Cet article est la cinquième partie d'une série sur les bogues, les pièges et les meilleures pratiques de T-SQL. Auparavant, j'ai couvert le déterminisme, les sous-requêtes, les jointures et le fenêtrage. Ce mois-ci, je couvre le pivotement et le non-pivotement. Merci Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man et Paul White pour avoir partagé vos suggestions !
Dans mes exemples, j'utiliserai un exemple de base de données appelé TSQLV5. Vous pouvez trouver le script qui crée et remplit cette base de données ici, et son diagramme ER ici.
Regroupement implicite avec PIVOT
Lorsque les utilisateurs souhaitent faire pivoter des données à l'aide de T-SQL, ils utilisent soit une solution standard avec une requête groupée et des expressions CASE, soit l'opérateur de table PIVOT propriétaire. Le principal avantage de l'opérateur PIVOT est qu'il a tendance à produire un code plus court. Cependant, cet opérateur présente quelques défauts, parmi lesquels un piège de conception inhérent qui peut entraîner des bogues dans votre code. Ici, je vais décrire le piège, le bogue potentiel et une meilleure pratique qui empêche le bogue. Je décrirai également une suggestion pour améliorer la syntaxe de l'opérateur PIVOT de manière à éviter le bogue.
Lorsque vous permutez des données, trois étapes sont impliquées dans la solution, avec trois éléments associés :
- Regroupement basé sur un élément de regroupement/sur les lignes
- Spread basé sur un élément spread/on cols
- Agrégation basée sur une agrégation/un élément de données
Voici la syntaxe de l'opérateur PIVOT :
SELECTFROM PIVOT( ( ) FOR IN( ) ) AS ;
La conception de l'opérateur PIVOT nécessite que vous spécifiiez explicitement les éléments d'agrégation et de répartition, mais laisse SQL Server comprendre implicitement l'élément de regroupement par élimination. Quelles que soient les colonnes qui apparaissent dans la table source fournie comme entrée de l'opérateur PIVOT, elles deviennent implicitement l'élément de regroupement.
Supposons, par exemple, que vous souhaitiez interroger la table Sales.Orders dans la base de données exemple TSQLV5. Vous souhaitez renvoyer les identifiants des expéditeurs sur les lignes, les années expédiées sur les colonnes et le nombre de commandes par expéditeur et par an comme agrégat.
De nombreuses personnes ont du mal à comprendre la syntaxe de l'opérateur PIVOT, ce qui entraîne souvent le regroupement des données par éléments indésirables. À titre d'exemple avec notre tâche, supposons que vous ne réalisez pas que l'élément de regroupement est déterminé implicitement et que vous obtenez la requête suivante :
SELECT shipperid, [2017], [2018], [2019]FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT( COUNT(shippeddate) FOR shippedyear IN([2017] , [2018], [2019]) ) AS P ;
Il n'y a que trois expéditeurs présents dans les données, avec les ID d'expéditeur 1, 2 et 3. Vous vous attendez donc à ne voir que trois lignes dans le résultat. Cependant, la sortie réelle de la requête affiche beaucoup plus de lignes :
numéro d'expédition 2017 2018 2019----------- ----------- ----------- ---------- -3 1 0 01 1 0 02 1 0 01 1 0 02 1 0 02 1 0 02 1 0 03 1 0 02 1 0 03 1 0 0...3 0 1 03 0 1 03 0 1 01 0 1 03 0 1 01 0 1 03 0 1 03 0 1 03 0 1 01 0 1 0...3 0 0 11 0 0 12 0 0 11 0 0 12 0 0 11 0 0 13 0 0 13 0 0 12 0 1 0...(830 lignes concernées)
Que s'est-il passé ?
Vous pouvez trouver un indice qui vous aidera à comprendre le bogue dans le code en consultant le plan de requête illustré à la figure 1.
 Figure 1 :Plan pour une requête pivot avec regroupement implicite
Figure 1 :Plan pour une requête pivot avec regroupement implicite
Ne laissez pas l'utilisation de l'opérateur CROSS APPLY avec la clause VALUES dans la requête vous embrouiller. Ceci est fait simplement pour calculer la colonne de résultat Shippedyear en fonction de la colonne source Shipdate, et est géré par le premier opérateur Compute Scalar du plan.
