Dans mes articles précédents, j'ai expliqué comment créer et configurer la fonctionnalité FILESTREAM dans une instance de serveur SQL. De plus, j'ai montré comment créer une table qui a une colonne FILESTREAM et comment y insérer et supprimer les données.
Dans cet article, je vais vous expliquer comment sauvegarder et restaurer la base de données compatible FILESTREAM. De plus, je vais montrer comment restaurer le groupe de fichiers FILESTREAM sans mettre la base de données hors ligne.
Comme je l'ai expliqué dans mes articles précédents, lorsque nous activons FILESTREAM sur une instance SQL Server, nous devons créer un conteneur FILESTREAM contenant le groupe de fichiers FILESTREAM. Lorsque nous sauvegardons la base de données compatible FILESTREAM, la sauvegarde du groupe de fichiers FILESTREAM sera incluse dans le jeu de sauvegarde. Lorsque nous restaurons la base de données, SQL Server restaure la base de données ainsi que le conteneur FILESTREAM et les fichiers qu'il contient.
Lorsque nous sauvegardons une base de données compatible FILESTREAM, elle :
- Sauvegarder tous les fichiers de données disponibles de la base de données.
- Sauvegardez le groupe de fichiers FILESTREAM et les fichiers qu'il contient.
- Sauvegarder le T-Log.
SQL Server offre la possibilité de sauvegarder uniquement le conteneur FILESTREAM. Si les fichiers du conteneur FILESTREAM sont corrompus, nous n'avons pas besoin de récupérer l'intégralité de la base de données. Nous pouvons restaurer uniquement le groupe de fichiers FILESTREAM.
Dans cette démo, je vais :
- Expliquez comment effectuer une sauvegarde complète de la base de données FS et sauvegarder uniquement le conteneur FILESTREAM.
- Expliquez comment restaurer la base de données compatible FILESTREAM.
- Comment restaurer le conteneur FILESTREAM en ligne et hors ligne. Remarque :SQL Server Enterprise Edition et Developer Edition prennent en charge la restauration EN LIGNE.
Configuration de la démo :
Dans cette démo, je vais utiliser :
- Base de données :SQL Server 2017
- Logiciel :studio de gestion SQL Server.
Sauvegarde de la base de données compatible FILESTREAM
Pour illustrer le processus de sauvegarde, j'ai créé une base de données compatible FILESTREAM nommée FileStream_Demo . Il a une table FILESTREAM nommée Document_Content .
Sauvegarde complète de la base de données
La sauvegarde d'une base de données compatible FILESTREAM est un processus simple. Pour en générer une sauvegarde complète, exécutez le script T-SQL suivant.
BACKUP DATABASE [FileStream_Demo] TO DISK = N'E:\Backups\FileStream_Demo.bak' WITH NOFORMAT, NOINIT, NAME = N'FileStream_Demo-Full Database Backup', SKIP, NOREWIND, NOUNLOAD, STATS = 10 GO
Voici le journal de sauvegarde généré par l'exécution de la commande de sauvegarde ci-dessus :
/*Begin Backup DataFile*/ Processed 568 pages for database 'FileStream_Demo', file 'FileStream_Demo' on file 1. /*Begin backup of FILESTREAM container*/ 10 percent processed. 20 percent processed. 30 percent processed. 40 percent processed. 50 percent processed. 60 percent processed. 70 percent processed. 80 percent processed. 90 percent processed. Processed 111106 pages for database 'FileStream_Demo', file 'Dummy-Documents' on file 1. /*Begin backup of FILESTREAM container*/ Processed 4 pages for database 'FileStream_Demo', file 'FileStream_Demo_log' on file 1. 100 percent processed. BACKUP DATABASE successfully processed 111677 pages in 18.410 seconds (47.391 MB/sec).
Comme je l'ai mentionné au début de l'article, le serveur SQL effectue d'abord une sauvegarde du fichier de données principal, puis des fichiers de données secondaires et enfin des journaux de transactions. Comme vous pouvez le voir dans le journal de sauvegarde, tout d'abord, le fichier de données primaire de sauvegarde du serveur SQL, puis le groupe de fichiers FILESTREAM et les données qui lui sont associées et enfin les journaux de transactions.
