Introduction
Atteindre une journalisation minimale en utilisant INSERT...SELECT dans un vide la cible d'index clusterisé n'est pas aussi simple que décrit dans le Guide de chargement des performances des données .
Ce message fournit de nouveaux détails sur les exigences de journalisation minimale lorsque la cible d'insertion est un index cluster traditionnel vide. (Le mot "traditionnel" ici exclut columnstore et mémoire optimisée ('Hekaton') tables groupées). Pour les conditions qui s'appliquent lorsque la table cible est un tas, consultez l'article précédent de cette série.
Résumé des tables groupées
Le Guide des performances de chargement des données contient un résumé de haut niveau des conditions requises pour la journalisation minimale dans des tables groupées :
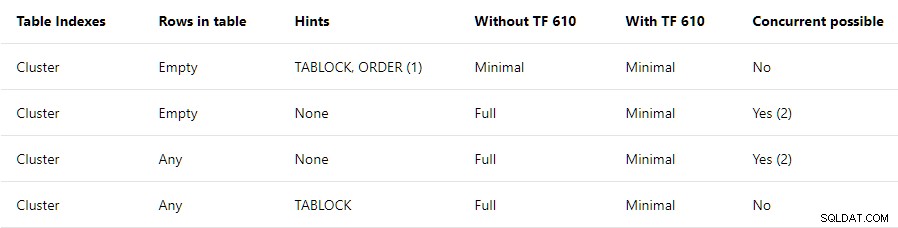
Ce message concerne la ligne du haut uniquement . Il indique que TABLOCK et ORDER des indices sont requis, avec une note indiquant :
Si vous utilisez BULK INSERT, l'indice de commande doit être utilisé.
Cible vide avec verrouillage de table
La ligne supérieure récapitulative suggère que tous les insertions dans un index cluster vide seront enregistrées au minimum tant que TABLOCK et ORDER des conseils sont spécifiés. Le TABLOCK un indice est requis pour activer le RowSetBulk installation telle qu'utilisée pour les chargements en vrac de table en tas. Une ORDER un indice est requis pour s'assurer que les lignes arrivent à l'insertion d'index cluster opérateur de plan dans l'index cible ordre des clés . Sans cette garantie, SQL Server pourrait ajouter des lignes d'index qui ne sont pas triées correctement, ce qui ne serait pas bon.
Contrairement aux autres méthodes de chargement en masse, il n'est pas possible pour spécifier le ORDER requis indice sur un INSERT...SELECT déclaration. Cet indice n'est pas le même en utilisant un ORDER BY clause sur INSERT...SELECT déclaration. Un ORDER BY clause sur un INSERT ne garantit que la façon dont toute identité les valeurs sont attribuées, pas l'ordre d'insertion des lignes.
Pour INSERT...SELECT , SQL Server prend sa propre décision s'il faut s'assurer que les lignes sont présentées à l'insertion d'index cluster opérateur dans l'ordre des clés ou non. Le résultat de cette évaluation est visible dans les plans d'exécution via le DMLRequestSort propriété de l'Insert opérateur. Le DMLRequestSort la propriété doit être défini sur true pour INSERT...SELECT dans un index pour être enregistré au minimum . Lorsqu'il est défini sur false , journalisation minimale ne peut pas se produire.
Avoir DMLRequestSort défini sur vrai est la seule garantie acceptable de l'ordre des entrées d'insertion pour SQL Server. On pourrait inspecter le plan d'exécution et prédire que les lignes devraient/arriveront/doivent arriver dans l'ordre de l'index clusterisé, mais sans les garanties internes spécifiques fourni par DMLRequestSort , cette évaluation ne compte pour rien.
Lorsque DMLRequestSort est vrai , SQL Server peut introduire un tri explicite opérateur dans le plan d'exécution. S'il peut garantir en interne la commande par d'autres moyens, le Trier peut être omis. Si des alternatives de tri et de non-tri sont disponibles, l'optimiseur effectuera un calcul basé sur les coûts choix. L'analyse des coûts ne tient pas compte de la journalisation minimale directement; il est motivé par les avantages attendus des E/S séquentielles et l'évitement du fractionnement des pages.
Conditions DMLRequestSort
Les deux tests suivants doivent réussir pour que SQL Server choisisse de définir DMLRequestSort à vrai lors de l'insertion dans un index cluster vide avec le verrouillage de table spécifié :
- Une estimation de plus de 250 lignes du côté entrée de l'insertion d'index cluster opérateur; et
- Une estimation taille des données de plus de 2 pages . La taille estimée des données n'est pas un nombre entier, donc un résultat de 2 001 pages remplirait cette condition.
(Cela peut vous rappeler les conditions de la journalisation minimale du tas , mais le besoin estimé la taille des données ici est de deux pages au lieu de huit.)
Calcul de la taille des données
La taille estimée des données le calcul ici est soumis aux mêmes bizarreries décrites dans l'article précédent pour les tas, sauf que le RID de 8 octets n'est pas présent.
