Compte tenu du cas d'utilisation majeur actuel d'une base de données pour récupérer des données, il devient très important que ses performances soient très élevées et cela ne peut être réalisé que si les données sont récupérées de la manière la plus efficace possible à partir du stockage. Il y a eu de nombreuses inventions et implémentations réussies pour atteindre le même objectif. L'une des approches bien connues adoptées par la plupart des bases de données consiste à avoir un index sur la table.
Qu'est-ce qu'un index de base de données ?
L'index de base de données, comme son nom l'indique, maintient un index des données réelles et améliore ainsi les performances pour récupérer les données de la table réelle. Dans une terminologie plus basée sur la base de données, l'index permet de récupérer la page contenant des données indexées dans un parcours très minimal car les données sont triées dans un ordre spécifique. L'avantage de l'indexation se fait au prix d'un espace de stockage supplémentaire afin d'écrire des données supplémentaires. Les index sont spécifiques à la table sous-jacente et consistent en une ou plusieurs clés (c'est-à-dire une ou plusieurs colonnes de la table spécifiée). Il existe principalement deux types d'architecture d'index
- Index groupé :les données d'index sont stockées avec d'autres parties de données et les données sont triées en fonction de la clé d'index. Il ne peut y avoir qu'un seul index dans cette catégorie pour une table spécifiée.
- Index non clusterisé :les données d'index sont stockées séparément et comportent un pointeur vers le stockage où une autre partie des données est stockée. Ceci est également connu sous le nom d'index secondaire. Il peut y avoir autant d'index de cette catégorie que vous le souhaitez sur une table spécifiée.
Il existe diverses structures de données utilisées pour la mise en œuvre des index, certaines des plus largement adoptées par la majorité des bases de données sont B-Tree et Hash.
Qu'est-ce qu'un index PostgreSQL ?
PostgreSQL ne prend en charge que les index non clusterisés. Cela signifie données d'index et des données complètes (ci-après appelées données de tas ) sont stockés dans un stockage séparé. Les index non clusterisés sont comme la "table des matières" dans n'importe quel document, dans lequel nous vérifions d'abord le numéro de page, puis vérifions ces numéros de page pour lire l'intégralité du contenu. Afin d'obtenir les données complètes basées sur un index, il maintient un pointeur vers les données de tas correspondantes. C'est la même chose qu'après avoir connu le numéro de page, il doit aller sur cette page et obtenir le contenu réel de la page.
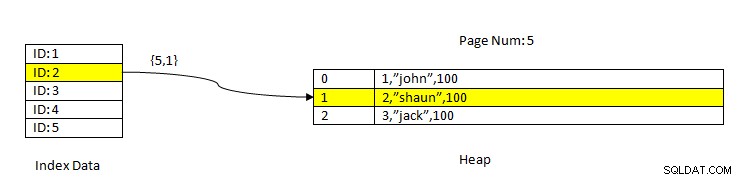 PostgreSQL :lecture des données à l'aide de l'index
PostgreSQL :lecture des données à l'aide de l'index Par exemple, considérons une table avec trois colonnes et un index sur la colonne ID . Afin de LIRE les données sur la base de la clé ID=2, tout d'abord, les données indexées avec la valeur ID 2 sont recherchées. Celui-ci contient un pointeur (appelé pointeur d'élément) en termes de numéro de page (c'est-à-dire de numéro de bloc) et de décalage des données dans cette page. Dans l'exemple actuel, l'index pointe vers le numéro de page 5 et le deuxième élément de ligne de la page qui, à son tour, maintient le décalage vers l'ensemble des données (2, "Shaun", 100). Notez que les données entières contiennent également les données indexées, ce qui signifie que les mêmes données sont répétées dans deux stockages.
Comment INDEX aide-t-il à améliorer les performances ? Eh bien, pour sélectionner un enregistrement INDEX, il n'analyse pas toutes les pages de manière séquentielle, il suffit plutôt d'analyser partiellement certaines des pages à l'aide de la structure de données Index sous-jacente. Mais il y a une torsion, puisque chaque enregistrement trouvé à partir des données d'index, il doit rechercher dans les données Heap des données entières, ce qui provoque beaucoup d'E/S aléatoires et il est considéré comme plus lent que les E/S séquentielles. Donc, seulement si un petit pourcentage d'enregistrements est sélectionné (ce qui a été décidé en fonction du coût de l'optimiseur PostgreSQL), alors seul PostgreSQL choisit Index Scan, sinon même s'il y a un index sur la table, il continue à utiliser Sequence Scan.
