SQL Server 2014 SP2 et les versions ultérieures produisent des plans d'exécution ("réels") qui peuvent inclure le temps écoulé et l'utilisation du processeur pour chaque opérateur de plan d'exécution (voir KB3170113 et cet article de blog de Pedro Lopes).
L'interprétation de ces chiffres n'est pas toujours aussi simple qu'on pourrait s'y attendre. Il existe des différences importantes entre le mode ligne et mode batch l'exécution, ainsi que des problèmes délicats avec le parallélisme en mode ligne . SQL Server effectue des ajustements de synchronisation en parallèle des plans pour favoriser la cohérence, mais ils ne sont pas parfaitement mis en œuvre. Il peut donc être difficile de tirer des conclusions solides sur le réglage des performances.
Cet article vise à vous aider à comprendre d'où viennent les délais dans chaque cas et comment ils peuvent être mieux interprétés dans leur contexte.
Configuration
Les exemples suivants utilisent le public Stack Overflow 2013 base de données (détails du téléchargement), avec un seul index ajouté :
CREATE INDEX PP ON dbo.Posts (PostTypeId ASC, CreationDate ASC) INCLUDE (AcceptedAnswerId);
Les requêtes de test renvoient le nombre de questions avec une réponse acceptée, regroupées par mois et par année. Ils sont exécutés sur SQL Server 2019 CU9 , sur un ordinateur portable avec 8 cœurs et 16 Go de mémoire alloués à l'instance SQL Server 2019. Niveau de compatibilité 150 est utilisé exclusivement.
Exécution série en mode batch
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Le plan d'exécution est (cliquez pour agrandir) :
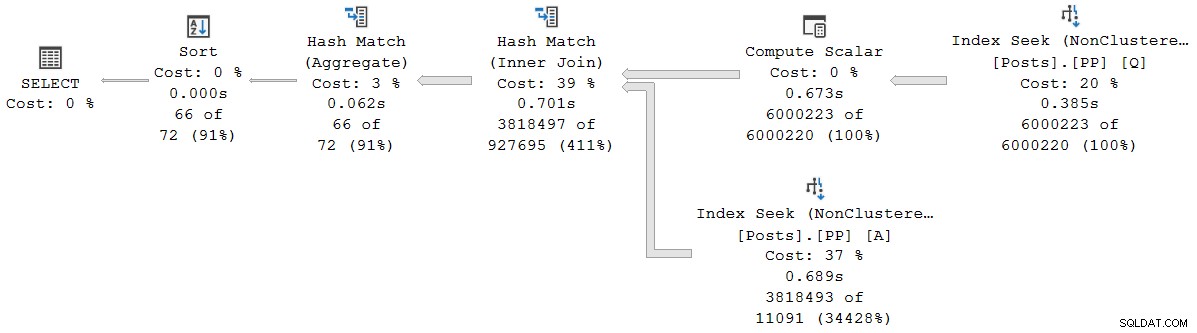
Chaque opérateur de ce plan fonctionne en mode batch, grâce au mode batch sur rowstore Fonctionnalité de traitement intelligent des requêtes dans SQL Server 2019 (aucun index columnstore nécessaire). La requête s'exécute pendant 2 523 ms avec 2 522 ms de temps CPU utilisé, lorsque toutes les données nécessaires sont déjà dans le pool de mémoire tampon.
Comme le note Pedro Lopes dans le billet de blog lié plus tôt, les temps écoulés et CPU signalés pour le mode batch individuel les opérateurs représentent le temps utilisé par cet opérateur seul .
SSMS affiche le temps écoulé dans la représentation graphique. Pour voir les temps CPU , sélectionnez un opérateur de plan, puis regardez dans les Propriétés la fenêtre. Cette vue détaillée affiche à la fois le temps écoulé et le temps CPU, par opérateur et par thread.
Les heures de showplan (y compris la représentation XML) sont tronquées en millisecondes. Si vous avez besoin d'une plus grande précision, utilisez le query_thread_profile événement étendu, qui rapporte en microsecondes . Le résultat de cet événement pour le plan d'exécution présenté ci-dessus est :
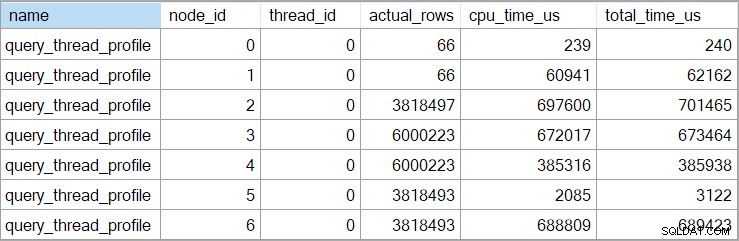
Cela montre que le temps écoulé pour la jointure (nœud 2) est de 701 465 µs (tronqué à 701 ms dans le showplan). L'agrégat a un temps écoulé de 62 162 µs (62 ms). La recherche d'index "questions" s'affiche comme s'exécutant pendant 385 ms, tandis que l'événement étendu montre que le chiffre réel pour le nœud 4 était de 385 938 µs (très près de 386 ms).
SQL Server utilise la haute précision QueryPerformanceCounter API pour capturer les données de synchronisation. Cela utilise du matériel, généralement un oscillateur à cristal, qui produit des ticks à un taux constant très élevé, quels que soient la vitesse du processeur, les paramètres d'alimentation ou quoi que ce soit de cette nature. L'horloge continue de fonctionner au même rythme même pendant le sommeil. Voir l'article très détaillé lié si vous êtes intéressé par tous les détails les plus fins. Le bref résumé est que vous pouvez faire confiance aux nombres de microsecondes pour être exacts.
