SQL Server 2014 a apporté de nombreuses nouvelles fonctionnalités que les administrateurs de base de données et les développeurs attendaient avec impatience de tester et d'utiliser dans leurs environnements, telles que l'index Columnstore en cluster pouvant être mis à jour, la durabilité différée et les extensions de pool de mémoire tampon. Les statistiques incrémentielles sont une fonctionnalité dont on ne parle pas souvent. À moins que vous n'utilisiez le partitionnement, ce n'est pas une fonctionnalité que vous pouvez implémenter. Mais si vous avez des tables partitionnées dans votre base de données, les statistiques incrémentielles étaient peut-être quelque chose que vous attendiez avec impatience.
Remarque :Benjamin Nevarez a couvert certaines notions de base liées aux statistiques incrémentielles dans son article de février 2014, SQL Server 2014 Incremental Statistics. Et même si peu de choses ont changé dans le fonctionnement de cette fonctionnalité depuis sa publication et la version d'avril 2014, le moment semblait venu de se pencher sur la façon dont l'activation des statistiques incrémentielles peut contribuer aux performances de maintenance.
Les statistiques incrémentielles sont parfois appelées statistiques au niveau de la partition, car pour la première fois, SQL Server peut créer automatiquement des statistiques spécifiques à une partition. L'un des défis précédents avec le partitionnement était que, même si vous pouviez avoir 1 à n partitions pour une table, il n'y avait qu'une (1) statistique qui représentait la distribution des données sur toutes ces partitions. Vous pouvez créer des statistiques filtrées pour la table partitionnée (une statistique pour chaque partition) afin de fournir à l'optimiseur de requête de meilleures informations sur la distribution des données. Mais il s'agissait d'un processus manuel et nécessitait un script pour les créer automatiquement pour chaque nouvelle partition.
Dans SQL Server 2014, vous utilisez le STATISTICS_INCREMENTAL option pour que SQL Server crée automatiquement ces statistiques au niveau de la partition. Cependant, ces statistiques ne sont pas utilisées comme vous pourriez le penser.
J'ai mentionné précédemment que, avant 2014, vous pouviez créer des statistiques filtrées pour donner à l'optimiseur de meilleures informations sur les partitions. Ces statistiques supplémentaires ? Ils ne sont actuellement pas utilisés par l'optimiseur. L'optimiseur de requête utilise toujours l'histogramme principal qui représente la table entière. (Post à venir qui le démontrera !)
Alors, à quoi servent les statistiques incrémentales ? Si vous partez du principe que seules les données de la partition la plus récente changent, dans l'idéal, vous ne mettez à jour que les statistiques de cette partition. Vous pouvez le faire maintenant avec des statistiques incrémentielles - et ce qui se passe, c'est que les informations sont ensuite fusionnées dans l'histogramme principal. L'histogramme de l'ensemble du tableau sera mis à jour sans avoir à lire l'intégralité du tableau pour mettre à jour les statistiques, ce qui peut vous aider à effectuer vos tâches de maintenance.
Configuration
Nous allons commencer par créer une fonction et un schéma de partition, puis une nouvelle table que nous allons partitionner. Notez que j'ai créé un groupe de fichiers pour chaque fonction de partition comme vous le feriez dans un environnement de production. Vous pouvez créer le schéma de partition sur le même groupe de fichiers (par exemple, PRIMARY ) si vous ne pouvez pas supprimer facilement votre base de données de test. Chaque groupe de fichiers a également une taille de quelques Go, car nous allons ajouter près de 400 millions de lignes.
