Lorsque vous devez travailler avec une base de données que vous ne connaissez pas à 100 %, vous pouvez être submergé par les centaines de métriques disponibles. Lesquels sont les plus importants ? Que dois-je surveiller et pourquoi ? Quels modèles de métriques devraient sonner l'alarme ? Dans cet article de blog, nous essaierons de vous présenter certaines des métriques les plus importantes à surveiller lors de l'exécution de MySQL ou MariaDB en production.
Compteurs d'état Com_*
Nous allons commencer par les compteurs Com_* - ceux-ci définissent le nombre et les types de requêtes exécutées par MySQL. Nous parlons ici de types de requêtes comme SELECT, INSERT, UPDATE et bien d'autres. Il est très important de garder un œil sur ceux-ci, car des pics soudains ou des baisses inattendues peuvent suggérer que quelque chose s'est mal passé dans le système.
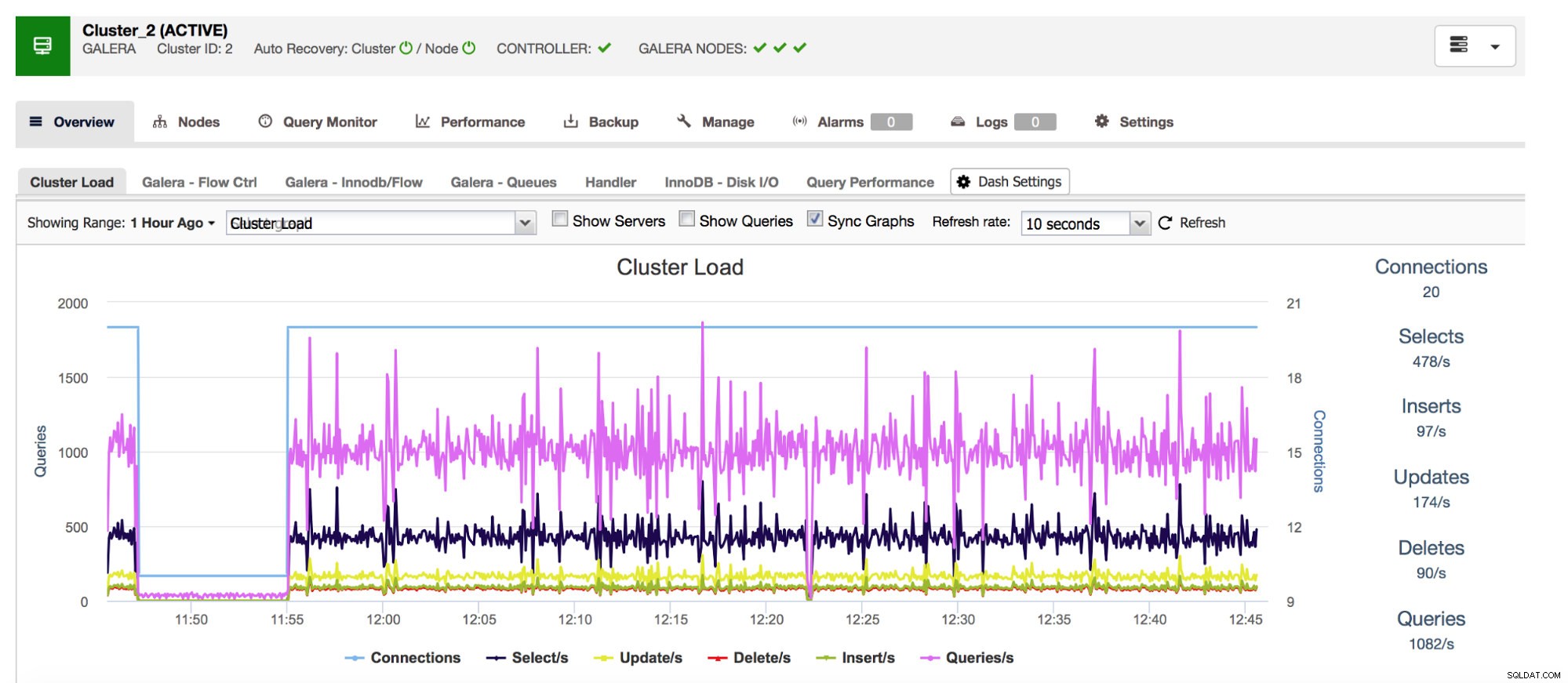
Notre système de gestion de base de données tout compris ClusterControl vous montre ces données liées aux types de requêtes les plus courants dans la section "Aperçu".
