Le 27 juin, le PASS Performance Virtual Chapter a tenu son Summer Performance Palooza 2013 - une sorte de 24 Hours of PASS à échelle réduite, mais axé uniquement sur des sujets liés à la performance. J'ai donné une session intitulée "10 mauvaises habitudes qui peuvent tuer la performance", traitant des 10 concepts suivants :
- SÉLECTIONNER *
- Index aveugles
- Aucun préfixe de schéma
- Options de curseur par défaut
- préfixe sp_
- Autoriser le gonflement du cache
- Types de données étendus
- Paramètres par défaut de SQL Server
- Utilisation excessive des fonctions
- "Fonctionne sur ma machine"
Vous vous souvenez peut-être de certains de ces sujets dans des présentations telles que ma conférence "Mauvaises habitudes et meilleures pratiques" ou nos webinaires hebdomadaires sur le réglage des requêtes que j'ai animés avec Kevin Kline de début juin à cette semaine. (Ces 6 vidéos, soit dit en passant, seront disponibles début août sur YouTube.)
Ma session a attiré 351 participants et j'ai reçu d'excellents commentaires. Je voulais aborder certaines de ces questions.
Tout d'abord, un problème de configuration :j'utilisais un tout nouveau microphone et je n'avais aucune idée que chaque frappe de touche sonnerait comme le tonnerre. J'ai résolu ce problème avec un meilleur placement de mes périphériques, mais je tiens à m'excuser auprès de toutes les personnes concernées.
Ensuite, les téléchargements ; le jeu et les échantillons sont affichés sur le site de l'événement. Ils se trouvent en bas de la page, mais vous pouvez également les télécharger ici.
Enfin, ce qui suit est une liste de questions qui ont été postées pendant la session, et je voulais m'assurer d'avoir répondu à toutes celles qui n'ont pas reçu de réponse pendant les questions et réponses en direct. Je m'excuse d'avoir inséré cela en un peu moins d'un mois. , mais il y avait beaucoup de questions, et je ne voulais pas les publier en plusieurs parties.
Q :Si vous avez un proc qui peut avoir des valeurs d'entrée extrêmement variables pour les paramètres donnés et que le résultat est que le plan mis en cache n'est pas optimal dans la plupart des cas, est-il préférable de créer le proc WITH RECOMPILE et de prendre le petit performances atteintes à chaque exécution ?
R : Vous devrez aborder cela au cas par cas, car cela dépendra vraiment d'une variété de facteurs (y compris la complexité du plan). Notez également que vous pouvez effectuer une recompilation au niveau de l'instruction de sorte que seules les instructions affectées doivent prendre le coup, par opposition au module entier. Paul White m'a rappelé que les gens "corrigent" souvent le reniflage des paramètres avec RECOMPILE , mais trop souvent cela signifie WITH RECOMPILE de style 2000 plutôt que le bien meilleur OPTION (RECOMPILE) , qui non seulement se limite à l'instruction, mais permet également l'incorporation de paramètres, ce qui WITH RECOMPILE ne fait pas. Donc, si vous allez utiliser RECOMPILE pour contrecarrer le reniflage de paramètre, ajoutez-le à l'instruction, pas au module.
R : Comme ci-dessus, cela dépendra du coût et de la complexité des plans et il n'y a aucun moyen de dire "Oui, il y aura toujours un gros coup de performance". Vous devez également être sûr de comparer cela à l'alternative.
Q :S'il y a un index clusterisé à la date d'insertion, plus tard lors de la récupération des données, nous utilisons la fonction de conversion, si vous utilisez la comparaison directe, la date de la requête n'est pas lisible, dans le monde réel, quel est le meilleur choixR : Je ne sais pas ce que signifie "lisible dans le monde réel". Si vous voulez dire que vous voulez la sortie dans un format spécifique, il est généralement préférable de convertir en chaîne côté client. C# et la plupart des autres langages que vous utilisez probablement au niveau de la présentation sont plus que capables de formater la sortie date/heure de la base de données dans le format régional de votre choix.