Dans ce plan en mode batch pur, le temps d'exécution total est très proche de la somme des temps écoulés par chaque opérateur. La différence est en grande partie due au travail post-déclaration non associé aux opérateurs de plan (qui ont tous fermé à ce moment-là), bien que la troncation en millisecondes joue également un rôle.
Dans les plans en mode batch pur, vous devez additionner manuellement les temps des opérateurs actuels et enfants pour obtenir le cumulatif temps écoulé à un nœud donné.
Exécution parallèle en mode batch
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Le plan d'exécution est :
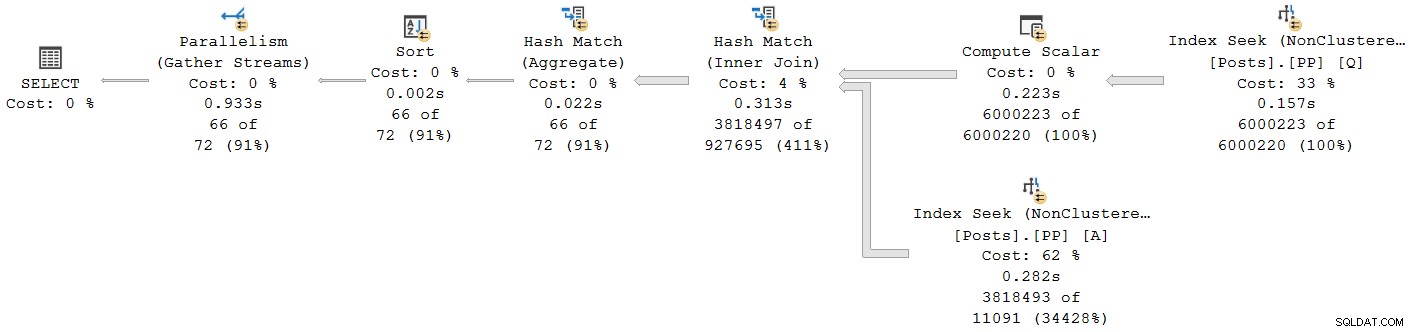
Tous les opérateurs, à l'exception de l'échange de flux de regroupement final, s'exécutent en mode batch. Le temps total écoulé est de 933 ms avec 6 673 ms de temps CPU avec un cache à chaud.
Sélection de la jointure de hachage et recherche dans les propriétés SSMS fenêtre, nous voyons le temps écoulé et le temps CPU par thread pour cet opérateur :
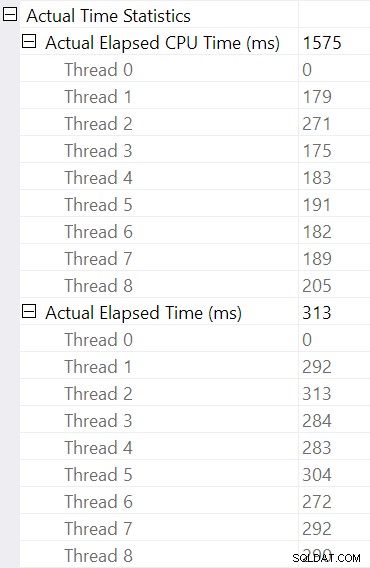
Le temps CPU rapporté pour l'opérateur est la somme des temps CPU des threads individuels. Le temps écoulé de l'opérateur signalé est le maximal des temps écoulés par thread. Les deux calculs sont effectués sur les valeurs de millisecondes tronquées par thread. Comme auparavant, le temps d'exécution total est très proche de la somme des temps écoulés par chaque opérateur.
Les plans parallèles en mode batch n'utilisent pas d'échanges pour répartir le travail entre les threads. Les opérateurs par lots sont implémentés afin que plusieurs threads puissent fonctionner efficacement sur une seule structure partagée (par exemple table de hachage). Une certaine synchronisation entre les threads est toujours requise dans les plans parallèles en mode batch, mais les points de synchronisation et d'autres détails ne sont pas visibles dans la sortie showplan.
Exécution série en mode ligne
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISALLOW_BATCH_MODE')
); Le plan d'exécution est visuellement le même que le plan série en mode batch, mais chaque opérateur s'exécute désormais en mode ligne :
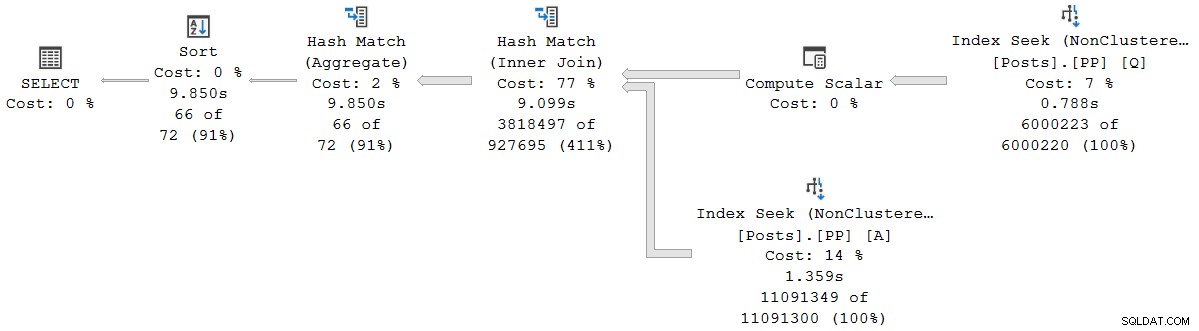
La requête s'exécute pendant 9 850 ms avec un temps CPU de 9 845 ms. C'est beaucoup plus lent que la requête en mode batch série (2523 ms/2522 ms), comme prévu. Plus important encore pour la présente discussion, le mode ligne l'opérateur écoulé et les temps CPU représentent le temps utilisé par l'opérateur actuel et tous ses enfants .
