J'ai récemment eu de nombreuses conversations sur les types de charges de travail, en particulier pour savoir si une charge de travail est paramétrée, ad hoc ou mixte. C'est l'une des choses que nous examinons lors d'un audit de santé, et Kimberly a une excellente requête à partir de son cache Plan et de l'optimisation pour les charges de travail ad hoc qui font partie de notre boîte à outils. J'ai copié la requête ci-dessous, et si vous ne l'avez jamais exécutée sur l'un de vos environnements de production auparavant, trouvez certainement du temps pour le faire.
SELECT objtype AS [CacheType],
COUNT_BIG(*) AS [Total Plans],
SUM(CAST(size_in_bytes AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs],
AVG(usecounts) AS [Avg Use Count],
SUM(CAST((CASE WHEN usecounts = 1 THEN size_in_bytes
ELSE 0
END) AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs – USE Count 1],
SUM(CASE WHEN usecounts = 1 THEN 1
ELSE 0
END) AS [Total Plans – USE Count 1]
FROM sys.dm_exec_cached_plans
GROUP BY objtype
ORDER BY [Total MBs – USE Count 1] DESC; Si j'exécute cette requête dans un environnement de production, nous pourrions obtenir une sortie comme celle-ci :
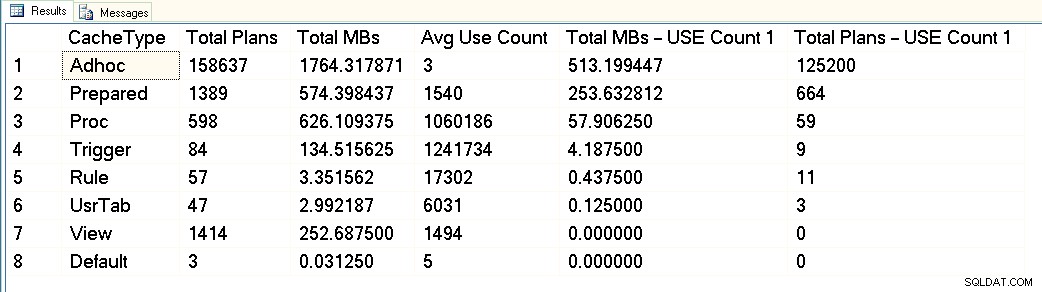
À partir de cette capture d'écran, vous pouvez voir que nous avons environ 3 Go au total dédiés au cache du plan, et que 1,7 Go sont destinés aux plans de plus de 158 000 requêtes ad hoc. Sur ces 1,7 Go, environ 500 Mo sont utilisés pour 125 000 plans qui exécutent ONE temps seulement. Environ 1 Go du cache de plan est destiné aux plans préparés et de procédure, et ils n'occupent qu'environ 300 Mo d'espace. Mais notez le nombre moyen d'utilisations - bien plus d'un million pour les procédures. En examinant ce résultat, je classerais cette charge de travail comme mixte :certaines requêtes paramétrées, d'autres ad hoc.
Le billet de blog de Kimberly traite des options de gestion d'un cache de plan rempli de nombreuses requêtes ad hoc. Le gonflement du cache du plan n'est qu'un problème auquel vous devez faire face lorsque vous avez une charge de travail ad hoc, et dans cet article, je souhaite explorer l'effet qu'il peut avoir sur le processeur en raison de toutes les compilations qui doivent se produire. Lorsqu'une requête s'exécute dans SQL Server, elle passe par la compilation et l'optimisation, et il y a une surcharge associée à ce processus, qui se manifeste fréquemment par un coût CPU. Une fois qu'un plan de requête est en cache, il peut être réutilisé. Les requêtes paramétrées peuvent finir par réutiliser un plan déjà en cache, car le texte de la requête est exactement le même. Lorsqu'une requête ad hoc s'exécute, elle ne réutilisera le plan en cache que si elle a le exact même texte et valeur(s) d'entrée .
