La semaine dernière, j'ai publié un article intitulé #BackToBasics :DATEFROMPARTS() , où j'ai montré comment utiliser cette fonction 2012+ pour des requêtes de plage de dates plus propres et sargables. Je l'ai utilisé pour démontrer que si vous utilisez un prédicat de date ouvert et que vous avez un index sur la colonne date/heure pertinente, vous pouvez vous retrouver avec une bien meilleure utilisation de l'index et des E/S inférieures (ou, dans le pire des cas , de même, si une recherche ne peut pas être utilisée pour une raison quelconque, ou s'il n'existe aucun index approprié :
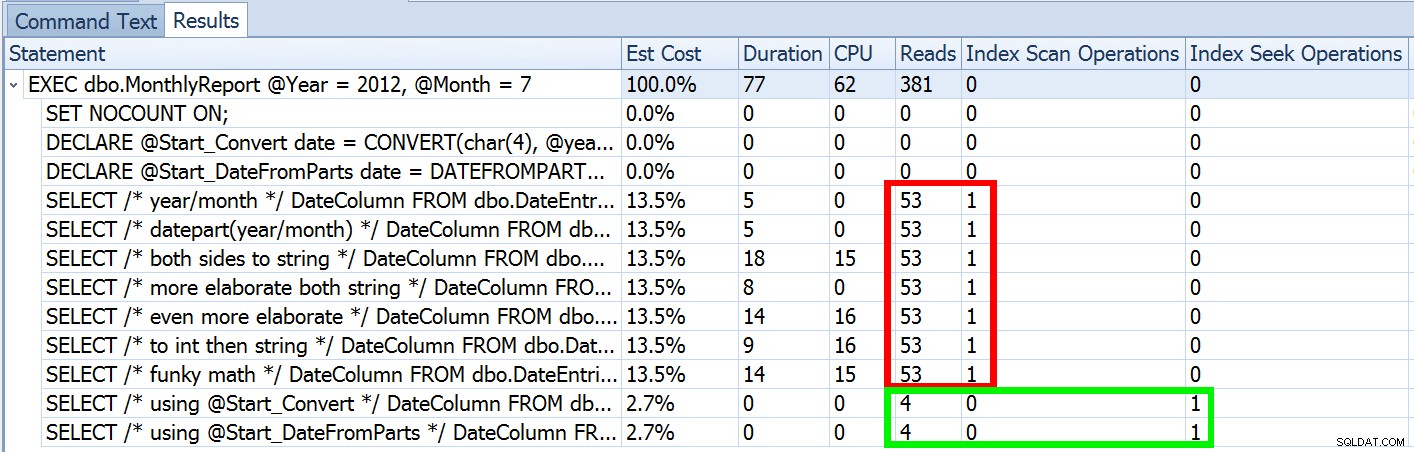
Mais ce n'est qu'une partie de l'histoire (et pour être clair, DATEFROMPARTS() n'est pas techniquement nécessaire pour obtenir une recherche, c'est juste plus propre dans ce cas). Si nous dézoomons un peu, nous remarquons que nos estimations sont loin d'être exactes, une complexité que je ne voulais pas introduire dans le post précédent :
Ce n'est pas rare à la fois pour les prédicats d'inégalité et pour les analyses forcées. Et bien sûr, la méthode que j'ai suggérée ne donnerait-elle pas les statistiques les plus inexactes ? Voici l'approche de base (vous pouvez obtenir le schéma de la table, les index et les exemples de données de mon article précédent) :
CREATE PROCEDURE dbo.MonthlyReport_Original
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO Maintenant, des estimations inexactes ne seront pas toujours un problème, mais cela peut causer des problèmes avec des choix de plan inefficaces aux deux extrêmes. Un plan unique peut ne pas être optimal lorsque la plage choisie génère un très petit ou un très grand pourcentage de la table ou de l'index, et cela peut devenir très difficile pour SQL Server de prédire quand la distribution des données est inégale. Joseph Sack a décrit les éléments les plus typiques que les mauvaises estimations peuvent affecter dans son article :"Ten Common Threats to Execution Plan Quality :"
"[…] les mauvaises estimations de ligne peuvent avoir un impact sur diverses décisions, notamment la sélection d'index, les opérations de recherche ou d'analyse, l'exécution parallèle ou série, la sélection d'algorithme de jointure, la sélection de jointure physique interne ou externe (par exemple, la construction ou la sonde), la génération de spool, les recherches de signets par rapport à l'accès complet en cluster ou à la table de tas, la sélection d'agrégats de flux ou de hachage, et si une modification de données utilise ou non un plan large ou étroit.