Q :Comment déterminer le nombre de fois qu'un plan mis en cache est utilisé ? Existe-t-il une colonne avec cette valeur ou des requêtes sur Internet qui donneront cette valeur ? Enfin, ces décomptes ne seraient-ils pertinents que depuis le dernier redémarrage ?R : La plupart des DMV ne sont valides que depuis le dernier démarrage du service, et même d'autres peuvent être vidés plus fréquemment (même à la demande - à la fois par inadvertance et exprès). Le cache du plan est, bien sûr, en constante évolution, et les plans AFAIK qui sortent du cache ne conservent pas leur nombre précédent s'ils réapparaissent. Ainsi, même lorsque vous voyez un plan dans le cache, je ne suis pas à 100 % confiant que vous pouvez croire le nombre d'utilisations que vous trouvez.
Cela dit, ce que vous recherchez probablement est sys.dm_exec_cached_plans.usecounts et vous pouvez également trouver sys.dm_exec_procedure_stats.execution_count pour aider à compléter les informations pour les procédures où les déclarations individuelles dans les procédures ne sont pas trouvées dans le cache.
R : Les principales préoccupations à ce sujet sont la possibilité d'utiliser certaines syntaxes, telles que OUTER APPLY ou des variables avec une fonction table. Je ne suis au courant d'aucun cas où l'utilisation d'une compatibilité inférieure a un impact direct sur les performances, mais il est généralement recommandé de reconstruire les index et de mettre à jour les statistiques (et de demander à votre fournisseur de prendre en charge le nouveau niveau de compatibilité dès que possible). Je l'ai vu résoudre une dégradation inattendue des performances dans un nombre important de cas, mais j'ai également entendu des avis selon lesquels cela n'est pas nécessaire et peut-être même imprudent.
R : Non, du moins en termes de performances, une exception où SELECT * n'a pas d'importance lorsqu'il est utilisé dans un EXISTS clause. Mais pourquoi utiliseriez-vous * ici? Je préfère utiliser EXISTS (SELECT 1 ... - l'optimiseur les traitera de la même manière, mais d'une certaine manière, il documente lui-même le code et s'assure que les lecteurs comprennent que la sous-requête ne renvoie aucune donnée (même s'ils manquent le gros EXISTS à l'extérieur). Certaines personnes utilisent NULL , et je ne sais pas pourquoi j'ai commencé à utiliser 1, mais je trouve NULL légèrement peu intuitif aussi.
*Note* vous devrez être prudent si vous essayez d'utiliser EXISTS (SELECT * à l'intérieur d'un module lié au schéma :
CREATE VIEW dbo.ThisWillNotWork
WITH SCHEMABINDING
AS
SELECT BusinessEntityID
FROM Person.Person AS p
WHERE EXISTS (SELECT * FROM Sales.SalesOrderHeader AS h
WHERE h.SalesPersonID = p.BusinessEntityID); Vous obtenez cette erreur :
Msg 1054, Niveau 15, État 6, Procédure ThisWillNotWork, Ligne 6La syntaxe '*' n'est pas autorisée dans les objets liés au schéma.
Cependant, le changer en SELECT 1 fonctionne très bien. Alors peut-être que c'est un autre argument pour éviter SELECT * même dans ce scénario.
R : Il y en a probablement des centaines dans une variété de langues. Comme les conventions de nommage, les normes de codage sont une chose très subjective. Peu importe la convention que vous décidez qui vous convient le mieux; si vous aimez tbl préfixes, devenez fou ! Préférez Pascal à bigEndian, lancez-vous. Vous souhaitez préfixer vos noms de colonne avec le type de données, comme intCustomerID , je ne vais pas t'arrêter. La chose la plus importante est que vous définissiez une convention et que vous l'utilisiez *de manière cohérente.*
Ceci dit, si vous voulez mon avis, je n'en manque pas.
Q :Est-ce que XACT_ABORT peut être utilisé dans SQL Server 2008 ?
R : Je n'ai connaissance d'aucun projet d'abandon de XACT_ABORT il devrait donc continuer à bien fonctionner. Franchement, je ne vois pas cela utilisé très souvent maintenant que nous avons TRY / CATCH (et THROW à partir de SQL Server 2012).
R : Je n'ai pas testé cela, mais dans de nombreux cas, le remplacement d'une fonction scalaire par une fonction table en ligne peut avoir un impact important sur les performances. Le problème que je trouve est que faire ce changement peut représenter une quantité importante de travail sur le système qui a été écrit avant APPLY existaient ou sont toujours gérés par des personnes qui n'ont pas adopté cette meilleure approche.