Configuration
Pour nos tests, nous allons générer une chaîne aléatoire dans TSQL et la concaténer à une requête afin que chaque exécution ait une valeur littérale différente. J'ai enveloppé cela dans une procédure stockée qui appelle la requête à l'aide de Dynamic String Execution (EXEC @QueryString), de sorte qu'elle se comporte comme une instruction ad hoc. L'appeler depuis une procédure stockée signifie que nous pouvons l'exécuter un nombre connu de fois.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DBCC FREEPROCCACHE;
GO
EXEC dbo.[RandomSelects] @NumRows = 10;
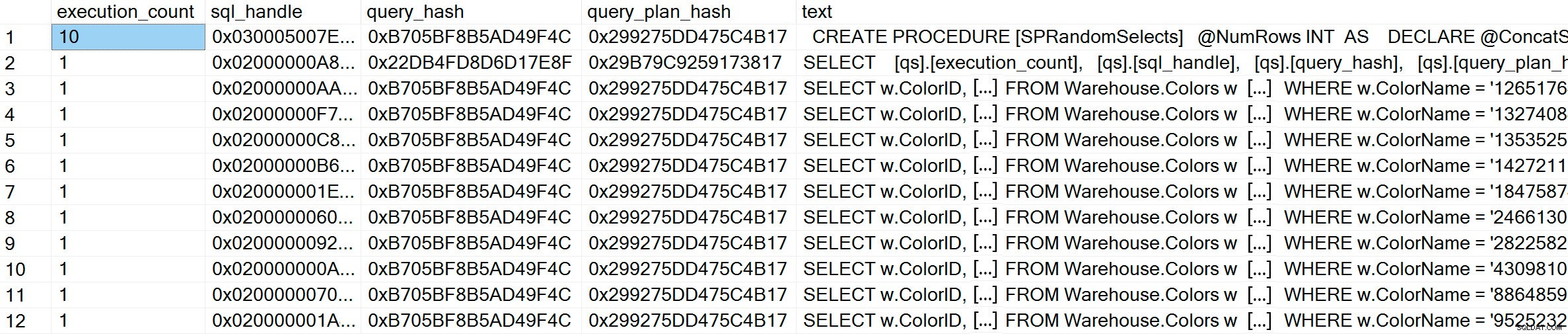
GO Après l'exécution, si nous vérifions le cache du plan, nous pouvons voir que nous avons 10 entrées uniques, chacune avec un execution_count de 1 (zoomez sur l'image si nécessaire pour voir les valeurs uniques du prédicat) :
SELECT [qs].[execution_count], [qs].[sql_handle], [qs].[query_hash], [qs].[query_plan_hash], [st].[text] FROM sys.dm_exec_query_stats AS [qs] CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st] CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp] WHERE [st].[text] LIKE '%Warehouse%' ORDER BY [st].[text], [qs].[execution_count] DESC; GO

Nous créons maintenant une procédure stockée presque identique qui exécute la même requête, mais paramétrée :
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = @ConcatString;
SELECT @RowLoop = @RowLoop + 1;
END
GO
EXEC dbo.[SPRandomSelects] @NumRows = 10;
GO Dans le cache du plan, en plus des 10 requêtes ad hoc, nous voyons une entrée pour la requête paramétrée qui a été exécutée 10 fois. Étant donné que l'entrée est paramétrée, même si des chaînes très différentes sont passées dans le paramètre, le texte de la requête est exactement le même :
Test
Maintenant que nous comprenons ce qui se passe dans le cache du plan, créons plus de charge. Nous allons utiliser un fichier de ligne de commande qui appelle le même fichier .sql sur 10 threads différents, chaque fichier appelant la procédure stockée 10 000 fois. Nous allons vider le cache du plan avant de commencer et capturer le pourcentage total de CPU et les compilations SQL/s avec PerfMon pendant l'exécution des scripts.
Contenu du fichier Adhoc.sql :
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 10000;
Contenu du fichier.sql paramétré :
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 10000;
Exemple de fichier de commandes (affiché dans le Bloc-notes) qui appelle le fichier .sql :
Exemple de fichier de commandes (affiché dans le Bloc-notes) qui crée 10 threads, chacun appelant le fichier Run_Adhoc.cmd :
Après avoir exécuté chaque ensemble de requêtes 100 000 fois au total, si nous examinons le cache du plan, nous voyons ce qui suit :

Il y a plus de 10 000 plans ad hoc dans le cache de plans. Vous vous demandez peut-être pourquoi il n'y a pas de plan pour les 100 000 requêtes ad hoc exécutées, et cela a à voir avec le fonctionnement du cache de plan (sa taille est basée sur la mémoire disponible, lorsque les plans inutilisés sont dépassés, etc.). Ce qui est essentiel, c'est que ainsi de nombreux plans ad hoc existent, par rapport à ce que nous voyons pour le reste des types de cache.
