Lorsqu'un plan d'exécution inclut une analyse d'une structure d'index b-tree, le moteur de stockage peut pouvoir choisir entre deux stratégies d'accès physique lors de l'exécution du plan :
- Suivez la structure de l'index b-tree ; ou,
- localiser les pages à l'aide des informations d'allocation de page interne.
Lorsqu'un choix est disponible, le moteur de stockage prend la décision d'exécution pour chaque exécution. Une recompilation de plan n'est pas nécessaire pour qu'il change d'avis.
La stratégie b-tree commence à la racine de l'arbre, descend jusqu'à un bord extrême du niveau feuille (selon que le balayage est en avant ou en arrière), puis suit les liens de page au niveau feuille jusqu'à ce que l'autre extrémité de l'index soit atteinte . La stratégie d'allocation utilise des structures Index Allocation Map (IAM) pour localiser les pages de base de données allouées à l'index. Chaque page IAM mappe les allocations sur un intervalle de 4 Go dans un seul fichier de base de données physique, de sorte que l'analyse des chaînes IAM associées à un index a tendance à accéder aux pages d'index dans l'ordre des fichiers physiques (du moins pour ce que SQL Server peut en dire).
Les principales différences entre les deux stratégies sont :
- Une analyse d'arborescence b peut fournir des lignes au processeur de requêtes dans l'ordre des clés d'index ; une analyse pilotée par IAM ne le peut pas ;
- une analyse b-tree peut ne pas être en mesure d'émettre de grandes requêtes d'E/S de lecture anticipée si des pages d'index logiquement contiguës ne sont pas également physiquement contiguës (par exemple, en raison de la division des pages dans l'index).
Un parcours b-tree est toujours disponible pour un index. Les conditions souvent citées pour que les scans d'ordre d'allocation soient disponibles sont :
- Le plan de requête doit permettre une analyse non ordonnée de l'index ;
- l'index doit comporter au moins 64 pages ; et,
- soit un
TABLOCKouNOLOCKl'indice doit être spécifié.
La première condition signifie simplement que l'optimiseur de requête doit avoir marqué l'analyse avec le Ordered:False biens. Marquer le scan Ordered:False signifie que les résultats corrects du plan d'exécution ne exigent pas l'analyse pour renvoyer les lignes dans l'ordre des clés d'index (bien qu'il puisse le faire si cela est pratique ou autrement nécessaire).
La deuxième condition (taille) s'applique uniquement à SQL Server 2005 et versions ultérieures. Cela reflète le fait qu'il y a un certain coût de démarrage pour effectuer une analyse pilotée par IAM, il doit donc y avoir un nombre minimum de pages pour que les économies potentielles remboursent l'investissement initial. Les "64 pages" font référence à la valeur de data_pages pour le IN_ROW_DATA unité d'allocation uniquement, comme indiqué dans sys.allocation_units.
Bien sûr, il ne peut y avoir de profit à partir d'une analyse d'ordre d'allocation que si les considérations de lecture anticipée éventuellement plus importantes réellement entrent en jeu, mais SQL Server ne prend pas actuellement en compte ce facteur. En particulier, il ne tient pas compte de la quantité d'index actuellement en mémoire, ni de la fragmentation de l'index.
La troisième condition est probablement la description la moins complète de la liste. Les conseils ne sont en fait pas obligatoires , bien qu'elles puissent être utilisées pour répondre aux besoins réels :les données doivent être garanties de ne pas changer pendant l'analyse, ou (plus controversé) nous devons indiquer que nous ne nous soucions pas sur les résultats potentiellement inexacts, en effectuant l'analyse au niveau d'isolement de lecture non validée.
Même avec ces précisions, la liste des conditions d'un scan ordonné par allocation n'est toujours pas complète. Il existe un certain nombre de mises en garde et d'exceptions importantes, sur lesquelles nous reviendrons bientôt.
Démo
La requête suivante utilise l'exemple de base de données AdventureWorks :
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P; Notez que la table Person contient 3 869 pages. Le plan post-exécution (réel) est le suivant (affiché dans SQL Sentry Plan Explorer) :
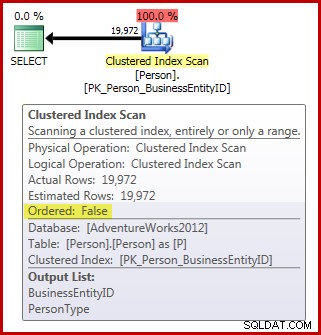
En termes d'exigences d'analyse des ordres d'allocation que nous avons jusqu'à présent :
- Le plan a le
Ordered:Falserequis biens; et, - le tableau compte plus de 64 pages ; mais,
- nous n'avons rien fait pour garantir que les données ne changent pas pendant l'analyse. En supposant que notre session utilise la valeur par défaut read commited niveau d'isolement, l'analyse n'est pas effectuée au niveau de la lecture non validée niveau d'isolement non plus.