L'événement étendu affiche également le CPU cumulé et les temps écoulés à chaque nœud (en microsecondes) :
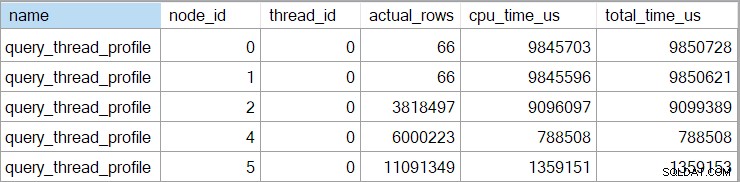
Il n'y a pas de données pour l'opérateur scalaire de calcul (nœud 3) car l'exécution en mode ligne peut différer la plupart des calculs d'expression à l'opérateur qui consomme le résultat. Ceci n'est actuellement pas implémenté pour l'exécution en mode batch.
Le rapport cumulatif Le temps écoulé pour les opérateurs en mode ligne signifie que le temps affiché pour l'opérateur de tri final correspond étroitement au temps d'exécution total de la requête (à une résolution de l'ordre de la milliseconde de toute façon). Le temps écoulé pour la jointure de hachage inclut également les contributions des deux recherches d'index en dessous, ainsi que son propre temps. Pour calculer le temps écoulé pour la jointure par hachage en mode ligne seule, nous aurions besoin d'en soustraire les deux temps de recherche.
Il y a des avantages et des inconvénients aux deux présentations (cumulatif pour le mode ligne, opérateur individuel uniquement pour le mode batch). Quelle que soit votre préférence, il est important de connaître les différences.
Plans en mode d'exécution mixte
En général, les plans d'exécution modernes peuvent contenir n'importe quel mélange d'opérateurs en mode ligne et en mode batch. Les opérateurs en mode batch rapporteront les temps juste pour eux-mêmes. Les opérateurs en mode ligne incluront un total cumulé jusqu'à ce point dans le plan, y compris tous enfants opérateurs. Pour être clair :les temps cumulés d'un opérateur en mode ligne incluent tout opérateur enfant en mode batch.
Nous l'avons vu précédemment dans le plan en mode batch parallèle :l'opérateur de flux de collecte final (mode ligne) avait un temps écoulé (cumulatif) affiché de 0,933 s, y compris tous ses opérateurs en mode batch enfants. Les autres opérateurs étaient tous en mode batch, et ont donc signalé les temps pour l'opérateur individuel seul.
Cette situation, où certains opérateurs de plan dans le même plan ont des temps cumulés et d'autres non, seront sans aucun doute considérés comme déroutants par de nombreuses personnes.
Exécution parallèle en mode ligne
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISALLOW_BATCH_MODE')
); Le plan d'exécution est :

Chaque opérateur est en mode ligne. La requête s'exécute pendant 4 677 ms avec 23 311 ms de temps CPU (somme de tous les threads).
En tant que plan exclusivement en mode ligne, nous nous attendrions à ce que tous les temps soient cumulatifs . En passant de l'enfant au parent (de droite à gauche), les temps devraient augmenter dans cette direction.
Regardons juste la section la plus à droite du plan :
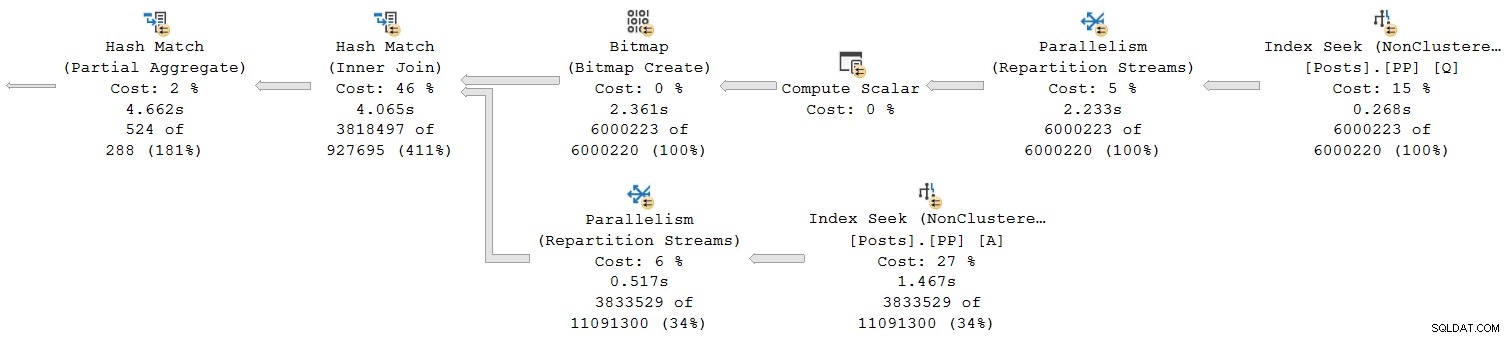
En travaillant de droite à gauche sur la rangée du haut, les temps cumulés semblent certainement être le cas. Mais il existe une exception sur l'entrée inférieure de la jointure de hachage :la recherche d'index a un temps écoulé de 1.467s , tandis que son parent les flux de répartition ont un temps écoulé de seulement 0.517s .