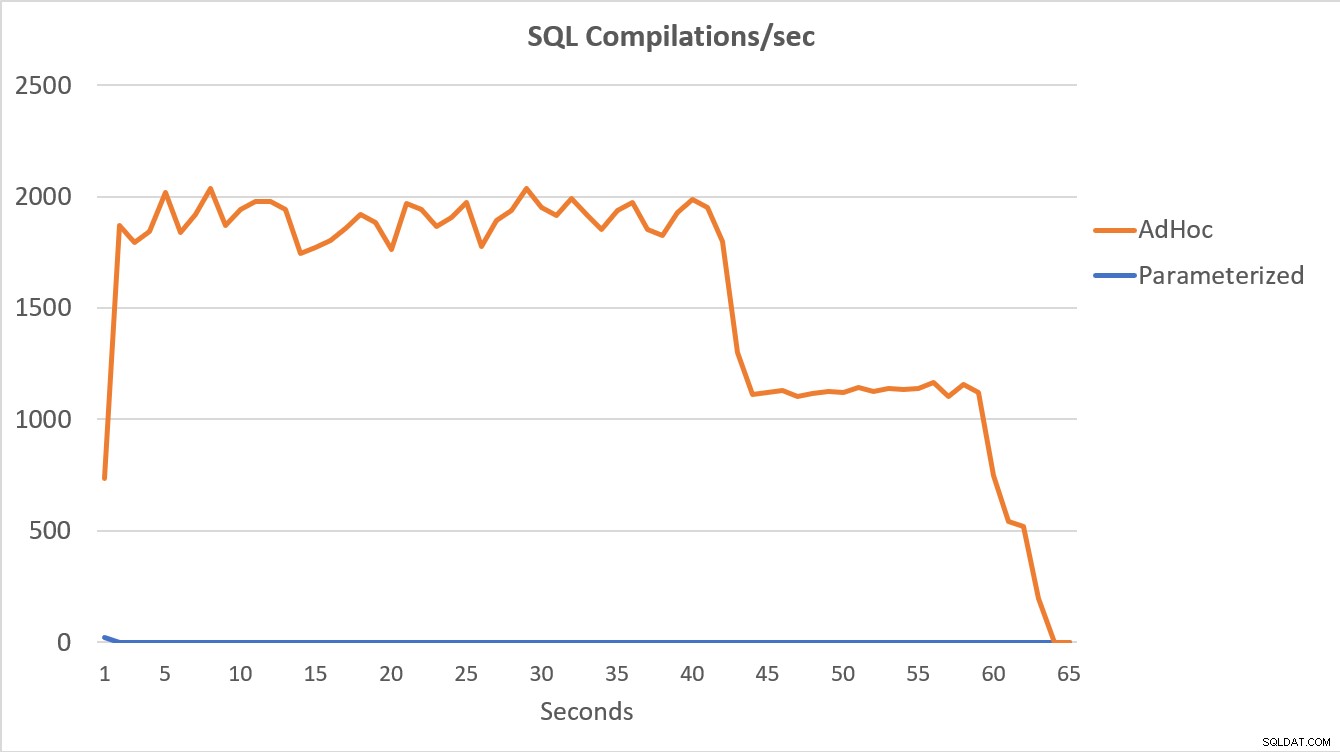
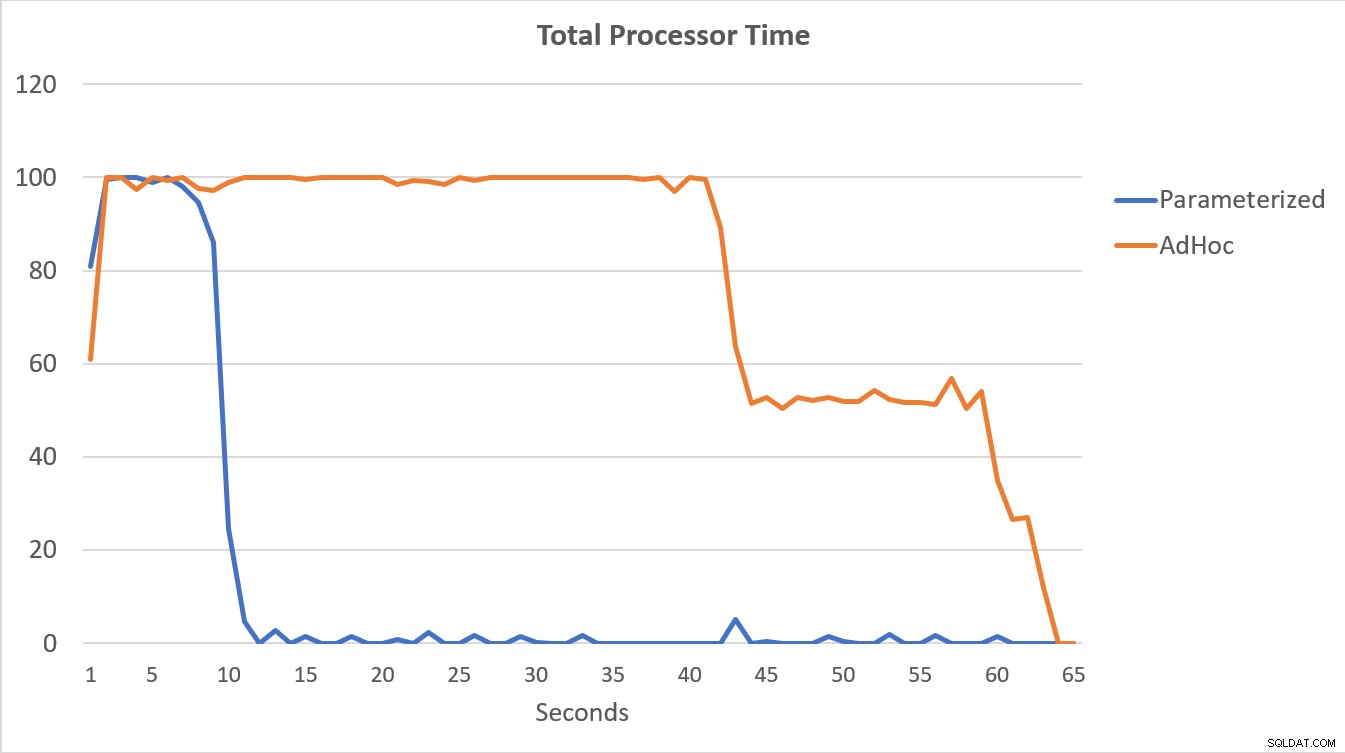
Les données PerfMon, représentées graphiquement ci-dessous, sont les plus révélatrices. L'exécution des 100 000 requêtes paramétrées s'est terminée en moins de 15 secondes, et il y a eu un petit pic de Compilations/sec au début, ce qui est à peine perceptible sur le graphique. Le même nombre d'exécutions adhoc a pris un peu plus de 60 secondes, avec des compilations/sec atteignant près de 2 000 avant de se rapprocher de 1 000 autour de la barre des 45 secondes, avec un processeur proche ou à 100 % la plupart du temps.
Résumé
Notre test était extrêmement simple dans la mesure où nous n'avons soumis des variations que pour une requête ad hoc, alors que dans un environnement de production, nous pourrions avoir des centaines ou des milliers de variantes différentes pour des centaines ou des milliers de différentes requêtes ad hoc. L'impact sur les performances de ces requêtes ad hoc n'est pas seulement le gonflement du cache du plan qui se produit, bien que le cache du plan soit un excellent point de départ si vous n'êtes pas familier avec le type de charge de travail que vous avez. Un volume élevé de requêtes ad hoc peut conduire à des compilations et donc au processeur, qui peut parfois être masqué en ajoutant plus de matériel, mais il peut arriver un moment où le processeur devient un goulot d'étranglement. Si vous pensez que cela pourrait être un problème, ou un problème potentiel, dans votre environnement, cherchez à identifier les requêtes ad hoc qui s'exécutent le plus fréquemment et voyez quelles options vous avez pour les paramétrer. Ne vous méprenez pas :il existe des problèmes potentiels avec les requêtes paramétrées (par exemple, la stabilité du plan en raison de l'asymétrie des données), et c'est un autre problème que vous devrez peut-être résoudre. Quelle que soit votre charge de travail, il est important de comprendre qu'il existe rarement une méthode « définir et oublier » pour le codage, la configuration, la maintenance, etc. effectuer de manière fiable. L'une des tâches d'un administrateur de base de données est de suivre ce changement et de gérer au mieux les performances, qu'elles soient liées à des problèmes de performances ad hoc ou paramétrés.