Lors de l'exécution d'une requête, l'optimiseur SQL Server essaie de trouver le meilleur plan de requête en fonction des index existants et des dernières statistiques disponibles pendant un temps raisonnable, bien sûr, si ce plan n'est pas déjà stocké dans le cache du serveur. Si non, la requête est exécutée selon ce plan, et le plan est stocké dans le cache du serveur. Si le plan a déjà été construit pour cette requête, la requête est exécutée selon le plan existant.
Nous sommes intéressés par le problème suivant :
Lors de la compilation d'un plan de requête, lors du tri des index possibles, si le serveur ne trouve pas le meilleur index, l'index manquant est marqué dans le plan de requête, et le serveur conserve des statistiques sur ces index :combien de fois le serveur utiliserait cet index et combien coûterait cette requête.
Dans cet article, nous allons analyser ces index manquants - comment les traiter.
Considérons cela sur un exemple particulier. Créez quelques tables dans notre base de données sur un serveur local et test :
[développez le titre =”Code”]
if object_id ('orders_detail') is not null drop table orders_detail;
if object_id('orders') is not null drop table orders;
go
create table orders
(
id int identity primary key,
dt datetime,
seller nvarchar(50)
)
create table orders_detail
(
id int identity primary key,
order_id int foreign key references orders(id),
product nvarchar(30),
qty int,
price money,
cost as qty * price
)
go
with cte as
(
select 1 id union all
select id+1 from cte where id < 20000
)
insert orders
select
dt,
seller
from
(
select
dateadd(day,abs(convert(int,convert(binary(4),newid()))%365),'2016-01-01') dt,
abs(convert(int,convert(binary(4),newid()))%5)+1 seller_id
from cte
) c
left join
(
values
(1,'John'),
(2,'Mike'),
(3,'Ann'),
(4,'Alice'),
(5,'George')
) t (id,seller) on t.id = c.seller_id
option(maxrecursion 0)
insert orders_detail
select
order_id,
product,
qty,
price
from
(
select
o.id as order_id,
abs(convert(int,convert(binary(4),newid()))%5)+1 product_id,
abs(convert(int,convert(binary(4),newid()))%20)+1 qty
from orders o cross join
(
select top(abs(convert(int,convert(binary(4),newid()))%5)+1) *
from
(
values (1),(2),(3),(4),(5),(6),(7),(8)
) n(num)
) n
) c
left join
(
values
(1,'Sugar', 50),
(2,'Milk', 80),
(3,'Bread', 20),
(4,'Pasta', 40),
(5,'Beer', 100)
) t (id,product, price) on t.id = c.product_id
go [/expand]
La structure est simple et se compose de deux tables. La première table est appelée commandes avec des champs tels qu'un identifiant, une date de vente et un vendeur. Le second concerne les détails de la commande, où certaines marchandises sont spécifiées avec le prix et la quantité.
Regardez une requête simple et son plan :
select count(*) from orders o join orders_detail d on o.id = d.order_id where d.cost > 1800 go
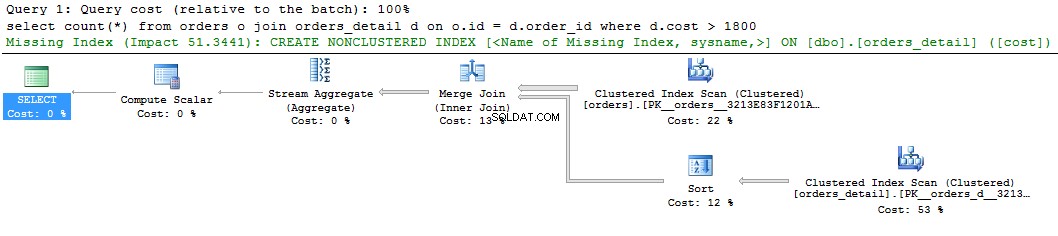
Nous pouvons voir un indice vert sur l'index manquant sur l'affichage graphique du plan de requête. Si vous cliquez dessus avec le bouton droit de la souris et sélectionnez "Détails de l'index manquant ..", le texte de l'index suggéré s'affichera. La seule chose à faire est de supprimer les commentaires dans le texte et de donner un nom à l'index. Le script est prêt à être exécuté.