R : Deux choses viennent à l'esprit :(1) le délai est lié au temps de compilation ou (2) le délai est lié à la quantité de données chargées pour satisfaire la requête, et la première fois qu'elles doivent provenir du disque et non la mémoire. Pour (1), vous pouvez exécuter la requête dans SQL Sentry Plan Explorer et la barre d'état vous indiquera le temps de compilation pour la première invocation et les suivantes (bien qu'une minute semble plutôt excessive pour cela, et peu probable). Si vous ne trouvez aucune différence, cela peut simplement être dû à la nature du système :mémoire insuffisante pour prendre en charge la quantité de données que vous essayez de charger avec cette requête en combinaison avec d'autres données qui se trouvaient déjà dans le pool de mémoire tampon. Si vous ne pensez pas que l'un ou l'autre soit le problème, voyez si les deux exécutions différentes donnent réellement des plans différents - s'il y a des différences, publiez les plans sur answers.sqlperformance.com et nous serons heureux de jeter un coup d'œil . En fait, la capture de plans réels pour les deux exécutions à l'aide de Plan Explorer dans tous les cas peut également vous informer des différences d'E/S et peut conduire à ce que SQL Server passe son temps lors de la première exécution plus lente.
Q :J'obtiens un reniflage de paramètres à l'aide de sp_executesql. Optimiser pour les charges de travail ad hoc résoudrait-il ce problème, car seul le stub de plan est en cache ?
R : Non, je ne pense pas que le paramètre Optimiser pour les charges de travail ad hoc aidera ce scénario, car le reniflage des paramètres implique que les exécutions ultérieures du même plan sont utilisées pour différents paramètres et avec des comportements de performances très différents. L'optimisation pour les charges de travail ad hoc est utilisée pour minimiser l'impact drastique sur le cache du plan qui peut se produire lorsque vous avez un grand nombre d'instructions SQL différentes. Donc, à moins que vous ne parliez de l'impact sur le cache du plan de nombreuses instructions différentes que vous envoyez à sp_executesql - qui ne serait pas qualifié de reniflage de paramètres - je pense expérimenter avec OPTION (RECOMPILE) peut avoir un meilleur résultat ou, si vous connaissez les valeurs de paramètre qui * produisent * de bons résultats dans une variété de combinaisons de paramètres, utilisez OPTIMIZE FOR . Cette réponse de Paul White peut fournir un bien meilleur aperçu.
R : Bien sûr, incluez simplement OPTION (RECOMPILE) dans le texte SQL dynamique :
DBCC FREEPROCCACHE; USE AdventureWorks2012; GO SET NOCOUNT ON; GO EXEC sp_executesql N'SELECT TOP (1) * INTO #x FROM Sales.SalesOrderHeader;'; GO EXEC sp_executesql N'SELECT TOP (1) * INTO #x FROM Sales.SalesOrderDetail OPTION (RECOMPILE);' GO SELECT t.[text], p.usecounts FROM sys.dm_exec_cached_plans AS p CROSS APPLY sys.dm_exec_sql_text(p.[plan_handle]) AS t WHERE t.[text] LIKE N'%Sales.' + 'SalesOrder%';
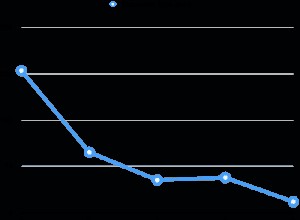
Résultats :1 ligne affichant le Sales.SalesOrderHeader requête.
Maintenant, si une instruction du lot n'inclut PAS OPTION (RECOMPILE) , le plan peut toujours être mis en cache, il ne peut tout simplement pas être réutilisé.
R : Eh bien, BETWEEN n'est pas sémantiquement équivalent à >= AND < , mais plutôt >= AND <= , et optimise et fonctionne exactement de la même manière. En tout cas, c'est à dessein que je n'utilise pas BETWEEN sur les requêtes de plage de dates - jamais - car il n'y a aucun moyen d'en faire une plage ouverte. Avec BETWEEN , les deux extrémités sont inclusives, et cela peut être très problématique selon le type de données sous-jacent (maintenant ou en raison d'un changement futur que vous ne connaissez peut-être pas). Le titre peut sembler un peu dur, mais j'entre dans les détails à ce sujet dans l'article de blog suivant :
Quel est le point commun entre BETWEEN et le diable ?
Q :Dans un curseur, que fait réellement "local fast_forward" ?