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 1024MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; /* create partition function */ CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', -- everything in 2011 '20120101', -- everything in 2012 '20130101', -- everything in 2013 '20140101', -- everything in 2014 '20150101' -- everything in 2015 ); GO /* create partition scheme */ CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO /* create the table */ CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Avant d'ajouter les données, nous allons créer l'index clusterisé et noter que la syntaxe inclut le WITH (STATISTICS_INCREMENTAL = ON) choix :
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) WITH (STATISTICS_INCREMENTAL = ON) ON [OrderDateRangePScheme] ([OrderDate]);
Ce qui est intéressant à noter ici, c'est que si vous regardez le ALTER TABLE entrée dans MSDN, il n'inclut pas cette option. Vous ne le trouverez que dans ALTER INDEX entrée… mais cela fonctionne. Si vous voulez suivre la documentation à la lettre, vous exécuterez :
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) ON [OrderDateRangePScheme] ([OrderDate]); GO ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON);
Une fois l'index clusterisé créé pour le schéma de partition, nous allons charger nos données, puis vérifier le nombre de lignes existantes par partition (notez que cela prend plus de 7 minutes sur mon ordinateur portable, vous voudrez peut-être ajouter moins de lignes en fonction de la quantité de stockage (et du temps) dont vous disposez :
/* load some data */
SET NOCOUNT ON;
DECLARE @Loops SMALLINT = 0;
DECLARE @Increment INT = 5000;
WHILE @Loops < 10000 -- adjust this to increase or decrease the number
-- of rows in the table, 10000 = 40 millon rows
BEGIN
INSERT [dbo].[Orders]
( [PurchaseOrderID]
,[EmployeeID]
,[VendorID]
,[TaxAmt]
,[Freight]
,[SubTotal]
,[Status]
,[RevisionNumber]
,[ModifiedDate]
,[ShipMethodID]
,[ShipDate]
,[OrderDate]
,[TotalDue]
)
SELECT
[PurchaseOrderID] + @Increment
, [EmployeeID]
, [VendorID]
, [TaxAmt]
, [Freight]
, [SubTotal]
, [Status]
, [RevisionNumber]
, [ModifiedDate]
, [ShipMethodID]
, [ShipDate]
, [OrderDate]
, [TotalDue]
FROM [Purchasing].[PurchaseOrderHeader];
CHECKPOINT;
SET @Loops = @Loops + 1;
SET @Increment = @Increment + 5000;
END
/* Check to see how much data exists per partition */
SELECT
$PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number]
, MIN([o].[OrderDate]) AS [Min_Order_Date]