Sauvegarde du conteneur FILESTREAM
Comme je l'ai mentionné au début de l'article, nous pouvons également générer une sauvegarde du conteneur FILESTREAM. Pour créer une sauvegarde du conteneur FILESTREAM, exécutez le script T-SQL suivant.
BACKUP DATABASE [FileStream_Demo] FILEGROUP = N'Dummy-Documents' TO DISK = N'E:\Backups\FS_Container.bak' WITH NOFORMAT, NOINIT, NAME = N'FileStream_Demo-Full Database Backup', SKIP, NOREWIND, NOUNLOAD, STATS = 10 GO
Restaurer la base de données compatible FILESTREAM
Lorsque nous restaurons la base de données FILESTREAM, SQL restaure le conteneur FileStream avec tous les fichiers du conteneur FILESTREAM.
Pour restaurer la base de données, effectuez les tâches suivantes :
- Dans SSMS, cliquez avec le bouton droit sur la base de données et sélectionnez Restaurer la base de données .
- Dans la boîte de dialogue Restaurer, sélectionnez Appareil et cliquez sur Parcourir . Une autre boîte de dialogue s'ouvrira. Dans la boîte de dialogue, cliquez sur Ajouter .
- Dans Rechercher le fichier de sauvegarde boîte de dialogue, naviguez dans la structure du répertoire, cliquez sur une sauvegarde appropriée et cliquez sur OK .
- Une fois les informations de sauvegarde chargées dans les Ensembles de sauvegarde à restaurer vue grille, cliquez sur OK pour commencer à restaurer le processus.
Vous pouvez également restaurer une base de données en exécutant la commande suivante :
USE [master] RESTORE DATABASE [FileStream_Demo] FROM DISK = N'E:\Backups\FileStream_Demo.bak' WITH FILE = 1, NOUNLOAD, STATS = 5 GO
Scénario de récupération de base de données compatible FILESTREAM
Le groupe de fichiers FILESTREAM restaure le processus comme le processus de restauration des groupes de fichiers.
Pour générer le scénario de restauration, créez une base de données compatible FILESTREAM nommée FileStream-Demo . La base de données a une table FILESTREAM nommée Document_Content . Insérez des données et des fichiers aléatoires dans le Document_Content tableau.
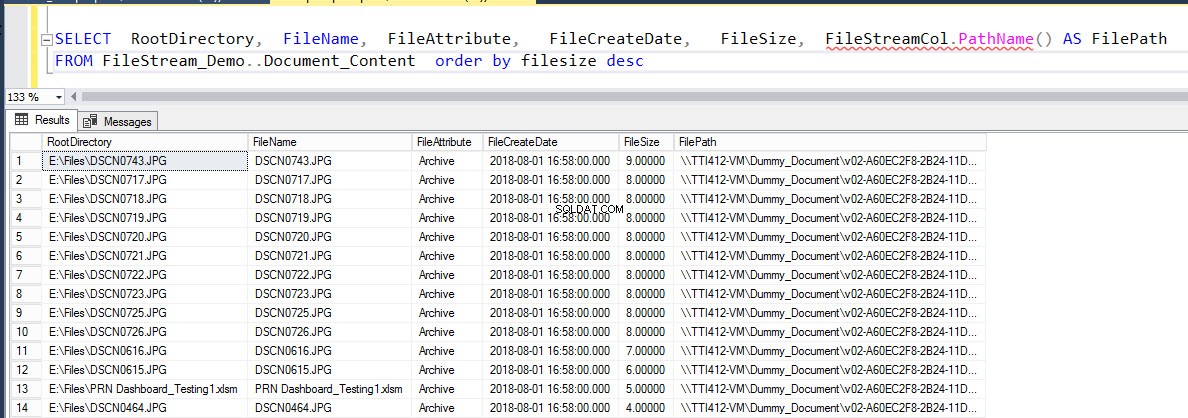
Exécutez la requête suivante pour remplir les détails des fichiers insérés dans la table.
SELECT RootDirectory, FileName, FileAttribute, FileCreateDate, FileSize, FileStreamCol.PathName() AS FilePath FROM Document_Content order by filesize desc
Le résultat est le suivant :
Voici une capture d'écran du conteneur FILESTREAM :
Tout d'abord, générez une sauvegarde complète de la base de données. Pour cela, exécutez la commande suivante.
