Dans les blogs précédents, mes collègues et moi vous avons montré comment surveiller les performances, gérer et déployer des clusters, exécuter des sauvegardes et même activer le basculement automatique pour TimescaleDB.
Dans ce blog, nous vous montrerons comment faire évoluer votre instance TimescaleDB unique vers un cluster multi-nœuds en quelques étapes simples.
Nous allons commencer par une configuration commune, une instance de nœud unique exécutée sur CentosOS. Le nœud est opérationnel et il est déjà surveillé et géré par le ClusterControl.
Si vous souhaitez savoir comment déployer ou importer votre instance TimescaleDB, consultez le blog écrit par mon collègue Sebastian Insausti, "Comment déployer facilement TimescaleDB."
La configuration ressemble à ceci...
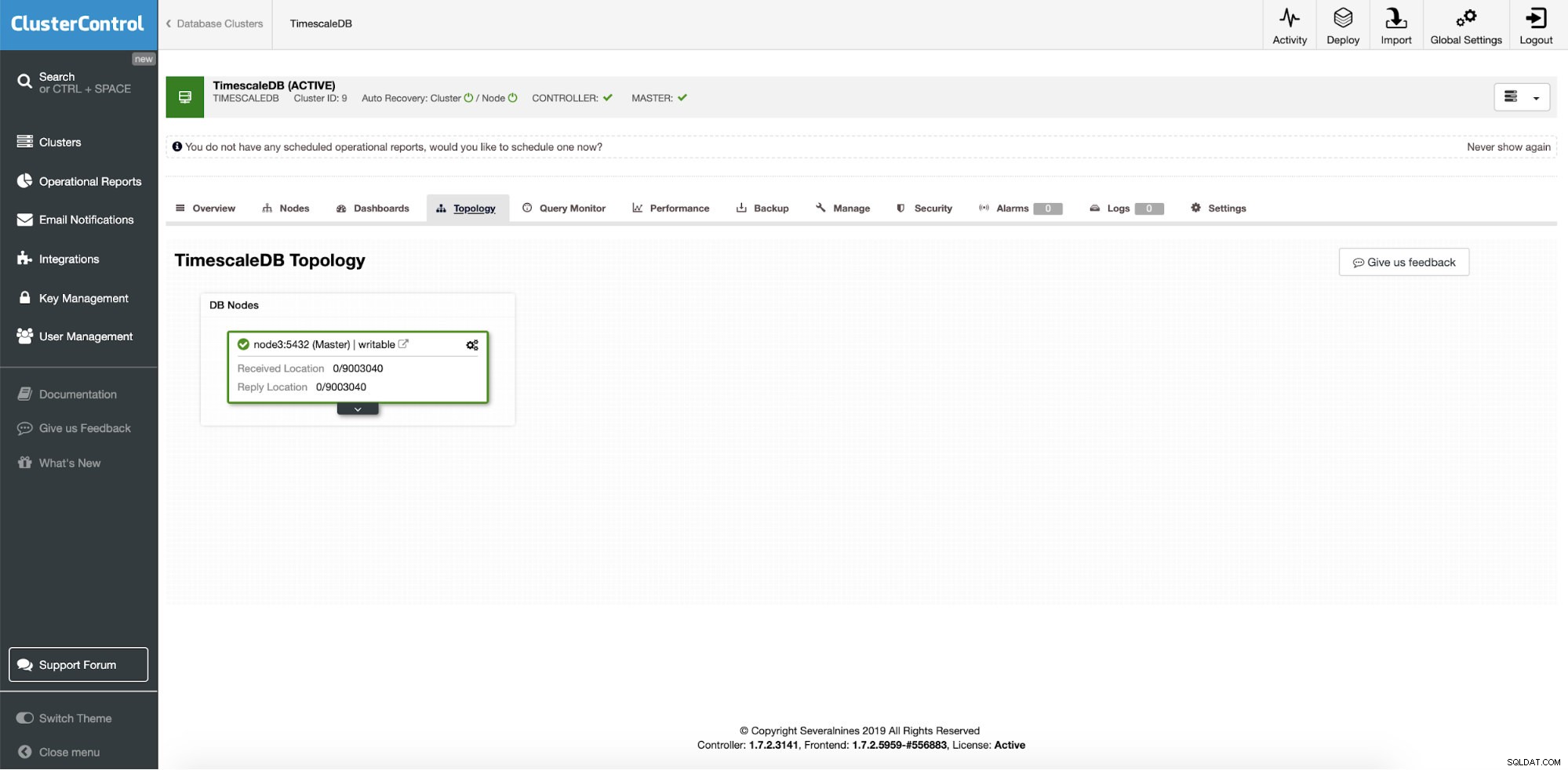 ClusterControl :instance unique TimescaleDB
ClusterControl :instance unique TimescaleDB Il s'agit donc d'une instance de production unique et nous souhaitons la convertir en cluster sans temps d'arrêt. Notre objectif principal est d'étendre les opérations de lecture d'application à d'autres machines avec une option pour les utiliser comme serveurs HA intermédiaires lors de l'écriture d'un plantage de serveur.