Comment un parent peut-il l'opérateur fonctionne moins de temps que son enfant si les temps écoulés sont cumulatifs dans les plans en mode ligne ?
Heures incohérentes
Il y a plusieurs parties à la réponse à ce puzzle. Prenons-le morceau par morceau, car c'est assez complexe :
Rappelons tout d'abord qu'un échange (opérateur de parallélisme) comporte deux parties. La main gauche (consommateur ) est connecté à un ensemble de threads exécutant des opérateurs dans la branche parallèle à gauche. Le bras droit (producteur ) de l'échange est connecté à un ensemble différent de threads exécutant des opérateurs dans la branche parallèle à droite.
Les lignes du côté producteur sont assemblées en paquets puis transférés du côté des consommateurs. Cela fournit un degré de tampon et contrôle de flux entre les deux ensembles de threads connectés. (Si vous avez besoin d'un rappel sur les échanges et les branches de plans parallèles, veuillez consulter mon article Plans d'exécution parallèles - Branches et fils.)
La portée des temps cumulés
En regardant la branche parallèle sur le producteur côté de l'échange :
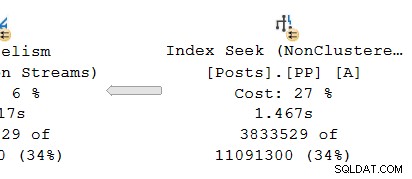
Comme d'habitude, les threads de travail supplémentaires DOP (degré de parallélisme) exécutent une série indépendante copie du plan des opérateurs de cette branche. Ainsi, au DOP 8, il y a 8 recherches d'index en série indépendantes coopérant pour effectuer la partie balayage de distance de l'opération de recherche d'index globale (parallèle). Chaque recherche à thread unique est connectée à une entrée (port) différente du côté producteur du partagé unique opérateur d'échange.
Une situation similaire existe sur le consommateur côté de l'échange. À DOP 8, il existe 8 copies distinctes à un seul thread de cette branche, toutes exécutées indépendamment :
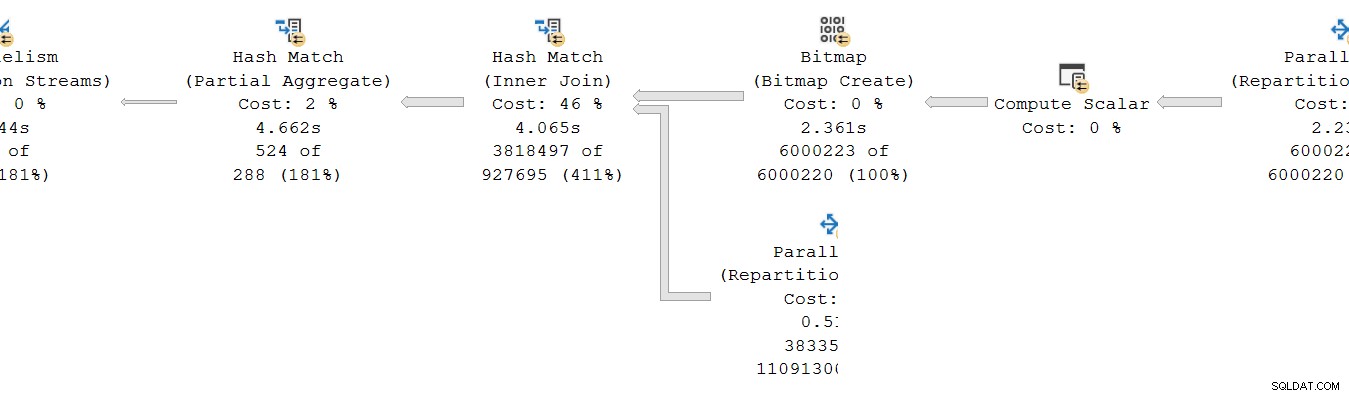
Chacun de ces sous-plans à thread unique s'exécute de la manière habituelle, chaque opérateur accumulant les totaux de temps écoulé et de temps CPU à chaque nœud. Étant des opérateurs en mode ligne, chaque total représente le temps passé le total cumulé pour le nœud actuel et chacun de ses enfants.
Le point crucial est que les totaux cumulés inclure uniquement les opérateurs sur le même thread et uniquement dans la branche actuelle . Espérons que cela ait un sens intuitif, car chaque fil n'a aucune idée de ce qui pourrait se passer ailleurs.
Comment les métriques en mode ligne sont collectées
La deuxième partie du puzzle concerne la manière dont le nombre de lignes et les métriques de synchronisation sont collectées dans les plans en mode ligne. Lorsque des informations de plan d'exécution ("réelles") sont requises, le moteur d'exécution ajoute un élément invisible opérateur de profilage à immédiatement à gauche (parent) de chaque opérateur du plan qui sera exécuté lors de l'exécution.
