Il existe deux compétences complémentaires qui sont très utiles dans le réglage des requêtes. L'un est la capacité de lire et d'interpréter les plans d'exécution. La seconde consiste à en savoir un peu plus sur le fonctionnement de l'optimiseur de requêtes pour traduire le texte SQL en un plan d'exécution. La combinaison des deux éléments peut nous aider à repérer les moments où une optimisation attendue n'a pas été appliquée, ce qui se traduit par un plan d'exécution qui n'est pas aussi efficace qu'il pourrait l'être. Le manque de documentation sur les optimisations exactes que SQL Server peut appliquer (et dans quelles circonstances) signifie cependant qu'une grande partie de cela dépend de l'expérience.
Un exemple
L'exemple de requête de cet article est basé sur la question posée par le MVP SQL Server Fabiano Amorim il y a quelques mois, sur la base d'un problème réel qu'il a rencontré. Le schéma et la requête de test ci-dessous sont une simplification de la situation réelle, mais ils conservent toutes les fonctionnalités importantes.
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Test 1 :10 000 lignes, SQL Server 2005+
Les données de table spécifiques n'ont pas vraiment d'importance pour ces tests. Les requêtes suivantes chargent simplement 10 000 lignes d'une table de nombres dans chacune des trois tables de test :
INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 10000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1;
Avec les données chargées, le plan d'exécution produit pour la requête de test est :
SELECT MAX(c1) FROM dbo.V1;
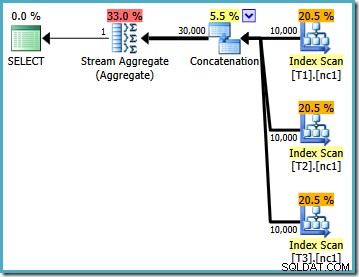
Ce plan d'exécution est une implémentation assez directe de la requête SQL logique (après l'expansion de la référence de vue V1). L'optimiseur voit la requête après l'expansion de la vue, presque comme si la requête avait été entièrement écrite :
SELECT MAX(c1)
FROM
(
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3
) AS V1;
En comparant le texte développé au plan d'exécution, le caractère direct de la mise en œuvre de l'optimiseur de requête est clair. Il y a un Index Scan pour chaque lecture des tables de base, un opérateur de concaténation pour implémenter le UNION ALL , et un Stream Aggregate pour le MAX final agrégé.
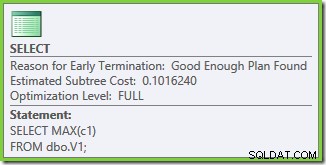
Les propriétés du plan d'exécution indiquent que l'optimisation basée sur les coûts a démarré (le niveau d'optimisation est FULL ), mais qu'il s'est terminé plus tôt parce qu'un plan "assez bon" a été trouvé. Le coût estimé du plan sélectionné est de 0,1016240 unités d'optimisation magique.
Test 2 :50 000 lignes, SQL Server 2008 et 2008 R2
Exécutez le script suivant pour réinitialiser l'environnement de test afin qu'il s'exécute avec 50 000 lignes :
TRUNCATE TABLE dbo.T1; TRUNCATE TABLE dbo.T2; TRUNCATE TABLE dbo.T3; INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 50000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1; SELECT MAX(c1) FROM dbo.V1;
Le plan d'exécution de ce test dépend de la version de SQL Server que vous exécutez. Dans SQL Server 2008 et 2008 R2, nous obtenons le plan suivant :
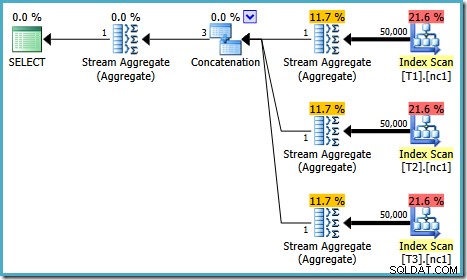
Les propriétés du plan montrent que l'optimisation basée sur les coûts s'est toujours terminée plus tôt pour la même raison qu'auparavant. Le coût estimé est plus élevé qu'avant à 0,41375 unités, mais cela est attendu en raison de la cardinalité plus élevée des tables de base.