Handler_* Compteurs d'état
Une catégorie de métriques que vous devriez surveiller sont les compteurs Handler_* dans MySQL. Les compteurs Com_* vous indiquent le type de requêtes que votre instance MySQL exécute, mais un SELECT peut être totalement différent d'un autre - SELECT peut être une recherche de clé primaire, il peut également s'agir d'une analyse de table si un index ne peut pas être utilisé. Les gestionnaires vous indiquent comment MySQL accède aux données stockées - ceci est très utile pour étudier les problèmes de performances et évaluer s'il y a un gain possible dans l'examen des requêtes et l'indexation supplémentaire.
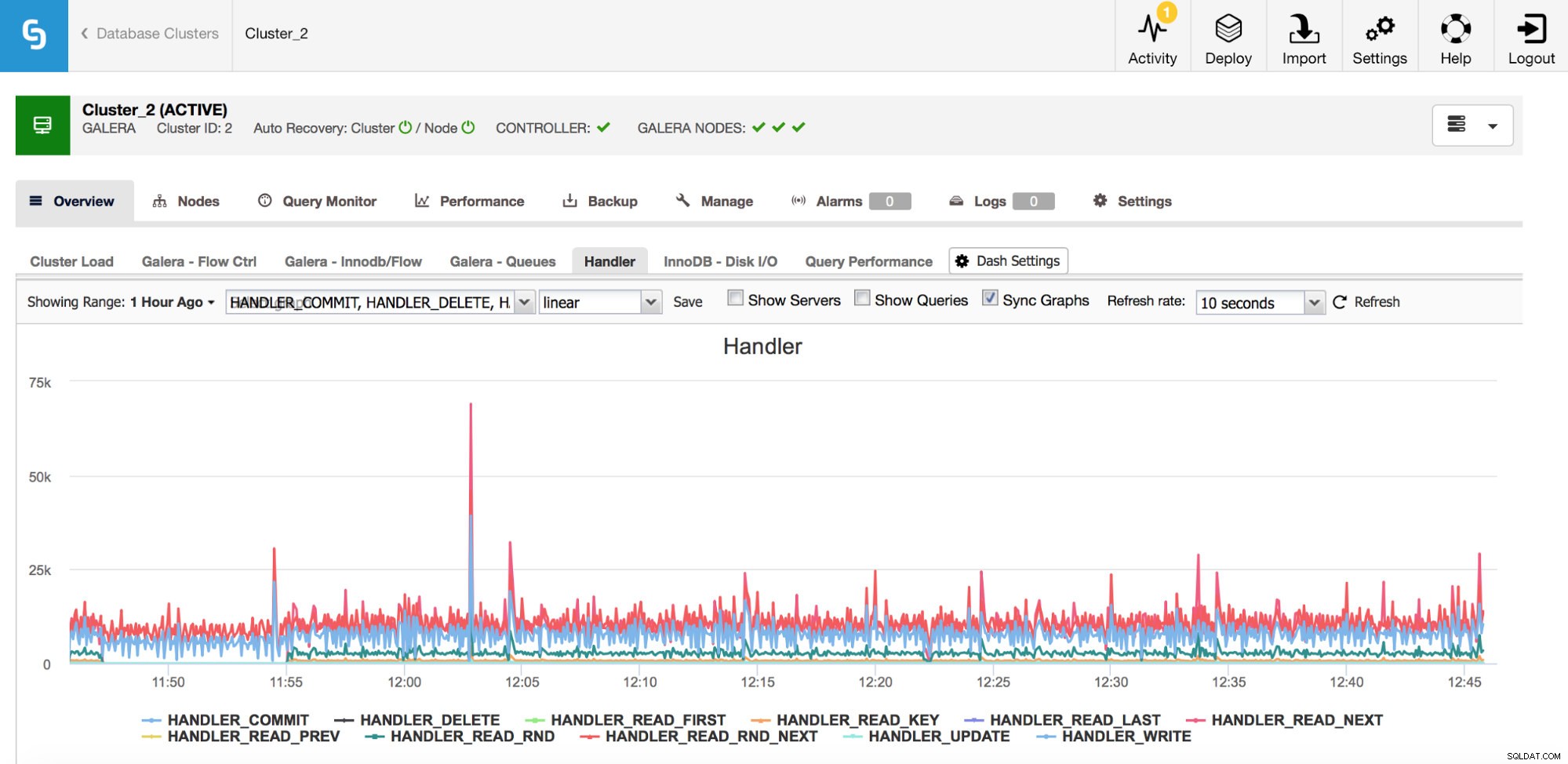
Comme vous pouvez le voir sur le graphique ci-dessus, il existe de nombreuses métriques à suivre (et les graphiques ClusterControl sont les plus importants) - nous ne les couvrirons pas tous ici (vous pouvez trouver des descriptions dans la documentation MySQL) mais nous aimerions souligner le les plus importants.