Cet opérateur peut enregistrer (entre autres choses) la différence entre l'heure à laquelle il a passé le contrôle à son opérateur enfant et l'heure à laquelle le contrôle a été rendu. Cette différence de temps représente le temps écoulé pour l'opérateur surveillé et tous ses enfants , puisque l'enfant appelle son propre enfant par ligne et ainsi de suite. Un opérateur peut être appelé plusieurs fois (pour initialiser, puis une fois par ligne, enfin pour fermer) donc le temps collecté par l'opérateur de profilage est un cumul sur potentiellement de nombreuses itérations par ligne.
Pour plus de détails sur les données de profilage collectées à l'aide de différentes méthodes de capture, consultez la documentation produit relative à l'infrastructure de profilage des requêtes. Pour ceux que cela intéresse, le nom de l'opérateur de profilage invisible utilisé par l'infrastructure standard est sqlmin!CQScanProfileNew . Comme tous les itérateurs en mode ligne, il a Open , GetRow , et Close méthodes, entre autres. Chaque méthode contient des appels au QueryPerformanceCounter de Windows API pour collecter la valeur actuelle du minuteur haute résolution.
Étant donné que l'opérateur de profilage est à gauche de l'opérateur cible, il ne mesure que le consommateur côté de l'échange. Il n'y a aucun opérateur de profilage pour le producteur côté de l'échange (malheureusement). S'il y en avait, il correspondrait ou dépasserait le temps écoulé indiqué sur la recherche d'index, car la recherche d'index et le côté producteur exécutent le même ensemble de threads et le côté producteur de l'échange est l'opérateur parent de la recherche d'index.
Temps revisité

Cela dit, vous pouvez toujours avoir des problèmes avec les horaires indiqués ci-dessus. Comment une recherche d'index peut-elle prendre 1.467s pour transmettre des lignes au côté producteur d'un échange, mais le côté consommateur ne prend que 0,517 s pour les recevoir ? Indépendamment des threads séparés, de la mise en mémoire tampon et ainsi de suite, sûrement l'échange devrait-il durer (de bout en bout) plus longtemps que la recherche ?
Eh bien, oui, mais c'est une mesure différente à partir du temps écoulé ou CPU. Soyons précis sur ce que nous mesurons ici.
Pour le mode ligne temps écoulé , imaginez un chronomètre par thread chez chaque opérateur. Le chronomètre démarre lorsque SQL Server entre le code d'un opérateur à partir de son parent et s'arrête (mais ne se réinitialise pas) lorsque ce code quitte l'opérateur pour rendre le contrôle au parent (pas à un enfant). Le temps écoulé inclut les attentes ou les retards de planification - aucun de ceux-ci n'arrête la montre.
Pour le temps CPU en mode ligne , imaginez le même chronomètre avec les mêmes caractéristiques, sauf qu'il s'arrête pendant les attentes et les retards de planification. Il n'accumule du temps que lorsque l'opérateur ou l'un de ses enfants s'exécute activement sur un planificateur (CPU). Le temps total sur un chronomètre par thread et par opérateur est constitué d'un cycle start-stop pour chaque ligne.
Appliquons cela à la situation actuelle avec le côté consommateur de l'échange et la recherche d'index :
N'oubliez pas que le côté consommateur de l'échange et la recherche d'index se trouvent dans des branches distinctes, ils s'exécutent donc sur des threads distincts . Le côté consommateur n'a pas d'enfant dans le même thread. La recherche d'index a le côté producteur de l'échange comme parent du même fil, mais nous n'avons pas de chronomètre là-bas.
Chaque thread consommateur démarre sa montre lorsque son opérateur parent (le côté sonde de la jointure de hachage) passe le contrôle (par exemple pour récupérer une ligne). La montre continue de fonctionner pendant que le consommateur récupère une ligne du paquet d'échange actuel. La montre s'arrête lorsque le contrôle quitte le consommateur et revient du côté de la sonde de jointure de hachage. D'autres parents (l'agrégat partiel et son échange parent) travailleront également sur cette ligne (et pourraient attendre) avant que le contrôle ne revienne du côté consommateur de notre échange pour récupérer la ligne suivante. À ce stade, le côté consommateur de notre échange recommence à accumuler le temps écoulé et le temps CPU.
Pendant ce temps, indépendamment de ce que les threads de branche côté consommateur pourraient faire, la recherche d'index les threads continuent de localiser des lignes dans l'index et de les alimenter dans l'échange. Un thread de recherche d'index démarre son chronomètre lorsque le côté producteur de l'échange lui demande une ligne. Le chronomètre est mis en pause lorsque la ligne est passée à l'échange. Lorsque l'échange demande la ligne suivante, le chronomètre de recherche d'index reprend.
Notez que le côté producteur de l'échange peut rencontrer CXPACKET attend que les tampons d'échange se remplissent, mais cela n'ajoutera pas aux temps écoulés enregistrés lors de la recherche d'index car son chronomètre ne fonctionne pas lorsque cela se produit. Si nous avions un chronomètre pour le côté producteur de l'échange, le temps écoulé manquant y serait affiché.