R : FAST_FORWARD est en fait la forme abrégée de READ_ONLY et FORWARD_ONLY . Voici ce qu'ils font :
LOCALfait en sorte que les portées extérieures (par défaut, un curseur estGLOBALsauf si vous avez modifié l'option au niveau de l'instance).READ_ONLYfait en sorte que vous ne puissiez pas mettre à jour le curseur directement, par ex. en utilisantWHERE CURRENT OF.FORWARD_ONLYempêche la possibilité de faire défiler, par ex. en utilisantFETCH PRIORouFETCH ABSOLUTEau lieu deFETCH NEXT.
La définition de ces options, comme je l'ai démontré (et dont j'ai parlé dans un blog), peut avoir un impact significatif sur les performances. Je vois très rarement des curseurs en production qui doivent réellement s'écarter de cet ensemble de fonctionnalités, mais ils sont généralement écrits pour accepter les valeurs par défaut beaucoup plus coûteuses de toute façon.
Q :qu'est-ce qui est le plus efficace, un curseur ou une boucle while ?
R : Un WHILE loop sera probablement plus efficace qu'un curseur équivalent avec les options par défaut, mais je suppose que vous trouverez peu ou pas de différence si vous utilisez LOCAL FAST_FORWARD . De manière générale, un WHILE loop *est* un curseur sans être appelé un curseur, et j'ai mis au défi des collègues très estimés de me prouver le contraire l'année dernière. Leur WHILE les boucles n'ont pas si bien fonctionné.
R : Un usp_ préfixe (ou tout préfixe autre que sp_ , ou pas de préfixe d'ailleurs) n'a *pas* le même impact que j'ai démontré. Je trouve cependant peu d'intérêt à utiliser un préfixe sur les procédures stockées car il y a très rarement un doute que lorsque je trouve du code qui dit EXEC something , que quelque chose est une procédure stockée - il y a donc peu de valeur (contrairement, par exemple, au préfixage des vues pour les distinguer des tables, car elles peuvent être utilisées de manière interchangeable). Donner à chaque procédure le même préfixe rend également beaucoup plus difficile la recherche de l'objet que vous recherchez dans, par exemple, l'Explorateur d'objets. Imaginez si chaque nom de famille dans l'annuaire téléphonique était précédé de LastName_ – en quoi cela vous aide-t-il ?
R : Oui! Eh bien, si vous êtes sur SQL Server 2008 ou supérieur. Une fois que vous avez identifié deux plans identiques, ils auront toujours un plan_handle distinct valeurs. Alors, identifiez celui que vous *ne voulez pas* garder, copiez son plan_handle , et placez-le dans ce DBCC commande :
DBCC FREEPROCCACHE(0x06.....);Q :L'utilisation de if else, etc. dans une procédure entraîne-t-elle de mauvais plans ? Est-elle optimisée pour la première exécution et optimisée uniquement pour ce chemin ? Les sections de code de chaque IF doivent-elles donc être transformées en procédures distinctes ?
R : Étant donné que SQL Server peut désormais effectuer une optimisation au niveau des instructions, cela a un effet moins drastique aujourd'hui que sur les anciennes versions, où la procédure entière devait être recompilée en une seule unité.
Q :J'ai parfois trouvé que l'écriture de sql dynamique peut être meilleure car elle élimine le problème de reniflage de paramètres pour sp. Est-ce vrai ? Y a-t-il des compromis ou d'autres considérations à faire concernant ce scénario ?R : Oui, SQL dynamique peut souvent contrecarrer le reniflage de paramètres, en particulier dans le cas où une requête massive "évier de cuisine" a beaucoup de paramètres facultatifs. J'ai traité d'autres considérations dans les questions ci-dessus.
Q :Si j'avais une colonne calculée sur ma table en tant que DATEPART(mycolumn, year) et dans l'index, est-ce que le serveur SQL l'utiliserait avec un SEEK ?R : Il devrait, mais bien sûr, cela dépend de la requête. L'index peut ne pas être adapté pour couvrir les colonnes de sortie ou satisfaire d'autres filtres et le paramètre que vous utilisez peut ne pas être suffisamment sélectif pour justifier une recherche.
Q :un plan est-il généré pour CHAQUE requête ? Un plan est-il généré même pour les plus triviaux ?R : Autant que je sache, un plan est généré pour chaque requête valide, même les plans triviaux, sauf si une erreur empêche la génération d'un plan (cela peut se produire dans plusieurs scénarios, tels que des indices non valides). Qu'ils soient mis en cache ou non (et combien de temps ils y restent) dépend de divers autres facteurs, dont certains dont j'ai parlé ci-dessus.
