Plus tôt dans cette série (Partie 1 | Partie 2), nous avons parlé de générer une série de nombres en utilisant diverses techniques. Bien qu'intéressante et utile dans certains scénarios, une application plus pratique consiste à générer une série de dates contiguës; par exemple, un rapport qui nécessite d'afficher tous les jours d'un mois, même si certains jours n'ont enregistré aucune transaction.
Dans un post précédent, j'ai mentionné qu'il est facile de dériver une série de jours à partir d'une série de chiffres. Puisque nous avons déjà établi plusieurs façons de dériver une série de nombres, regardons à quoi ressemble la prochaine étape. Commençons très simplement et supposons que nous voulons exécuter un rapport pendant trois jours, du 1er au 3 janvier, et incluons une ligne pour chaque jour. L'ancienne méthode serait de créer une table #temp, de créer une boucle, d'avoir une variable qui contient le jour actuel, dans la boucle d'insérer une ligne dans la table #temp jusqu'à la fin de la plage, puis d'utiliser le # table temporaire à jointure externe à nos données source. C'est plus de code que je ne veux même en présenter ici, sans parler de le mettre en production, de le maintenir et de faire en sorte que les collègues apprennent.
Commencer simplement
Avec une séquence de nombres établie (quelle que soit la méthode que vous choisissez), cette tâche devient beaucoup plus facile. Pour cet exemple, je peux remplacer les générateurs de séquences complexes par une union très simple, car je n'ai besoin que de trois jours. Je vais faire en sorte que cet ensemble contienne quatre lignes, afin qu'il soit également facile de montrer comment découper exactement la série dont vous avez besoin.
Tout d'abord, nous avons quelques variables pour contenir le début et la fin de la plage qui nous intéresse :
DECLARE @s DATE = '2012-01-01', @e DATE = '2012-01-03';
Maintenant, si nous commençons avec le générateur de série simple, cela peut ressembler à ceci. Je vais ajouter un ORDER BY ici aussi, juste pour être sûr, car nous ne pouvons jamais nous fier aux hypothèses que nous faisons sur la commande.
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT n FROM n ORDER BY n; -- result: n ---- 1 2 3 4
Pour convertir cela en une série de dates, nous pouvons simplement appliquer DATEADD() à partir de la date de début :
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT DATEADD(DAY, n, @s) FROM n ORDER BY n; -- result: ---- 2012-01-02 2012-01-03 2012-01-04 2012-01-05
Ce n'est toujours pas tout à fait exact, puisque notre gamme commence le 2 au lieu du 1er. Donc, pour utiliser notre date de début comme base, nous devons convertir notre ensemble de base 1 à base 0. Nous pouvons le faire en soustrayant 1 :
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT DATEADD(DAY, n-1, @s) FROM n ORDER BY n; -- result: ---- 2012-01-01 2012-01-02 2012-01-03 2012-01-04
Presque là! Nous avons juste besoin de limiter le résultat de notre source de série plus large, ce que nous pouvons faire en alimentant le DATEDIFF , en jours, entre le début et la fin de la plage, à un TOP opérateur - puis en ajoutant 1 (puisque DATEDIFF rapporte essentiellement une plage ouverte).
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s) FROM n ORDER BY n; -- result: ---- 2012-01-01 2012-01-02 2012-01-03
Ajout de données réelles
Maintenant, pour voir comment nous ferions une jointure avec une autre table pour dériver un rapport, nous pouvons simplement utiliser cette nouvelle requête et jointure externe avec les données source.
;WITH n(n) AS ( SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 ), d(OrderDate) AS ( SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s) FROM n ORDER BY n ) SELECT d.OrderDate, OrderCount = COUNT(o.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeader AS o ON o.OrderDate >= d.OrderDate AND o.OrderDate < DATEADD(DAY, 1, d.OrderDate) GROUP BY d.OrderDate ORDER BY d.OrderDate;
(Notez que nous ne pouvons plus dire COUNT(*) , puisque cela comptera le côté gauche, qui sera toujours 1.)