La table d'entrée de l'opérateur PIVOT contient toutes les colonnes de la table Sales.Orders, plus la colonne de résultat Shippedyear. Comme mentionné, SQL Server détermine implicitement l'élément de regroupement par élimination en fonction de ce que vous n'avez pas spécifié comme éléments d'agrégation (shippeddate) et de propagation (shippedyear). Vous vous attendiez peut-être intuitivement à ce que la colonne shipperid soit la colonne de regroupement car elle apparaît dans la liste SELECT, mais comme vous pouvez le voir dans le plan, en pratique, vous avez une liste de colonnes beaucoup plus longue, y compris orderid, qui est la colonne de clé primaire dans le tableau source. Cela signifie qu'au lieu d'obtenir une ligne par expéditeur, vous obtenez une ligne par commande. Puisque dans la liste SELECT vous avez spécifié uniquement les colonnes shipperid, [2017], [2018] et [2019], vous ne voyez pas le reste, ce qui ajoute à la confusion. Mais les autres ont participé au groupement implicite.
Ce qui pourrait être formidable, c'est que la syntaxe de l'opérateur PIVOT prenne en charge une clause dans laquelle vous pouvez indiquer explicitement l'élément grouping/on rows. Quelque chose comme ça :
SELECTFROM PIVOT( ( ) FOR IN( ) ON ROWS ) AS ;
Sur la base de cette syntaxe, vous utiliseriez le code suivant pour gérer notre tâche :
SELECT shipperid, [2017], [2018], [2019]FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT( COUNT(shippeddate) FOR shippedyear IN([2017] , [2018], [2019]) ON ROWS shipperid ) AS P ;
Vous pouvez trouver un élément de rétroaction avec une suggestion pour améliorer la syntaxe de l'opérateur PIVOT ici. Pour faire de cette amélioration une modification incassable, cette clause peut être rendue facultative, la valeur par défaut étant le comportement existant. Il existe d'autres suggestions pour améliorer la syntaxe de l'opérateur PIVOT en le rendant plus dynamique et en prenant en charge plusieurs agrégats.
En attendant, il existe une meilleure pratique qui peut vous aider à éviter le bogue. Utilisez une expression de table telle qu'un CTE ou une table dérivée dans laquelle vous ne projetez que les trois éléments que vous devez impliquer dans l'opération de pivot, puis utilisez l'expression de table comme entrée de l'opérateur PIVOT. De cette façon, vous contrôlez entièrement l'élément de regroupement. Voici la syntaxe générale suivant cette bonne pratique :
WITHAS( SELECT , , FROM )SELECT FROM PIVOT( ( ) FOR IN( ) ) AS ;
Appliqué à notre tâche, vous utilisez le code suivant :
WITH C AS( SELECT shipperid, YEAR(shippeddate) AS shipperid, expeditionddate FROM Sales.Orders)SELECT shipperid, [2017], [2018], [2019]FROM C PIVOT( COUNT(shippeddate) FOR shippedyear IN([ 2017], [2018], [2019]) ) AS P ;
Cette fois, vous n'obtenez que trois lignes de résultats comme prévu :
numéro d'expédition 2017 2018 2019----------- ----------- ----------- ---------- -3 51 125 731 36 130 792 56 143 116
Une autre option consiste à utiliser l'ancienne solution standard classique pour pivoter à l'aide d'une requête groupée et d'expressions CASE, comme ceci :
SELECT shipperid, COUNT(CASE WHEN shippedyear =2017 THEN 1 END) AS [2017], COUNT(CASE WHEN shippedyear =2018 THEN 1 END) AS [2018], COUNT(CASE WHEN shippedyear =2019 THEN 1 END) AS [2019]FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear)WHERE shipdate IS NOT NULLGROUP BY shipperid ;
Avec cette syntaxe, les trois étapes pivots et leurs éléments associés doivent être explicites dans le code. Cependant, lorsque vous avez un grand nombre de valeurs de répartition, cette syntaxe a tendance à être détaillée. Dans de tels cas, les gens préfèrent souvent utiliser l'opérateur PIVOT.