En résumé, bien que la création d'index accélère les performances, elle doit être choisie avec soin car elle entraîne une surcharge en termes de stockage et une dégradation des performances d'INSERT.
Maintenant, nous pouvons nous demander, au cas où nous n'aurions besoin que de la partie index des données, pouvons-nous récupérer uniquement à partir de la page de stockage de l'index ? Eh bien, la réponse à cette question est directement liée au fonctionnement de MVCC sur le stockage d'index, comme expliqué ci-après.
Utilisation de MVCC pour l'indexation
Comme les pages Heap, la page d'index gère plusieurs versions du tuple d'index, mais elle ne gère pas les informations de visibilité. Comme expliqué dans mon précédent MVCC blog, afin de décider de la version visible appropriée des tuples, il faut comparer la transaction. La transaction qui a inséré/mis à jour/supprimé le tuple est maintenue avec le tuple de tas, mais la même chose n'est pas maintenue avec le tuple d'index. Ceci est purement fait pour économiser de l'espace de stockage et c'est un compromis entre l'espace et les performances.
Revenons maintenant à la question initiale, puisque les informations de visibilité dans le tuple d'index ne sont pas là, il doit consulter le tuple de tas correspondant pour voir si les données sélectionnées sont visibles. Ainsi, même si d'autres parties des données du tuple de tas ne sont pas nécessaires, vous devez toujours accéder aux pages de tas pour vérifier la visibilité. Mais encore une fois, il y a une torsion dans le cas où tous les tuples d'une page donnée (page pointée par l'index, c'est-à-dire ItemPointer) sont visibles, il n'est donc pas nécessaire de faire référence à chaque élément de la page Heap pour un "contrôle de visibilité" et donc les données peuvent être renvoyées uniquement à partir de la page Index. Ce cas particulier est appelé "Index Only Scan". Afin de prendre en charge cela, PostgreSQL maintient une carte de visibilité pour chaque page afin de vérifier la visibilité au niveau de la page.
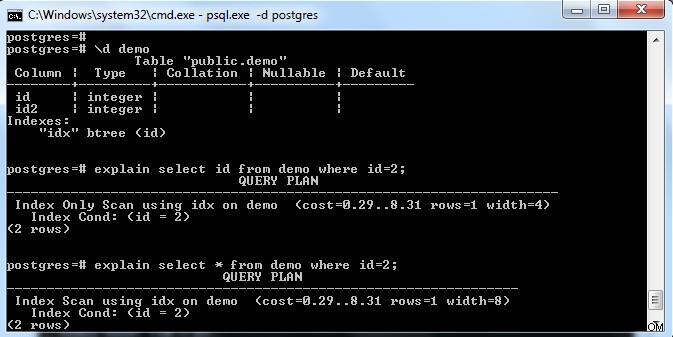
Comme le montre l'image ci-dessus, il y a un index sur la table "demo" avec une clé sur la colonne "id". Si nous essayons de sélectionner uniquement le champ d'index (c'est-à-dire l'identifiant), il choisit alors "l'analyse de l'index uniquement" (en considérant la page de référence entièrement visible).
Index clusterisé
Il n'y a pas de prise en charge de l'index clusterisé direct dans PostgreSQL mais il existe un moyen indirect d'obtenir partiellement la même chose. Ceci est réalisé par les commandes SQL ci-dessous :
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]La première commande demande à la base de données de regrouper une table (c'est-à-dire de trier la table) en utilisant l'index donné. Cet index devrait déjà avoir été créé. Ce regroupement n'est qu'une seule opération et son impact ne persiste pas après l'opération suivante sur cette table, c'est-à-dire que si plusieurs enregistrements sont insérés/mis à jour, la table peut ne pas rester ordonnée. Si l'utilisateur a besoin de garder la table groupée (ordonnée), il peut utiliser la première commande sans donner de nom d'index.
La deuxième commande n'est utile que pour re-cluster la table (c'est-à-dire la table qui a déjà été regroupée à l'aide d'un index). Cette commande regroupe à nouveau toutes les tables de la base de données actuelle visible par l'utilisateur actuellement connecté.
