Déployer un cluster de bases de données n'est pas sorcier - il existe de nombreux tutoriels sur la façon de le faire. Mais comment savez-vous que ce que vous venez de déployer est prêt pour la production ? Les déploiements manuels peuvent également être fastidieux et répétitifs. Selon le nombre de nœuds dans le cluster, les étapes de déploiement peuvent prendre du temps et être sujettes aux erreurs. Les outils de gestion de la configuration tels que Puppet, Chef et Ansible sont populaires dans le déploiement de l'infrastructure, mais pour les clusters de bases de données avec état, vous devez effectuer d'importants scripts pour gérer le déploiement de l'ensemble de la pile HA de la base de données. De plus, le modèle/module/livre de recettes/rôle choisi doit être méticuleusement testé avant de pouvoir lui faire confiance dans le cadre de l'automatisation de votre infrastructure. Les changements de version nécessitent que les scripts soient mis à jour et testés à nouveau.
La bonne nouvelle est que ClusterControl automatise les déploiements de l'ensemble de la pile - et gratuitement en plus ! Nous avons déployé des milliers de clusters de production et pris un certain nombre de précautions pour nous assurer qu'ils sont prêts pour la production. Différentes topologies sont prises en charge, de la réplication maître-esclave au cluster Galera, NDB et InnoDB, avec différents proxys de base de données en plus.
Une pile haute disponibilité, déployée via ClusterControl, se compose de trois couches :
- Couche de base de données (par exemple, Galera Cluster)
- Couche proxy inverse (par exemple, HAProxy ou ProxySQL)
- Couche Keepalived, qui, avec l'utilisation de l'adresse IP virtuelle, garantit une haute disponibilité de la couche proxy
Dans ce blog, nous allons vous montrer comment déployer un cluster Galera de niveau production avec des équilibreurs de charge pour une configuration à haute disponibilité. La configuration complète se compose de 6 hôtes :
- 1 hôte - ClusterControl (déploiement, surveillance, serveur de gestion)
- 3 hébergeurs - cluster MySQL Galera
- 2 hôtes :les proxys inverses agissent comme des équilibreurs de charge devant le cluster.
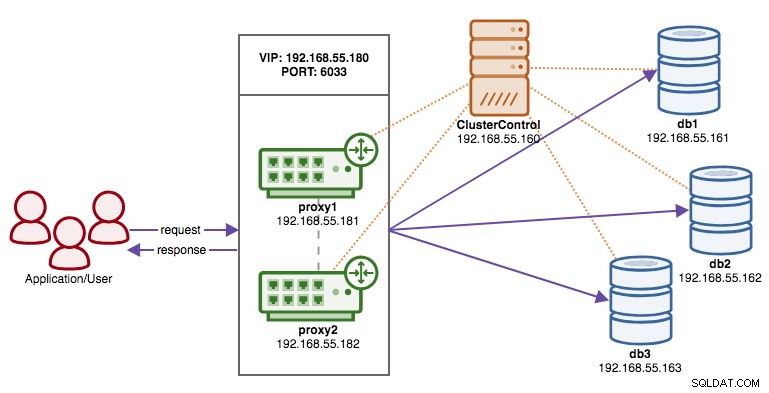
Le schéma suivant illustre notre résultat final une fois le déploiement terminé :
Prérequis
ClusterControl doit résider sur un nœud indépendant qui ne fait pas partie du cluster. Téléchargez ClusterControl, et la page générera une licence unique pour vous et montrera les étapes pour installer ClusterControl :
$ wget -O install-cc https://severalnines.com/scripts/install-cc
$ chmod +x install-cc
$ ./install-cc # as root or sudo userSuivez les instructions où vous serez guidé pour configurer le serveur MySQL, le mot de passe root MySQL sur le nœud ClusterControl, le mot de passe cmon pour l'utilisation de ClusterControl, etc. Vous devriez obtenir la ligne suivante une fois l'installation terminée :
Determining network interfaces. This may take a couple of minutes. Do NOT press any key.