Pour se rapprocher visuellement d'un résumé de la situation, le diagramme suivant montre quand chaque opérateur accumule le temps écoulé dans les deux branches parallèles :
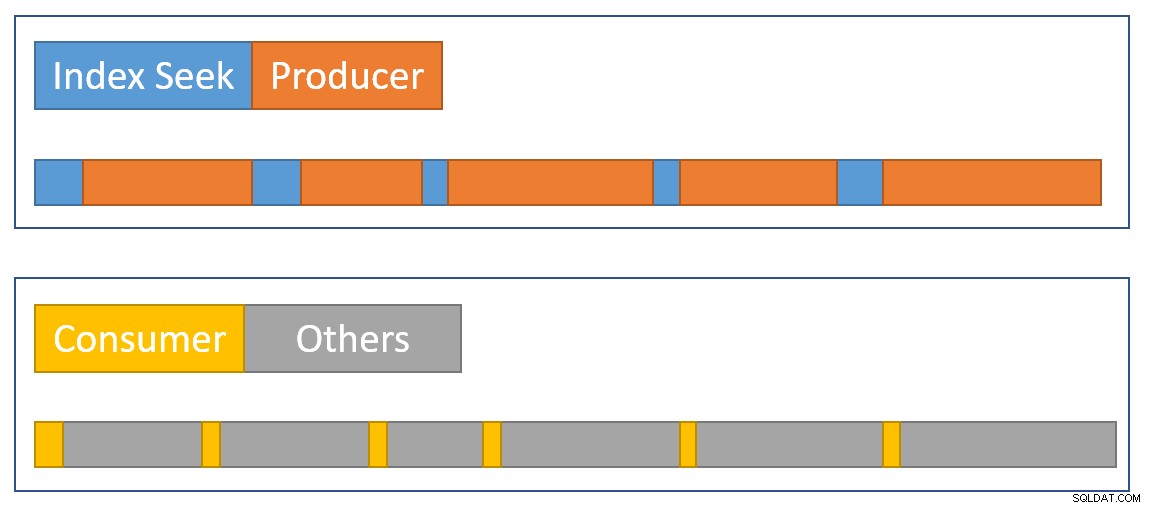
Le bleu Les barres de temps de recherche d'index sont courtes car la récupération d'une ligne à partir d'un index est rapide. L'orange les délais de production peuvent être longs à cause de CXPACKET attend. Le jaune les temps de consommation sont courts car il est rapide de récupérer une ligne de l'échange lorsque les données sont disponibles. Le gris les segments de temps représentent le temps utilisé par les autres opérateurs (côté sonde de jointure de hachage, agrégat partiel et son côté producteur d'échange parent) au-dessus du côté consommateur de l'échange.
Nous nous attendons à ce que les paquets d'échange soient remplis rapidement par la recherche d'index, mais vidé lentement (relativement parlant) par les opérateurs côté consommateur parce qu'ils ont plus de travail à faire. Cela signifie que les paquets dans l'échange seront généralement pleins ou presque pleins. Le consommateur pourra récupérer rapidement une ligne en attente, mais le producteur devra peut-être attendre que l'espace de paquet apparaisse.
Il est dommage que nous ne puissions pas voir les temps écoulés du côté producteur de l'échange. J'ai longtemps été d'avis qu'un échange devrait être représenté par deux différents opérateurs dans les plans d'exécution. Cela rendrait CXPACKET difficile /CXCONSUMER analyse d'attente beaucoup moins nécessaire et plans d'exécution beaucoup plus faciles à comprendre. L'opérateur producteur d'échange aurait naturellement son propre opérateur de profilage.
Conceptions alternatives
Il existe de nombreuses façons pour SQL Server d'obtenir des résultats cumulatifs cohérents le temps écoulé et le temps CPU sur les branches parallèles en principe . Au lieu de profiler les opérateurs, chaque ligne pouvait contenir des informations sur le temps écoulé et le temps CPU qu'elle avait accumulé jusqu'à présent au cours de son parcours dans le plan. Avec l'historique associé à chaque ligne, peu importe la manière dont les échanges redistribuent les lignes entre les threads, etc.
Ce n'est pas ainsi que le produit a été conçu, donc ce n'est pas ce que nous avons (et cela pourrait être inefficace de toute façon). Pour être juste, la conception originale du mode ligne ne concernait que des éléments tels que la collecte du nombre réel de lignes et le nombre d'itérations à chaque opérateur. L'ajout du temps écoulé par opérateur aux plans était une fonctionnalité très demandée , mais ce n'était pas facile à intégrer dans le cadre existant.
Lorsque le traitement en mode batch a été ajouté au produit, une approche différente (synchronisation pour l'opérateur actuel uniquement) a pu être mise en œuvre dans le cadre du développement d'origine sans rien casser. Encore une fois, en principe , les opérateurs en mode ligne auraient pu être modifiés pour fonctionner de la même manière que les opérateurs en mode batch, mais cela aurait nécessité beaucoup de travail de réingénierie de chaque opérateur en mode ligne existant. L'ajout d'un nouveau point de données aux opérateurs de profilage en mode ligne existants était beaucoup plus facile. Compte tenu des ressources d'ingénierie limitées et d'une longue liste d'améliorations de produits souhaitées, des compromis comme celui-ci doivent souvent être faits.
Le deuxième problème
Une autre incohérence temporelle cumulative se produit dans le plan actuel sur le côté gauche :

À première vue, cela semble être le même problème :l'agrégat partiel a un temps écoulé de 4,662 s , mais l'échange ci-dessus ne dure que 2.844s . Les mêmes mécanismes de base qu'auparavant sont bien sûr en jeu, mais il y a un autre facteur important. Un indice réside dans les temps étrangement égaux signalés pour l'échange d'agrégation, de tri et de répartition des flux.