Par exemple, dans la figure ci-dessous, le premier SELECT renvoie les enregistrements dans un ordre non trié car il n'y a pas d'index clusterisé. Même s'il existe déjà un index non clusterisé, les enregistrements sont sélectionnés dans la zone de tas où les enregistrements ne sont pas triés.
Le deuxième SELECT renvoie les enregistrements triés par colonne "id" car ils ont été regroupés à l'aide de l'index contenant la colonne "id".
Le troisième SELECT renvoie des enregistrements partiels dans l'ordre trié mais les enregistrements nouvellement insérés ne sont pas triés. Le quatrième SELECT renvoie à nouveau tous les enregistrements dans l'ordre trié car la table a de nouveau été regroupée
 Commande de cluster PostgreSQL
Commande de cluster PostgreSQL Type d'index
PostgreSQL fournit plusieurs types d'index comme ci-dessous :
- B-Tree
- Hachage
- GIST
- GIN
- BRIN
Chaque type d'index implémente différents types de structure de données sous-jacente, ce qui convient le mieux à différents types de requêtes. Par défaut, l'index B-Tree est créé, ce qui est des index largement utilisés. Les détails de chaque type d'index seront couverts dans un futur blog.
Divers :index partiel et d'expression
Nous n'avons discuté que des index sur une ou plusieurs colonnes d'une table mais il existe deux autres façons de créer des index sur PostgreSQL
- Index partiel : L'index partiel est un index construit à l'aide du sous-ensemble d'une colonne clé pour une table particulière. Le sous-ensemble est défini par l'expression conditionnelle donnée lors de la création de l'index. Ainsi, avec l'index partiel, l'espace de stockage pour stocker les données d'index est enregistré. L'utilisateur doit donc choisir la condition de manière à ce que ces valeurs ne soient pas très courantes, car pour les valeurs plus fréquentes (communes), le balayage d'index ne sera de toute façon pas choisi. Le reste de la fonctionnalité reste le même que pour un index normal. Exemple :Index partiel
- Indice d'expression : Les index d'expression donnent un autre type de flexibilité dans PostgreSQL. Tous les index discutés jusqu'à présent, y compris les index partiels, sont sur un ensemble particulier de colonnes. Mais que se passe-t-il si une requête implique l'accès à une table basée sur l'expression (expression impliquant une ou plusieurs colonnes), sans index d'expression, elle ne choisira pas le parcours d'index. Ainsi, afin d'accéder rapidement à ce type de requêtes, PostgreSQL permet de créer un index sur une expression. Le reste de la fonctionnalité reste le même que pour un index normal.
 Exemple :Index d'expressions
Exemple :Index d'expressions
Stockage d'index dans InnoDB
L'utilisation et la fonctionnalité d'Index sont essentiellement les mêmes que celles de PostgreSQL avec une différence majeure en termes d'index clusterisé.
InnoDB prend en charge deux catégories d'index :
- Index clusterisé
- Index secondaire
Index clusterisé
L'index clusterisé est un type spécial d'index dans InnoDB. Ici, les données indexées ne sont pas stockées séparément, mais font partie de l'ensemble des données de la ligne. En d'autres termes, l'index clusterisé force simplement les données de la table à être triées physiquement à l'aide de la colonne clé de l'index. Il peut être considéré comme un "Dictionnaire", où les données sont triées en fonction de l'alphabet.
Étant donné que l'index clusterisé trie les lignes à l'aide d'une clé d'index, il ne peut y avoir qu'un seul index clusterisé. De plus, il doit y avoir un index clusterisé car InnoDB l'utilise pour manipuler de manière optimale les données lors de diverses opérations de données.
Les index clusterisés sont créés automatiquement (dans le cadre de la création de la table) à l'aide de l'une des colonnes de la table selon la priorité ci-dessous :
- Utilisation de la clé primaire si la clé primaire est mentionnée dans le cadre de la création de la table.
- Choisit n'importe quelle colonne unique où toutes les colonnes clés ne sont PAS NULLES.
- Sinon, génère en interne un index clusterisé masqué sur une colonne système qui contient l'ID de ligne de chaque ligne.
Contrairement à l'index non clusterisé PostgreSQL, InnoDB accède plus rapidement à une ligne en utilisant l'index clusterisé car la recherche d'index mène directement à la page avec toutes les données de la ligne et évite ainsi les E/S aléatoires.