Public/external IP => https://{public_IP}/clustercontrol
Installation successful. If you want to uninstall ClusterControl then run install-cc --uninstall.Ensuite, sur le serveur ClusterControl, générez une clé SSH que nous utiliserons pour configurer ultérieurement le SSH sans mot de passe. Vous pouvez utiliser n'importe quel utilisateur du système, mais il doit avoir la capacité d'effectuer des opérations de super-utilisateur (sudoer). Dans cet exemple, nous avons choisi l'utilisateur root :
$ whoami
root
$ ssh-keygen -t rsaConfigurez SSH sans mot de passe pour tous les nœuds que vous souhaitez surveiller/gérer via ClusterControl. Dans ce cas, nous allons le configurer sur tous les nœuds de la pile (y compris le nœud ClusterControl lui-même). Sur le nœud ClusterControl, exécutez les commandes suivantes et spécifiez le mot de passe root lorsque vous y êtes invité :
$ ssh-copy-id example@sqldat.com # clustercontrol
$ ssh-copy-id example@sqldat.com # galera1
$ ssh-copy-id example@sqldat.com # galera2
$ ssh-copy-id example@sqldat.com # galera3
$ ssh-copy-id example@sqldat.com # proxy1
$ ssh-copy-id example@sqldat.com # proxy2Vous pouvez ensuite vérifier si cela fonctionne en exécutant la commande suivante sur le nœud ClusterControl :
$ ssh example@sqldat.com "ls /root"Assurez-vous que vous pouvez voir le résultat de la commande ci-dessus sans avoir à saisir de mot de passe.
Déploiement du cluster
ClusterControl prend en charge tous les fournisseurs pour Galera Cluster (Codership, Percona et MariaDB). Il existe quelques différences mineures qui peuvent influencer votre décision de choisir le fournisseur. Si vous souhaitez en savoir plus sur les différences entre eux, consultez notre article de blog précédent - Comparaison des clusters Galera - Codership vs Percona vs MariaDB.
Pour un déploiement en production, un cluster Galera à trois nœuds est le minimum que vous devriez avoir. Vous pouvez toujours le mettre à l'échelle plus tard une fois le cluster déployé, manuellement ou via ClusterControl. Nous allons ouvrir notre interface utilisateur ClusterControl à https://192.168.55.160/clustercontrol et créer le premier utilisateur administrateur. Ensuite, allez dans le menu du haut et cliquez sur Déployer -> MySQL Galera et la boîte de dialogue suivante s'affichera :
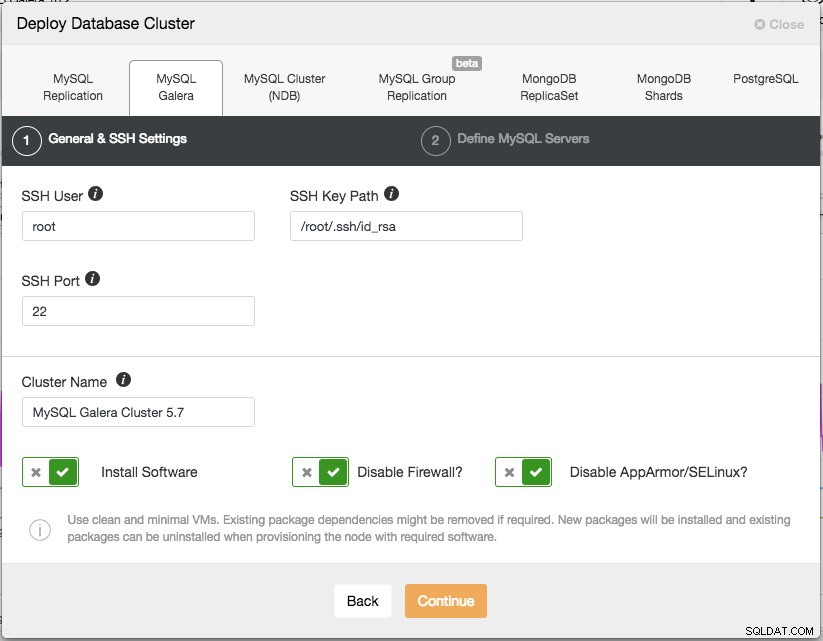
Il y a deux étapes, la première est les "Paramètres généraux et SSH". Ici, nous devons configurer l'utilisateur SSH que ClusterControl doit utiliser pour se connecter aux nœuds de la base de données, ainsi que le chemin d'accès à la clé SSH (tel que généré dans la section Prérequis) ainsi que le port SSH des nœuds de la base de données. ClusterControl suppose que tous les nœuds de base de données sont configurés avec le même utilisateur, clé et port SSH. Ensuite, donnez un nom au cluster, dans ce cas nous utiliserons "MySQL Galera Cluster 5.7". Cette valeur peut être modifiée ultérieurement. Sélectionnez ensuite les options pour demander à ClusterControl d'installer le logiciel requis, de désactiver le pare-feu et également de désactiver le module d'amélioration de la sécurité sur la distribution Linux particulière. Il est recommandé d'activer tous ces éléments afin de maximiser le potentiel d'un déploiement réussi.
