Lors de la modification de postgresql.conf , vous avez peut-être remarqué qu'il existe une option appelée full_page_writes . Le commentaire à côté dit quelque chose à propos des écritures de pages partielles, et les gens le laissent généralement défini sur on - ce qui est une bonne chose, comme je l'expliquerai plus tard dans cet article. Il est cependant utile de comprendre ce que font les écritures pleine page, car l'impact sur les performances peut être assez important.
Contrairement à mon article précédent sur le réglage des points de contrôle, ce n'est pas un guide sur la façon de régler le serveur. Il n'y a pas grand-chose que vous puissiez modifier, vraiment, mais je vais vous montrer comment certaines décisions au niveau de l'application (par exemple, le choix des types de données) peuvent interagir avec les écritures pleine page.
Écritures partielles/Pages déchirées
Alors, à quoi correspondent les écrits pleine page ? Comme le commentaire dans postgresql.conf dit que c'est un moyen de récupérer des écritures de page partielles - PostgreSQL utilise des pages de 8 Ko (par défaut), mais d'autres parties de la pile utilisent des tailles de blocs différentes. Les systèmes de fichiers Linux utilisent généralement des pages de 4 ko (il est possible d'utiliser des pages plus petites, mais 4 ko est le maximum sur x86), et au niveau matériel, les anciens disques utilisaient des secteurs de 512 octets tandis que les nouveaux appareils écrivent souvent des données en gros morceaux (souvent 4 ko ou même 8 ko) .
Ainsi, lorsque PostgreSQL écrit la page de 8 Ko, les autres couches de la pile de stockage peuvent la diviser en plus petits morceaux, gérés séparément. Cela pose un problème concernant l'atomicité d'écriture. La page PostgreSQL de 8 Ko peut être divisée en deux pages de système de fichiers de 4 Ko, puis en secteurs de 512 Ko. Maintenant, que se passe-t-il si le serveur plante (coupure de courant, bug du noyau, …) ?
Même si le serveur utilise un système de stockage conçu pour faire face à de telles pannes (SSD avec condensateurs, contrôleurs RAID avec batteries, …), le noyau découpe déjà les données en pages de 4ko. Il est donc possible que la base de données ait écrit une page de données de 8 Ko, mais seule une partie de celle-ci a été enregistrée sur le disque avant le crash.
À ce stade, vous pensez probablement que c'est exactement la raison pour laquelle nous avons un journal des transactions (WAL), et vous avez raison ! Ainsi, après le démarrage du serveur, la base de données lira WAL (depuis le dernier point de contrôle terminé) et appliquera à nouveau les modifications pour s'assurer que les fichiers de données sont complets. Simple.
Mais il y a un hic - la récupération n'applique pas les modifications aveuglément, elle a souvent besoin de lire les pages de données, etc. Ce qui suppose que la page n'est pas déjà bloquée d'une manière ou d'une autre, par exemple en raison d'une écriture partielle. Ce qui semble un peu contradictoire, car pour corriger la corruption des données, nous supposons qu'il n'y a pas de corruption des données.
Les écritures pleine page sont un moyen de contourner cette énigme - lors de la première modification d'une page après un point de contrôle, la page entière est écrite dans WAL. Cela garantit que lors de la récupération, le premier enregistrement WAL touchant une page contient la page entière, éliminant ainsi le besoin de lire la page - éventuellement cassée - à partir du fichier de données.
Amplification de l'écriture
Bien sûr, la conséquence négative de ceci est l'augmentation de la taille du WAL - changer un seul octet sur la page de 8 Ko enregistrera le tout dans le WAL. L'écriture pleine page ne se produit que lors de la première écriture après un point de contrôle, donc rendre les points de contrôle moins fréquents est un moyen d'améliorer la situation - généralement, il y a une courte "rafale" d'écritures pleine page après un point de contrôle, puis relativement peu d'écritures pleine page jusqu'à la fin d'un point de contrôle.
Clés UUID ou BIGSERIAL
Mais il existe des interactions inattendues avec les décisions de conception prises au niveau de l'application. Supposons que nous ayons une table simple avec une clé primaire, soit un BIGSERIAL ou UUID , et nous y insérons des données. Y aura-t-il une différence dans la quantité de WAL générée (en supposant que nous insérons le même nombre de lignes) ?