BACKUP DATABASE [FileStream_Demo] TO DISK = N'E:\Backups\Full_FileStream_Demo_20180810.bak' WITH NOFORMAT, NOINIT,NAME = N'FileStream_Demo-Full Database Backup'
Deuxièmement, générez une sauvegarde FILEGROUP du groupe de fichiers FILESTREAM nommé Dummy-Document en exécutant la commande suivante :
BACKUP DATABASE [FileStream_Demo] FILEGROUP = N'Dummy-Documents' TO DISK = N'E:\Backups\FileStream_Filegroup_Demo.bak' WITH NOFORMAT, NOINIT, NAME = N'FileStream_Demo-Full FILEGROUP Backup'
Pour générer la corruption FILESTREAM, supprimez certains fichiers du conteneur FILESTREAM. Une fois ces fichiers supprimés, essayez de récupérer les données de "Document_Content" en exécutant la commande suivante :
Use FileStream_Demo Go select * from Document_Content
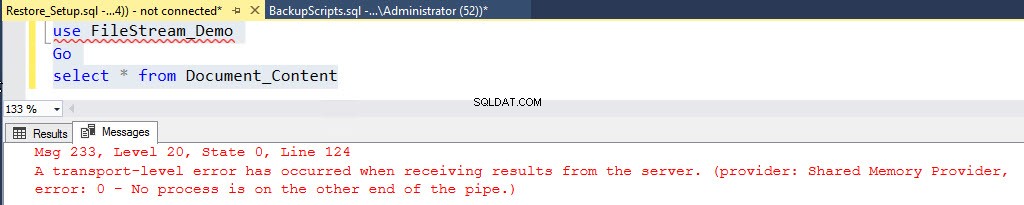
Vous obtiendrez l'erreur suivante :
Msg 233, Level 20, State 0, Line 122 A transport-level error has occurred when receiving results from the server. (provider: Shared Memory Provider, error: 0 - No process is on the other end of the pipe.)
Voir la capture d'écran suivante :
Maintenant, nous devons restaurer le conteneur FILESTREAM pour corriger cette erreur. Nous avons généré une sauvegarde complète et une sauvegarde du document factice groupe de fichiers.
Nous pouvons restaurer l'intégralité du conteneur FILESTREAM en restaurant le groupe de fichiers FILESTREAM. Je vais montrer :
- Restauration hors ligne du groupe de fichiers FILESTREAM.
- Restauration en ligne du groupe de fichiers FILESTREAM.
Restauration hors ligne du groupe de fichiers du conteneur FILESTREAM
Comme j'avais supprimé des fichiers du conteneur FILESTREAM, nous n'avons pas besoin de restaurer l'intégralité de la base de données. Ainsi, au lieu de restaurer l'intégralité de la base de données, nous restaurerons le seul groupe de fichiers. Pour ce faire, commencez par générer une sauvegarde Tail-Log pour capturer les modifications de données qui n'ont pas été sauvegardées. La sauvegarde du journal de fin doit être effectuée à l'aide de l'option NORECOVERY pour mettre la base de données en état de restauration, ce qui permet d'appliquer des sauvegardes sur la base de données. Pour cela, exécutez la requête suivante :
backup log [FileStream_Demo] to disk ='E:\Backups\FileStream_Filegroup_Demo_Log_1.trn' With NORECOVERY
Une fois la sauvegarde Tail-log générée, la base de données sera en mode de restauration. Maintenant, nous pouvons appliquer la sauvegarde FILEGROUP sur une base de données avec l'option NORECOVERY. Pour cela, exécutez la commande suivante :