Cliquez sur Continuer et la boîte de dialogue suivante s'affichera :
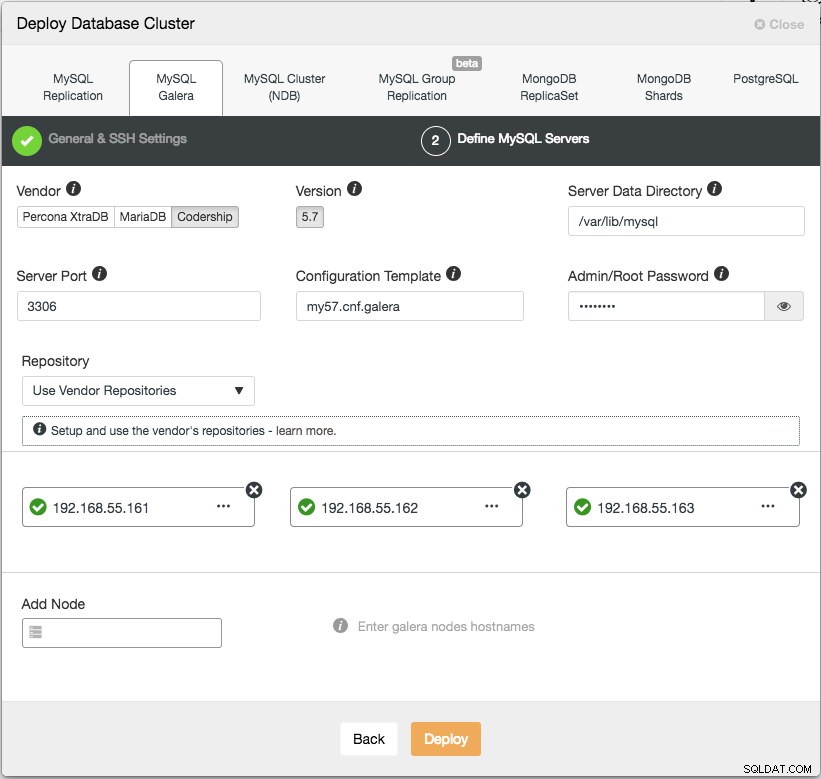
Dans l'étape suivante, nous devons configurer les serveurs de base de données - fournisseur, version, datadir, port, etc. - qui sont assez explicites. "Modèle de configuration" est le nom du fichier de modèle sous /usr/share/cmon/templates du nœud ClusterControl. "Repository" est la manière dont ClusterControl doit configurer le référentiel sur le nœud de la base de données. Par défaut, il utilisera le référentiel du fournisseur et installera la dernière version fournie par le référentiel. Cependant, dans certains cas, l'utilisateur peut disposer d'un référentiel préexistant en miroir à partir du référentiel d'origine en raison de restrictions de politique de sécurité. Néanmoins, ClusterControl prend en charge la plupart d'entre eux, comme décrit dans le guide de l'utilisateur, sous Référentiel.