Handler_read_rnd_next - chaque fois que MySQL accède à une ligne sans recherche d'index, dans un ordre séquentiel, ce compteur sera augmenté. Si, dans votre charge de travail, handler_read_rnd_next est responsable d'un pourcentage élevé de l'ensemble du trafic, cela signifie que vos tables pourraient très probablement utiliser des index supplémentaires car MySQL effectue de nombreuses analyses de table.
Handler_read_next et handler_read_prev - ces deux compteurs sont mis à jour chaque fois que MySQL effectue une analyse d'index - en avant ou en arrière. Handler_read_first et handler_read_last peuvent apporter un peu plus de lumière sur le type de balayages d'index dont il s'agit - si nous parlons d'un balayage complet de l'index (avant ou arrière), ces deux compteurs seront mis à jour.
Handler_read_key - ce compteur, en revanche, si sa valeur est élevée, vous indique que vos tables sont bien indexées car de nombreuses lignes ont été consultées via une recherche d'index.
Délai de réplication
Si vous travaillez avec la réplication MySQL, le décalage de réplication est une métrique que vous souhaitez absolument surveiller. Le décalage de réplication est inévitable et vous devrez y faire face, mais pour y faire face, vous devez comprendre pourquoi cela se produit. Pour cela, la première étape sera de savoir _quand_ il est apparu.
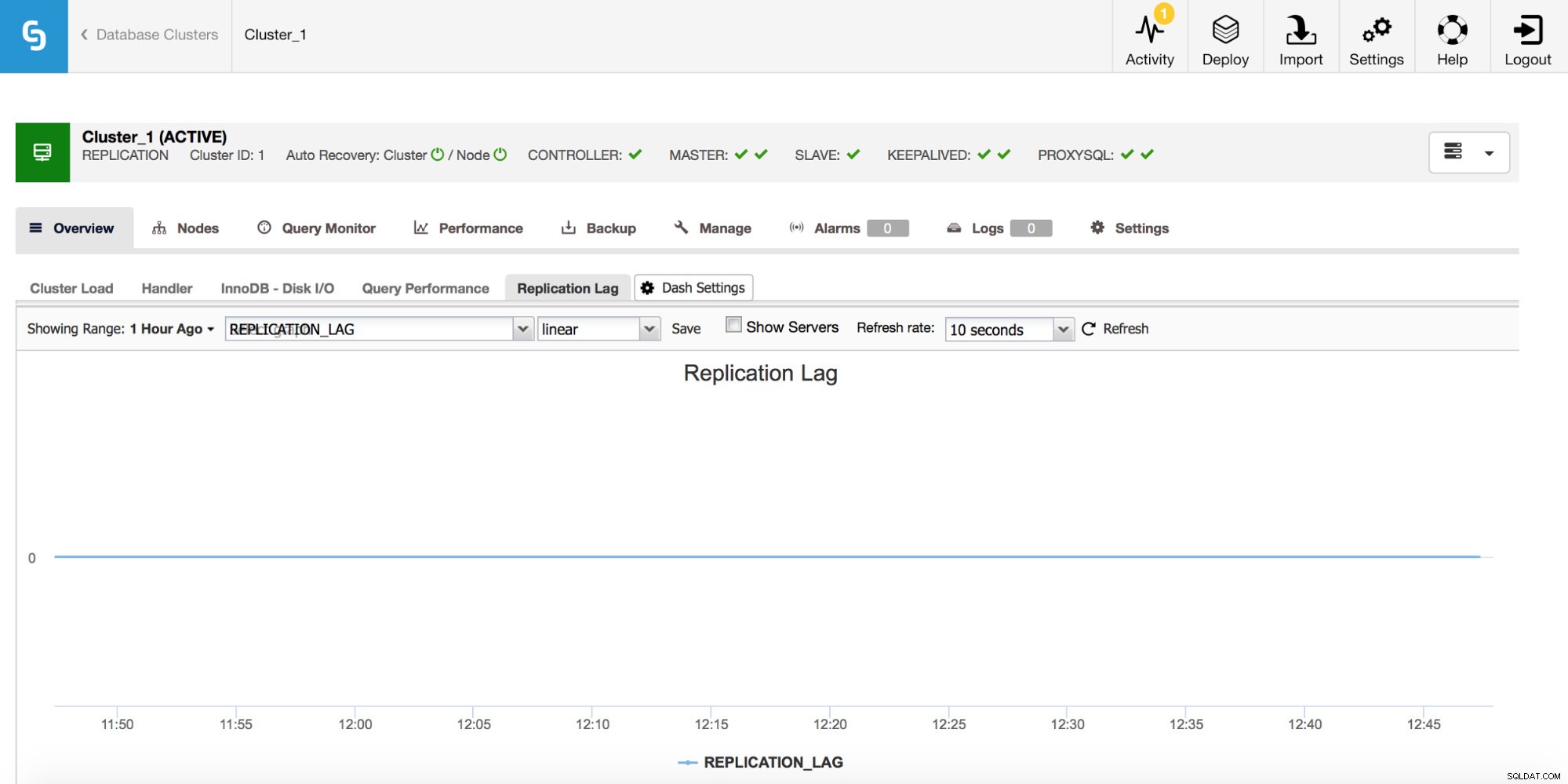
Chaque fois que vous voyez un pic de retard de réplication, vous voudriez vérifier d'autres graphiques pour obtenir plus d'indices - pourquoi cela s'est-il produit ? Qu'est-ce qui a pu en être la cause ? Les raisons peuvent être différentes :DML longs et lourds, augmentation significative du nombre de DML exécutés en peu de temps, limitations du processeur ou des E/S.
E/S InnoDB
Il existe un certain nombre de métriques importantes pour surveiller celles liées aux E/S.
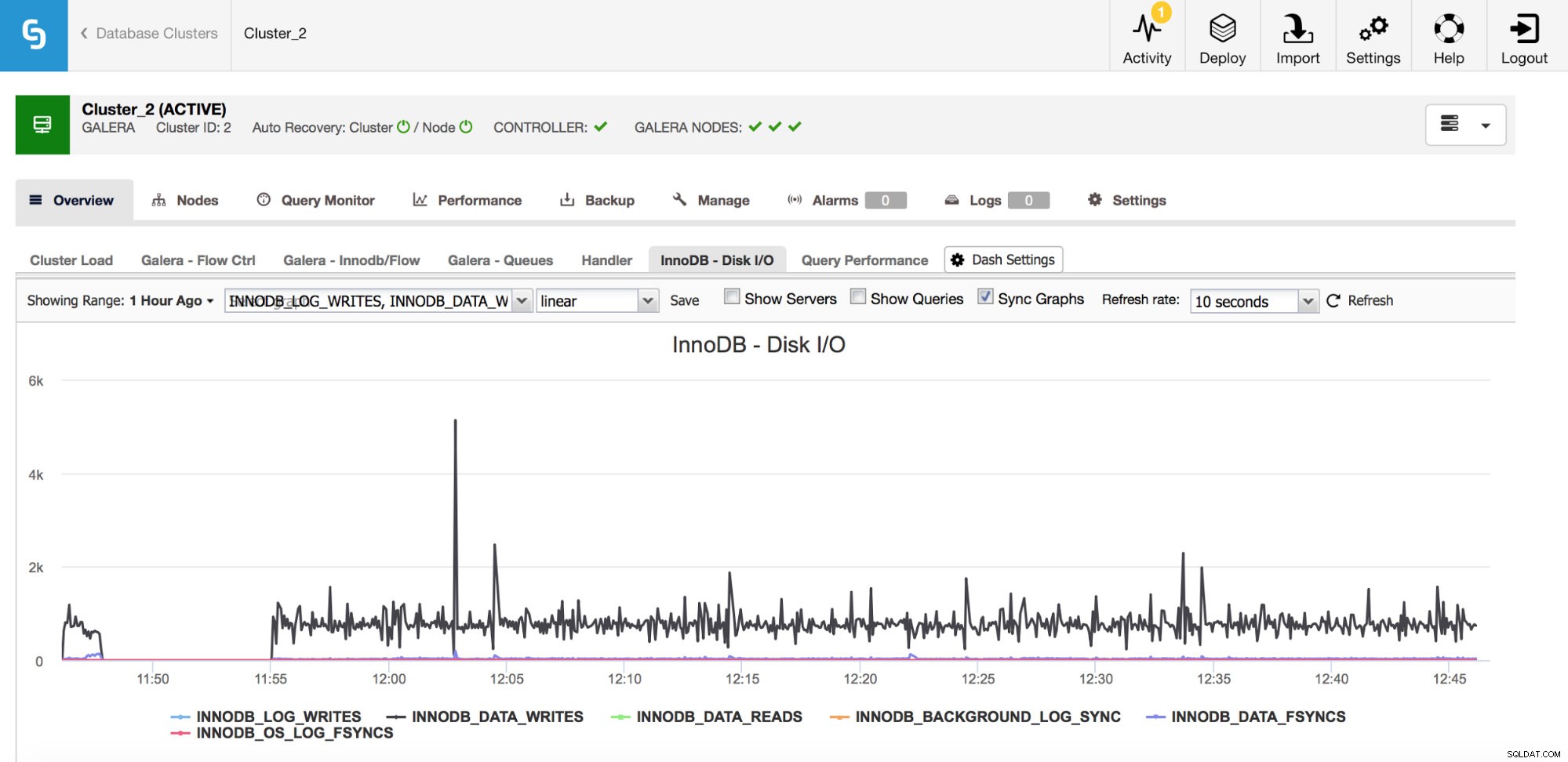
Dans le graphique ci-dessus, vous pouvez voir quelques métriques qui vous indiquent quel type d'E/S InnoDB fait - écritures et lectures de données, écritures de journalisation, fsyncs. Ces métriques vous aideront à décider, par exemple, si le retard de réplication a été causé par un pic d'E/S ou peut-être à cause d'une autre raison. Il est également important de suivre ces métriques et de les comparer avec vos limitations matérielles - si vous vous rapprochez des limites matérielles de vos disques, il est peut-être temps d'examiner cela avant que cela n'ait des effets plus graves sur les performances de votre base de données.
Guide DevOps de la gestion des bases de données de ManyninesDécouvrez ce que vous devez savoir pour automatiser et gérer vos bases de données open sourceTélécharger gratuitementMétriques Galera - Contrôle de flux et files d'attente
S'il vous arrive d'utiliser Galera Cluster (quelle que soit la saveur que vous utilisez), il y a quelques mesures supplémentaires que vous voudriez surveiller de près, elles sont quelque peu liées les unes aux autres. Le premier d'entre eux sont des métriques liées au contrôle de flux.
