les valeurs nulles ou les données profondes, mais la disposition des 63 bits restants varie selon le type de données.
Toujours en lot
Les données normalisées pour les types de données suivants sont toujours stockées par lot puisqu'ils n'ont jamais besoin de plus de 63 bits :
datetime(n)– redimensionné en interne àtime(7)datetime2(n)– redimensionné en interne àdatetime2(7)integersmallinttinyintbit– utilise letinyintmise en œuvre.smalldatetimedatetimerealfloatsmallmoney
Ça dépend
Les types de données suivants peuvent être stockés par lots ou en profondeur en fonction de la valeur des données :
bigint– comme décrit précédemment.money– même plage en lot quebigintmais divisé par 10 000.numeric/decimal– 18 chiffres décimaux ou moins dans le lot indépendamment de précision déclarée. Par exemple ledecimal(38,9)la valeur -999999999.999999999 peut être représentée par l'entier de 8 octets -999999999999999999 (f21f494c589c0001hex), qui peut être doublé en -1999999999999999998 (e43e9298b1380002hex) de manière réversible dans les 64 bits. SQL Server sait où va la virgule par rapport à l'échelle du type de données.datetimeoffset(n)– en lot si la valeur d'exécution conviendra àdatetimeoffset(2)peu importe de la précision déclarée en fractions de seconde.timestamp– le format interne est différent de l'affichage. Par exemple untimestampaffiché à partir de T-SQL sous la forme0x000000000099449Aest représenté en interne par9a449900 00000000(en hexagone). Cette valeur est stockée en tant que données profondes car elle ne tient pas dans 64 bits lorsqu'elle est doublée (décalée à gauche d'un bit).
Données toujours approfondies
Les éléments suivants sont toujours stockés en tant que données profondes (sauf les valeurs nulles) :
uniqueidentifiervarbinary(n)– y compris(max)binarychar/varchar(n)/nchar/nvarchar(n)/sysnamey compris(max)– ces types peuvent également utiliser un dictionnaire (si disponible).text/ntext/image/xml– utilise levarbinary(n)mise en œuvre.
Pour être clair, des valeurs nulles pour tous les types de données compatibles en mode batch sont stockés dans le lot en tant que valeur spéciale "un".
Réflexions finales
Vous pouvez vous attendre à tirer le meilleur parti des optimisations disponibles du columnstore et du mode batch lorsque vous utilisez des types de données et des valeurs qui tiennent en 64 bits. Vous aurez également les meilleures chances de bénéficier d'améliorations progressives du produit au fil du temps, par exemple les dernières améliorations du refoulement agrégé notées dans le texte principal. Tous les avantages en termes de performances ne seront pas aussi visibles dans les plans d'exécution, ni même documentés. Néanmoins, les différences peuvent être extrêmement importantes.
Je dois également mentionner que les données sont normalisées lorsqu'un opérateur de plan d'exécution en mode ligne fournit des données à un parent en mode batch, ou lorsqu'un scan non-columnstore produit des lots (mode batch sur rowstore). Il existe un adaptateur ligne-lot invisible qui appelle la routine de normalisation appropriée sur chaque valeur de colonne avant de l'ajouter au lot. Éviter les types de données avec une normalisation compliquée et un stockage de données approfondi peut également améliorer les performances.