use master go RESTORE DATABASE [FileStream_Demo] FILE='Dummy-Documents' FROM DISK = N'E:\Backups\FileStream_Filegroup_Demo.bak' WITH NORECOVERY,REPLACE;
Appliquez maintenant la sauvegarde Tail-log avec l'option RECOVERY. Pour cela, exécutez la commande suivante :
RESTORE LOG [FileStream_Demo] FROM DISK = N'E:\Backups\FileStream_Filegroup_Demo_Log_1.trn'
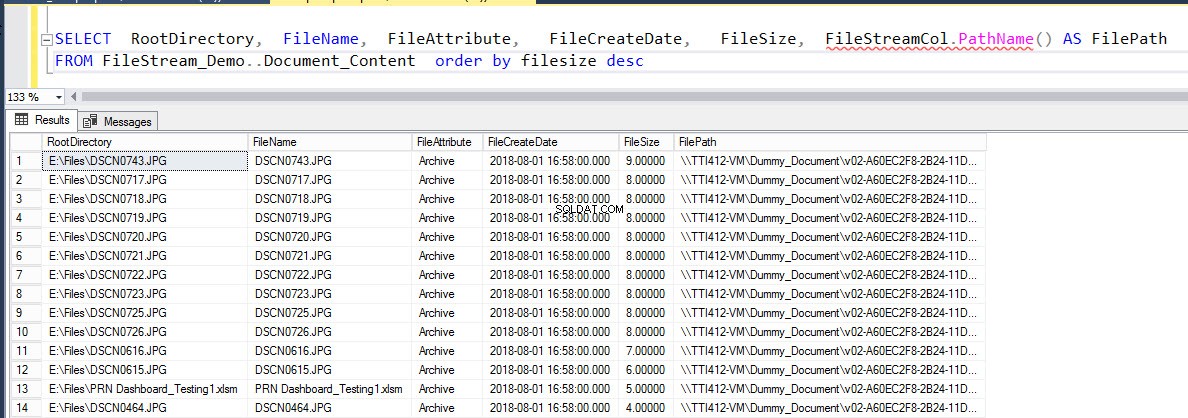
Une fois la sauvegarde restaurée, la base de données sera en ligne et tous les fichiers seront restaurés dans le conteneur FILESTREAM. Pour le vérifier, exécutez la commande suivante :
SELECT RootDirectory, FileName, FileAttribute, FileCreateDate, FileSize, FileStreamCol.PathName() AS FilePath FROM Document_Content order by filesize desc
Le résultat de la requête ci-dessus est le suivant :
Restauration en ligne du groupe de fichiers FILESTREAM
En utilisant SQL Server Enterprise Edition, nous pouvons restaurer la sauvegarde lorsque la base de données est en ligne. Par exemple, si un fichier F1 du groupe de fichiers secondaire FG-1 est corrompu, nous pouvons restaurer le fichier F1 pendant que la base de données reste en ligne. La séquence de restauration de la restauration hors ligne et de la restauration en ligne est la même.
Comme mentionné ci-dessus, pour effectuer une restauration en ligne du groupe de fichiers FILESTREAM, créez le Dummy-Document fichier de données hors ligne. Pour cela, exécutez la commande suivante.
use master go Alter database [FileStream_Demo] MODIFY FILE (NAME='Dummy-Documents',OFFLINE)
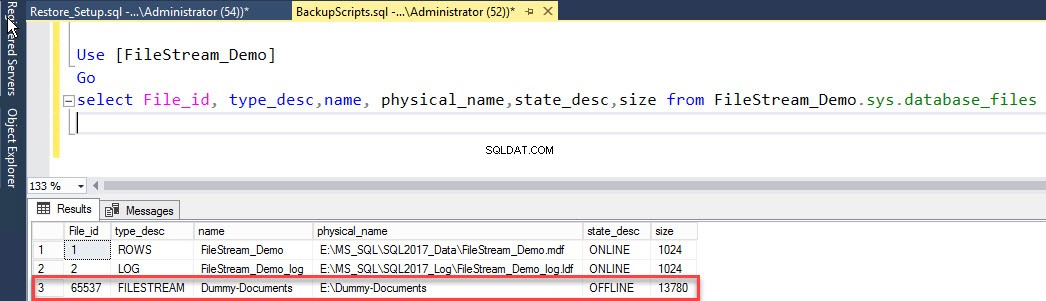
Pour vérifier l'état du fichier, exécutez la requête suivante :
Use [FileStream_Demo] Go select File_id, type_desc,name, physical_name,state_desc,size from FileStream_Demo.sys.database_files
Le résultat est le suivant :
Nous avons déjà sauvegardé le document factice groupe de fichiers. Ainsi, une fois le fichier de données hors ligne, restaurez la sauvegarde FILEGROUP sur une base de données avec l'option NORECOVERY. Pour cela, exécutez la commande suivante :
use master go RESTORE DATABASE [FileStream_Demo] FILE='Dummy-Documents' FROM DISK = N'E:\Backups\FileStream_Filegroup_Demo.bak' WITH NORECOVERY, REPLACE;
Maintenant, effectuez une sauvegarde du journal de la base de données pour vous assurer que le point auquel le fichier de données s'est déconnecté est capturé. Pour cela, exécutez la commande suivante :
backup log [FileStream_Demo] to disk ='E:\Backups\FileStream_Filegroup_Demo_Log1.trn'
Exécutez la commande suivante pour restaurer la dernière sauvegarde T-Log.