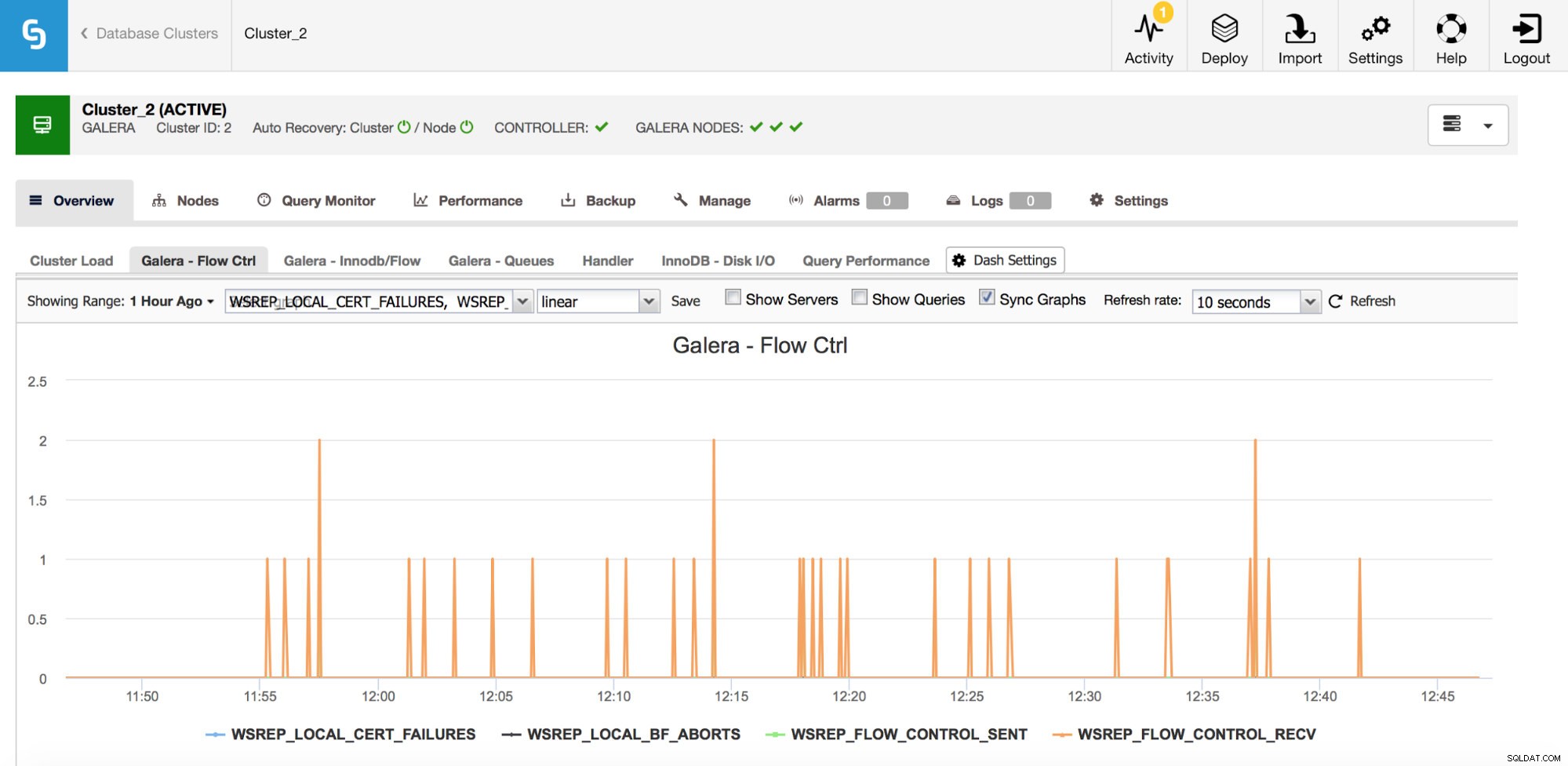
Le contrôle de flux, dans Galera, est un moyen de synchroniser le cluster. Chaque fois qu'un nœud se bloque et ne peut pas suivre le reste du cluster, il commence à envoyer des messages de contrôle de flux demandant aux nœuds restants du cluster de ralentir. Cela lui permet de se rattraper. Cela réduit les performances du cluster, il est donc important de pouvoir dire quel nœud et quand il a commencé à envoyer des messages de contrôle de flux. Cela peut expliquer certains des ralentissements rencontrés par les utilisateurs ou limiter la fenêtre de temps et l'hôte à utiliser pour une enquête plus approfondie.
Le deuxième ensemble de mesures à surveiller concerne les files d'attente d'envoi et de réception dans Galera.