Par conséquent, nous nous attendrions à ce que cette analyse soit effectuée en analysant l'arbre b plutôt qu'en étant pilotée par IAM. Les résultats de la requête indiquent que cela est probablement vrai :
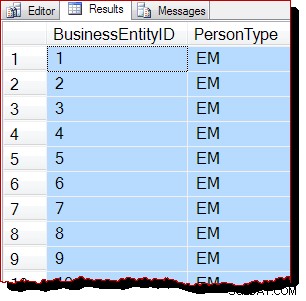
Les lignes sont renvoyées dans l'ordre des clés de l'index clusterisé (par BusinessEntityID ). Je dois préciser que cette commande de résultats n'est absolument pas garantie , et ne doit pas être invoqué. Les résultats ordonnés ne sont garantis que par un ORDER BY de niveau supérieur approprié clause.
Néanmoins, l'ordre de sortie observé est une preuve circonstancielle que l'analyse a été effectuée cette fois en suivant la structure b-tree de l'index groupé. Si plus de preuves sont nécessaires, nous pouvons joindre un débogueur et examiner le chemin de code que SQL Server exécute pendant l'analyse :

La pile d'appels montre clairement l'analyse suivant le b-tree.
Ajout d'un indice de verrouillage de table
Nous modifions maintenant la requête pour inclure un indice de verrouillage de table :
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK); Au niveau d'isolement de verrouillage de lecture validée par défaut, le verrou partagé au niveau de la table empêche toute modification simultanée possible des données. Avec les trois conditions préalables pour les analyses pilotées par IAM remplies, nous nous attendrions maintenant à ce que SQL Server utilise une analyse par ordre d'allocation. Le plan d'exécution est le même qu'avant, je ne le répéterai donc pas, mais les résultats de la requête sont certainement différents :
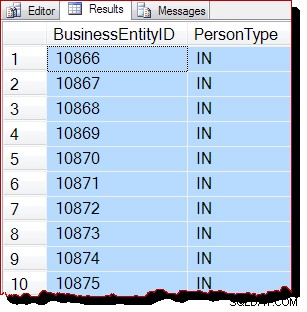
Les résultats sont toujours apparemment classés par BusinessEntityID , mais le point de départ (10866) est différent. En effet, si nous faisons défiler les résultats, nous rencontrons bientôt des sections qui sont plus manifestement hors de l'ordre des clés :
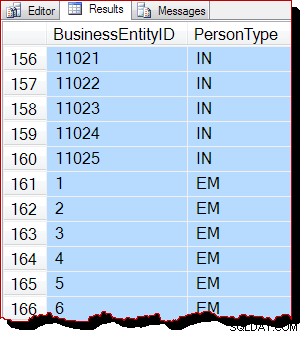
L'ordre partiel est dû au fait que l'analyse de l'ordre d'allocation traite une page d'index entière à la fois. Les résultats dans une page arrivent à être renvoyés triés par la clé d'index, mais l'ordre des pages numérisées est maintenant différent. Encore une fois, je dois souligner que les résultats peuvent sembler différents pour vous :il n'y a aucune garantie d'ordre de sortie, même au sein d'une page, sans un ORDER BY de niveau supérieur sur la requête d'origine.
Pour comparaison avec la pile d'appels présentée précédemment, il s'agit d'une trace de pile obtenue pendant que SQL Server traitait la requête avec le TABLOCK indice :
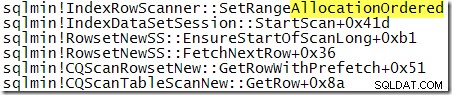
En avançant un peu plus dans l'exécution :

De toute évidence, SQL Server effectue une analyse ordonnée par allocation lorsque le verrou de table est spécifié. Il est dommage qu'il n'y ait aucune indication dans un plan de post-exécution sur le type d'analyse utilisé lors de l'exécution. Pour rappel, le type d'analyse est choisi par le moteur de stockage, et peut changer entre les exécutions sans recompilation du plan.
Autres façons de remplir la troisième condition
J'ai déjà dit que pour obtenir une analyse pilotée par IAM, nous devons nous assurer que les données ne peuvent pas changer sous l'analyse pendant qu'elle est en cours, ou nous devons exécuter la requête au niveau d'isolement en lecture non validée. Nous avons vu qu'un indice de verrouillage de table pour verrouiller l'isolation validée en lecture est suffisant pour répondre à la première de ces exigences, et il est facile de montrer que l'utilisation d'un NOLOCK/READUNCOMMITTED indice permet également une analyse de l'ordre d'allocation avec la requête de démonstration.