Il semble raisonnable de s'attendre à ce que les deux cas produisent à peu près la même quantité de WAL, mais comme l'illustrent les graphiques suivants, il existe une énorme différence dans la pratique.
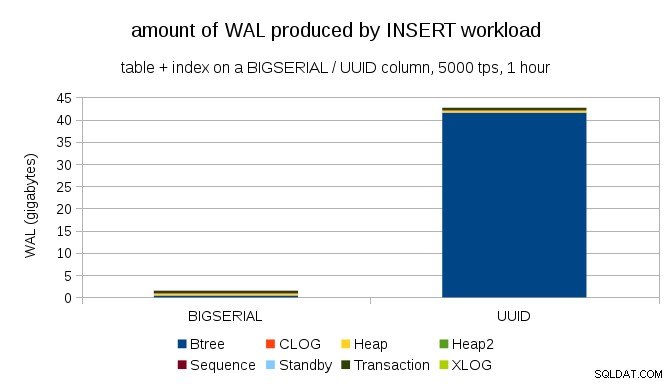
Cela montre la quantité de WAL produite pendant un benchmark de 1h, limité à 5000 insertions par seconde. Avec BIGSERIAL clé primaire cela produit ~ 2 Go de WAL, tandis qu'avec UUID c'est plus de 40 Go. C'est une différence assez significative, et il est clair que la plupart des WAL sont associés à l'index qui sauvegarde la clé primaire. Regardons comme types d'enregistrements WAL.
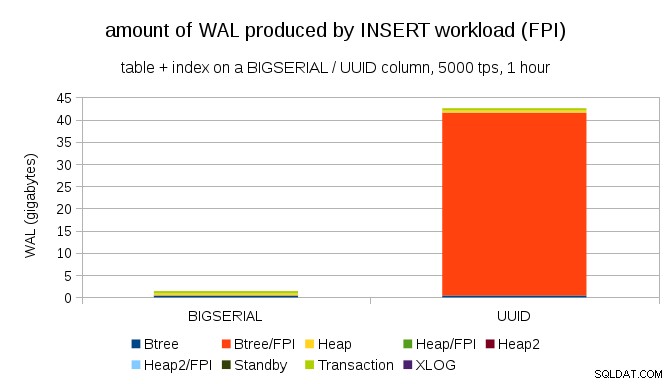
De toute évidence, la grande majorité des enregistrements sont des images pleine page (FPI), c'est-à-dire le résultat d'écritures pleine page. Mais pourquoi cela se produit-il ?
Bien sûr, cela est dû au UUID inhérent aléatoire. Avec BIGSERIAL new sont séquentiels et sont donc insérés dans les mêmes pages feuilles de l'index btree. Comme seule la première modification d'une page déclenche l'écriture pleine page, seule une infime partie des enregistrements WAL sont des FPI. Avec UUID c'est un cas complètement différent, bien sûr - les valeurs ne sont pas séquentielles du tout, en fait chaque insertion est susceptible de toucher une page de feuille d'index de feuille complètement nouvelle (en supposant que l'index est assez grand).
La base de données ne peut pas faire grand-chose :la charge de travail est simplement de nature aléatoire, déclenchant de nombreuses écritures pleine page.