Une autre façon d'écrire cela serait :
;WITH d(OrderDate) AS
(
SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s)
FROM
(
SELECT 1 UNION ALL SELECT 2 UNION ALL
SELECT 3 UNION ALL SELECT 4
) AS n(n) ORDER BY n
)
SELECT
d.OrderDate,
OrderCount = COUNT(o.SalesOrderID)
FROM d
LEFT OUTER JOIN Sales.SalesOrderHeader AS o
ON o.OrderDate >= d.OrderDate
AND o.OrderDate < DATEADD(DAY, 1, d.OrderDate)
GROUP BY d.OrderDate
ORDER BY d.OrderDate;
Cela devrait permettre d'envisager plus facilement comment vous remplaceriez le CTE principal par la génération d'une séquence de dates à partir de n'importe quelle source de votre choix. Nous les passerons en revue (à l'exception de l'approche CTE récursive, qui ne servait qu'à biaiser les graphiques), en utilisant AdventureWorks2012, mais nous utiliserons le SalesOrderHeaderEnlarged tableau que j'ai créé à partir de ce script de Jonathan Kehayias. J'ai ajouté un index pour aider avec cette requête spécifique :
CREATE INDEX d_so ON Sales.SalesOrderHeaderEnlarged(OrderDate);
Notez également que je choisis une plage de dates arbitraire dont je sais qu'elle existe dans le tableau.
Tableau des nombres
;WITH d(OrderDate) AS ( SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s) FROM dbo.Numbers ORDER BY n ) SELECT d.OrderDate, OrderCount = COUNT(s.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND CONVERT(DATE, s.OrderDate) = d.OrderDate WHERE d.OrderDate >= @s AND d.OrderDate <= @e GROUP BY d.OrderDate ORDER BY d.OrderDate;
Planifier (cliquer pour agrandir) :
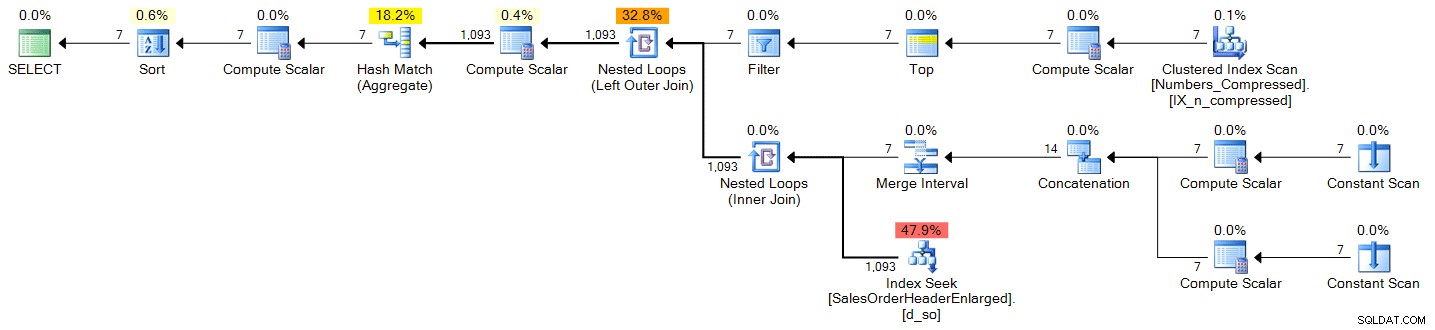
spt_values
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29'; ;WITH d(OrderDate) AS ( SELECT DATEADD(DAY, n-1, @s) FROM (SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) ROW_NUMBER() OVER (ORDER BY Number) FROM master..spt_values) AS x(n) ) SELECT d.OrderDate, OrderCount = COUNT(s.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND CONVERT(DATE, s.OrderDate) = d.OrderDate WHERE d.OrderDate >= @s AND d.OrderDate <= @e GROUP BY d.OrderDate ORDER BY d.OrderDate;