use master go RESTORE LOG [FileStream_Demo] FROM DISK = N'E:\Backups\FileStream_Filegroup_Demo_Log1.trn'
Une fois la sauvegarde du journal restaurée, tous les fichiers du conteneur FILESTREAM seront restaurés et le groupe de fichiers sera en ligne. Pour vérifier cela, exécutez la requête suivante :
Use [FileStream_Demo] Go select File_id, type_desc,name, physical_name,state_desc,size from FileStream_Demo.sys.database_files
Le résultat est le suivant :
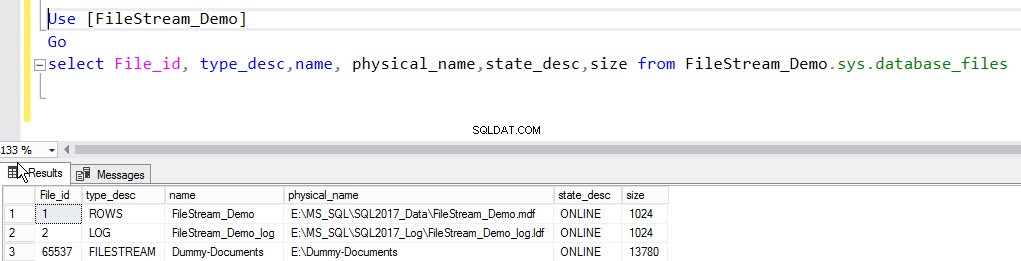
Une fois la sauvegarde restaurée, la base de données sera en ligne et tous les fichiers seront restaurés dans le conteneur FILESTREAM. Pour le vérifier, exécutez la commande suivante :
SELECT RootDirectory, FileName, FileAttribute, FileCreateDate, FileSize, FileStreamCol.PathName() AS FilePath FROM Document_Content order by filesize desc
Le résultat est le suivant :
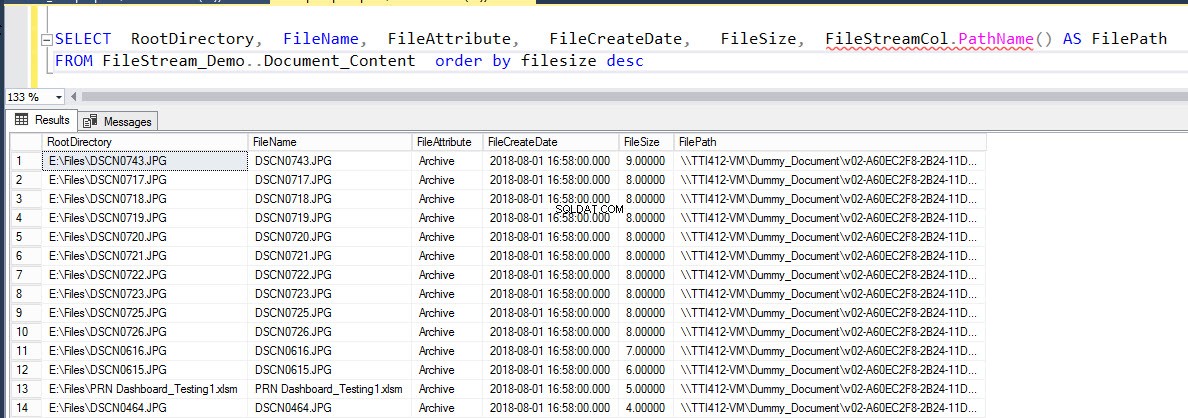
Résumé
Dans cet article, j'ai expliqué :
- Comment effectuer une sauvegarde et restaurer la base de données FILESTREAM et le groupe de fichiers FILESTREAM.
- Comment restaurer le groupe de fichiers FILESTREAM en ligne et hors ligne.