Nous ne construirons pas l'index que nous avons reçu de l'indice fourni par SSMS. Nous verrons plutôt si cet index sera recommandé par les vues dynamiques liées aux index manquants. Les vues sont les suivantes :
select * from sys.dm_db_missing_index_group_stats select * from sys.dm_db_missing_index_details select * from sys.dm_db_missing_index_groups
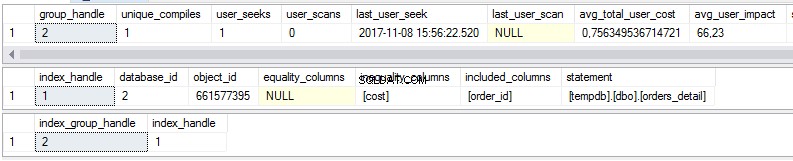
Comme nous pouvons le voir, il existe des statistiques sur les index manquants dans la première vue :
- Combien de fois une recherche serait-elle effectuée si l'index suggéré existait ?
- Combien de fois une analyse serait-elle effectuée si l'index suggéré existait ?
- Date et heure les plus récentes auxquelles nous avons utilisé l'index
- Le coût réel actuel du plan de requête sans l'index suggéré.
La deuxième vue est le corps de l'index :
- Base de données
- Objet/tableau
- Colonnes triées
- Colonnes ajoutées pour augmenter la couverture de l'index
La troisième vue est la combinaison des première et deuxième vues.
En conséquence, il n'est pas difficile d'obtenir un script qui générerait un script pour créer des index manquants à partir de ces vues dynamiques. Le script est le suivant :
[expand title=”Code”]
with igs as
(
select *
from sys.dm_db_missing_index_group_stats
)
, igd as
(
select *,
isnull(equality_columns,'')+','+isnull(inequality_columns,'') as ix_col
from sys.dm_db_missing_index_details
)
select --top(10)
'use ['+db_name(igd.database_id)+'];
create index ['+'ix_'+replace(convert(varchar(10),getdate(),120),'-','')+'_'+convert(varchar,igs.group_handle)+'] on '+
igd.[statement]+'('+
case
when left(ix_col,1)=',' then stuff(ix_col,1,1,'')
when right(ix_col,1)=',' then reverse(stuff(reverse(ix_col),1,1,''))
else ix_col
end
+') '+isnull('include('+igd.included_columns+')','')+' with(online=on, maxdop=0)
go
' command
,igs.user_seeks
,igs.user_scans
,igs.avg_total_user_cost
from igs
join sys.dm_db_missing_index_groups link on link.index_group_handle = igs.group_handle
join igd on link.index_handle = igd.index_handle
where igd.database_id = db_id()
order by igs.avg_total_user_cost * igs.user_seeks desc [/expand]
Pour l'efficacité de l'index, les index manquants sont sortis. La solution parfaite est lorsque cet ensemble de résultats ne renvoie rien. Dans notre exemple, le jeu de résultats renverra au moins un index :

Lorsque le temps manque et que vous n'avez pas envie de vous occuper des bogues du client, j'ai exécuté la requête, copié la première colonne et l'ai exécutée sur le serveur. Après cela, tout a bien fonctionné.
Je recommande de traiter consciemment les informations contenues dans ces index. Par exemple, si le système recommande les index suivants :
create index ix_01 on tbl1 (a,b) include (c) create index ix_02 on tbl1 (a,b) include (d) create index ix_03 on tbl1 (a)
Et ces index servent à la recherche, il est bien évident qu'il est plus logique de remplacer ces index par un qui couvrira les trois proposés :
create index ix_1 on tbl1 (a,b) include (c,d)
Ainsi, nous faisons une revue des index manquants avant de les déployer sur le serveur de production. Bien que…. Encore une fois, par exemple, j'ai déployé les index perdus sur le serveur TFS, augmentant ainsi les performances globales. Il a fallu un minimum de temps pour effectuer cette optimisation. Cependant, lors du passage de TFS 2015 à TFS 2017, j'ai rencontré le problème qu'il n'y avait pas de mise à jour en raison de ces nouveaux index. Néanmoins, ils peuvent facilement être trouvés par le masque
select * from sys.indexes where name like 'ix[_]2017%'
Outil utile :
dbForge Index Manager - complément SSMS pratique pour analyser l'état des index SQL et résoudre les problèmes de fragmentation d'index.