Planifier (cliquer pour agrandir) :
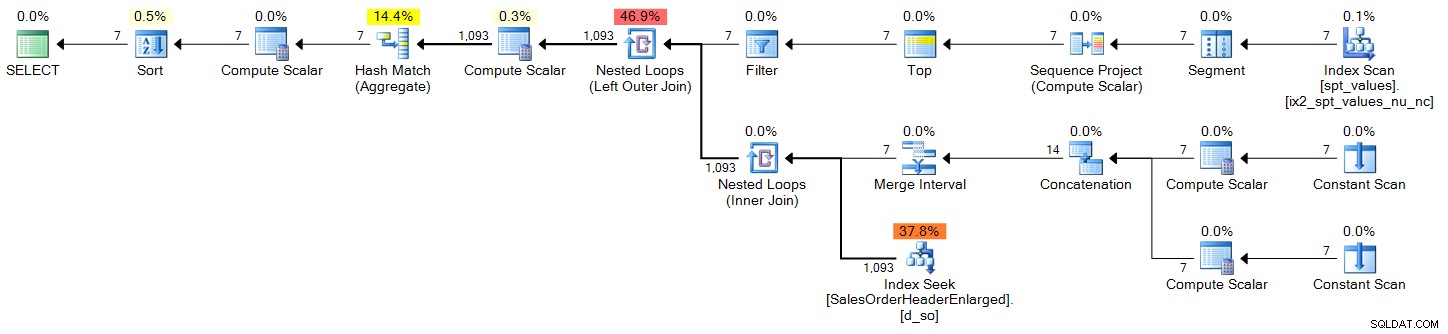
sys.all_objects
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29'; ;WITH d(OrderDate) AS ( SELECT DATEADD(DAY, n-1, @s) FROM (SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects) AS x(n) ) SELECT d.OrderDate, OrderCount = COUNT(s.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND CONVERT(DATE, s.OrderDate) = d.OrderDate WHERE d.OrderDate >= @s AND d.OrderDate <= @e GROUP BY d.OrderDate ORDER BY d.OrderDate;
Planifier (cliquer pour agrandir) :
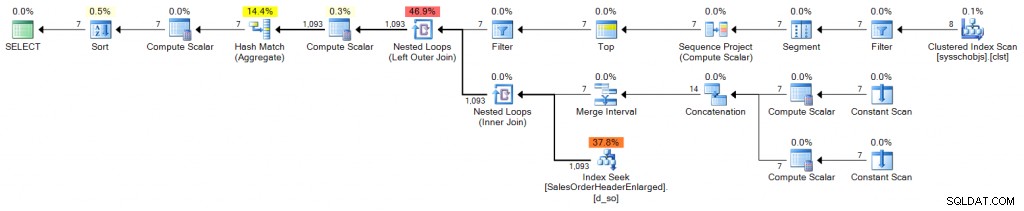
CTE empilés
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29';
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b),
d(OrderDate) AS
(
SELECT TOP (DATEDIFF(DAY, @s, @e) + 1)
d = DATEADD(DAY, ROW_NUMBER() OVER (ORDER BY n)-1, @s)
FROM e2
)
SELECT
d.OrderDate,
OrderCount = COUNT(s.SalesOrderID)
FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s
ON s.OrderDate >= @s AND s.OrderDate <= @e
AND d.OrderDate = CONVERT(DATE, s.OrderDate)
WHERE d.OrderDate >= @s AND d.OrderDate <= @e
GROUP BY d.OrderDate
ORDER BY d.OrderDate; Planifier (cliquer pour agrandir) :
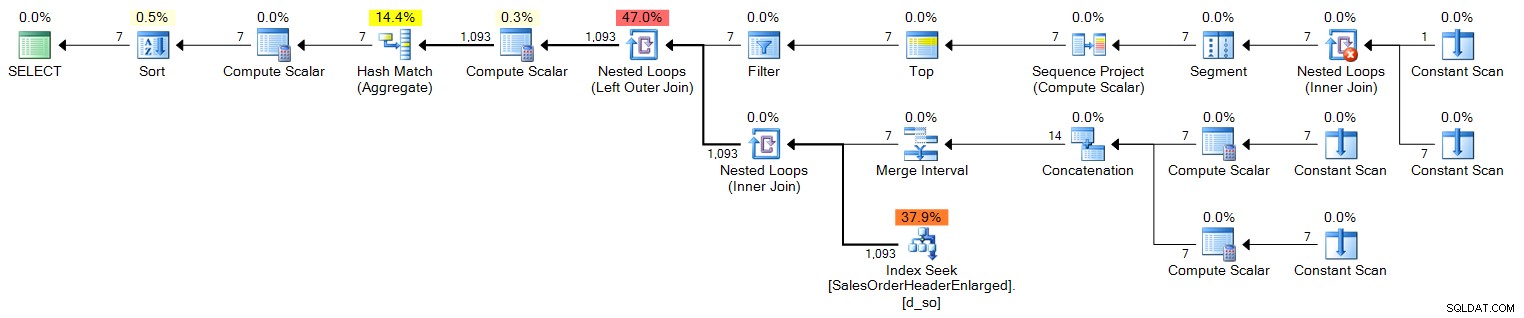
Maintenant, pendant un an, cela ne suffira pas, car il ne produit que 100 lignes. Pendant un an, nous aurions besoin de couvrir 366 lignes (pour tenir compte des années bissextiles potentielles), donc cela ressemblerait à ceci :
DECLARE @s DATE = '2006-10-23', @e DATE = '2007-10-22';
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b),
e3(n) AS (SELECT 1 FROM e2 CROSS JOIN (SELECT TOP (37) n FROM e2) AS b),
d(OrderDate) AS
(
SELECT TOP (DATEDIFF(DAY, @s, @e) + 1)
d = DATEADD(DAY, ROW_NUMBER() OVER (ORDER BY N)-1, @s)
FROM e3
)
SELECT
d.OrderDate,
OrderCount = COUNT(s.SalesOrderID)
FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s
