Au cas où vous ne l'auriez pas vu, nous venons de publier ClusterControl 1.7.5 avec des améliorations majeures et de nouvelles fonctionnalités utiles. Certaines des fonctionnalités incluent la maintenance à l'échelle du cluster, la prise en charge des versions CentOS 8 et Debian 10, la prise en charge de PostgreSQL 12, la prise en charge de MongoDB 4.2 et Percona MongoDB v4.0, ainsi que le nouveau MySQL Freeze Frame.
Attendez, mais qu'est-ce qu'un Freeze Frame MySQL ? Est-ce quelque chose de nouveau pour MySQL ?
Eh bien, ce n'est pas quelque chose de nouveau dans le noyau MySQL lui-même. C'est une nouvelle fonctionnalité que nous avons ajoutée à ClusterControl 1.7.5 et qui est spécifique aux bases de données MySQL. Le Freeze Frame MySQL dans ClusterControl 1.7.5 couvrira les éléments suivants :
- Instantané de l'état de MySQL avant l'échec du cluster.
- Instantané de la liste des processus MySQL avant l'échec du cluster (à venir).
- Inspectez les incidents de cluster dans les rapports opérationnels ou à partir de l'outil de ligne de commande s9s.
Ce sont des ensembles d'informations précieux qui peuvent aider à détecter les bogues et à corriger vos clusters MySQL/MariaDB lorsque les choses tournent mal. À l'avenir, nous prévoyons également d'inclure des instantanés des valeurs de statut SHOW ENGINE InnoDB. Alors restez à l'écoute de nos futures versions.
Notez que cette fonctionnalité est toujours en version bêta, nous prévoyons de collecter davantage d'ensembles de données au fur et à mesure que nous travaillons avec nos utilisateurs. Dans ce blog, nous vous montrerons comment tirer parti de cette fonctionnalité, en particulier lorsque vous avez besoin d'informations supplémentaires lors du diagnostic de votre cluster MySQL/MariaDB.
ClusterControl sur la gestion de l'échec du cluster
Pour les échecs de cluster, ClusterControl ne fait rien à moins que la récupération automatique (cluster/nœud) soit activée comme ci-dessous :