Il n'est pas difficile d'obtenir une amplification d'écriture similaire même avec BIGSERIAL clés, bien sûr. Il ne nécessite qu'une charge de travail différente - par exemple avec UPDATE charge de travail, mise à jour aléatoire des enregistrements avec une distribution uniforme, le graphique ressemble à ceci :
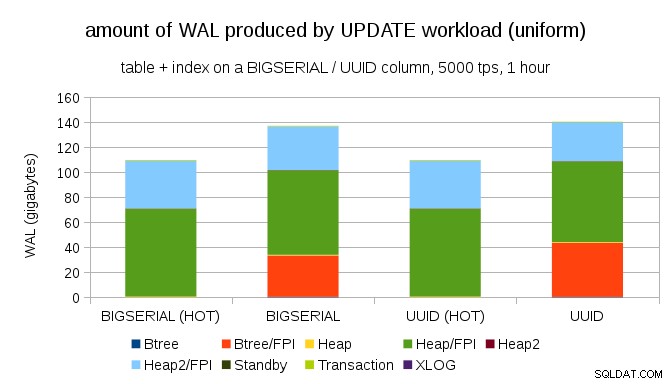
Soudain, les différences entre les types de données ont disparu - l'accès est aléatoire dans les deux cas, ce qui entraîne presque exactement la même quantité de WAL produite. Une autre différence est que la plupart des WAL sont associés à des "tas", c'est-à-dire des tables, et non des index. Les cas "HOT" ont été conçus pour permettre l'optimisation HOT UPDATE (c'est-à-dire la mise à jour sans avoir à toucher à un index), ce qui élimine pratiquement tout le trafic WAL lié à l'index.
Mais vous pourriez dire que la plupart des applications ne mettent pas à jour l'ensemble des données. Habituellement, seul un petit sous-ensemble de données est "actif" - les gens n'accèdent qu'aux messages des derniers jours sur un forum de discussion, aux commandes non résolues dans une boutique en ligne, etc. Comment cela change-t-il les résultats ?
Heureusement, pgbench prend en charge les distributions non uniformes, et par exemple avec une distribution exponentielle touchant 1 % de sous-ensemble de données ~ 25 % du temps, le graphique ressemble à ceci :
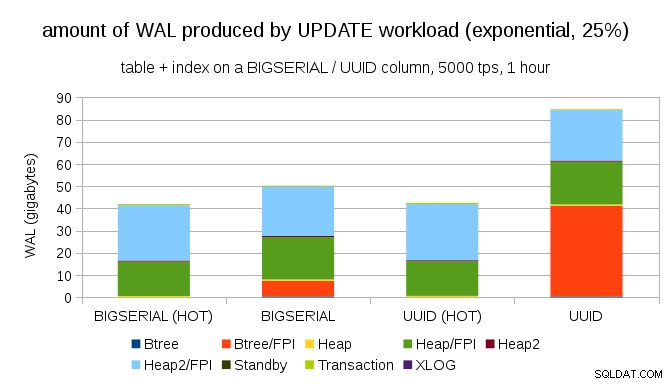
Et après avoir rendu la distribution encore plus asymétrique, touchant le sous-ensemble de 1 % environ 75 % du temps :
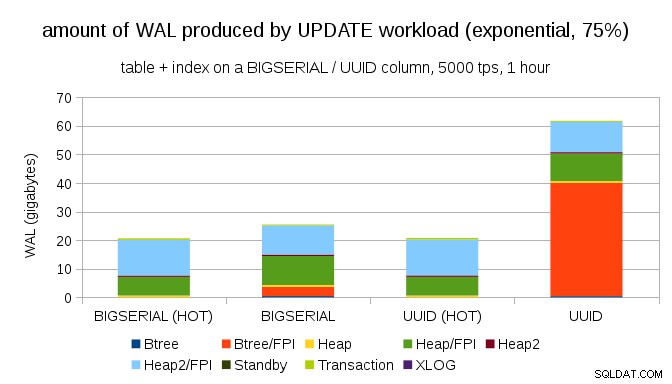
Cela montre à nouveau à quel point le choix des types de données peut faire une grande différence, ainsi que l'importance du réglage des mises à jour HOT.
