IRI propose désormais également des fonctions de recherche floue, à la fois dans ses outils gratuits de profilage de base de données et de fichiers plats, et sous forme de bibliothèques de fonctions de terrain disponibles dans IRI CoSort, FieldShield et Voracity pour améliorer la qualité des données, la sécurité et les capacités MDM. Ceci est le premier d'une série d'articles sur les solutions de recherche floue IRI couvrant leur application à l'amélioration de la qualité des données.
Présentation
La véracité ou la fiabilité des données de l'un des grands mots en "V" (avec volume, variété, vélocité et valeur) dont IRI et al parlent dans le contexte de la gestion des données et des informations d'entreprise. Généralement, l'IRI définit les données douteuses comme ayant un ou plusieurs de ces attributs :
- Mauvaise qualité, car il est incohérent, inexact ou incomplet
- Ambigu (pensez au MDM), imprécis (non structuré) ou trompeur (réseaux sociaux)
- Biais (question d'enquête), bruyant (superflu ou contaminé) ou anormal (valeurs aberrantes)
- Non valide pour toute autre raison (les données sont-elles correctes et exactes pour l'utilisation prévue ?)
- Non sécurisé :contient-il des informations personnelles ou des secrets, et est-il correctement masqué, réversible, etc. ?
Cet article se concentre uniquement sur les nouvelles solutions de recherche floue au premier problème, la qualité des données. D'autres articles de ce blog expliquent comment le logiciel IRI résout les quatre autres problèmes de véracité ; demandez de l'aide pour les trouver si vous ne pouvez pas.
À propos de la recherche floue
Les recherches approximatives trouvent des mots ou des expressions (valeurs) similaires, mais pas nécessairement identiques, à d'autres mots ou expressions (valeurs). Ce type de recherche a de nombreuses utilisations, telles que la recherche d'erreurs de séquence, d'orthographe, de caractères transposés et d'autres que nous aborderons plus tard.
Effectuer une recherche approximative de mots ou d'expressions approximatifs peut aider à trouver des données qui peuvent être des doublons de données précédemment stockées. Cependant, la saisie de l'utilisateur ou la correction automatique peut avoir modifié les données d'une manière ou d'une autre pour donner l'impression que les enregistrements sont indépendants.
Le reste de l'article couvrira quatre fonctions de recherche floues désormais prises en charge par IRI, comment les utiliser pour parcourir vos données et renvoyer ces enregistrements se rapprochant de la valeur de recherche.
1. Levenshtein
L'algorithme Levenshtein fonctionne en prenant deux mots ou expressions et en comptant le nombre d'étapes d'édition nécessaires pour transformer un mot ou une expression en un autre. Moins il faudra d'étapes, plus le mot ou la phrase est susceptible de correspondre. Les étapes que la fonction Levenshtein peut suivre sont :
- Insertion d'un caractère dans le mot ou la phrase
- Suppression d'un caractère du mot ou de la phrase
- Remplacement d'un caractère dans un mot ou une phrase par un autre
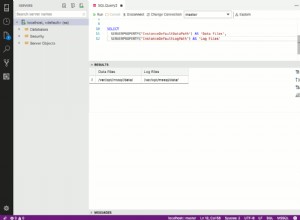
Voici un programme CoSort SortCL (script de travail) illustrant l'utilisation de la fonction de recherche floue de Levenshtein :
/INFILE=LevenshteinSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=LevenshteinOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_levenshtein(NAME, "Barney Oakley"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Deux parties doivent être utilisées pour produire le résultat souhaité.
FS_Result=fs_levenshtein(NAME, "Barney Oakley")
Cette ligne appelle la fonction fs_levenshtein et stocke le résultat dans le champ FS_RESULT. La fonction prend deux paramètres d'entrée :
- Le champ sur lequel exécuter la recherche approximative (NAME dans notre exemple)
- La chaîne à laquelle le champ de saisie sera comparé ("Barney Oakley" dans notre exemple).
/INCLUDE WHERE FS_RESULT GT 50
Cette ligne compare le champ FS_RESULT et vérifie s'il est supérieur à 50, puis seuls les enregistrements avec un FS_RESULT supérieur à 50 sont sortis. Ce qui suit montre la sortie de notre exemple.

Comme le montre la sortie, ce type de recherche est utile pour trouver :
- Noms concaténés
- Bruit
- Les fautes d'orthographe
- Caractères transposés
- Erreurs de transcription
- Erreurs de frappe
La fonction Levenshtein est donc également utile pour identifier les erreurs de saisie de données courantes. Cependant, parmi les quatre algorithmes, c'est celui qui prend le plus de temps à exécuter, car il compare chaque caractère d'une chaîne à chaque caractère de l'autre.
Le coefficient de dés, ou algorithme de dés, divise les mots ou les phrases en paires de caractères, compare ces paires et compte les correspondances. Plus les mots ont de correspondances, plus le mot lui-même est susceptible de correspondre.
Le script SortCL suivant illustre la fonction de recherche floue du coefficient de dés.