Une fois activé, ClusterControl essaiera de récupérer un nœud ou de récupérer le cluster en évoquant l'ensemble de la topologie du cluster.
Pour MySQL, par exemple dans une réplication maître-esclave, il doit y avoir au moins un maître actif à tout moment, quel que soit le nombre d'esclaves disponibles. ClusterControl tente de corriger la topologie au moins une fois pour les clusters de réplication, mais fournit plus de tentatives pour la réplication multi-maître comme NDB Cluster et Galera Cluster. La récupération de nœud tente de récupérer un nœud de base de données défaillant, par ex. lorsque le processus a été tué (arrêt anormal), ou le processus a subi un OOM (Out-of-Memory). ClusterControl se connectera au nœud via SSH et essaiera d'afficher MySQL. Nous avons déjà blogué sur la façon dont ClusterControl effectue la récupération et le basculement automatiques de la base de données, veuillez donc consulter cet article pour en savoir plus sur le schéma de récupération automatique de ClusterControl.
Dans la version précédente de ClusterControl <1.7.5, ces tentatives de récupération déclenchaient des alarmes. Mais une chose que nos clients ont manquée était un rapport d'incident plus complet avec des informations sur l'état juste avant la défaillance du cluster. Jusqu'à ce que nous nous rendions compte de cette lacune et que nous ajoutions cette fonctionnalité dans ClusterControl 1.7.5. Nous l'avons appelé "MySQL Freeze Frame". Le MySQL Freeze Frame, au moment d'écrire ces lignes, offre un bref résumé des incidents entraînant des changements d'état du cluster juste avant le crash. Plus important encore, il inclut à la fin du rapport la liste des hôtes et leurs variables et valeurs MySQL Global Status.
En quoi MySQL Freeze Frame diffère-t-il de la récupération automatique ?
Le MySQL Freeze Frame ne fait pas partie de la récupération automatique de ClusterControl. Que la récupération automatique soit désactivée ou activée, MySQL Freeze Frame fera toujours son travail tant qu'une panne de cluster ou de nœud a été détectée.
Comment fonctionne MySQL Freeze Frame ?
Dans ClusterControl, il existe certains états que nous classons comme différents types d'état de cluster. MySQL Freeze Frame générera un rapport d'incident lorsque ces deux états seront déclenchés :
- CLUSTER_DEGRADED
- CLUSTER_FAILURE
Dans ClusterControl, un CLUSTER_DEGRADED est lorsque vous pouvez écrire dans un cluster, mais qu'un ou plusieurs nœuds sont en panne. Lorsque cela se produit, ClusterControl génère le rapport d'incident.
Pour CLUSTER_FAILURE, bien que sa nomenclature s'explique d'elle-même, c'est l'état où votre cluster échoue et n'est plus en mesure de traiter les lectures ou les écritures. Alors c'est un état CLUSTER_FAILURE. Qu'un processus de récupération automatique tente de résoudre le problème ou qu'il soit désactivé, ClusterControl générera le rapport d'incident.
Comment activer MySQL Freeze Frame ?
L'arrêt sur image MySQL de ClusterControl est activé par défaut et ne génère un rapport d'incident que lorsque les états CLUSTER_DEGRADED ou CLUSTER_FAILURE sont déclenchés ou rencontrés. Il n'est donc pas nécessaire que l'utilisateur définisse un paramètre de configuration de ClusterControl, ClusterControl le fera automatiquement pour vous.
Localisation du rapport d'incident d'arrêt sur image MySQL
Au moment d'écrire ces lignes, il existe 4 façons de localiser le rapport d'incident. Ceux-ci peuvent être trouvés en faisant les sections suivantes ci-dessous.
Utiliser l'onglet Rapports opérationnels
Les rapports opérationnels des versions précédentes sont utilisés uniquement pour créer, planifier ou répertorier les rapports opérationnels qui ont été générés par les utilisateurs. Depuis la version 1.7.5, nous avons inclus le rapport d'incident généré par notre fonctionnalité MySQL Freeze Frame. Voir l'exemple ci-dessous :
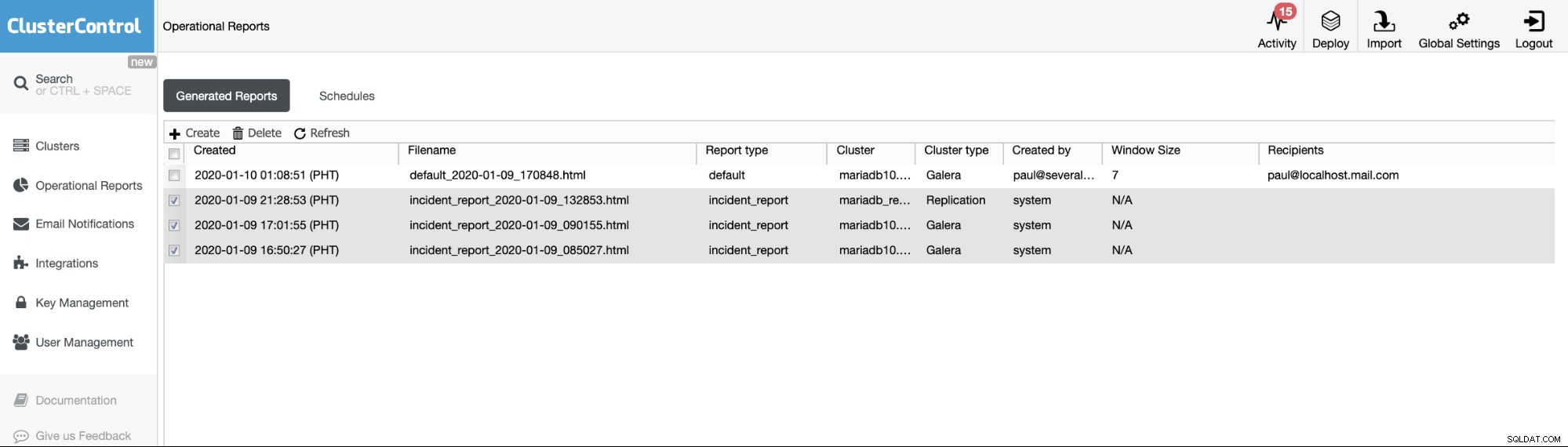
Les éléments cochés ou les éléments avec le type de rapport ==incident_report, sont l'incident rapports générés par la fonctionnalité MySQL Freeze Frame dans ClusterControl.
Utilisation des rapports d'erreurs
En sélectionnant le cluster et en générant un rapport d'erreur, c'est-à-dire en suivant ce processus :
Utilisation de la ligne de commande CLI s9s
Sur un rapport d'incident généré, il inclut des instructions ou des conseils sur la façon dont vous pouvez l'utiliser avec la commande CLI s9s. Voici ce qui apparaît dans le rapport d'incident :
Astuce ! L'utilisation de l'outil CLI s9s vous permet de regrouper facilement les données dans ce rapport, par exemple :
s9s report --list --long
s9s report --cat --report-id=NDonc, si vous souhaitez localiser et générer un rapport d'erreur, vous pouvez utiliser cette approche :
[example@sqldat.com ~]$ s9s report --list --long --cluster-id=60
ID CID TYPE CREATED TITLE
19 60 incident_report 16:50:27 Incident Report - Cluster Failed
20 60 incident_report 17:01:55 Incident ReportSi je veux grep les variables wsrep_* sur un hôte spécifique, je peux faire ce qui suit :
[example@sqldat.com ~]$ s9s report --cat --report-id=20 --cluster-id=60|sed -n '/WSREP.*/p'|sed 's/ */ /g'|grep '192.168.10.80'|uniq -d