Q :Un appel à sp_executesql génère-t-il (et réutilise-t-il) le plan mis en cache ?
R : Oui, si vous envoyez exactement le même texte de requête, peu importe si vous l'émettez directement ou si vous l'envoyez via sp_executesql , SQL Server mettra en cache et réutilisera le plan.
R : Je ne vois pas pourquoi pas. La seule préoccupation que j'aurais est qu'avec l'initialisation instantanée des fichiers, les développeurs peuvent ne pas remarquer un grand nombre d'événements de croissance automatique, ce qui peut refléter de mauvais paramètres de croissance automatique qui peuvent avoir un impact très différent sur l'environnement de production (surtout si l'un de ces serveurs ne le fait pas * * avoir IFI activé).
Q :Avec la fonction dans la clause SELECT, serait-il correct de dire qu'il est préférable de dupliquer le code ?
R : Personnellement, je dirais oui. J'ai beaucoup amélioré les performances en remplaçant les fonctions scalaires dans le SELECT list avec un équivalent en ligne, même dans les cas où je dois répéter ce code. Comme mentionné ci-dessus, cependant, vous pouvez trouver dans certains cas que le remplacement de cela par une fonction table en ligne peut vous permettre de réutiliser le code sans pénaliser les performances.
R : L'asymétrie des données peut avoir un facteur, et je soupçonne que cela dépend du type de données que vous générez / simulez et de la distance à laquelle l'asymétrie peut être. Si vous avez, par exemple, une colonne varchar(100) qui, en production, contient généralement 90 caractères et que votre génération de données produit des données d'une moyenne de 50 (ce que SQL Server supposera), vous allez trouver un impact très différent sur le nombre de pages et d'optimisation, et des tests probablement peu réalistes.
Mais je vais être honnête :cette facette spécifique n'est pas quelque chose dans laquelle j'ai investi beaucoup de temps, car je peux généralement me forcer à obtenir de vraies données. :-)
Q :Toutes les fonctions sont-elles créées égales lors de l'examen des performances des requêtes ? Sinon, existe-t-il une liste de fonctions connues que vous devriez éviter dans la mesure du possible ?R : Non, toutes les fonctions ne sont pas égales en termes de performances. Il existe trois types de fonctions différents que nous pouvons créer (en ignorant les fonctions CLR pour le moment) :
- Fonctions scalaires multi-instructions
- Fonctions table multi-instructions
- Fonctions table en ligne
Les fonctions scalaires en ligne sont mentionnées dans la documentation, mais elles sont un mythe et, à partir de SQL Server 2014 au moins, peut aussi bien être mentionné aux côtés de Sasquatch et du monstre du Loch Ness.
En général, et je mettrais cela en police 80pt si je le pouvais, les fonctions table en ligne sont bonnes, et les autres doivent être évitées dans la mesure du possible, car elles sont beaucoup plus difficiles à optimiser.
Les fonctions peuvent également avoir différentes propriétés qui affectent leurs performances, par exemple si elles sont déterministes et si elles sont liées au schéma.
Pour de nombreux modèles de fonction, il y a certainement des considérations de performances que vous devez prendre en compte, et vous devez également être conscient de cet élément Connect qui vise à les résoudre.
Q :Pouvons-nous continuer à cumuler les totaux sans curseur ?R : Oui nous pouvons; il existe plusieurs méthodes autres qu'un curseur (comme détaillé dans mon article de blog, Meilleures approches pour les totaux cumulés - mis à jour pour SQL Server 2012):
- Sous-requête dans la liste SELECT
- CTE récursif
- Auto-adhésion
- "Mise à jour originale"
- SQL Server 2012+ uniquement :SUM() OVER() (en utilisant la valeur par défaut / RANGE)
- SQL Server 2012+ uniquement :SUM() OVER() (à l'aide de ROWS)
La dernière option est de loin la meilleure approche si vous êtes sur SQL Server 2012; sinon, il existe des restrictions sur les autres options non-curseur qui feront souvent d'un curseur le choix le plus attrayant. Par exemple, la méthode de mise à jour originale n'est pas documentée et n'est pas garantie de fonctionner dans l'ordre que vous attendez; le CTE récursif exige qu'il n'y ait aucune lacune dans le mécanisme séquentiel que vous utilisez; et les approches de sous-requête et d'auto-jointure ne sont tout simplement pas évolutives.