Plus de nœuds devraient également réduire les temps d'arrêt de maintenance des applications. Comme les correctifs appliqués en mode de redémarrage progressif - un nœud corrigé à la fois tandis que les autres nœuds desservent les connexions à la base de données.
La dernière exigence est de créer une adresse unique pour notre nouveau cluster afin que nos nouveaux nœuds soient visibles pour l'application à partir d'un seul endroit.

Nous pouvons résumer notre plan d'action en deux grandes étapes :
- Ajout d'une réplique lit
- Installer et configurer Haproxy
Ajout d'une réplique en lecture
Si nous allons dans les actions de cluster et sélectionnons "Ajouter un esclave de réplication", nous pouvons soit créer un nouveau réplica à partir de zéro, soit ajouter une base de données TimescaleDB existante en tant que réplica.
 ClusterControl :ajouter un esclave de réplication
ClusterControl :ajouter un esclave de réplication 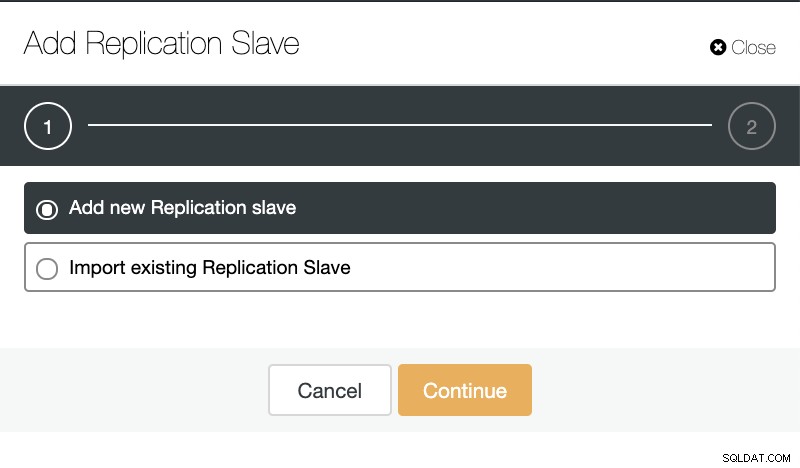 ClusterControl :ajouter un nouvel esclave de réplication, importer un esclave de réplication existant
ClusterControl :ajouter un nouvel esclave de réplication, importer un esclave de réplication existant Comme vous pouvez le voir dans l'image ci-dessous, nous n'avons qu'à choisir notre serveur maître, entrer l'adresse IP de notre nouveau serveur esclave et le port de la base de données.