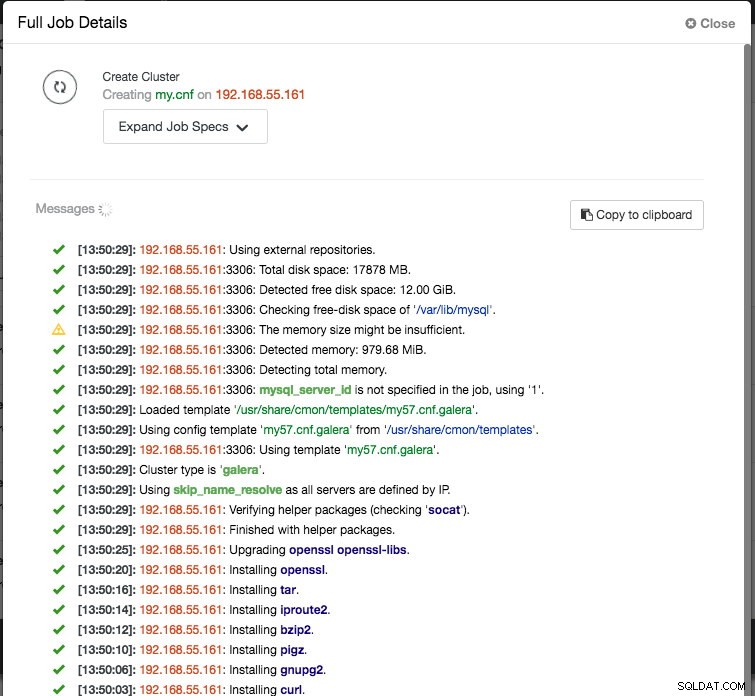
Enfin, ajoutez l'adresse IP ou le nom d'hôte (doit être un FQDN valide) des nœuds de la base de données. Vous verrez une icône de coche verte à gauche du nœud, indiquant que ClusterControl a pu se connecter au nœud via SSH sans mot de passe. Vous êtes maintenant prêt à partir. Cliquez sur Déployer pour démarrer le déploiement. Cela peut prendre 15 à 20 minutes. Vous pouvez surveiller la progression du déploiement sous Activité (menu du haut) -> Tâches -> Créer un cluster :
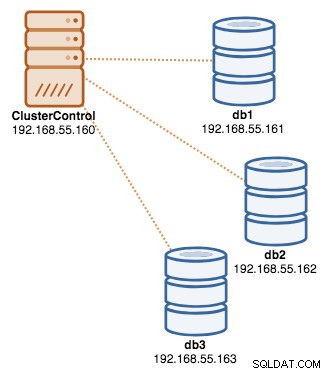
Une fois le déploiement terminé, à ce stade, notre architecture peut être illustrée comme suit :
Déploiement des équilibreurs de charge
Dans Galera Cluster, tous les nœuds sont égaux - chaque nœud détient le même rôle et le même jeu de données. Par conséquent, il n'y a pas de basculement au sein du cluster en cas de défaillance d'un nœud. Seul le côté application nécessite un basculement, pour ignorer les nœuds inopérants pendant que le cluster est partitionné. Par conséquent, il est fortement recommandé de placer des équilibreurs de charge au-dessus d'un cluster Galera pour :
- Unifiez les différents points de terminaison de la base de données en un seul point de terminaison (hôte de l'équilibreur de charge ou adresse IP virtuelle en tant que point de terminaison).
- Équilibrer les connexions de base de données entre les serveurs de base de données principaux.
- Effectuez des vérifications de l'état et transférez uniquement les connexions à la base de données vers des nœuds sains.
- Redirection/réécriture/blocage des requêtes incriminées (mal écrites) avant qu'elles n'atteignent les serveurs de base de données.
Il existe trois principaux choix de proxys inverses pour Galera Cluster - HAProxy, MariaDB MaxScale ou ProxySQL - tous peuvent être installés et configurés automatiquement par ClusterControl. Dans ce déploiement, nous avons choisi ProxySQL car il vérifie tout ce qui précède et il comprend le protocole MySQL des serveurs principaux.
Dans cette architecture, nous souhaitons utiliser deux serveurs ProxySQL pour éliminer tout point de défaillance unique (SPOF) au niveau de la base de données, qui seront liés à l'aide d'une adresse IP virtuelle flottante. Nous expliquerons cela dans la section suivante. Un nœud agira en tant que proxy actif et l'autre en tant que serveur de secours. Le nœud qui détient l'adresse IP virtuelle à un moment donné est le nœud actif.