Suppression implicite des valeurs NULL avec UNPIVOT
Le prochain élément de cet article est plus un piège qu'un bug. Cela a à voir avec l'opérateur propriétaire T-SQL UNPIVOT, qui vous permet de ne pas faire pivoter les données d'un état de colonnes à un état de lignes.
Je vais utiliser une table appelée CustOrders comme exemple de données. Utilisez le code suivant pour créer, remplir et interroger ce tableau afin d'afficher son contenu :
DROP TABLE IF EXISTS dbo.CustOrders;GO WITH C AS( SELECT custid, YEAR(orderdate) AS orderyearyear, val FROM Sales.OrderValues)SELECT custid, [2017], [2018], [2019]INTO dbo.CustOrdersFROM C PIVOT( SUM(val) FOR orderyearyear IN([2017], [2018], [2019]) ) AS P ; SELECT * FROM dbo.CustOrders ;
Ce code génère la sortie suivante :
custid 2017 2018 2019------- ---------- ---------- ----------1 NULL 2022.50 2250.502 88.80 799.75 514.403 403.20 5960.78 660.004 1379.00 6406.90 5604.755 4324.40 13849.02 6754.166 NULL 1079.80 2160.007 9986.20 7817.88 730.008 982.00 3026.85 224.009 4074.28 11208.36 6680.6110 1832.80 7630.25 11338.5611 479.40 3179.50 2431.0012 NULL 238.00 1576.8013 100.80 NULL NULL14 1674.22 6516.40 4158.2615 2169.00 1128.00 513.7516 NULL 787.60 931.5017 533.60 420.00 2809.6118 268.80 487.00 860.1019 950.00 4514.35 9296.6920 15568.07 48096.27 41210.65...
Ce tableau contient les valeurs totales des commandes par client et par an. Les valeurs NULL représentent les cas où un client n'a eu aucune activité de commande au cours de l'année cible.
Supposons que vous souhaitiez annuler le pivot des données de la table CustOrders, en renvoyant une ligne par client et par année, avec une colonne de résultat appelée val contenant la valeur totale de la commande pour le client et l'année actuels. Toute tâche non pivotée implique généralement trois éléments :
- Les noms des colonnes source existantes que vous annulez :[2017], [2018], [2019] dans notre cas
- Un nom que vous attribuez à la colonne cible qui contiendra les noms de colonne source :orderyear dans notre cas
- Un nom que vous attribuez à la colonne cible qui contiendra les valeurs de la colonne source :val dans notre cas
Si vous décidez d'utiliser l'opérateur UNPIVOT pour gérer la tâche non pivotée, vous devez d'abord comprendre les trois éléments ci-dessus, puis utiliser la syntaxe suivante :
SELECT, , FROM UNPIVOT( FOR IN( ) ) AS ;
Appliqué à notre tâche, vous utilisez la requête suivante :
SELECT custid, orderyear, valFROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U ;
Cette requête génère la sortie suivante :
custid orderyear val------- ---------- ----------1 2018 2022.501 2019 2250.502 2017 88.802 2018 799.752 2019 514.403 2017 403.203 2018 5960.783 2019 660.004 2017 1379.004 2018 6406.904 2019 5604.755 2017 4324.405 2018 13849.025 2019 6754.166 2018 1079.806 2019 2160.007 2017 9986.207 2018 7817.887 2019 730.00 ...
En regardant les données source et le résultat de la requête, remarquez-vous ce qui manque ?
La conception de l'opérateur UNPIVOT implique une élimination implicite des lignes de résultats qui ont un NULL dans la colonne des valeurs — val dans notre cas. En regardant le plan d'exécution de cette requête illustré à la figure 2, vous pouvez voir l'opérateur de filtre supprimer les lignes avec les valeurs NULL dans la colonne val (Expr1007 dans le plan).