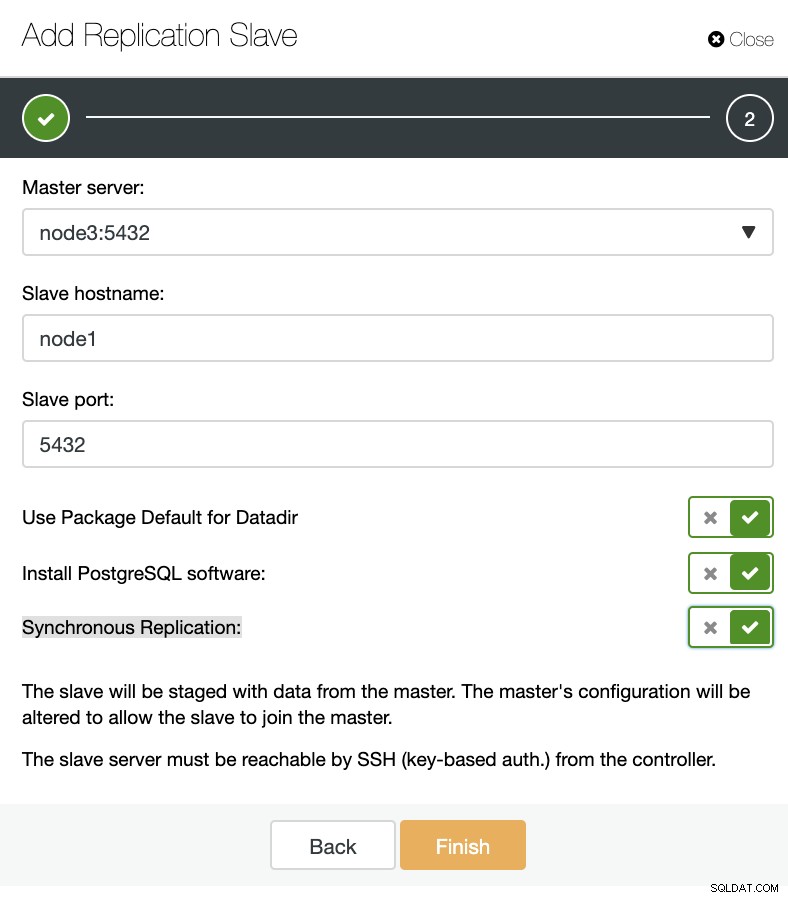 ClusterControl :Ajouter un esclave de réplication
ClusterControl :Ajouter un esclave de réplication Ensuite, nous pouvons choisir si nous voulons que ClusterControl installe le logiciel pour nous et si l'esclave de réplication doit être synchrone ou asynchrone. Lorsque vous importez un serveur esclave existant, vous pouvez utiliser l'option d'importation comme suit :
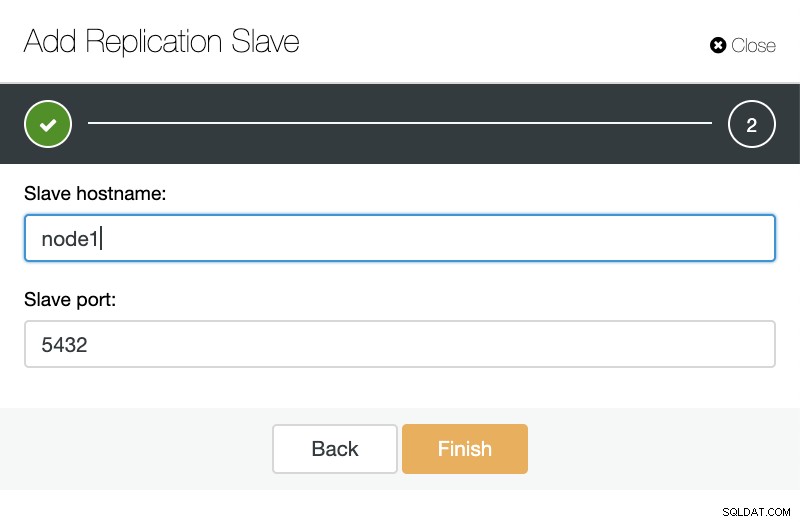 ClusterControl :Importer l'esclave de réplication pour TimescaleDB
ClusterControl :Importer l'esclave de réplication pour TimescaleDB Dans les deux cas, nous pouvons ajouter autant de répliques que nous le souhaitons. Dans notre cas d'exemple, nous ajouterons deux nœuds. CusterControl créera une tâche interne et s'occupera de toutes les étapes nécessaires sans aucune à la fois.