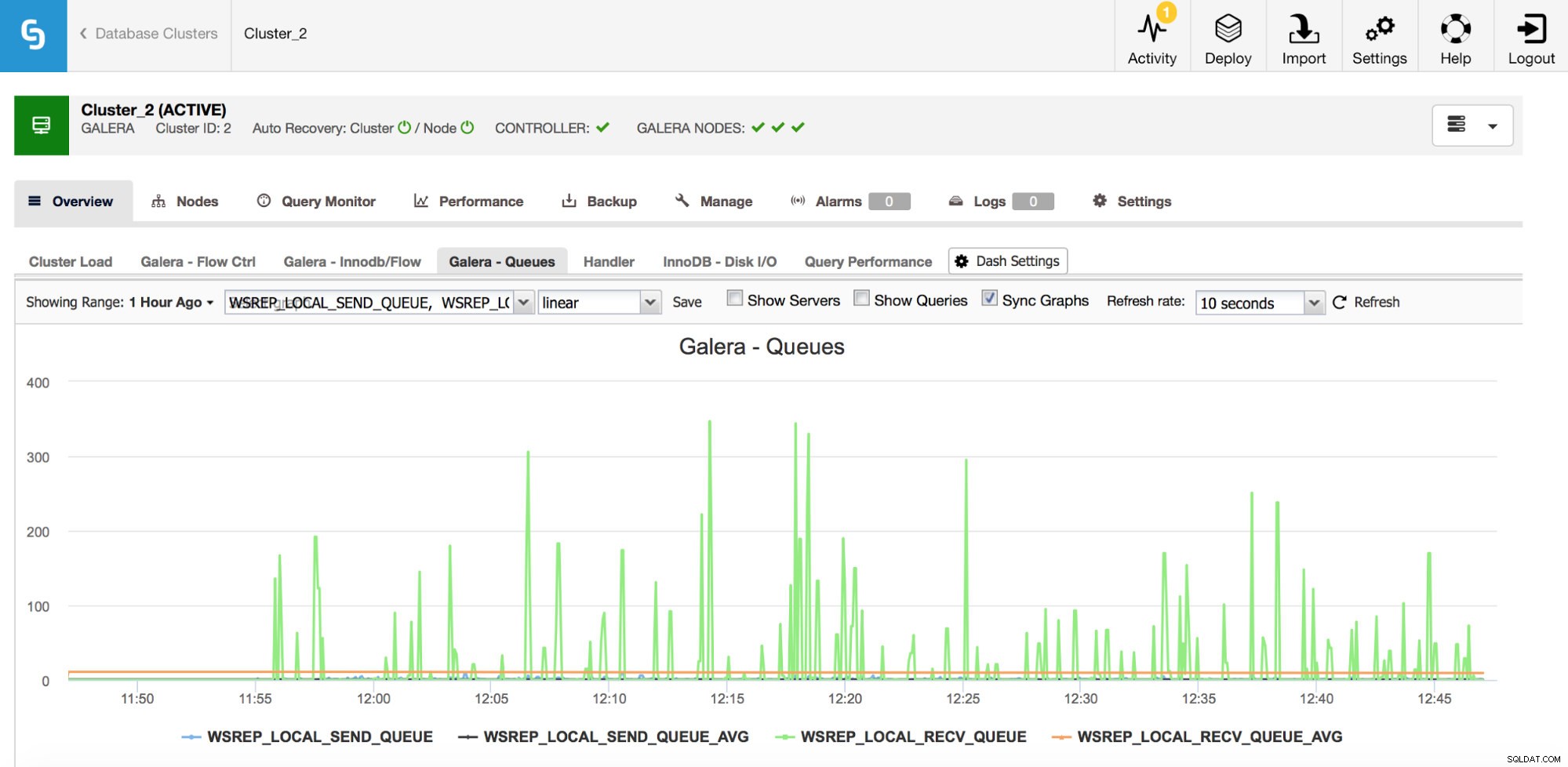
Les nœuds Galera peuvent mettre en cache des jeux d'écriture (transactions) s'ils ne peuvent pas tous les appliquer immédiatement. Si nécessaire, ils peuvent également mettre en cache des ensembles d'écritures qui sont sur le point d'être envoyés à d'autres nœuds (si un nœud donné reçoit des écritures de l'application). Les deux cas sont les symptômes d'un ralentissement qui, très probablement, entraînera l'envoi de messages de contrôle de flux et nécessitera une enquête :pourquoi cela s'est produit, sur quel nœud, à quelle heure ?
Ce n'est, bien sûr, que la partie émergée de l'iceberg lorsque nous considérons toutes les métriques que MySQL met à disposition - cependant, vous ne pouvez pas vous tromper si vous commencez à regarder celles que nous avons couvertes ici, en plus des métriques OS/matériel habituelles comme le CPU , la mémoire, l'utilisation du disque et l'état des services.