| WSREP_APPLIER_THREAD_COUNT | 4 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_CONF_ID | 18446744073709551615 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_SIZE | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_DELAYED | 27ac86a9-3254-11ea-b104-bb705eb13dde:tcp://192.168.10.100:4567:1,9234d567-3253-11ea-92d3-b643c178d325:tcp://192.168.10.90:4567:1,9234d567-3253-11ea-92d4-b643c178d325:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25e-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25f-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b260-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b261-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b262-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b263-cfcbda888ea9:tcp://192.168.10.90:4567:1,b0b7cb15-3241-11ea-bdbc-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbd-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbe-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbf-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdc0-1a21deddc100:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b321-9a836d562a47:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b322-9a836d562a47:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ab-e298880f3348:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ac-e298880f3348:tcp://192.168.10.100:4567:1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_GCOMM_UUID | 781facbc-3241-11ea-8a22-d74e5dcf7e08 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LAST_COMMITTED | 443 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_CACHED_DOWNTO | 98 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_RECV_QUEUE_MAX | 2 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROTOCOL_VERSION | 10 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROVIDER_VERSION | 26.4.3(r4535) | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED | 112 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED_BYTES | 14413 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED_BYTES | 40592 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_DATA_BYTES | 31734 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS_BYTES | 2752 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_ROLLBACKER_THREAD_COUNT | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_THREAD_COUNT | 5 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_REPL_LATENCY | 4.508e-06/4.508e-06/4.508e-06/0/1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |Recherche manuelle via le chemin du fichier système
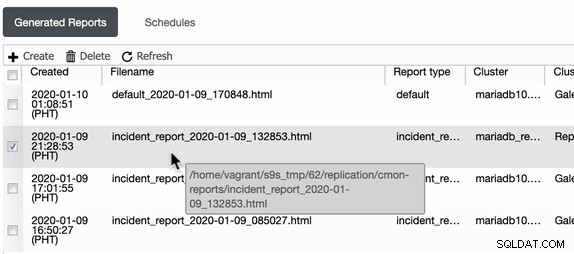
ClusterControl génère ces rapports d'incident sur l'hôte sur lequel ClusterControl s'exécute. ClusterControl crée un répertoire dans /home/
Y a-t-il des dangers ou des mises en garde lors de l'utilisation de MySQL Freeze Frame ?
ClusterControl ne change ni ne modifie rien dans vos nœuds ou cluster MySQL. MySQL Freeze Frame lira simplement SHOW GLOBAL STATUS (à partir de ce moment) à des intervalles spécifiques pour enregistrer les enregistrements car nous ne pouvons pas prédire l'état d'un nœud ou d'un cluster MySQL lorsqu'il peut planter ou lorsqu'il peut avoir des problèmes de matériel ou de disque. Il n'est pas possible de prévoir cela, nous sauvegardons donc les valeurs et nous pouvons donc générer un rapport d'incident au cas où un nœud particulier tomberait en panne. Dans ce cas, le danger d'avoir cela est proche de zéro. Il peut théoriquement ajouter une série de requêtes client au(x) serveur(s) au cas où certains verrous seraient détenus dans MySQL, mais nous ne l'avons pas encore remarqué. La série de tests ne le montre pas, nous serions donc heureux si vous pouviez laisser informez-nous ou déposez un ticket d'assistance en cas de problème.
Dans certaines situations, un rapport d'incident peut ne pas être en mesure de collecter des variables d'état globales si un problème de réseau était le problème avant que ClusterControl ne gèle une trame spécifique pour collecter des données. C'est tout à fait raisonnable car il n'y a aucun moyen que ClusterControl puisse collecter des données pour un diagnostic plus approfondi car il n'y a pas de connexion au nœud en premier lieu.
Enfin, vous pourriez vous demander pourquoi toutes les variables ne sont pas affichées dans la section GLOBAL STATUS ? En attendant, nous définissons un filtre dans lequel les valeurs vides ou 0 sont exclues du rapport d'incident. La raison en est que nous voulons économiser de l'espace disque. Une fois que ces rapports d'incident ne sont plus nécessaires, vous pouvez les supprimer via l'onglet Rapports opérationnels.
Test de la fonctionnalité MySQL Freeze Frame
Nous pensons que vous avez hâte d'essayer celui-ci et de voir comment cela fonctionne. Mais s'il vous plaît, assurez-vous que vous n'exécutez pas ou ne testez pas cela dans un environnement réel ou de production. Nous couvrirons 2 phases de scénario dans MySQL/MariaDB, une pour la configuration maître-esclave et une pour la configuration de type Galera.
Scénario de test de configuration maître-esclave
Dans une configuration maître-esclave(s), c'est facile et simple à essayer.
Première étape
Assurez-vous que vous avez désactivé les modes de récupération automatique (cluster et nœud), comme ci-dessous :