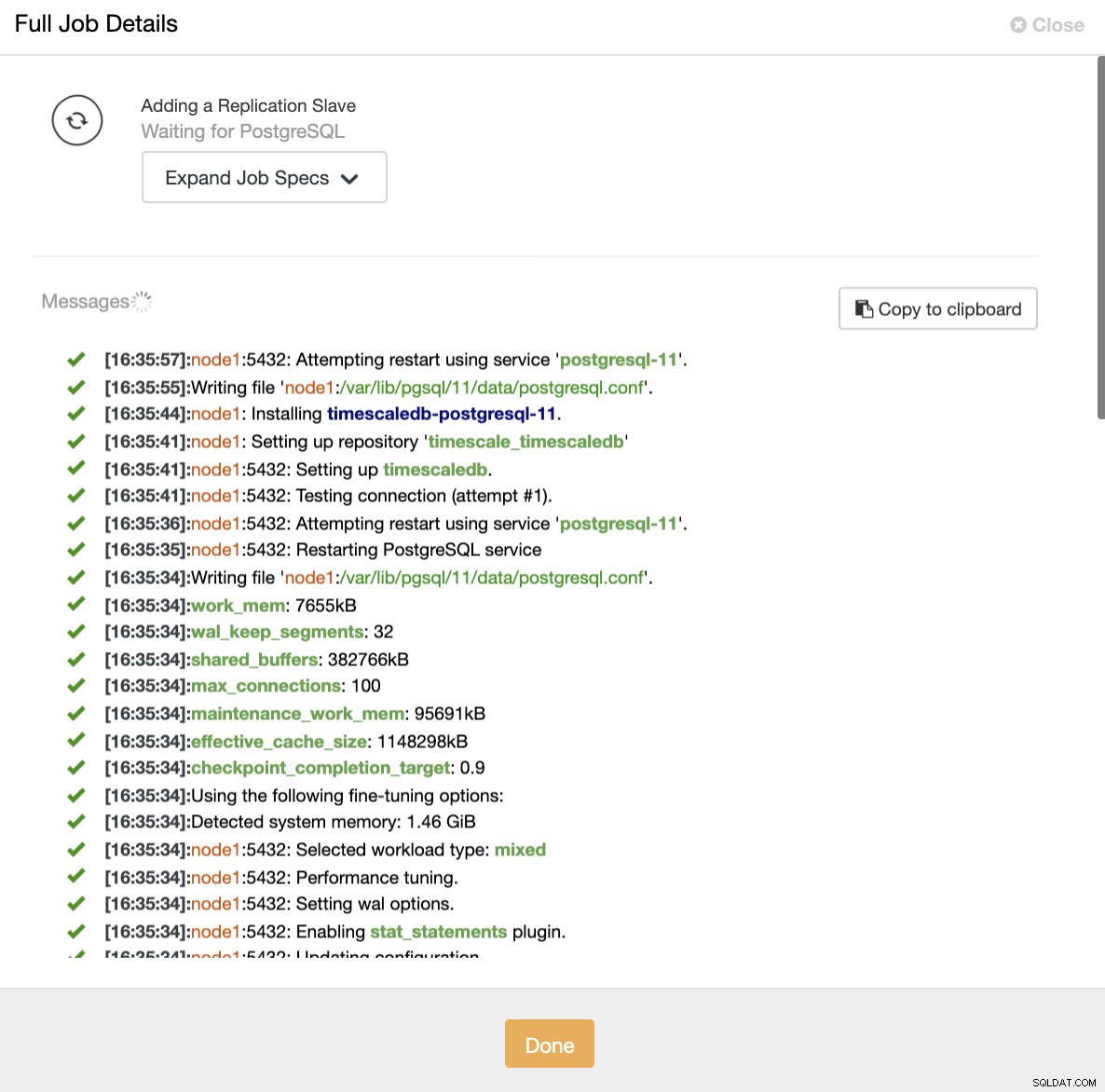 ClusterControl :ajouter un réplica en lecture
ClusterControl :ajouter un réplica en lecture Ajout d'un équilibreur de charge à TimescaleDB
À ce stade, nos données sont réparties sur plusieurs nœuds ou centres de données si vous avez choisi d'ajouter des nœuds esclaves de réplication à un emplacement différent. Le cluster est mis à l'échelle avec deux nœuds de réplica en lecture supplémentaires.