/INFILE=DiceSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=DiceOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_dice(NAME, "Robert Thomas Smith"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Deux parties doivent être utilisées pour nous donner le résultat souhaité.
FS_Result=fs_dice(NAME, "Robert Thomas Smith")
Cette ligne appelle la fonction fs_dice et stocke le résultat dans le champ FS_RESULT. La fonction prend deux paramètres d'entrée :
- Le champ sur lequel exécuter la recherche approximative (NAME dans notre exemple).
- La chaîne à laquelle le champ de saisie sera comparé ("Robert Thomas Smith" dans notre exemple).
/INCLUDE WHERE FS_RESULT GT 50
Cette ligne compare le champ FS_RESULT et vérifie s'il est supérieur à 50, puis seuls les enregistrements avec un FS_RESULT supérieur à 50 sont sortis. Ce qui suit montre la sortie de notre exemple.
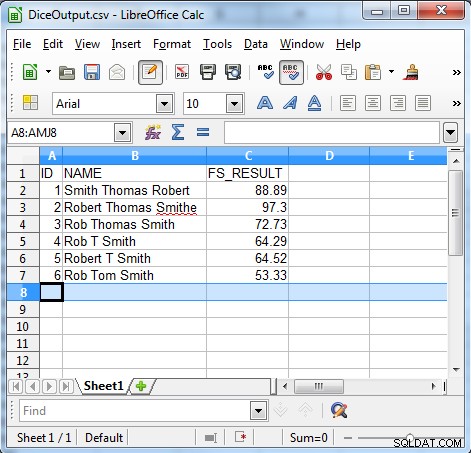
Comme le montre le résultat, l'algorithme du coefficient de dés est utile pour trouver des données incohérentes telles que :
- Erreurs de séquence
- Corrections involontaires
- Surnoms
- Initiales et surnoms
- Utilisation imprévisible des initiales
- Localisation
L'algorithme de dés est plus rapide que le Levenshtein, mais peut devenir moins précis lorsqu'il y a de nombreuses erreurs simples telles que des fautes de frappe.
3. Métaphone et 4. Soundex
les algorithmes Metaphone et Soundex comparent des mots ou des phrases en fonction de leurs sons phonétiques. Pour ce faire, Soundex lit le mot ou la phrase et examine les caractères individuels, tandis que Metaphone examine à la fois les caractères individuels et les groupes de caractères. Ensuite, les deux donnent des codes basés sur l'orthographe et la prononciation du mot.
Le script SortCL suivant illustre les fonctions de recherche Soundex et Metasphone :
/INFILE=SoundexSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=SoundexOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(SE_RESULT=fs_soundex(NAME, "John"), POSITION=3, SEPARATOR=",") /FIELD=(MP_RESULT=fs_metaphone(NAME, "John"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Dans chaque cas, trois parties doivent être utilisées pour nous donner le résultat souhaité.
SE_RESULT=fs_soundex(NAME, "John") MP_RESULT=fs_metaphone(NAME, "John")
La ligne appelle la fonction et stocke le résultat dans le champ RESULT. Les fonctions acceptent toutes deux deux paramètres d'entrée :
- Le champ sur lequel exécuter la recherche approximative (NAME dans notre exemple)
- Le xstring auquel le champ de saisie sera comparé ("John" dans notre exemple)
/INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Cette ligne compare les champs SE_RESULT et MP_RESULT, puis vérifie et renvoie la ligne si l'un est supérieur à 0.
Soundex renvoie soit 100 pour une correspondance, soit 0 si ce n'est pas une correspondance. Metaphone a des résultats plus spécifiques et renvoie 100 pour une correspondance forte, 66 pour une correspondance normale et 33 pour une correspondance mineure.
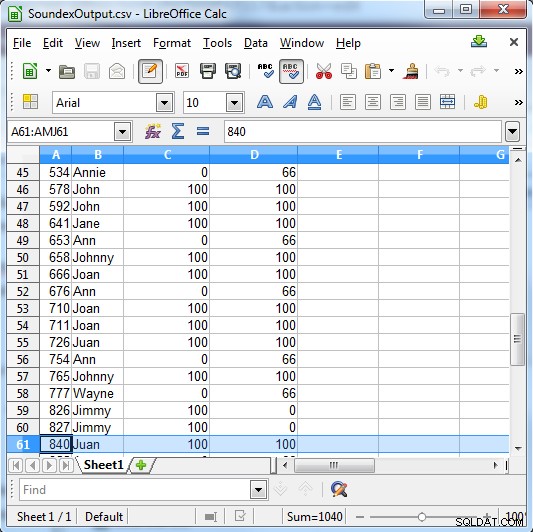
Colonne C montre les résultats Soundex. Colonne D affiche les résultats Metaphone
Comme le montre la sortie, ce type de recherche est utile pour trouver :
- Erreurs phonétiques
Veuillez envoyer vos commentaires sur cet article ci-dessous, et si vous souhaitez utiliser ces fonctions, veuillez contacter votre représentant IRI. Consultez notre prochain article sur l'utilisation de ces algorithmes dans l'assistant de consolidation (qualité) des données IRI Workbench.