Pour SQL Server 2012 et versions antérieures, cela signifie 5 octets supplémentaires par ligne sont inclus dans le calcul de la taille des données :un octet pour un bit interne flag, et quatre octets pour le uniquifier (utilisé dans le calcul même pour les index uniques, qui ne stockent pas d'uniquificateur ).
Pour SQL Server 2014 et versions ultérieures, l'uniquificateur est correctement omis pour unique index, mais un octet supplémentaire pour le bit interne l'indicateur est conservé.
Démo
Le script suivant doit être exécuté sur une instance SQL Server de développement dans une nouvelle base de données de test configuré pour utiliser le SIMPLE ou BULK_LOGGED modèle de récupération.
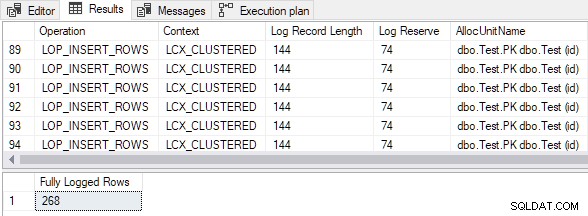
La démo charge 268 lignes dans une toute nouvelle table en cluster à l'aide de INSERT...SELECT avec TABLOCK , et des rapports sur les enregistrements du journal des transactions générés.
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (268)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
(Si vous exécutez le script sur SQL Server 2012 ou une version antérieure, modifiez le TOP clause dans le script de 268 à 252, pour des raisons qui seront expliquées dans un instant.)
La sortie montre que toutes les lignes insérées ont été entièrement enregistrées malgré le vide table cible en cluster et le TABLOCK indice :
Taille des données d'insertion calculée
Les propriétés du plan d'exécution de l'insertion d'index cluster l'opérateur montre que DMLRequestSort est défini sur false . En effet, bien que le nombre estimé de lignes à insérer soit supérieur à 250 (répondant à la première exigence), le calculé la taille des données pas dépasser deux pages de 8 Ko.
Les détails du calcul (pour SQL Server 2014 et versions ultérieures) sont les suivants :
- Total de longueur fixe taille de colonne =54 octets :
- Tapez l'identifiant 104
bit=1 octet (interne). - Tapez l'identifiant 56
integer=4 octets (idcolonne). - Tapez l'identifiant 56
integer=4 octets (c1colonne). - Tapez l'identifiant 175
char(45)=45 octets (paddingcolonne).
- Tapez l'identifiant 104
- Bitmap nul =3 octets .
- En-tête de ligne surcharge =4 octets .
- Taille de ligne calculée =54 + 3 + 4 =61 octets .
- Taille des données calculées = 61 octets x 268 lignes =16 348 octets .
- Pages de données calculées =16 384 / 8 192 =1,99560546875 .
La taille de ligne calculée (61 octets) diffère de la véritable taille de stockage de ligne (60 octets) par l'octet supplémentaire de métadonnées internes présent dans le flux d'insertion. Le calcul ne tient pas non plus compte des 96 octets utilisés sur chaque page par l'en-tête de page, ou d'autres éléments tels que la surcharge de version de ligne. Le même calcul sur SQL Server 2012 ajoute 4 octets supplémentaires par ligne pour l'uniquificateur (qui n'est pas présent dans les index uniques comme mentionné précédemment). Les octets supplémentaires signifient que moins de lignes doivent tenir sur chaque page :
- Taille de ligne calculée =61 + 4 =65 octets .
- Taille des données calculées = 65 octets x 252 lignes =16 380 octets
- Pages de données calculées =16 380 / 8 192 =1,99951171875 .
Modification du TOP la clause de 268 lignes à 269 (ou de 252 à 253 pour 2012) rend le calcul de la taille de données attendue juste pourboire au-delà du seuil minimum de 2 pages :
- SQL Server 2014
- 61 octets x 269 lignes =16 409 octets.
- 16 409 / 8192 =2,0030517578125 pages.
- SQL Server 2012
- 65 octets x 253 lignes =16 445 octets.
- 16 445 / 8192 =2,0074462890625 pages.
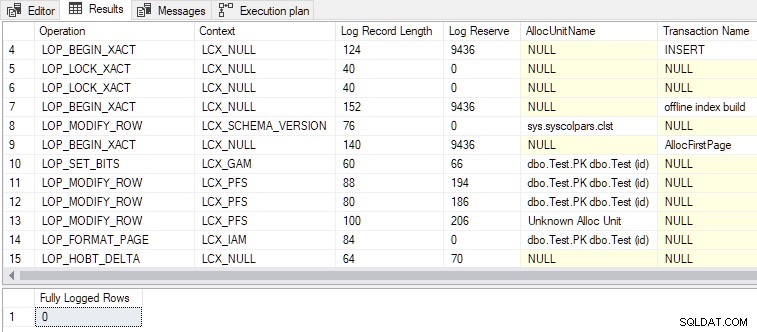
La deuxième condition étant désormais également satisfaite, DMLRequestSort est défini sur true , et journalisation minimale est atteint, comme indiqué dans la sortie ci-dessous :
Quelques autres points d'intérêt :
- Au total, 79 enregistrements de journal sont générés, contre 328 pour la version entièrement enregistrée. Moins d'enregistrements de journal sont le résultat attendu d'une journalisation minimale.