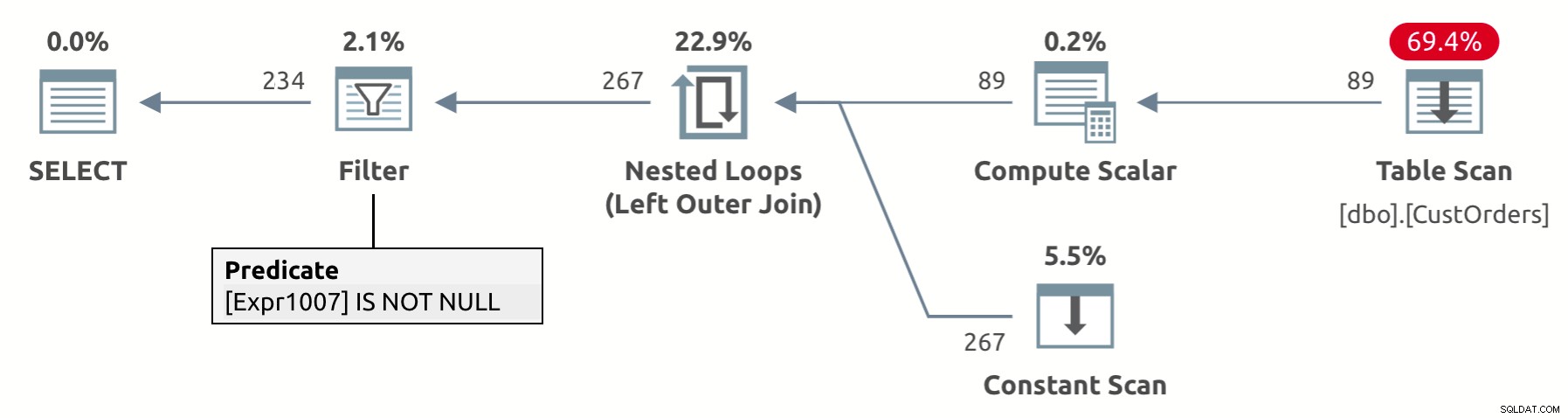 Figure 2 :Plan pour une requête non pivotée avec suppression implicite des valeurs NULL
Figure 2 :Plan pour une requête non pivotée avec suppression implicite des valeurs NULL
Parfois, ce comportement est souhaitable, auquel cas vous n'avez rien à faire de spécial. Le problème est que parfois vous souhaitez conserver les lignes avec les valeurs NULL. Le piège, c'est quand vous voulez conserver les valeurs NULL et que vous ne réalisez même pas que l'opérateur UNPIVOT est conçu pour les supprimer.
Ce qui pourrait être formidable, c'est si l'opérateur UNPIVOT avait une clause facultative qui vous permettait de spécifier si vous souhaitez supprimer ou conserver les valeurs NULL, la première étant la valeur par défaut pour la compatibilité descendante. Voici un exemple de ce à quoi cette syntaxe pourrait ressembler :
SELECT, , FROM UNPIVOT( FOR IN( ) [REMOVE NULLS | KEEP NULLS] ) AS ; Si vous vouliez conserver les valeurs NULL, selon cette syntaxe, vous utiliseriez la requête suivante :
SELECT custid, orderyear, valFROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) KEEP NULLS ) AS U;Vous pouvez trouver un élément de rétroaction avec une suggestion pour améliorer la syntaxe de l'opérateur UNPIVOT de cette manière ici.