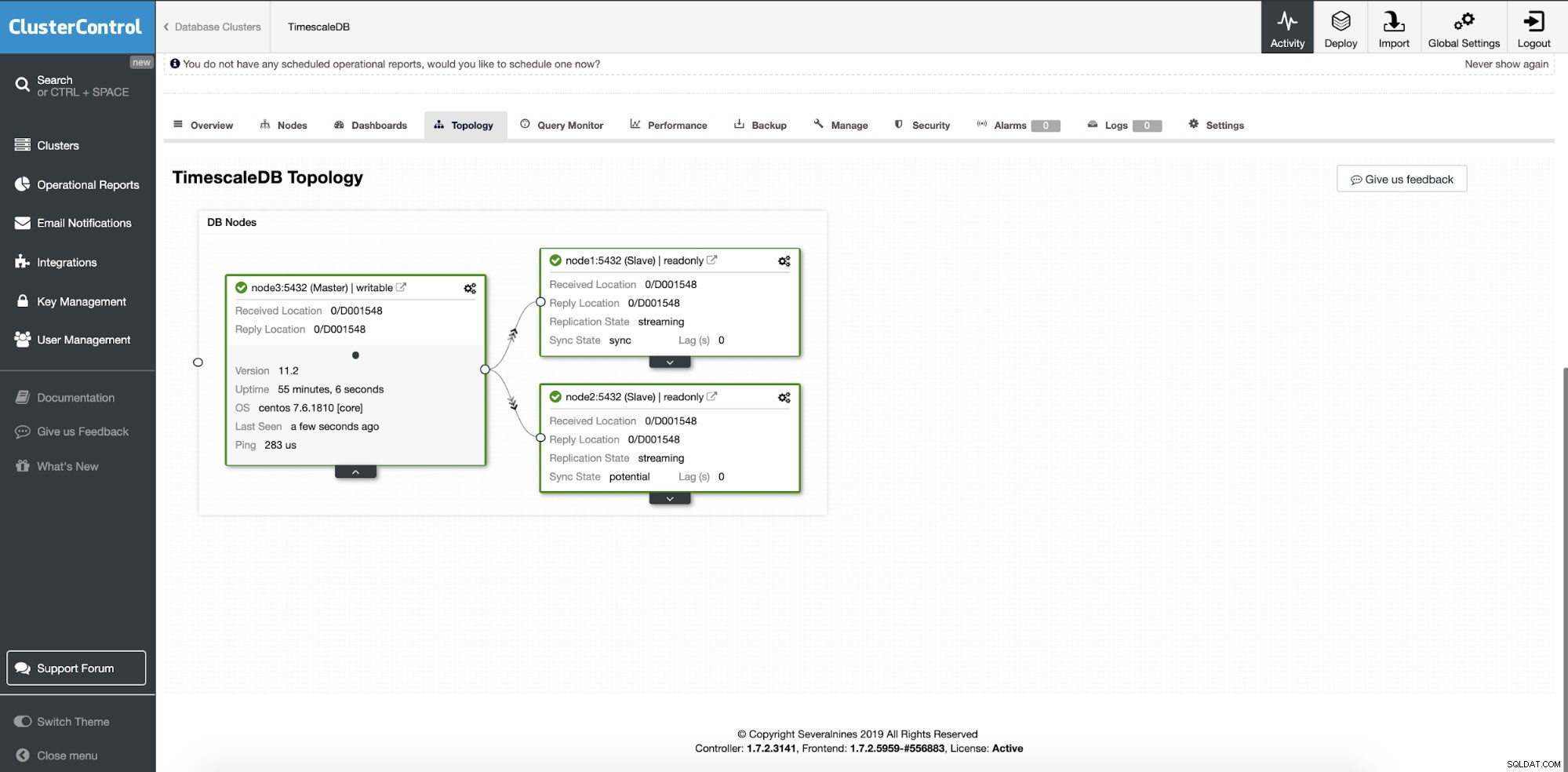 ClusterControl :deux nœuds ajoutés
ClusterControl :deux nœuds ajoutés La question est de savoir comment l'application sait-elle à quel nœud de base de données accéder ? Nous utiliserons HAProxy et différents ports pour les opérations d'écriture et de lecture.
Dans le cluster TimescaleDB, menu contextuel, choisissez d'ajouter un équilibreur de charge.

Nous devons maintenant fournir l'emplacement du serveur sur lequel Haproxy doit être installé, quelle politique nous voulons utiliser pour les connexions à la base de données et quels nœuds participent à la configuration de Haproxy.