Vous souvenez-vous des "ajustements de timing" que j'ai mentionnés dans l'introduction ? C'est là qu'ils entrent en jeu. Examinons les temps écoulés individuels pour les threads du côté consommateur de l'échange de flux de répartition :
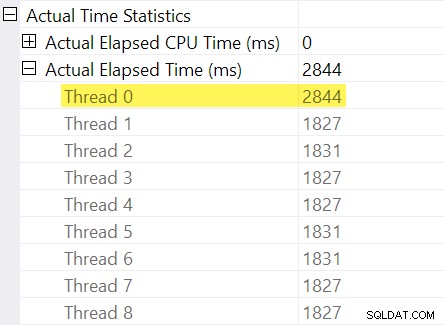
Rappelez-vous que les plans indiquent le temps écoulé pour un opérateur parallèle comme le maximum des temps par thread. Les 8 threads avaient un temps écoulé d'environ 1 830 ms, mais il existe une entrée supplémentaire pour "Thread 0" avec 2 844 ms. En effet chaque opérateur dans cette branche parallèle (le consommateur d'échange, le tri et l'agrégat de flux) ont le même Contribution de 2 844 ms à partir de « Thread 0 ».
Le thread zéro (c'est-à-dire la tâche parent ou le coordinateur) n'exécute directement les opérateurs qu'à gauche de l'opérateur de flux de collecte final. Pourquoi y a-t-il du travail qui lui est assigné ici, dans une branche parallèle ?
Explication
Ce problème peut se produire lorsqu'il existe un opérateur bloquant dans la branche parallèle ci-dessous (à droite de) l'actuel. Sans cet ajustement, les opérateurs de la branche actuelle sous-déclareraient le temps écoulé par le temps nécessaire pour ouvrir la branche enfant (il y a compliqué raisons architecturales).
SQL Server cherche à en tenir compte en enregistrant le délai de la branche enfant au niveau de l'échange dans l'opérateur de profilage invisible. La valeur de temps est enregistrée par rapport à la tâche parent ("Thread 0") dans la différence entre son premier actif et dernier actif fois. (Cela peut sembler étrange d'enregistrer le nombre de cette manière, mais au moment où le nombre doit être enregistré, les threads de travail parallèles supplémentaires n'ont pas encore été créés).
Dans le cas actuel, le ajustement de 2 844 ms survient principalement en raison du temps nécessaire à la jointure de hachage pour construire sa table de hachage. (Notez que ce temps est différent du total temps d'exécution de la jointure par hachage, qui inclut le temps nécessaire pour traiter le côté sonde de la jointure).
Le besoin d'un ajustement survient parce qu'une jointure de hachage bloque sur son entrée de construction. (Fait intéressant, le hachage agrégat partiel dans le plan n'est pas considéré comme bloquant dans ce contexte car il ne se voit attribuer qu'une quantité minimale de mémoire, ne déborde jamais sur tempdb , et arrête simplement l'agrégation s'il manque de mémoire (revenant ainsi à un mode de diffusion). Craig Freedman l'explique dans son article, Partial Aggregation).
Étant donné que l'ajustement du temps écoulé représente un délai d'initialisation dans la branche enfant, SQL Server devrait pour traiter la valeur "Thread 0" comme un décalage pour les nombres de temps écoulé mesurés par thread dans la branche actuelle. Prendre le maximum de tous les threads car le temps écoulé est raisonnable en général, car les threads ont tendance à démarrer en même temps. Ce n'est pas logique de le faire lorsque l'une des valeurs de thread est un décalage pour toutes les autres valeurs !
Nous pouvons effectuer le calcul correct du décalage manuellement en utilisant les données disponibles dans le plan. Du côté consommateur de l'échange, nous avons :
Le temps écoulé maximal entre les threads de travail supplémentaires est de 1 831 ms (à l'exclusion de la valeur de décalage stockée dans "Thread 0"). Ajout du décalage de 2 844 ms donne un total de 4 675 ms .
Dans tout plan où les temps par thread sont inférieurs que le décalage, l'opérateur va incorrectement affiche le décalage comme le temps total écoulé. Cela est susceptible de se produire lorsque le premier opérateur de blocage est lent (peut-être un tri ou un agrégat global sur un grand ensemble de données) et que les derniers opérateurs de branche prennent moins de temps.
Revisiter cette partie du plan :
Remplacement du décalage de 2 844 ms attribué par erreur aux flux de répartition, au tri et aux opérateurs d'agrégation de flux par nos 4 675 ms calculés place leurs temps écoulés cumulés entre les 4 662 ms au niveau de l'agrégat partiel et les 4 676 ms lors des flux de rassemblement finaux. (Le tri et l'agrégat fonctionnent sur un nombre infime de lignes, de sorte que leurs calculs de temps écoulé sont identiques au tri, mais en général, ils seraient souvent différents) :

Tous les opérateurs du fragment de plan ci-dessus ont 0 ms de temps CPU écoulé sur tous les threads (à l'exception de l'agrégat partiel, qui a 14 891 ms). Le plan avec nos chiffres calculés a donc bien plus de sens que celui affiché :
- 4 675 ms – 4 662 ms =13 ms elapsed est un nombre beaucoup plus raisonnable pour le temps consommé par les flux de répartition seuls . Cet opérateur ne consomme pas de temps CPU et ne traite que 524 lignes.
- 0 ms écoulé (à une résolution en millisecondes) est raisonnable pour le petit agrégat de tri et de flux (encore une fois, à l'exclusion de leurs enfants).
- 4 676 ms – 4 675 ms =1 ms semble bon pour les flux de collecte finaux de collecter 66 lignes sur le thread de tâche parent pour les renvoyer au client.