, MAX([o].[OrderDate]) AS [Max_Order_Date]
, COUNT(*) AS [Rows In Partition]
FROM [dbo].[Orders] AS [o]
GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate])
ORDER BY [Partition Number];
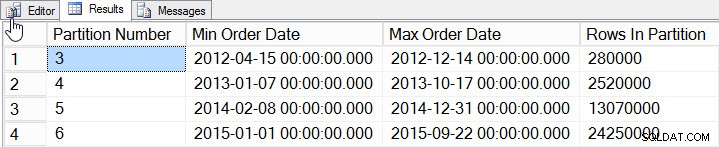 Données par partition
Données par partition
Nous avons ajouté des données pour 2012 à 2015, avec beaucoup plus de données en 2014 et 2015. Voyons à quoi ressemblent nos statistiques :
DBCC SHOW_STATISTICS ('dbo.Orders',[OrdersPK]);
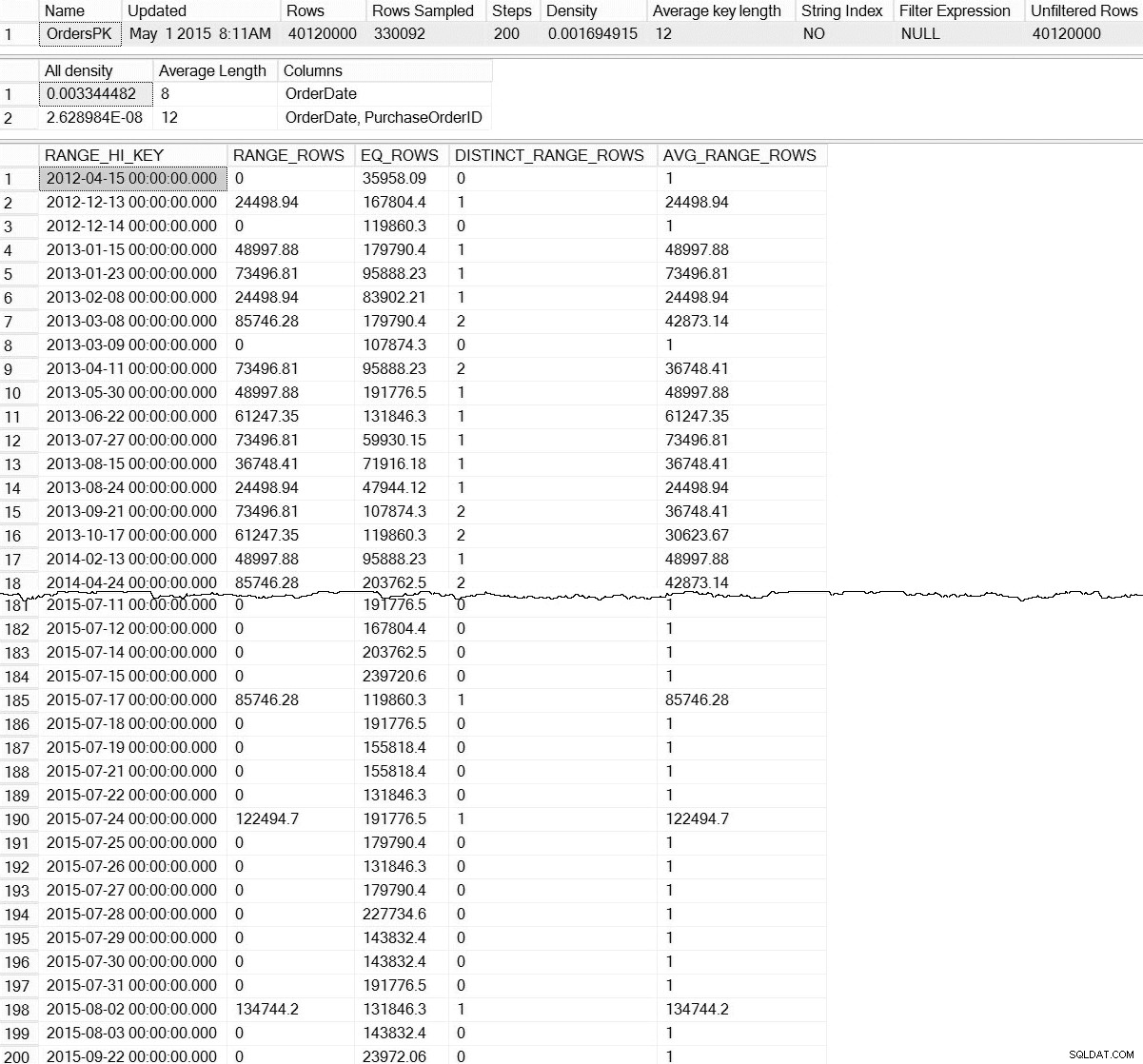 Sortie DBCC SHOW_STATISTICS pour dbo.Orders (cliquez pour agrandir)
Sortie DBCC SHOW_STATISTICS pour dbo.Orders (cliquez pour agrandir)
Avec le DBCC SHOW_STATISTICS par défaut commande, nous n'avons aucune information sur les statistiques au niveau de la partition. Ne craignez rien; nous ne sommes pas complètement condamnés - il existe une fonction de gestion dynamique non documentée, sys.dm_db_stats_properties_internal . N'oubliez pas que non documenté signifie qu'il n'est pas pris en charge (il n'y a pas d'entrée MSDN pour le DMF) et qu'il peut changer à tout moment sans aucun avertissement de Microsoft. Cela dit, c'est un bon début pour se faire une idée de ce qui existe pour nos statistiques incrémentales :
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 Informations d'histogramme de dm_db_stats_properties_internal (cliquez pour agrandir)
Informations d'histogramme de dm_db_stats_properties_internal (cliquez pour agrandir)
C'est beaucoup plus intéressant. Ici, nous pouvons voir la preuve que les statistiques au niveau de la partition (et plus) existent. Parce que ce DMF n'est pas documenté, nous devons faire une interprétation. Pour aujourd'hui, nous allons nous concentrer sur les sept premières lignes de la sortie, où la première ligne représente l'histogramme pour l'ensemble du tableau (notez les rows valeur de 40 millions), et les lignes suivantes représentent les histogrammes pour chaque partition. Malheureusement, le partition_number la valeur de cet histogramme ne correspond pas au numéro de partition de sys.dm_db_index_physical_stats pour le partitionnement basé à droite (il correspond correctement au partitionnement basé à gauche). Notez également que cette sortie inclut également le last_updated et modification_counter colonnes, qui sont utiles lors du dépannage, et il peut être utilisé pour développer des scripts de maintenance qui mettent à jour intelligemment les statistiques en fonction de l'âge ou des modifications de lignes.