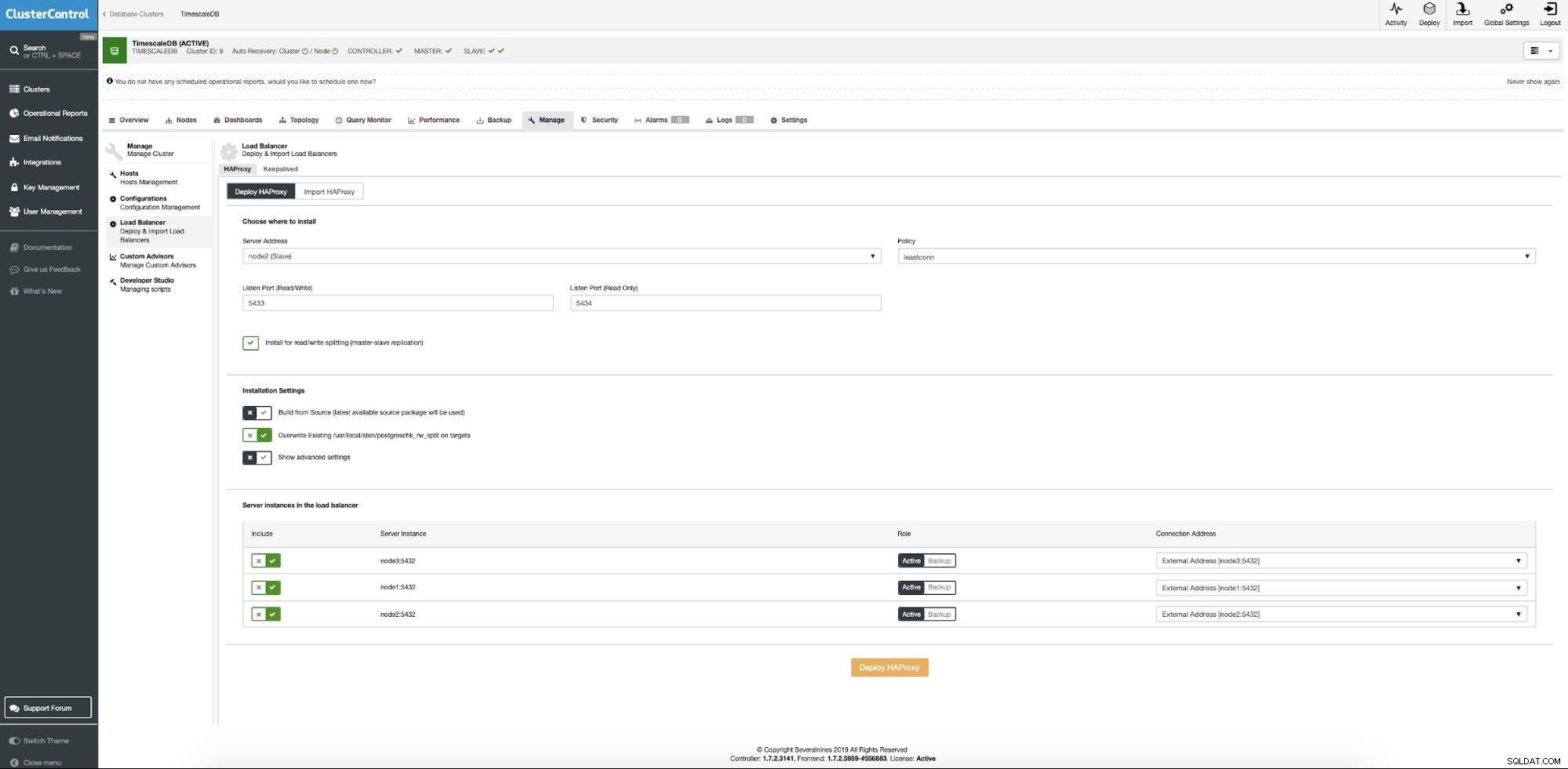
Lorsque tout est réglé, appuyez sur le bouton de déploiement. Après quelques minutes, nous devrions préparer notre configuration de cluster. ClusterControl s'occupera de tous les prérequis et configurations pour déployer l'équilibreur de charge.
Après un déploiement réussi, nous pouvons voir la topologie de notre nouveau cluster ; avec équilibrage de charge et nœuds de lecture supplémentaires. Avec plus de nœuds intégrés, ClusterControl active automatiquement la récupération automatique. Ainsi, lorsque le nœud maître tombe en panne, l'opération de basculement démarre d'elle-même.