Test 3 : 50 000 lignes, SQL Server 2005 et 2012
La même requête exécutée en 2005 ou 2012 produit un plan d'exécution différent :
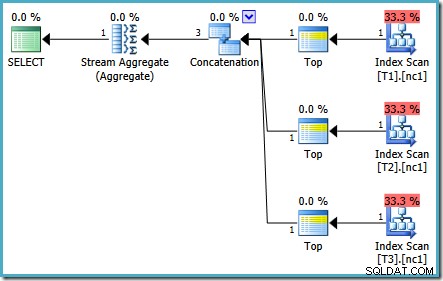
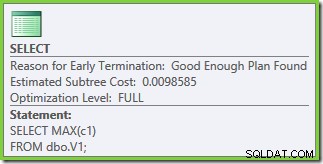
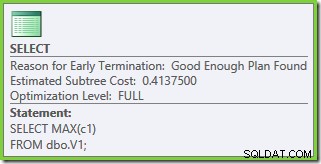
L'optimisation s'est de nouveau terminée plus tôt, mais le coût estimé du plan pour 50 000 lignes par table de base est tombé à 0,0098585 (à partir de 0,41375 sur SQL Server 2008 et 2008 R2).
Explication
Comme vous le savez peut-être, l'optimiseur de requête SQL Server sépare l'effort d'optimisation en plusieurs étapes, les étapes ultérieures ajoutant davantage de techniques d'optimisation et laissant plus de temps. Les étapes d'optimisation sont :
- Plan trivial
- Optimisation basée sur les coûts
- Traitement des transactions (recherche 0)
- Plan rapide (recherche 1)
- Plan rapide avec parallélisme activé
- Optimisation complète (recherche 2)
Aucun des tests effectués ici ne se qualifie pour un plan trivial car l'agrégat et les syndicats ont de multiples possibilités de mise en œuvre, nécessitant une décision basée sur les coûts.
Traitement des transactions
L'étape de traitement des transactions (TP) nécessite qu'une requête contienne au moins trois références de table, sinon l'optimisation basée sur les coûts ignore cette étape et passe directement à la planification rapide. L'étape TP est destinée aux requêtes de navigation à faible coût typiques des charges de travail OLTP. Il essaie un nombre limité de techniques d'optimisation et se limite à trouver des plans avec des jointures de boucle imbriquées (sauf si une jointure par hachage est nécessaire pour générer un plan valide).
À certains égards, il est surprenant que la requête de test se qualifie pour une étape visant à trouver des plans OLTP. Bien que la requête contienne les trois références de table requises, elle ne contient aucune jointure. L'exigence de trois tables n'est qu'une heuristique, je ne m'attarderai donc pas sur ce point.
Quelles étapes de l'optimiseur ont été exécutées ?
Il existe un certain nombre de méthodes, celle documentée étant de comparer le contenu de sys.dm_exec_query_optimizer_info avant et après la compilation. C'est bien, mais il enregistre des informations à l'échelle de l'instance, vous devez donc faire attention à ce que la vôtre soit la seule compilation de requêtes qui se produit entre les instantanés.
Une alternative non documentée (mais raisonnablement connue) qui fonctionne sur toutes les versions actuellement prises en charge de SQL Server consiste à activer les indicateurs de trace 8675 et 3604 lors de la compilation de la requête.
Essai 1
Ce test produit une sortie de l'indicateur de trace 8675 semblable à ce qui suit :

Le coût estimé de 0,101624 après l'étape TP est suffisamment faible pour que l'optimiseur ne recherche pas de plans moins chers. Le plan simple auquel nous aboutissons est tout à fait raisonnable compte tenu de la relativement faible cardinalité des tables de base, même s'il n'est pas vraiment optimal.