Pages de 8 Ko et 4 Ko
Une question intéressante est de savoir combien de trafic WAL pourrions-nous économiser en utilisant des pages plus petites dans PostgreSQL (ce qui nécessite de compiler un package personnalisé). Dans le meilleur des cas, cela pourrait économiser jusqu'à 50 % de WAL, grâce à la journalisation de seulement 4 ko au lieu de 8 ko. Pour la charge de travail avec des mises à jour uniformément distribuées, cela ressemble à ceci :
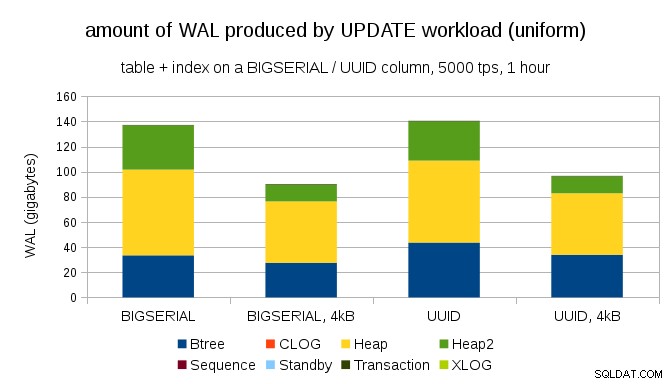
L'économie n'est donc pas exactement de 50 %, mais la réduction d'environ 140 Go à environ 90 Go est encore assez importante.
Avons-nous toujours besoin d'écritures pleine page ?
Cela peut sembler ridicule après avoir expliqué le danger des écritures partielles, mais peut-être que désactiver les écritures pleine page pourrait être une option viable, du moins dans certains cas.
Tout d'abord, je me demande si les systèmes de fichiers Linux modernes sont toujours vulnérables aux écritures partielles ? Le paramètre a été introduit dans PostgreSQL 8.1 publié en 2005, donc peut-être que certaines des nombreuses améliorations du système de fichiers introduites depuis lors en font un non-problème. Probablement pas universellement pour les charges de travail arbitraires, mais peut-être que supposer une condition supplémentaire (par exemple, utiliser une taille de page de 4 Ko dans PostgreSQL) serait suffisante ? De plus, PostgreSQL n'écrase jamais uniquement un sous-ensemble de la page de 8 Ko - la page entière est toujours écrite.
J'ai fait beaucoup de tests récemment en essayant de déclencher une écriture partielle, et je n'ai pas encore réussi à provoquer un seul cas. Bien sûr, ce n'est pas vraiment la preuve que le problème n'existe pas. Mais même si le problème persiste, les sommes de contrôle des données peuvent constituer une protection suffisante (cela ne résoudra pas le problème, mais vous indiquera au moins qu'il y a une page cassée).
Deuxièmement, de nombreux systèmes s'appuient aujourd'hui sur des répliques de réplication en continu - au lieu d'attendre que le serveur redémarre après un problème matériel (ce qui peut prendre beaucoup de temps) et de passer ensuite plus de temps à effectuer une récupération, les systèmes passent simplement en mode de secours. Si la base de données sur le primaire défaillant est supprimée (puis clonée à partir du nouveau primaire), les écritures partielles ne posent aucun problème.
Mais je suppose que si nous commencions à recommander cela, alors "Je ne sais pas comment les données ont été corrompues, je viens de définir full_page_writes=off sur les systèmes !" deviendrait l'une des phrases les plus courantes juste avant la mort pour les DBA (avec le "J'ai vu ce serpent sur reddit, il n'est pas venimeux").
Résumé
Vous ne pouvez pas faire grand-chose pour régler directement les écritures pleine page. Pour la plupart des charges de travail, la plupart des écritures pleine page se produisent juste après un point de contrôle, puis disparaissent jusqu'au point de contrôle suivant. Il est donc important de régler les points de contrôle pour qu'ils ne se produisent pas trop souvent.
Certaines décisions au niveau de l'application peuvent augmenter le caractère aléatoire des écritures dans les tables et les index - par exemple, les valeurs UUID sont intrinsèquement aléatoires, transformant même la charge de travail INSERT simple en mises à jour d'index aléatoires. Le schéma utilisé dans les exemples était plutôt trivial - en pratique, il y aura des index secondaires, des clés étrangères, etc. Mais utiliser les clés primaires BIGSERIAL en interne (et conserver l'UUID comme clés de substitution) réduirait au moins l'amplification en écriture.
Je suis vraiment intéressé par la discussion sur la nécessité d'écritures pleine page sur les noyaux / systèmes de fichiers actuels. Malheureusement, je n'ai pas trouvé beaucoup de ressources, donc si vous avez des informations pertinentes, faites-le moi savoir.