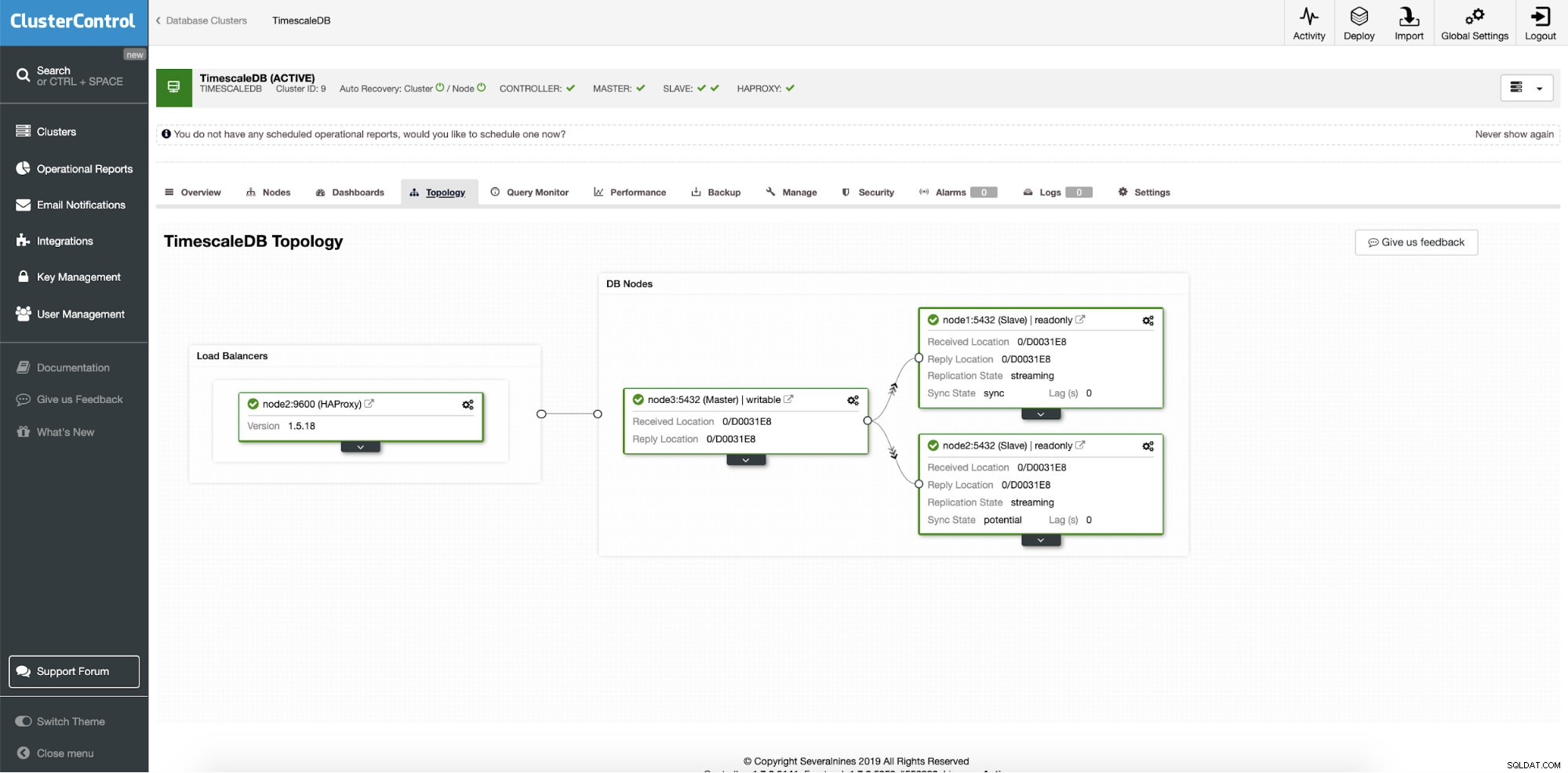 ClusterControl :topologie finale
ClusterControl :topologie finale Conclusion
TimescaleDB est une base de données open source inventée pour rendre SQL évolutif pour les données de séries chronologiques. Disposer d'un moyen automatisé d'étendre leur cluster est essentiel pour atteindre performances et efficacité. Comme nous l'avons vu ci-dessus, vous pouvez désormais faire évoluer TimescaleDB en utilisant facilement ClusterControl.