Auteur invité :Derik Hammer (@SQLHammer)
Récemment, Aaron Bertrand a publié un blog sur les mythes nuisibles et omniprésents sur les performances de SQL Server. Dans le prolongement de cette série de blogs, je vais réfuter ce mythe courant :
Lire le manuel
En allant directement à la source, j'ai regardé l'article de Books Online sur les tables qui inclut des variables de table. Même si l'article fait référence aux avantages de l'utilisation de variables de table, le fait qu'elles soient 100 % en mémoire est manifestement absent.
Un affirmatif manquant n'implique pas un négatif, cependant. Depuis la publication des tables OLTP en mémoire, il existe désormais beaucoup plus de documentation dans BOL pour le traitement en mémoire. C'est là que j'ai trouvé cet article sur l'accélération de la table temporaire et des variables de table en utilisant l'optimisation de la mémoire.
L'article entier tourne autour de la façon de faire en sorte que vos objets temporaires utilisent la fonctionnalité OLTP en mémoire, et c'est là que j'ai trouvé l'affirmative que je cherchais.
"Une variable de table traditionnelle représente une table dans la base de données tempdb. Pour des performances beaucoup plus rapides, vous pouvez optimiser la mémoire de votre variable de table."Les variables de table ne sont pas des constructions en mémoire. Afin d'utiliser la technologie en mémoire, vous devez définir explicitement un TYPE optimisé en mémoire et utiliser ce TYPE pour définir votre variable de table.
Prouvez-le
La documentation est une chose, mais la voir de mes propres yeux en est une autre. Je sais que les tables temporaires créent des objets dans tempdb et écriront des données sur le disque. Je vais d'abord vous montrer à quoi cela ressemble pour les tables temporaires, puis j'utiliserai la même méthode pour valider l'hypothèse selon laquelle les variables de table agissent de la même manière.
Analyse des enregistrements de journaux
Cette requête exécutera un CHECKPOINT pour me donner un point de départ propre, puis affichera le nombre d'enregistrements de journal et les noms de transaction qui existent dans le journal.
USE tempdb; GO CHECKPOINT; GO SELECT COUNT(*) [Count] FROM sys.fn_dblog (NULL, NULL); SELECT [Transaction Name] FROM sys.fn_dblog (NULL, NULL) WHERE [Transaction Name] IS NOT NULL;
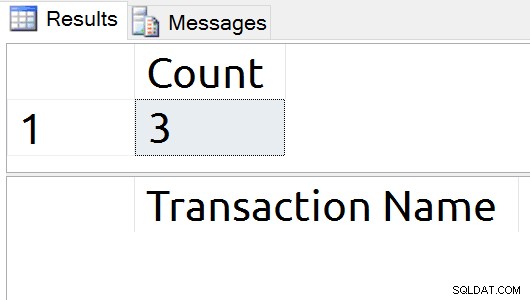
L'exécution répétée de T-SQL a entraîné un nombre cohérent de trois enregistrements sur SQL Server 2016 SP1.
Cela crée une table temporaire et affiche l'enregistrement de l'objet, prouvant qu'il s'agit d'un objet réel dans tempdb.
USE tempdb; GO DROP TABLE IF EXISTS #tmp; GO CREATE TABLE #tmp (id int NULL); SELECT name FROM sys.objects o WHERE is_ms_shipped = 0;

Maintenant, je vais afficher à nouveau les enregistrements du journal. Je ne relancerai pas la commande CHECKPOINT.
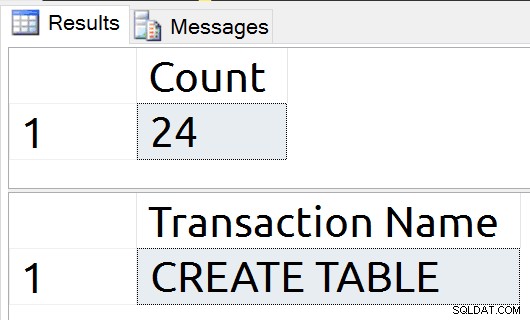
Vingt et un enregistrements de journal ont été écrits, prouvant qu'il s'agit d'écritures sur disque, et notre CREATE TABLE est clairement inclus dans ces enregistrements de journal.
Pour comparer ces résultats aux variables de table, je vais réinitialiser l'expérience en exécutant CHECKPOINT, puis en exécutant le T-SQL ci-dessous, en créant une variable de table.
USE tempdb; GO DECLARE @var TABLE (id int NULL); SELECT name FROM sys.objects o WHERE is_ms_shipped = 0;
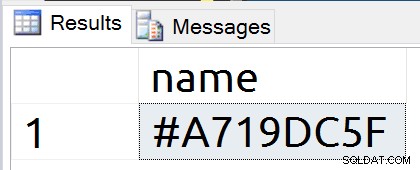
Une fois de plus, nous avons un nouvel enregistrement d'objet. Cette fois, cependant, le nom est plus aléatoire qu'avec les tables temporaires.