En fait, il existe de nombreuses façons de remplir la troisième condition, notamment :
- Modification de l'index pour n'autoriser que les verrous de table ;
- rendre la base de données en lecture seule (afin que les données soient garanties de ne pas changer) ; ou,
- modifier la session niveau d'isolement à
READ UNCOMMITTED.
Il existe cependant des variantes beaucoup plus intéressantes sur ce thème qui obligent à modifier les trois conditions énoncées précédemment…
Niveaux d'isolation de la gestion des versions de ligne
Activez l'isolement d'instantané validé en lecture (RCSI) sur la base de données AdventureWorks et exécutez le test avec le TABLOCK indice à nouveau (lors de la lecture de l'isolement engagé) :
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT ON
WITH ROLLBACK IMMEDIATE;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
GO
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK);
GO
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT OFF
WITH ROLLBACK IMMEDIATE;
Avec RCSI actif, un indexé scan est utilisé avec TABLOCK , pas l'analyse de l'ordre d'allocation que nous avons vue juste avant. La raison est le TABLOCK indice spécifie un verrou partagé au niveau de la table, mais avec RCSI activé, pas de verrous partagés sont pris. Sans le verrou de table partagé, nous n'avons pas satisfait à l'exigence d'empêcher les modifications simultanées des données pendant que l'analyse est en cours, de sorte qu'une analyse par ordre d'allocation ne peut pas être utilisée.
Cependant, il est possible d'obtenir une analyse ordonnée par allocation lorsque RCSI est activé. Une façon consiste à utiliser un TABLOCKX indice (pour un exclusif au niveau de la table verrou) au lieu de TABLOCK . On pourrait aussi retenir le TABLOCK indice et ajoutez-en un autre comme READCOMMITTEDLOCK , ou REPEATABLE READ ou SERIALIZABLE … etc. Tout cela fonctionne en empêchant la possibilité de modifications simultanées en prenant un verrou de table partagé, au prix de perdre les avantages de RCSI . On peut aussi toujours réaliser un scan d'ordre d'allocation en utilisant un NOLOCK ou READUNCOMMITTED indice, bien sûr.
La situation sous isolation d'instantané (SI) est très similaire à RCSI, et n'a pas été explorée en détail pour des raisons d'espace.
TABLESAMPLE effectue toujours* une analyse de l'ordre d'allocation
Le TABLESAMPLE clause est une exception intéressante à beaucoup de choses dont nous avons discuté jusqu'ici.
Spécification d'un TABLESAMPLE clause always* résulte en une analyse de l'ordre d'allocation, même sous RCSI ou SI, et même sans indice. Pour être clair, l'analyse de l'ordre d'allocation résultant de l'utilisation de TABLESAMPLE conserve la sémantique RCSI/SI - l'analyse utilise les versions de ligne et la lecture ne bloque pas l'écriture (et vice versa).
Une deuxième surprise est que TABLESAMPLE toujours* effectue une analyse pilotée par IAM même si le tableau compte moins de 64 pages . Cela a du sens car la documentation indique au moins que le SYSTEM la méthode d'échantillonnage utilise la structure IAM (il n'y a donc pas d'autre choix que de faire un scan d'ordre d'allocation) :
SYSTÈME Est une méthode d'échantillonnage dépendante de la mise en œuvre spécifiée par les normes ISO. Dans SQL Server, il s'agit de la seule méthode d'échantillonnage disponible et elle est appliquée par défaut. SYSTEM applique une méthode d'échantillonnage basée sur les pages dans laquelle un ensemble aléatoire de pages du tableau est choisi pour l'échantillon, et toutes les lignes de ces pages sont renvoyées en tant que sous-ensemble d'échantillon.
* Une exception se produit si les ROWS ou PERCENT spécification dans le TABLESAMPLE clause signifie 100 % de la table. Spécifier plus de ROWS que celles indiquées par les métadonnées sont actuellement dans le tableau ne fonctionnera pas non plus. Utilisation de TABLESAMPLE SYSTEM (100 PERCENT) ou équivalent ne sera pas forcer une analyse de l'ordre d'allocation.
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
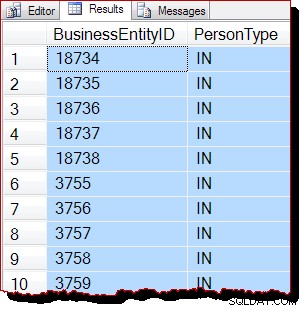
TABLESAMPLE SYSTEM (50 ROWS)
REPEATABLE (12345678)
--WITH (TABLOCK); Résultats :
L'effet de TOP et SET ROWCOUNT
En bref, aucun de ceux-ci n'a d'effet sur la décision d'utiliser ou non un balayage d'ordre d'allocation. Cela peut paraître surprenant dans les cas où il est "évident" que moins de 64 pages seront numérisées.