Pour déployer le premier serveur ProxySQL, allez simplement dans le menu d'action du cluster (côté droit de la barre de résumé) et cliquez sur Ajouter un équilibreur de charge -> ProxySQL -> Déployer ProxySQL et vous verrez ce qui suit :
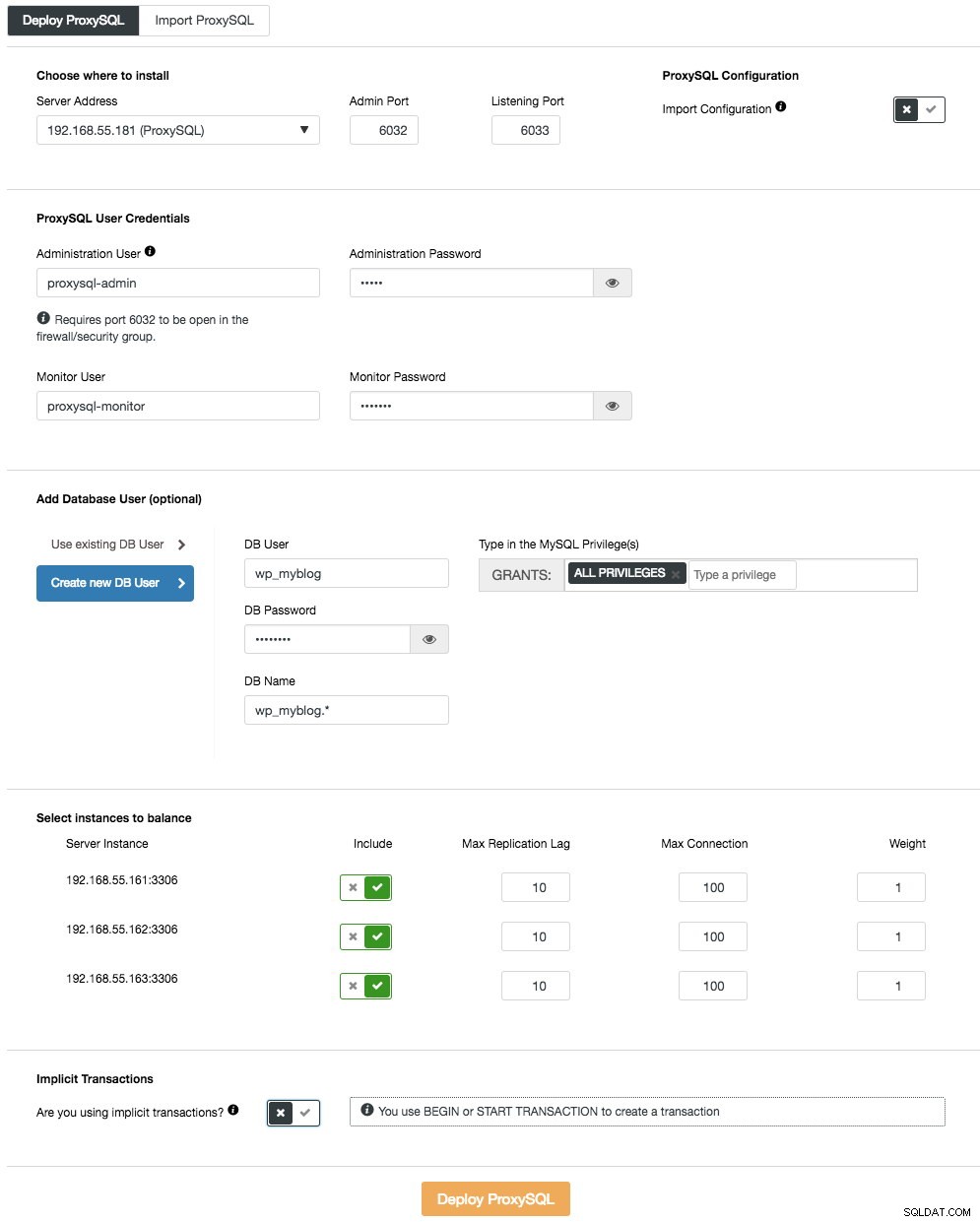
Encore une fois, la plupart des champs sont explicites. Dans la section "Utilisateur de la base de données", ProxySQL agit comme une passerelle par laquelle votre application se connecte à la base de données. L'application s'authentifie auprès de ProxySQL, vous devez donc ajouter tous les utilisateurs de tous les nœuds MySQL principaux, ainsi que leurs mots de passe, dans ProxySQL. À partir de ClusterControl, vous pouvez soit créer un nouvel utilisateur à utiliser par l'application - vous pouvez décider de son nom, de son mot de passe, de l'accès aux bases de données accordées et des privilèges MySQL que cet utilisateur aura. Cet utilisateur sera créé à la fois côté MySQL et ProxySQL. La deuxième option, plus adaptée aux infrastructures existantes, consiste à utiliser les utilisateurs de la base de données existante. Vous devez transmettre le nom d'utilisateur et le mot de passe, et cet utilisateur ne sera créé que sur ProxySQL.