Il y en a d'autres aussi, comme les allocations de mémoire qui sont trop grandes ou trop petites. Il poursuit en décrivant certaines des causes les plus courantes de mauvaises estimations, mais la principale cause dans ce cas est absente de sa liste :les estimations approximatives. Parce que nous utilisons une variable locale pour changer le int entrant paramètres à une seule date locale variable, SQL Server ne sait pas quelle sera la valeur, il fait donc des suppositions standardisées de cardinalité basées sur l'ensemble de la table.
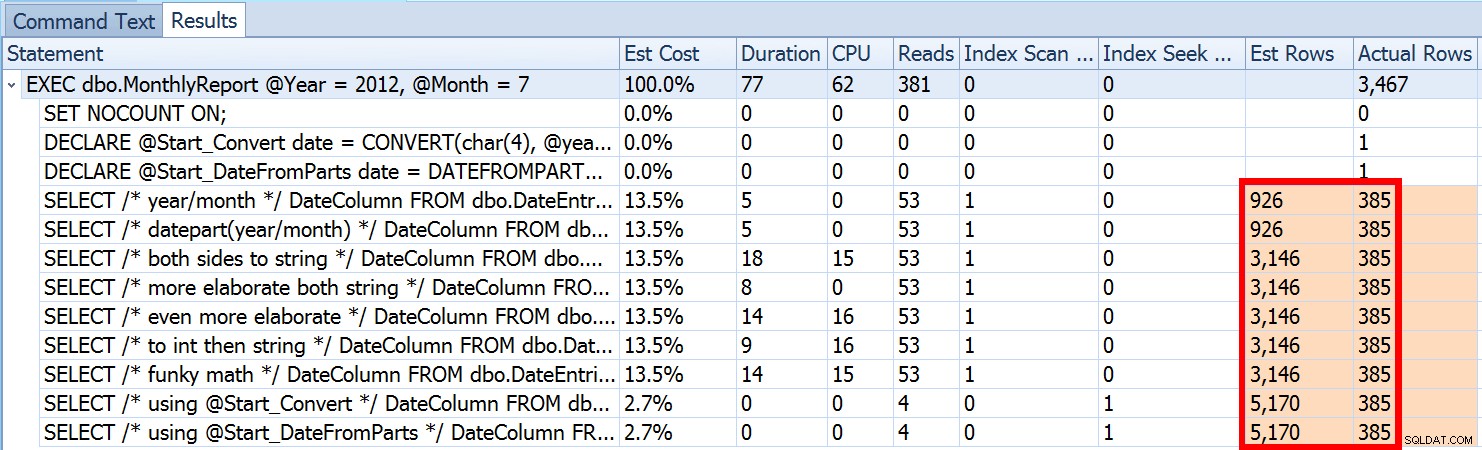
Nous avons vu ci-dessus que l'estimation de mon approche suggérée était de 5 170 lignes. Maintenant, nous savons qu'avec un prédicat d'inégalité, et avec SQL Server ne connaissant pas les valeurs des paramètres, il devinera 30 % de la table. 31,645 * 0.3 n'est pas 5 170. Ni 31,465 * 0.3 * 0.3 , quand on se souvient qu'il y a en fait deux prédicats travaillant sur la même colonne. Alors d'où vient cette valeur de 5 170 ?