Minimisation de la maintenance requise
La principale valeur des statistiques incrémentielles à ce stade est la possibilité de mettre à jour les statistiques d'une partition et de les fusionner dans l'histogramme au niveau de la table, sans avoir à mettre à jour les statistiques pour l'ensemble de la table (et donc à lire l'intégralité de la table). Pour voir cela en action, commençons par mettre à jour les statistiques de la partition qui contient les données de 2015, la partition 5, et nous enregistrerons le temps pris et prendrons un instantané des sys.dm_io_virtual_file_stats DMF avant et après pour voir combien d'E/S se produisent :
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH RESAMPLE ON PARTITIONS(6); GO SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture AS f INNER JOIN #SecondCapture AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Sortie :
Temps d'exécution de SQL Server :Temps CPU =203 ms, temps écoulé =240 ms.
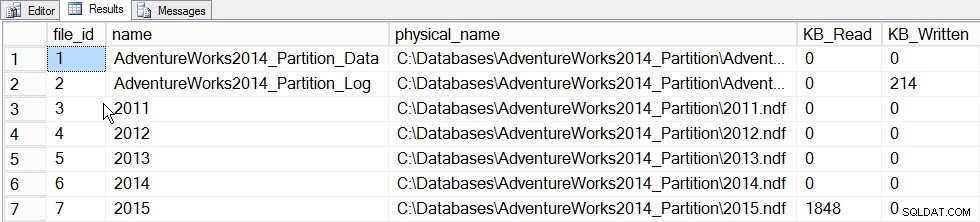 Données File_stats après la mise à jour d'une partition
Données File_stats après la mise à jour d'une partition
Si nous regardons le sys.dm_db_stats_properties_internal sortie, nous voyons que last_updated modifié à la fois pour l'histogramme de 2015 et l'histogramme au niveau de la table (ainsi que pour quelques autres nœuds, pour une enquête ultérieure) :
 Informations d'histogramme mises à jour à partir de dm_db_stats_properties_internal
Informations d'histogramme mises à jour à partir de dm_db_stats_properties_internal
Nous allons maintenant mettre à jour les statistiques avec un FULLSCAN pour la table, et nous prendrons un instantané de file_stats avant et après :
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH FULLSCAN SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture2 AS f INNER JOIN #SecondCapture2 AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Sortie :
Temps d'exécution de SQL Server :Temps CPU =12 720 ms, temps écoulé =13 646 ms
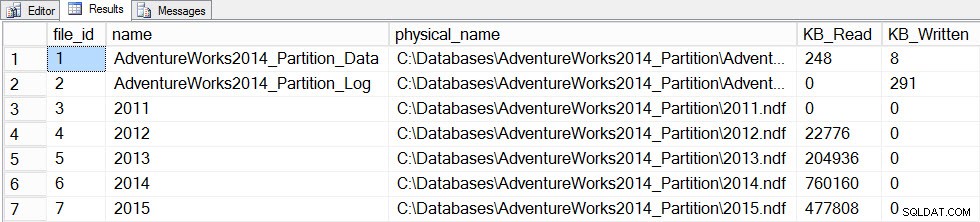 Données Filestats après mise à jour avec une analyse complète
Données Filestats après mise à jour avec une analyse complète
La mise à jour a pris beaucoup plus de temps (13 secondes contre quelques centaines de millisecondes) et a généré beaucoup plus d'E/S. Si nous vérifions sys.dm_db_stats_properties_internal encore une fois, nous constatons que last_updated modifié pour tous les histogrammes :
 Informations d'histogramme de dm_db_stats_properties_internal après une analyse complète
Informations d'histogramme de dm_db_stats_properties_internal après une analyse complète
Résumé
Bien que les statistiques incrémentielles ne soient pas encore utilisées par l'optimiseur de requêtes pour fournir des informations sur chaque partition, elles offrent un avantage en termes de performances lors de la gestion des statistiques pour les tables partitionnées. Si les statistiques ne doivent être mises à jour que pour certaines partitions, seules celles-ci peuvent être mises à jour. Les nouvelles informations sont ensuite fusionnées dans l'histogramme au niveau de la table, fournissant à l'optimiseur des informations plus récentes, sans le coût de la lecture de la table entière. À l'avenir, nous espérons que ces statistiques au niveau de la partition seront être utilisé par l'optimiseur. Restez à l'écoute…