La dernière section, "Transaction implicite", ClusterControl configurera ProxySQL pour envoyer tout le trafic au maître si nous avons démarré la transaction avec SET autocommit=0. Sinon, si vous utilisez BEGIN ou START TRANSACTION pour créer une transaction, ClusterControl configurera le fractionnement lecture/écriture dans les règles de requête. Cela permet de s'assurer que ProxySQL traitera correctement les transactions. Si vous ne savez pas comment votre application fait cela, vous pouvez choisir ce dernier.
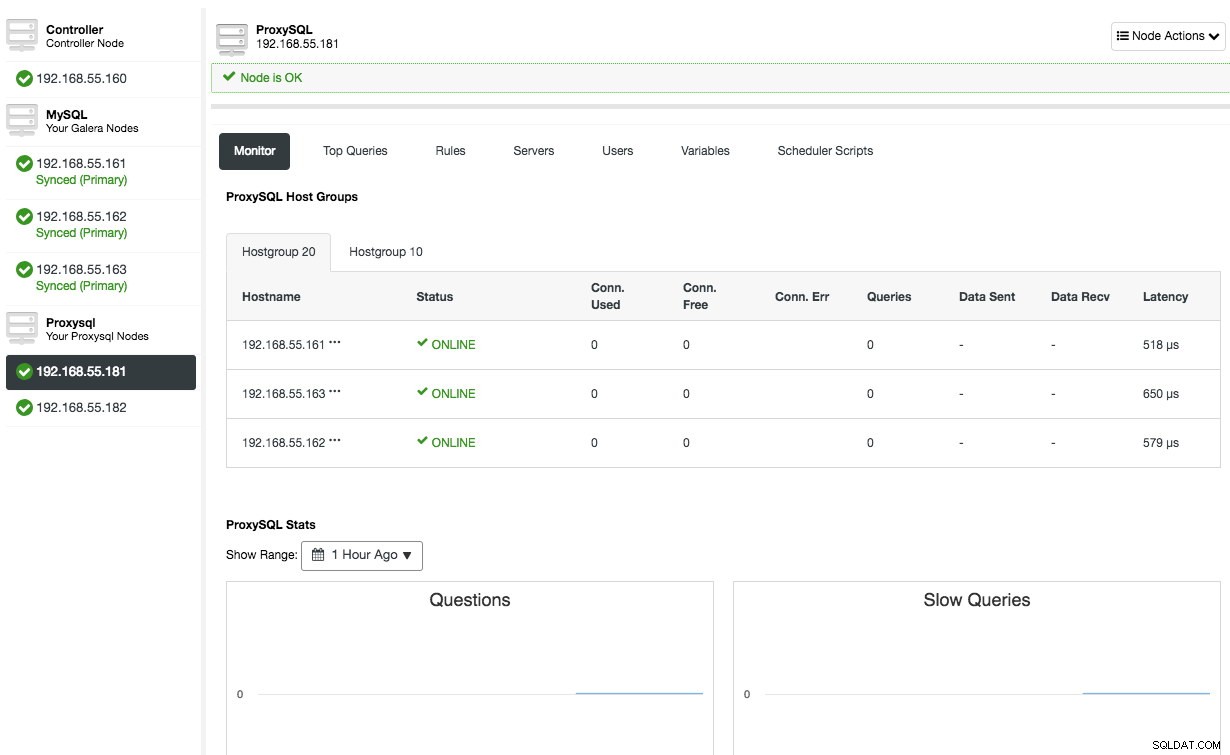
Répétez la même configuration pour le deuxième nœud ProxySQL, à l'exception de la valeur "Adresse du serveur" qui est 192.168.55.182. Une fois cela fait, les deux nœuds seront répertoriés sous l'onglet "Nœuds" -> ProxySQL où vous pourrez les surveiller et les gérer directement depuis l'interface utilisateur :
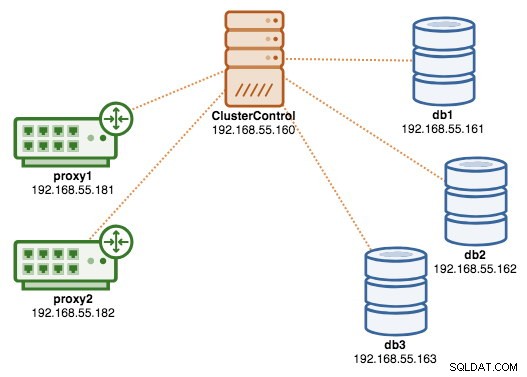
À ce stade, notre architecture ressemble maintenant à ceci :
Si vous souhaitez en savoir plus sur ProxySQL, consultez ce tutoriel - Équilibrage de charge de base de données pour MySQL et MariaDB avec ProxySQL - Tutoriel.