Par exemple, les requêtes suivantes utilisent toutes deux une analyse pilotée par IAM pour renvoyer 5 lignes d'une analyse :
SELECT TOP (5)
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 5;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 0; Les résultats sont les mêmes pour les deux :
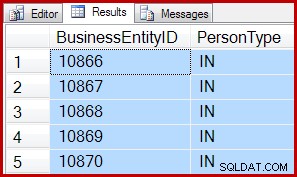
Cela signifie que TOP et SET ROWCOUNT les requêtes pourraient encourir les frais généraux liés à la configuration d'une analyse d'ordre d'allocation, même si moins de 64 pages sont numérisées. En guise d'atténuation, des requêtes TOP plus complexes avec des prédicats sélectifs poussés dans l'analyse pourraient toujours bénéficier d'une analyse d'ordre d'allocation. Si l'analyse doit traiter 10 000 pages pour trouver les 5 premières lignes qui correspondent, une analyse de l'ordre d'allocation peut toujours être gagnante.
Empêcher toutes* les analyses d'ordre d'allocation à l'échelle de l'instance
Ce n'est pas quelque chose que vous feriez probablement jamais intentionnellement, mais il existe un paramètre de serveur qui empêchera les analyses d'ordre d'allocation pour toutes les requêtes des utilisateurs dans toutes les bases de données.
Aussi improbable que cela puisse paraître, le paramètre en question est l'option de configuration du serveur de seuil de curseur, qui a la description suivante dans la documentation en ligne :
L'option de seuil de curseur spécifie le nombre de lignes dans le jeu de curseurs auquel les jeux de clés de curseur sont générés de manière asynchrone. Lorsque les curseurs génèrent un jeu de clés pour un jeu de résultats, l'optimiseur de requête estime le nombre de lignes qui seront renvoyées pour ce jeu de résultats. Si l'optimiseur de requête estime que le nombre de lignes renvoyées est supérieur à ce seuil, le curseur est généré de manière asynchrone, ce qui permet à l'utilisateur d'extraire des lignes du curseur pendant que le curseur continue d'être rempli. Sinon, le curseur est généré de manière synchrone et la requête attend que toutes les lignes soient renvoyées.
Si le cursor threshold est définie sur autre chose que -1 (valeur par défaut), aucune analyse de l'ordre d'allocation ne se produira pour les requêtes utilisateur dans n'importe quelle base de données sur l'instance SQL Server.
En d'autres termes, si le remplissage de curseurs asynchrones est activé, aucune analyse pilotée par IAM n'est effectuée pour vous.
* L'exception est (non-100 %) TABLESAMPLE requêtes. Les requêtes internes générées par le système pour la création et la mise à jour des statistiques continuent également d'utiliser des analyses par ordre d'allocation.
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
-- WARNING! Disables allocation-order scans instance-wide
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = 5000;
RECONFIGURE WITH OVERRIDE;
GO
-- Would normally result in an allocation-order scan
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (READUNCOMMITTED);
GO
-- Reset to default allocation-order scans
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = -1;
RECONFIGURE WITH OVERRIDE; Résultats (pas d'analyse de l'ordre d'allocation) :
On ne peut que deviner que la population de curseurs asynchrones ne fonctionne pas bien avec les analyses d'ordre d'allocation pour une raison quelconque. Il est tout à fait inattendu que cette restriction affecte toutes les requêtes des utilisateurs sans curseur aussi bien. Peut-être est-il trop difficile pour SQL Server de détecter si une requête s'exécute dans le cadre d'un curseur d'API émis en externe ? Qui sait.
Ce serait bien si cet effet secondaire était officiellement documenté quelque part, bien qu'il soit difficile de savoir exactement où il devrait aller dans Books Online. Je me demande combien de systèmes de production n'utilisent pas les analyses d'ordre d'allocation à cause de cela ? Peut-être pas beaucoup, mais sait-on jamais.
Pour conclure, voici un résumé. Une analyse ordonnée par allocation est disponible si :
- L'option de serveur
cursor thresholdest défini sur –1 (valeur par défaut); et, - l'opérateur d'analyse du plan de requête a le
Ordered:Falsebiens; et, - le nombre total de pages_données des
IN_ROW_DATAunités d'allocation est d'au moins 64 ; et, - soit :
- SQL Server a une garantie acceptable que les modifications simultanées sont impossibles ; ou,
- l'analyse s'exécute au niveau d'isolement de lecture non validée.
Indépendamment de tout ce qui précède, une analyse avec un TABLESAMPLE La clause utilise toujours des analyses ordonnées par allocation (avec la seule exception technique notée dans le texte principal).