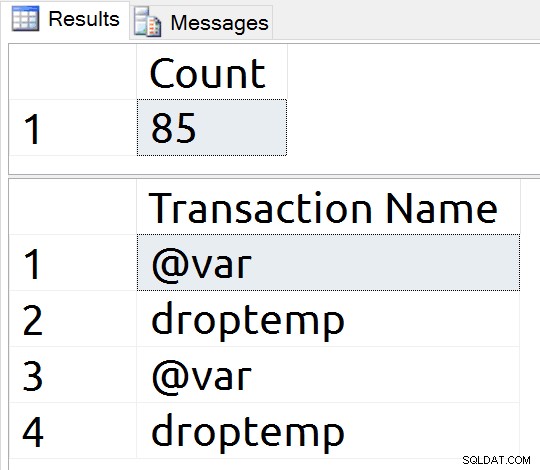
Il y a quatre-vingt-deux nouveaux enregistrements de journal et noms de transaction prouvant que ma variable est écrite dans le journal, et donc sur le disque.
En réalité en mémoire
Il est maintenant temps pour moi de faire disparaître les enregistrements du journal.
J'ai créé un groupe de fichiers OLTP en mémoire, puis créé un type de table à mémoire optimisée.
USE Test; GO CREATE TYPE dbo.inMemoryTableType AS TABLE ( id INT NULL INDEX ix1 ) WITH (MEMORY_OPTIMIZED = ON); GO
J'ai exécuté à nouveau le CHECKPOINT, puis j'ai créé la table optimisée en mémoire.
USE Test; GO DECLARE @var dbo.inMemoryTableType; INSERT INTO @var (id) VALUES (1) SELECT * from @var; GO
Après avoir examiné le journal, je n'ai vu aucune activité de journal. Cette méthode est en fait 100 % en mémoire.
À emporter
Les variables de table utilisent tempdb de la même manière que les tables temporaires utilisent tempdb. Les variables de table ne sont pas des constructions en mémoire mais peuvent le devenir si vous utilisez des types de table définis par l'utilisateur optimisés en mémoire. Souvent, je trouve que les tables temporaires sont un bien meilleur choix que les variables de table. La raison principale en est que les variables de table n'ont pas de statistiques et, selon la version et les paramètres de SQL Server, les estimations de ligne s'élèvent à 1 ligne ou 100 lignes. Dans les deux cas, ce sont des suppositions et deviennent des éléments de désinformation préjudiciables dans votre processus d'optimisation des requêtes.
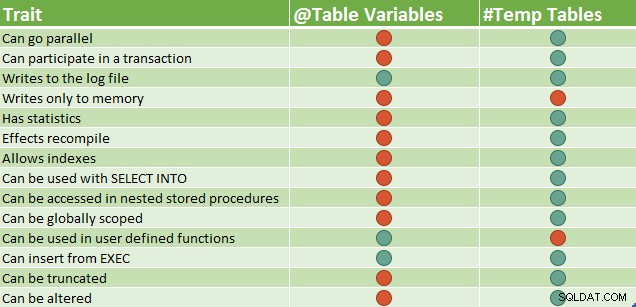
Notez que certaines de ces différences de fonctionnalités peuvent changer au fil du temps. Par exemple, dans les versions récentes de SQL Server, vous pouvez créer des index supplémentaires sur une variable de table à l'aide de la syntaxe d'index en ligne. Le tableau suivant comporte trois index ; la clé primaire (cluster par défaut) et deux index non cluster :
DECLARE @t TABLE ( a int PRIMARY KEY, b int, INDEX x (b, a DESC), INDEX y (b DESC, a) );
Il y a une excellente réponse sur DBA Stack Exchange où Martin Smith détaille de manière exhaustive les différences entre les variables de table et les tables #temp :
- Quelle est la différence entre une table temporaire et une variable de table dans SQL Server ?
À propos de l'auteur
 Derik est un professionnel des données et un nouveau MVP Microsoft Data Platform qui se concentre sur SQL Server. Sa passion se concentre sur la haute disponibilité, la reprise après sinistre, l'intégration continue et la maintenance automatisée. Son expérience couvre l'administration de bases de données à long terme, le conseil et les entreprises entrepreneuriales travaillant dans les secteurs de la finance et de la santé. Il est actuellement administrateur principal de base de données en charge de l'équipe des opérations de base de données au siège mondial de Subway Franchise. Lorsqu'il n'est pas à l'heure ou qu'il ne blogue pas sur SQLHammer.com, Derik consacre son temps à la #sqlfamily en tant que chef de chapitre du groupe d'utilisateurs FairfieldPASS SQL Server à Stamford, CT.
Derik est un professionnel des données et un nouveau MVP Microsoft Data Platform qui se concentre sur SQL Server. Sa passion se concentre sur la haute disponibilité, la reprise après sinistre, l'intégration continue et la maintenance automatisée. Son expérience couvre l'administration de bases de données à long terme, le conseil et les entreprises entrepreneuriales travaillant dans les secteurs de la finance et de la santé. Il est actuellement administrateur principal de base de données en charge de l'équipe des opérations de base de données au siège mondial de Subway Franchise. Lorsqu'il n'est pas à l'heure ou qu'il ne blogue pas sur SQLHammer.com, Derik consacre son temps à la #sqlfamily en tant que chef de chapitre du groupe d'utilisateurs FairfieldPASS SQL Server à Stamford, CT.