Essai 2
Avec 50 000 lignes dans chaque table de base, l'indicateur de trace révèle différentes informations :

Cette fois, le coût estimé après l'étape TP est de 0,428735 (plus de lignes =coût plus élevé). C'est suffisant pour encourager l'optimiseur à passer à l'étape de planification rapide. Avec plus de techniques d'optimisation disponibles, cette étape trouve un plan avec un coût de 0,41375 . Cela ne représente pas une énorme amélioration par rapport au plan de test 1, mais il est inférieur au seuil de coût par défaut pour le parallélisme, et pas suffisant pour entrer dans l'optimisation complète, donc encore une fois l'optimisation se termine plus tôt.
Essai 3
Pour l'exécution de SQL Server 2005 et 2012, la sortie de l'indicateur de trace est :

Il existe des différences mineures dans le nombre de tâches exécutées entre les versions, mais la différence importante est que sur SQL Server 2005 et 2012, l'étape Plan rapide trouve un plan ne coûtant que 0,0098543 unités. Il s'agit du plan qui contient les opérateurs Top au lieu des trois agrégats de flux sous l'opérateur de concaténation vu dans les plans SQL Server 2008 et 2008 R2.
Bogues et correctifs non documentés
SQL Server 2008 et 2008 R2 contiennent un bogue de régression (par rapport à 2005) qui a été corrigé sous l'indicateur de trace 4199, mais non documenté pour autant que je sache. Il existe une documentation pour TF 4199 qui répertorie les correctifs mis à disposition sous des indicateurs de trace distincts avant d'être couverts par 4199, mais comme le dit cet article de la base de connaissances :
Cet indicateur de trace unique peut être utilisé pour activer tous les correctifs précédemment apportés au processeur de requêtes sous de nombreux indicateurs de trace. En outre, tous les futurs correctifs du processeur de requêtes seront contrôlés à l'aide de cet indicateur de trace.
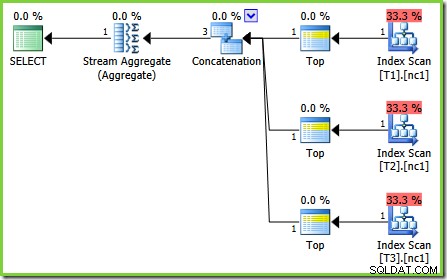
Le bogue dans ce cas est l'un de ces "futurs correctifs du processeur de requêtes". Une règle d'optimisation particulière, ScalarGbAggToTop , ne s'applique pas aux nouveaux agrégats vus dans le plan test 2. Avec l'indicateur de trace 4199 activé sur les versions appropriées de SQL Server 2008 et 2008 R2, le bogue est corrigé et le plan optimal du test 3 est obtenu :
-- Trace flag 4199 required for 2008 and 2008 R2 SELECT MAX(c1) FROM dbo.V1 OPTION (QUERYTRACEON 4199);
Conclusion
Une fois que vous savez que l'optimiseur peut transformer un scalaire MIN ou MAX agréger en un TOP (1) sur un flux ordonné, le plan montré dans le test 2 semble étrange. Les agrégats scalaires au-dessus d'un parcours d'index (qui peuvent fournir un ordre si on le leur demande) se distinguent comme une optimisation manquée qui serait normalement appliquée.
C'est ce que je disais dans l'introduction :une fois que vous avez une idée du genre de choses que l'optimiseur peut faire, cela peut vous aider à reconnaître les cas où quelque chose s'est mal passé.
La réponse ne sera pas toujours d'activer l'indicateur de trace 4199, car vous pourriez rencontrer des problèmes qui n'ont pas encore été résolus. Vous pouvez également ne pas souhaiter que les autres correctifs QP couverts par l'indicateur de trace s'appliquent dans un cas particulier - les correctifs de l'optimiseur n'améliorent pas toujours les choses. S'ils le faisaient, il n'y aurait pas besoin de se protéger contre les régressions de plan malheureuses en utilisant ce drapeau.
La solution dans d'autres cas pourrait être de formuler la requête SQL en utilisant une syntaxe différente, de diviser la requête en morceaux plus conviviaux pour l'optimiseur, ou autre chose entièrement. Quelle que soit la réponse, il est toujours utile d'en savoir un peu plus sur les composants internes de l'optimiseur afin que vous puissiez reconnaître qu'il y a eu un problème en premier lieu :)