Comme le décrit Paul White dans son article, "Estimation de la cardinalité pour plusieurs prédicats", le nouvel estimateur de cardinalité dans SQL Server 2014 utilise une temporisation exponentielle, il multiplie donc le nombre de lignes de la table (31 465) par la sélectivité du premier prédicat (0,3) , puis multiplie cela par la racine carrée de la sélectivité du second prédicat (~0.547723).
31 645 * (0,3) * SQRT(0,3) ~=5 170,227Donc, nous pouvons maintenant voir où SQL Server a proposé son estimation ; Quelles sont les méthodes que nous pouvons utiliser pour y remédier ?
- Transmettre les paramètres de date. Lorsque cela est possible, vous pouvez modifier l'application afin qu'elle transmette des paramètres de date appropriés au lieu de paramètres entiers séparés.
- Utilisez une procédure wrapper. Une variante de la méthode #1 - par exemple si vous ne pouvez pas changer l'application - consisterait à créer une deuxième procédure stockée qui accepte les paramètres de date construits à partir de la première.
- Utilisez
OPTION (RECOMPILE). Au moindre coût de compilation à chaque exécution de la requête, cela oblige SQL Server à optimiser en fonction des valeurs présentées à chaque fois, au lieu d'optimiser un plan unique pour des valeurs de paramètre inconnues, premières ou moyennes. (Pour un traitement approfondi de ce sujet, voir "Parameter Sniffing, Embedding, and the RECOMPILE Options" de Paul White.
- Utilisez SQL dynamique. Faire en sorte que SQL dynamique accepte la
dateconstruite la variable force le bon paramétrage (comme si vous aviez appelé une procédure stockée avec unedateparamètre), mais c'est un peu moche, et plus difficile à entretenir.
- Désordre avec les indices et les indicateurs de suivi. Paul White en parle dans l'article susmentionné.
Je ne vais pas suggérer qu'il s'agit d'une liste exhaustive, et je ne vais pas réitérer les conseils de Paul sur les indices ou les indicateurs de trace, donc je vais juste me concentrer sur montrer comment les quatre premières approches peuvent atténuer le problème avec de mauvaises estimations .
1. Paramètres de date
CREATE PROCEDURE dbo.MonthlyReport_TwoDates
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Two Dates */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO 2. Procédure d'emballage
CREATE PROCEDURE dbo.MonthlyReport_WrapperTarget
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Wrapper */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO
CREATE PROCEDURE dbo.MonthlyReport_WrapperSource
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
EXEC dbo.MonthlyReport_WrapperTarget @Start = @Start, @End = @End;
END
GO 3. OPTION (RECOMPILER)
CREATE PROCEDURE dbo.MonthlyReport_Recompile
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT /* Recompile */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End OPTION (RECOMPILE);
END
GO 4. SQL dynamique
CREATE PROCEDURE dbo.MonthlyReport_DynamicSQL
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
DECLARE @sql nvarchar(max) = N'SELECT /* Dynamic SQL */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;';
EXEC sys.sp_executesql @sql, N'@Start date, @End date', @Start, @End;
END
GO
Les épreuves
Avec les quatre ensembles de procédures en place, il était facile de construire des tests qui me montreraient les plans et les estimations dérivées de SQL Server. Étant donné que certains mois sont plus occupés que d'autres, j'ai choisi trois mois différents et je les ai tous exécutés plusieurs fois.
