Dans mon article précédent sur les statistiques incrémentielles, une nouvelle fonctionnalité de SQL Server 2014, j'ai démontré comment elles peuvent aider à réduire la durée des tâches de maintenance. En effet, les statistiques peuvent être mises à jour au niveau de la partition et les modifications fusionnées dans l'histogramme principal de la table. J'ai également noté que l'optimiseur de requête n'utilise pas ces statistiques au niveau de la partition lors de la génération de plans de requête, ce que les gens attendaient peut-être. Aucune documentation n'existe pour indiquer que les statistiques incrémentielles seront ou ne seront pas utilisées par l'optimiseur de requête. Alors, comment savez-vous? Vous devez le tester. :-)
La configuration
La configuration de ce test sera similaire à celle du dernier message, mais avec moins de données. Notez que les tailles par défaut sont plus petites pour les fichiers de données et que le script ne charge que quelques millions de lignes de données :
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', --everything in 2011 '20120101', --everything in 2012 '20130101', --everything in 2013 '20140101', --everything in 2014 '20150101' --everything in 2015 ); GO CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Lorsque nous créons l'index clusterisé pour dbo.Orders, nous le créerons sans le STATISTICS_INCREMENTAL activée, nous allons donc commencer avec une table partitionnée traditionnelle sans statistiques incrémentielles :
ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ([OrderDate], [PurchaseOrderID]) ON [OrderDateRangePScheme] ([OrderDate]);
Ensuite, nous allons charger environ 4 millions de lignes, ce qui prend un peu moins d'une minute sur ma machine :
SET NOCOUNT ON; DECLARE @Loops SMALLINT = 0; DECLARE @Increment INT = 3000; WHILE @Loops < 1000 BEGIN INSERT [dbo].[Orders] ([PurchaseOrderID] ,[EmployeeID] ,[VendorID] ,[TaxAmt] ,[Freight] ,[SubTotal] ,[Status] ,[RevisionNumber] ,[ModifiedDate] ,[ShipMethodID] ,[ShipDate] ,[OrderDate] ,[TotalDue] ) SELECT [PurchaseOrderID] + @Increment , [EmployeeID] , [VendorID] , [TaxAmt] , [Freight] , [SubTotal] , [Status] , [RevisionNumber] , [ModifiedDate] , [ShipMethodID] , DATEADD(DAY, 365, [ShipDate]) , DATEADD(DAY, 365, [OrderDate]) , [TotalDue] + 365 FROM [Purchasing].[PurchaseOrderHeader]; CHECKPOINT; SET @Loops = @Loops + 1; SET @Increment = @Increment + 5000; END
Après le chargement des données, nous mettrons à jour les statistiques avec un FULLSCAN (afin de pouvoir créer un histogramme aussi cohérent que possible pour les tests), puis nous vérifierons quelles données nous avons dans chaque partition :
UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN; SELECT $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number] , MIN([o].[OrderDate]) AS [Min_Order_Date] , MAX([o].[OrderDate]) AS [Max_Order_Date] , COUNT(*) AS [Rows_In_Partition] FROM [dbo].[Orders] AS [o] GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) ORDER BY [Partition Number];
 Données dans chaque partition après le chargement des données
Données dans chaque partition après le chargement des données
La plupart des données se trouvent dans la partition 2015, mais il y a aussi des données pour 2012, 2013 et 2014. Et si nous vérifions la sortie du DMV non documenté sys.dm_db_stats_properties_internal , nous pouvons voir qu'il n'existe aucune statistique au niveau de la partition :
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 sortie sys.dm_db_stats_properties_internal affichant une seule statistique pour dbo.Orders
sortie sys.dm_db_stats_properties_internal affichant une seule statistique pour dbo.Orders
L'épreuve
Le test nécessite une requête simple que nous pouvons utiliser pour vérifier que l'élimination de la partition se produit, et également vérifier les estimations basées sur les statistiques. La requête ne renvoie aucune donnée, mais cela n'a pas d'importance, nous sommes intéressés par ce que l'optimiseur pensait il renverrait, basé sur les statistiques :
SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
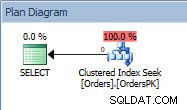 Plan de requête pour l'instruction SELECT
Plan de requête pour l'instruction SELECT
Le plan a un Clustered Index Seek, et si nous vérifions les propriétés, nous voyons qu'il a estimé 4000 lignes, et a accédé à la partition 5, qui contient les données de 2014.