- Le
LOP_BEGIN_XACTenregistrements dans le journalisé au minimum les enregistrements réservent une quantité relativement importante d'espace de journalisation (9 436 octets chacun). - L'un des noms de transaction répertoriés dans les enregistrements du journal est "création d'index hors ligne" . Bien que nous n'ayons pas demandé la création d'un index en tant que tel, le chargement en bloc de lignes dans un index vide est essentiellement la même opération.
- Le entièrement connecté insert prend un verrou exclusif au niveau de la table (
Tab-X), tandis que le minimum de journalisation insert prend la modification du schéma (Sch-M) tout comme le fait une "vraie" construction d'index hors ligne. - Charger en bloc une table en cluster vide à l'aide de
INSERT...SELECTavecTABLOCKetDMRequestSortdéfini sur vrai utilise leRowsetBulkmécanisme, tout comme le mécanisme minimalement connecté charges de tas dans l'article précédent.
Estimations de cardinalité
Faites attention aux estimations de faible cardinalité à l'insertion d'index cluster opérateur. Si l'un des seuils requis pour définir DMLRequestSort à vrai n'est pas atteint en raison d'une estimation de cardinalité inexacte, l'insertion sera entièrement enregistrée , quel que soit le nombre réel de lignes et la taille totale des données rencontrées au moment de l'exécution.
Par exemple, changer le TOP clause dans le script de démonstration pour utiliser une variable donne une cardinalité fixe suppose de 100 lignes, ce qui est inférieur au minimum de 251 lignes :
-- Insert rows
DECLARE @NumRows bigint = 269;
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (@NumRows)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV; Mise en cache du plan
Le DMLRequestSort la propriété est enregistrée dans le cadre du plan mis en cache. Lorsqu'un plan mis en cache est réutilisé , la valeur de DMLRequestSort n'est pas recalculé au moment de l'exécution, à moins qu'une recompilation ne se produise. Notez que les recompilations ne se produisent pas pour TRIVIAL plans basés sur les changements de statistiques ou de cardinalité de table.
Une façon d'éviter tout comportement inattendu dû à la mise en cache consiste à utiliser une OPTION (RECOMPILE) indice. Cela garantira le paramètre approprié pour DMLRequestSort est recalculé, au prix d'une compilation à chaque exécution.
Indicateur de suivi
Il est possible de forcer DMLRequestSort être défini sur true en définissant non documenté et non pris en charge trace flag 2332, comme je l'ai écrit dans Optimisation des requêtes T-SQL qui modifient les données. Malheureusement, cela n'est pas affecter la journalisation minimale éligibilité pour les tableaux groupés vides — l'encart doit toujours être estimé à plus de 250 lignes et 2 pages. Cet indicateur de trace affecte les autres journalisation minimale scénarios, qui sont couverts dans la dernière partie de cette série.
Résumé
Chargement en masse d'un élément vide index clusterisé utilisant INSERT...SELECT réutilise le RowsetBulk mécanisme utilisé pour charger en bloc les tables de tas. Cela nécessite un verrouillage de table (normalement réalisé avec un TABLOCK indice) et un ORDER indice. Il n'y a aucun moyen d'ajouter un ORDER allusion à un INSERT...SELECT déclaration. Par conséquent, atteindre une journalisation minimale dans une table en cluster vide nécessite que le DMLRequestSort propriété de l'insertion d'index cluster l'opérateur est défini sur true . Cela garantit à SQL Server que les lignes présentées à l'Insert l'opérateur arrivera dans l'ordre des clés d'index cible. L'effet est le même que lors de l'utilisation de ORDER indice disponible pour d'autres méthodes d'insertion en bloc comme BULK INSERT et bcp .
Dans l'ordre de DMLRequestSort être défini sur true , il doit y avoir :
- Plus de 250 lignes estimé à insérer ; et
- Une estimation insérer une taille de données de plus de deux pages .
L'estimation insérer le calcul de la taille des données ne le fait pas correspondre au résultat de la multiplication du plan d'exécution nombre estimé de lignes et taille de ligne estimée propriétés à l'entrée de l'Insert opérateur. Le calcul interne inclut (incorrectement) une ou plusieurs colonnes internes dans le flux d'insertion, qui ne sont pas conservées dans l'index final. Le calcul interne ne tient pas non plus compte des en-têtes de page ou d'autres frais généraux tels que la gestion des versions de ligne.
Lors du test ou du débogage de la journalisation minimale problèmes, méfiez-vous des estimations de faible cardinalité et rappelez-vous que le paramètre de DMLRequestSort est mis en cache dans le cadre du plan d'exécution.
La dernière partie de cette série détaille les conditions requises pour atteindre une exploitation forestière minimale sans utiliser le RowsetBulk mécanisme. Celles-ci correspondent directement aux nouvelles fonctionnalités ajoutées sous l'indicateur de trace 610 à SQL Server 2008, puis modifiées pour être activées par défaut à partir de SQL Server 2016.