Mis à part l'incohérence évidente dans le plan donné entre l'agrégat partiel (4 662 ms) et les flux de répartition (2 844 ms), il est déraisonnable de penser que les flux de regroupement finaux de 66 lignes pourraient être responsables de 4 676 ms - 2 844 ms = 1 832 ms du temps écoulé. Le nombre corrigé (1 ms) est beaucoup plus précis et n'induira pas les utilisateurs en erreur.
Maintenant, même si ce calcul de décalage a été effectué correctement, les plans en mode de rangées parallèles pourraient ne pas montrent des temps cumulés cohérents dans tous les cas, pour les raisons évoquées précédemment. Atteindre une cohérence complète peut être difficile, voire impossible, sans modifications majeures de l'architecture.
Pour anticiper une question qui pourrait se poser à ce stade :non, l'analyse précédente de l'échange et de la recherche d'index n'impliquait pas d'erreur de calcul de décalage "Thread 0". Il n'y a pas d'opérateur de blocage en dessous de cet échange, donc aucun délai d'initialisation ne se produit.
Un dernier exemple
Cet exemple de requête suivant utilise la même base de données et le même index qu'auparavant. Je ne l'explorerai pas trop en détail car il ne sert qu'à développer des points que j'ai déjà soulevés, pour le lecteur intéressé.
Les fonctionnalités de cette démo sont :
- Sans
ORDER GROUPindice, il montre comment un agrégat partiel n'est pas considéré comme un opérateur de blocage, donc aucun ajustement "Thread 0" n'intervient lors de l'échange des flux de répartition. Les temps écoulés sont cohérents. - Avec l'astuce, des tris bloquants sont introduits à la place d'un agrégat partiel de hachage. Deux différents Des ajustements "Thread 0" apparaissent aux deux échanges de repartitionnement. Les temps écoulés sont incohérents sur les deux branches, de différentes manières.
Requête :
SELECT * FROM
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 1
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C1
JOIN
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 2
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C2
ON C2.yr = C1.yr
AND C2.mth = C1.mth
ORDER BY
C1.yr ASC,
C1.mth ASC
OPTION
(
--ORDER GROUP,
USE HINT ('DISALLOW_BATCH_MODE')
);
Plan d'exécution sans ORDER GROUP (pas d'ajustement, temps cohérents) :

Plan d'exécution avec ORDER GROUP (deux ajustements différents, horaires incohérents) :

Résumé et conclusions
Rapport des opérateurs de plan en mode ligne cumulatif times inclusive of all child operators in the same thread. Batch mode operators record the time used inside that operator alone .
A single plan can include both row and batch mode operators; the row mode operators will record cumulative elapsed time, including any batch operators. Correctly interpreting elapsed times in mixed-mode plans can be challenging.
For parallel plans, total CPU time for an operator is the sum of individual thread contributions. Total elapsed time is the maximum of the per-thread numbers.
Row mode actual plans include an invisible profiling operator to the immediate left (parent) of executing visible operators to collect runtime statistics like total row count, number of iterations, and timings. Because the row mode profiling operator is a parent of the target operator, it captures activity for that operator and all children (but only in the same thread).
Exchanges are row mode operators. There is no separate hidden profiling operator for the producer side, so exchanges only show details and timings for the consumer side . The consumer side has no children in the same thread so it reports timings for itself only.
Long elapsed times on an exchange with low CPU usage generally mean the consumer side has to wait for rows (CXCONSUMER ). This is often caused by a slow producer side (with various root causes). For an example of that with a super investigation, see CXCONSUMER As a Sign of Slow Parallel Joins by Josh Darneli.
Batch mode operators do not use separate profiling operators. The batch mode operator itself contains code to record timing on every entry and exit (e.g. per batch). Passing control to a child operator counts as an exit . This is why batch mode operators record only their own activity (exclusive of their child operators).
Internal architectural details mean the way parallel row mode plans start up would cause elapsed times to be under-reported for operators in a parallel branch when a child parallel branch contains a blocking operator. An attempt is made to adjust for the timing offset caused by this, but the implementation appears to be incomplete, resulting in inconsistent and potentially misleading elapsed times. Multiple separate adjustments may be present in a single execution plan. Adjustments may accumulate when multiple branches contain blocking operators, and a single operator may combine more than one adjustment (e.g. merge join with an adjustment on each input).
Without the attempted adjustments, parallel row-mode plans would only show consistent elapsed times within a branch (i.e. between parallelism operators). This would not be ideal, but it would arguably be better than the current situation. As it is, we simply cannot trust elapsed times in parallel row-mode plans to be a true reflection of reality.
Look out for “Thread 0” elapsed times on exchanges, and the associated branch plan operators. These will sometimes show up as implausibly identical times for operators within that branch. You may need to manually add the offset to the maximum per-thread times for each affected operator to get sensible results.
The same adjustment mechanism exists for CPU times , but it appears non-functional at the moment. Unfortunately, this means you should not expect CPU times to be cumulative across branches in row mode parallel plans. This is somewhat ironic because it does make sense to sum CPU times (including the “Thread 0” value). I doubt many people rely on cumulative CPU times in execution plans though.
With any luck, these calculations will be improved in a future product update, if the required corrective work is not too onerous.
In the meantime, this all represents another reason to prefer batch mode plans when dealing with even moderately large numbers of rows. Performance will usually be improved, and the timing numbers will make more sense. Remember, SQL Server 2019 makes batch mode processing easier to achieve in practice because it does not require a columnstore index.