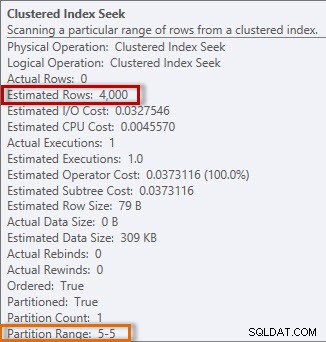 Informations estimées et réelles de Clustered Index Seek
Informations estimées et réelles de Clustered Index Seek
Si nous examinons l'histogramme de la table dbo.Orders, en particulier dans la zone des données d'avril 2014, nous constatons qu'il n'y a pas d'étape pour le 01/04/2014. L'optimiseur estime donc le nombre de lignes pour cette date à l'aide de l'étape pour le 24/04/2014, où AVG_RANGE_ROWS est de 4 000 (pour toute valeur comprise entre le 14/02/2014 et le 23/04/2014 inclus, l'optimiseur estimera que 4 000 lignes seront renvoyées).
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
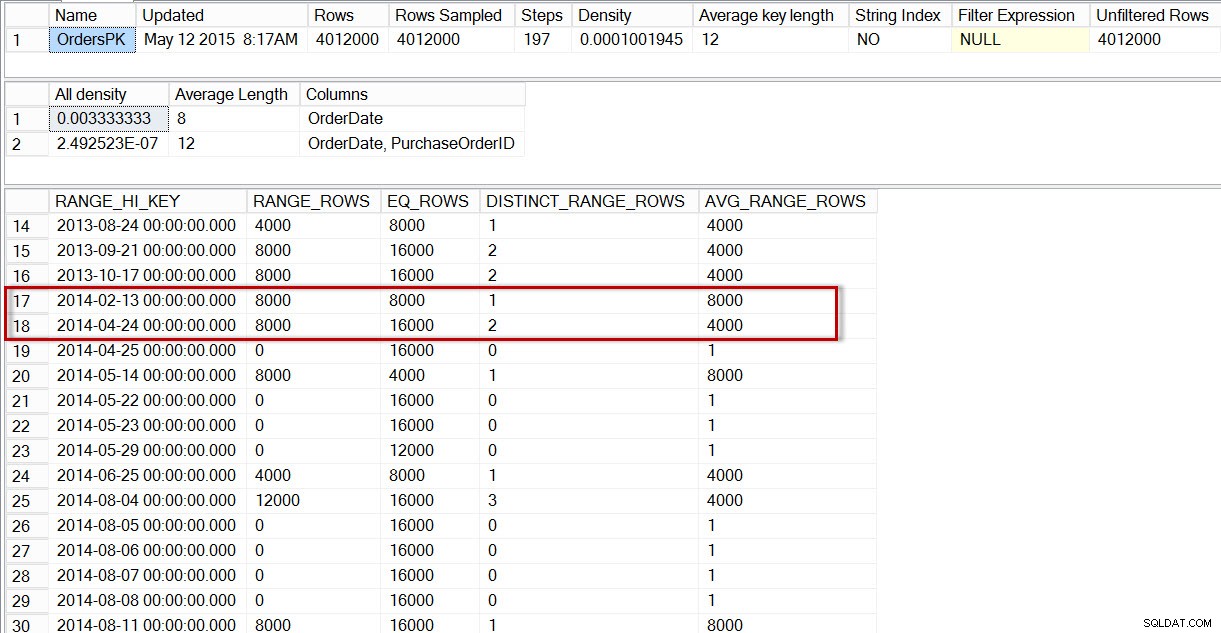 Distribution dans l'histogramme dbo.Orders
Distribution dans l'histogramme dbo.Orders
Le devis et le plan sont totalement à prévoir. Activons les statistiques incrémentielles et voyons ce que nous obtenons.
ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON); GO UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN;
Si nous réexécutons notre requête sur sys.dm_db_stats_properties_internal , nous pouvons voir les statistiques incrémentielles :
 sys.dm_db_stats_properties_internal affichant des informations statistiques incrémentielles
sys.dm_db_stats_properties_internal affichant des informations statistiques incrémentielles
Maintenant, réexécutons à nouveau notre requête dbo.Orders, et nous exécuterons DBCC FREEPROCCACHE d'abord pour s'assurer que le plan n'est pas réutilisé :
DBCC FREEPROCCACHE; GO SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
On obtient le même plan, et le même devis :
Plan de requête pour l'instruction SELECT
Informations estimées et réelles de Clustered Index Seek
Si nous vérifions l'histogramme principal pour dbo.Orders, nous voyons presque le même histogramme qu'avant :
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
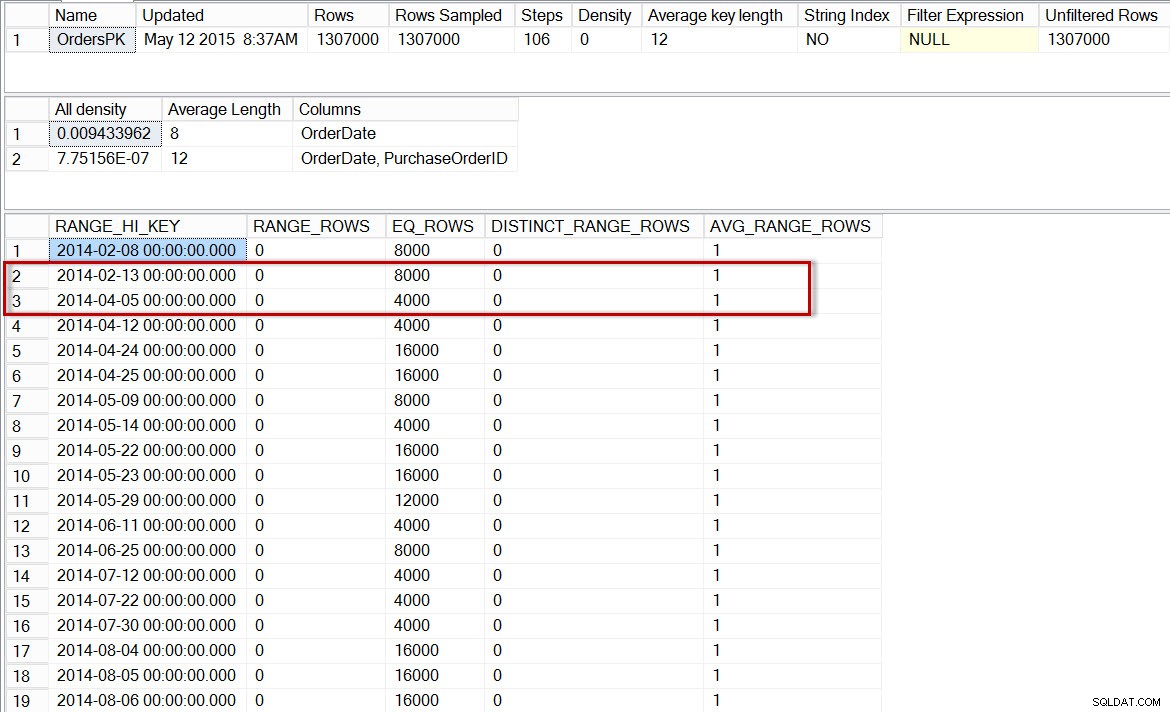 Histogramme pour dbo.Orders, après activation des statistiques incrémentielles
Histogramme pour dbo.Orders, après activation des statistiques incrémentielles
Maintenant, vérifions l'histogramme de la partition avec les données de 2014 (nous pouvons le faire en utilisant l'indicateur de trace non documenté 2309, qui permet de spécifier un numéro de partition comme argument supplémentaire pour DBCC SHOW_STATISTICS ):
DBCC TRACEON(2309);
GO
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK', 6);
Histogramme pour la partition 2014 de dbo.Orders, après activation des statistiques incrémentielles
Ici, nous voyons que, encore une fois, il n'y a pas d'étape pour 2014-04-01, mais il y a 0 RANGE_ROWS entre le 13/02/2014 et le 05/04/2014, avec un AVG_RANGE_ROWS de 1. Si l'optimiseur utilisait l'histogramme pour les statistiques au niveau de la partition, l'estimation du nombre de lignes pour le 01/04/2014 serait de 1.
Remarque :La partition identifiée comme utilisée dans le plan de requête est 5, mais vous remarquerez que le DBCC SHOW_STATISTICS L'instruction fait référence à la partition 6. L'hypothèse est une incohérence dans les métadonnées des statistiques (une erreur courante de un par un, probablement due à un comptage basé sur 0 par rapport à un comptage basé sur 1), qui peut ou non être corrigée à l'avenir. Comprenez que l'indicateur de trace n'est pas documenté pour le moment et qu'il n'est pas recommandé de l'utiliser dans un environnement de production.
Résumé
L'ajout de statistiques incrémentielles dans la version SQL Server 2014 est un pas dans la bonne direction pour améliorer les estimations de cardinalité pour les tables partitionnées. Cependant, comme nous l'avons démontré, la valeur actuelle des statistiques incrémentielles est limitée à des durées de maintenance réduites, car ces statistiques incrémentielles ne sont pas encore utilisées par l'optimiseur de requête.