afin qu'il n'essaye pas ou ne tente pas de corriger le scénario de test.
Étape 2
Accédez à votre nœud maître et essayez de le définir en lecture seule :
example@sqldat.com[mysql]> set @@global.read_only=1;
Query OK, 0 rows affected (0.000 sec)Étape 3
Cette fois, une alarme a été déclenchée et donc un rapport d'incident généré. Voyez ci-dessous à quoi ressemble mon cluster :

et l'alarme s'est déclenchée :

et le rapport d'incident a été généré :

Scénario de test de configuration du cluster Galera
Pour une configuration basée sur Galera, nous devons nous assurer que le cluster ne sera plus disponible, c'est-à-dire une défaillance à l'échelle du cluster. Contrairement au test maître-esclave, vous pouvez laisser la récupération automatique activée puisque nous jouerons avec les interfaces réseau.
Remarque :pour cette configuration, assurez-vous que vous disposez de plusieurs interfaces si vous testez les nœuds dans une instance distante, car vous ne pouvez pas activer l'interface lorsque vous désactivez l'interface à laquelle vous êtes connecté.
Première étape
Créer un cluster Galera à 3 nœuds (par exemple en utilisant vagrant)
Étape 2
Émettez la commande (comme ci-dessous) pour simuler un problème de réseau et faites-le à tous les nœuds
[example@sqldat.com ~]# ifdown eth1
Device 'eth1' successfully disconnected.Étape 3
Maintenant, il a arrêté mon cluster et a cet état :

a déclenché une alarme,

et il génère un rapport d'incident :

Pour un exemple de rapport d'incident, vous pouvez utiliser ce fichier brut et l'enregistrer au format html.
C'est assez simple à essayer, mais encore une fois, faites-le uniquement dans un environnement non live et non prod.
Conclusion
MySQL Freeze Frame dans ClusterControl peut être utile lors du diagnostic des plantages. Lors du dépannage, vous avez besoin d'une mine d'informations afin de déterminer la cause et c'est exactement ce que fournit MySQL Freeze Frame.