De plus, obtenir les données de la table dans un ordre trié à l'aide de l'index clusterisé est très rapide car toutes les données sont déjà triées et des données entières sont également disponibles.
Index secondaire
L'index créé explicitement dans InnoDB est considéré comme un index secondaire, similaire à l'index non cluster PostgreSQL. Chaque enregistrement dans le stockage d'index secondaire contient une clé primaire des colonnes des lignes (qui ont été utilisées pour créer l'index clusterisé) ainsi que les colonnes spécifiées pour créer un index secondaire.
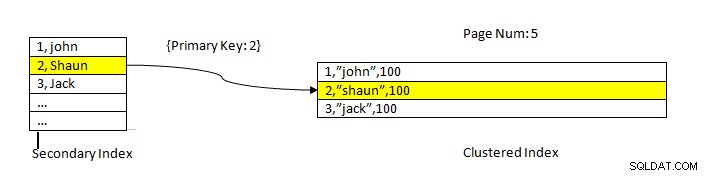 InnoDB :données lues à l'aide de l'index
InnoDB :données lues à l'aide de l'index L'extraction de données à l'aide d'un index secondaire est similaire à celle de PostgreSQL, sauf que la recherche d'index secondaire InnoDB donne une clé primaire comme pointeur pour extraire les données restantes de l'index clusterisé.
Par exemple, comme le montre l'image ci-dessus, l'index clusterisé est sur la colonne ID, les données de la table sont donc triées de la même manière. L'Index secondaire est sur la colonne "nom ”, de sorte que nous pouvons voir que l'index secondaire a à la fois une valeur d'ID et de nom. Une fois que nous avons recherché à l'aide de l'index secondaire, il trouve l'emplacement approprié avec la valeur de clé correspondante. Ensuite, la clé primaire correspondante est utilisée pour faire référence à la partie restante des données de l'index clusterisé.
MVCC pour l'index
L'index clusterisé MVCC utilise le modèle d'annulation InnoDB traditionnel (en fait le même que le MVCC de données entières, car l'index clusterisé n'est rien d'autre que des données entières).
Mais l'index secondaire MVCC utilise une approche un peu différente pour maintenir MVCC. Lors de la mise à jour de l'index secondaire, l'ancienne entrée d'index est marquée de suppression et de nouveaux enregistrements sont insérés dans le même stockage, c'est-à-dire que UPDATE n'est pas en place. Enfin, les anciennes entrées d'index sont purgées. À présent, vous avez peut-être remarqué que l'index secondaire InnoDB MVCC est presque le même que celui du modèle PostgreSQL MVCC.
Type d'index
InnoDB ne prend en charge que le type d'index B-Tree et n'a donc pas besoin d'être spécifié lors de la création de l'index.
Divers :index de hachage adaptatifs
Comme mentionné dans la section précédente, seul l'index de type B-Tree est pris en charge par InnoDB, mais il y a une torsion. InnoDB a la fonctionnalité de détecter automatiquement si la requête peut bénéficier de la construction d'un index de hachage et si des données entières de la table peuvent tenir en mémoire, alors il le fait automatiquement.
L'index de hachage est construit à l'aide de l'index B-Tree existant en fonction de la requête. S'il existe plusieurs index B-Tree secondaires, il choisira celui qui se qualifie selon la requête. L'index de hachage construit n'est pas complet, il construit simplement un index partiel selon le modèle d'utilisation des données.
C'est l'une des fonctionnalités les plus puissantes pour améliorer dynamiquement les performances des requêtes.
Conclusion
L'utilisation de n'importe quel index dans n'importe quelle base de données est vraiment utile pour améliorer les performances de READ mais en même temps, cela dégrade les performances d'INSERT/UPDATE car il doit écrire des données supplémentaires. L'index doit donc être choisi très judicieusement et ne doit être créé que si les clés d'index sont utilisées comme prédicat pour récupérer des données.
InnoDB fournit une très bonne fonctionnalité en termes d'index clusterisé, qui peut être très utile selon les cas d'utilisation. De plus, son indexation de hachage adaptative est très puissante.
Alors que PostgreSQL fournit différents types d'index, qui peuvent vraiment donner des options d'accès aux fonctionnalités et un ou tous peuvent être utilisés en fonction du cas d'utilisation de l'entreprise. De plus, les index partiels et d'expression sont très utiles selon le cas d'utilisation.