DECLARE @Year int = 2012, @Month int = 7; -- 385 rows DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1); DECLARE @End date = DATEADD(MONTH, 1, @Start); EXEC dbo.MonthlyReport_Original @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_TwoDates @Start = @Start, @End = @End; EXEC dbo.MonthlyReport_WrapperSource @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_Recompile @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_DynamicSQL @Year = @Year, @Month = @Month; /* repeat for @Year = 2011, @Month = 9 -- 157 rows */ /* repeat for @Year = 2014, @Month = 4 -- 2,115 rows */
Le résultat? Chaque plan donne le même Index Seek, mais les estimations ne sont correctes que sur les trois plages de dates dans l'OPTION (RECOMPILE) version. Les autres continuent d'utiliser les estimations dérivées du premier ensemble de paramètres (juillet 2012), et ainsi de suite pendant qu'ils obtiennent de meilleures estimations pour le premier l'exécution, cette estimation ne sera pas nécessairement meilleure pour la suite exécutions utilisant différents paramètres (un cas d'école classique de reniflage de paramètres) :
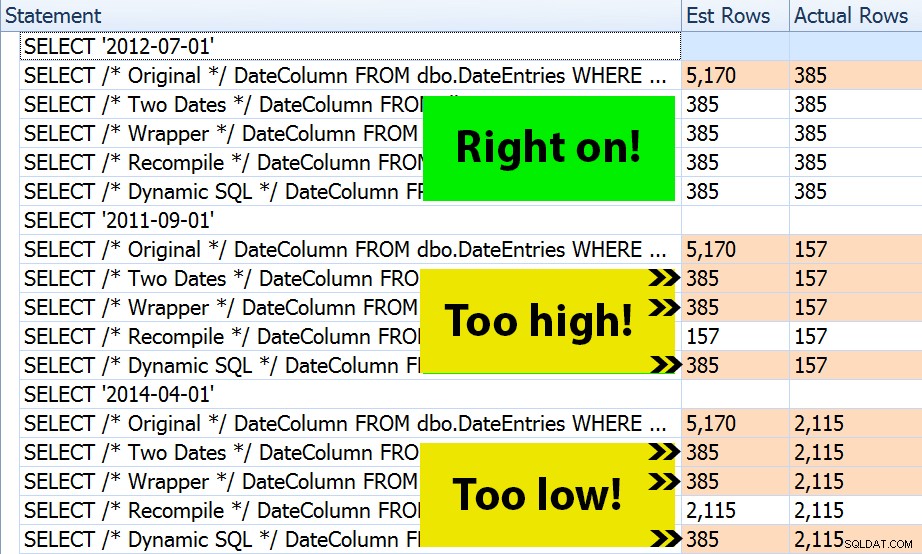
Notez que ce qui précède n'est pas une sortie *exacte* de SQL Sentry Plan Explorer - par exemple, j'ai supprimé les lignes de l'arborescence d'instructions qui affichaient les appels de procédure stockée externe et les déclarations de paramètres.
Ce sera à vous de déterminer si la tactique consistant à compiler à chaque fois est la meilleure pour vous, ou si vous devez "réparer" quelque chose en premier lieu. Ici, nous nous sommes retrouvés avec les mêmes plans, et aucune différence notable dans les mesures de performances d'exécution. Mais sur des tables plus grandes, avec une distribution de données plus asymétrique et des écarts plus importants dans les valeurs de prédicat (par exemple, envisagez un rapport qui peut couvrir une semaine, une année et n'importe quoi entre les deux), cela peut valoir la peine d'être étudié. Et notez que vous pouvez combiner des méthodes ici - par exemple, vous pouvez passer aux paramètres de date appropriés * et * ajouter OPTION (RECOMPILE) , si vous le souhaitez.
Conclusion
Dans ce cas précis, qui est une simplification intentionnelle, l'effort pour obtenir les estimations correctes n'a pas vraiment payé - nous n'avons pas obtenu de plan différent et les performances d'exécution étaient équivalentes. Il existe certainement d'autres cas, cependant, où cela fera une différence, et il est important de reconnaître la disparité des estimations et de déterminer si cela pourrait devenir un problème à mesure que vos données augmentent et/ou que votre distribution est biaisée. Malheureusement, il n'y a pas de réponse noire ou blanche, car de nombreuses variables affecteront la justification de la surcharge de compilation - comme dans de nombreux scénarios, IT DEPENDS™ …