En attendant, si vous souhaitez conserver les lignes avec les valeurs NULL, vous devez trouver une solution de contournement. Si vous insistez pour utiliser l'opérateur UNPIVOT, vous devez appliquer deux étapes. Dans la première étape, vous définissez une expression de table basée sur une requête qui utilise la fonction ISNULL ou COALESCE pour remplacer les valeurs NULL dans toutes les colonnes non pivotées par une valeur qui ne peut normalement pas apparaître dans les données, par exemple, -1 dans notre cas. Dans la deuxième étape, vous utilisez la fonction NULLIF dans la requête externe sur la colonne des valeurs pour remplacer le -1 par un NULL. Voici le code complet de la solution :
WITH C AS( SELECT custid, ISNULL([2017], -1.0) AS [2017], ISNULL([2018], -1.0) AS [2018], ISNULL([2019], -1.0) AS [2019 ] FROM dbo.CustOrders)SELECT custid, orderyear, NULLIF(val, -1.0) AS valFROM C UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;Voici le résultat de cette requête montrant que les lignes avec NULL dans la colonne val sont conservées :
custid orderyear val------- ---------- ----------1 2017 NULL1 2018 2022.501 2019 2250.502 2017 88.802 2018 799.752 2019 514.403 2017 403.203 2018 5960.783 2019 660.004 2017 1379.004 2018 6406.904 2019 5604.755 2017 4324.405 2018 13849.025 2019 6754.166 2017 Null6 2018 1079.806 2019 2160.007 2017 9986.207 2018 7817.887 2019 730.00 ...Cette approche est délicate, surtout lorsque vous avez un grand nombre de colonnes à annuler le pivot.
Une autre solution utilise une combinaison de l'opérateur APPLY et de la clause VALUES. Vous construisez une ligne pour chaque colonne non pivotée, avec une colonne représentant la colonne des noms cibles (orderyear dans notre cas) et une autre représentant la colonne des valeurs cibles (val dans notre cas). Vous fournissez l'année constante pour la colonne des noms et la colonne source corrélée pertinente pour la colonne des valeurs. Voici le code complet de la solution :
SELECT custid, orderyear, valFROM dbo.CustOrders CROSS APPLY ( VALUES(2017, [2017]), (2018, [2018]), (2019, [2019]) AS A(orderyear, val);La bonne chose ici est qu'à moins que vous ne soyez intéressé par la suppression des lignes avec les NULL dans la colonne val, vous n'avez rien à faire de spécial. Il n'y a pas d'étape implicite ici qui supprime les lignes avec les NULLS. De plus, puisque l'alias de colonne val est créé dans le cadre de la clause FROM, il est accessible à la clause WHERE. Donc, si vous êtes intéressé par la suppression des NULL, vous pouvez être explicite à ce sujet dans la clause WHERE en interagissant directement avec l'alias de la colonne de valeurs, comme ceci :
SELECT custid, orderyear, valFROM dbo.CustOrders CROSS APPLY ( VALUES(2017, [2017]), (2018, [2018]), (2019, [2019]) ) AS A(orderyear, val)WHERE val IS PAS NULL ;Le fait est que cette syntaxe vous permet de contrôler si vous souhaitez conserver ou supprimer les valeurs NULL. Il est plus flexible que l'opérateur UNPIVOT d'une autre manière, vous permettant de gérer plusieurs mesures non pivotées telles que val et qty. Mon objectif dans cet article était cependant le piège impliquant les NULL, donc je ne suis pas entré dans cet aspect.
Conclusion
La conception des opérateurs PIVOT et UNPIVOT entraîne parfois des bogues et des pièges dans votre code. La syntaxe de l'opérateur PIVOT ne vous permet pas d'indiquer explicitement l'élément de regroupement. Si vous ne vous en rendez pas compte, vous pouvez vous retrouver avec des éléments de regroupement indésirables. Comme meilleure pratique, il est recommandé d'utiliser une expression de table comme entrée de l'opérateur PIVOT, et c'est pourquoi contrôler explicitement quel est l'élément de regroupement.
La syntaxe de l'opérateur UNPIVOT ne vous permet pas de contrôler s'il faut supprimer ou conserver les lignes avec des valeurs NULL dans la colonne des valeurs de résultat. Comme solution de contournement, vous utilisez soit une solution maladroite avec les fonctions ISNULL et NULLIF, soit une solution basée sur l'opérateur APPLY et la clause VALUES.
J'ai également mentionné deux éléments de retour avec des suggestions pour améliorer les opérateurs PIVOT et UNPIVOT avec des options plus explicites pour contrôler le comportement de l'opérateur et de ses éléments.