Déploiement de l'adresse IP virtuelle
La dernière partie est l'adresse IP virtuelle. Sans cela, nos équilibreurs de charge (proxy inverses) seraient le maillon faible car ils constitueraient un point de défaillance unique - à moins que l'application n'ait la capacité de rediriger automatiquement les connexions de base de données défaillantes vers un autre équilibreur de charge. Néanmoins, il est recommandé de les unifier à l'aide d'une adresse IP virtuelle et de simplifier le point de terminaison de connexion à la couche de base de données.
Depuis ClusterControl UI -> Ajouter un équilibreur de charge -> Keepalived -> Deploy Keepalived et sélectionnez les deux hôtes ProxySQL que nous avons déployés :
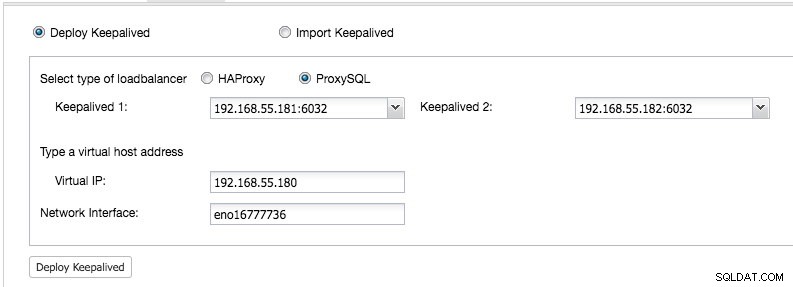
Spécifiez également l'adresse IP virtuelle et l'interface réseau pour lier l'adresse IP. L'interface réseau doit exister sur les deux nœuds ProxySQL. Une fois déployé, vous devriez voir les coches vertes suivantes dans la barre récapitulative du cluster :

À ce stade, notre architecture peut être illustrée comme suit :
Notre cluster de bases de données est maintenant prêt pour une utilisation en production. Vous pouvez y importer votre base de données existante ou créer une nouvelle base de données. Vous pouvez utiliser la fonctionnalité de gestion des schémas et des utilisateurs si la licence d'évaluation n'a pas expiré.
Pour comprendre comment ClusterControl configure Keepalived, consultez cet article de blog, Comment ClusterControl configure l'adresse IP virtuelle et à quoi s'attendre lors du basculement.
Connexion au cluster de bases de données
Du point de vue de l'application et du client, ils doivent se connecter à 192.168.55.180 sur le port 6033 qui est l'adresse IP virtuelle flottant au-dessus des équilibreurs de charge. Par exemple, la configuration de la base de données Wordpress ressemblera à ceci :
/** The name of the database for WordPress */
define( 'DB_NAME', 'wp_myblog' );
/** MySQL database username */
define( 'DB_USER', 'wp_myblog' );
/** MySQL database password */
define( 'DB_PASSWORD', 'mysecr3t' );
/** MySQL hostname - virtual IP address with ProxySQL load-balanced port*/
define( 'DB_HOST', '192.168.55.180:6033' );Si vous souhaitez accéder directement au cluster de bases de données, en contournant l'équilibreur de charge, vous pouvez simplement vous connecter au port 3306 des hôtes de base de données. Ceci est généralement requis par le personnel DBA pour l'administration, la gestion et le dépannage. Avec ClusterControl, la plupart de ces opérations peuvent être effectuées directement depuis l'interface utilisateur.
Réflexions finales
Comme indiqué ci-dessus, le déploiement d'un cluster de bases de données n'est plus une tâche difficile. Une fois déployé, il existe une suite complète de fonctionnalités de surveillance gratuites ainsi que des fonctionnalités commerciales pour la gestion des sauvegardes, le basculement/récupération et autres. Le déploiement rapide de différents types de topologies de cluster/réplication peut être utile lors de l'évaluation de solutions de bases de données à haute disponibilité et de leur adaptation à votre environnement particulier.