ON s.OrderDate >= @s AND s.OrderDate <= @e
AND d.OrderDate = CONVERT(DATE, s.OrderDate)
WHERE d.OrderDate >= @s AND d.OrderDate <= @e
GROUP BY d.OrderDate
ORDER BY d.OrderDate; Planifier (cliquer pour agrandir) :
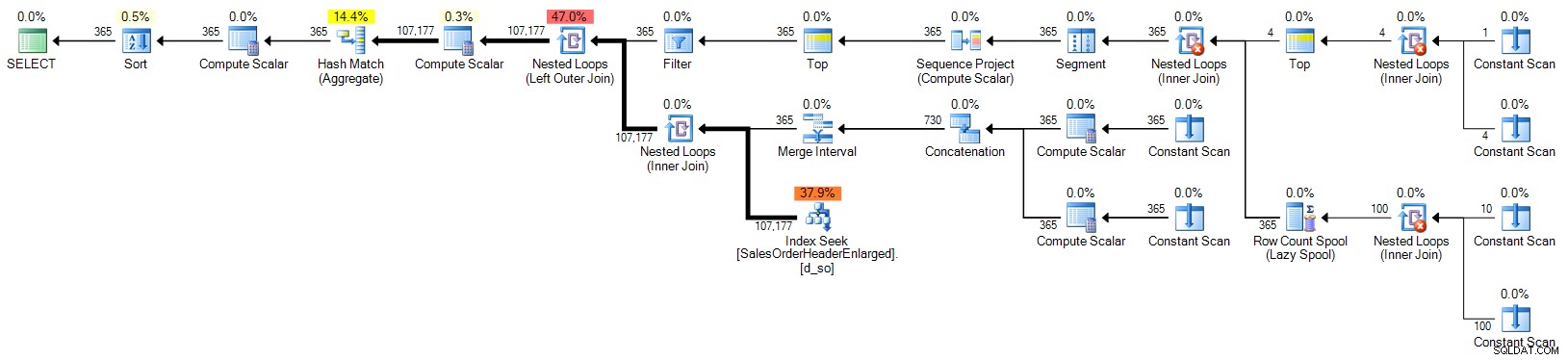
Tableau calendrier
C'est une nouveauté dont nous n'avons pas beaucoup parlé dans les deux articles précédents. Si vous utilisez des séries de dates pour de nombreuses requêtes, vous devriez envisager d'avoir à la fois une table de nombres et une table de calendrier. Le même argument vaut pour la quantité d'espace réellement requise et la rapidité d'accès lorsque la table est interrogée fréquemment. Par exemple, pour stocker 30 ans de dates, il faut moins de 11 000 lignes (le nombre exact dépend du nombre d'années bissextiles que vous couvrez) et ne prend que 200 Ko. Oui, vous avez bien lu :200 kilo-octets . (Et compressé, il ne fait que 136 Ko.)
Pour générer une table Calendar avec 30 ans de données, en supposant que vous ayez déjà été convaincu qu'avoir une table Numbers est une bonne chose, nous pouvons faire ceci :
DECLARE @s DATE = '2005-07-01'; -- earliest year in SalesOrderHeader DECLARE @e DATE = DATEADD(DAY, -1, DATEADD(YEAR, 30, @s)); SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) d = CONVERT(DATE, DATEADD(DAY, n-1, @s)) INTO dbo.Calendar FROM dbo.Numbers ORDER BY n; CREATE UNIQUE CLUSTERED INDEX d ON dbo.Calendar(d);
Maintenant, pour utiliser cette table Calendar dans notre requête de rapport de ventes, nous pouvons écrire une requête beaucoup plus simple :
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29'; SELECT OrderDate = c.d, OrderCount = COUNT(s.SalesOrderID) FROM dbo.Calendar AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND c.d = CONVERT(DATE, s.OrderDate) WHERE c.d >= @s AND c.d <= @e GROUP BY c.d ORDER BY c.d;
Planifier (cliquer pour agrandir) :

Performances
J'ai créé des copies compressées et non compressées des tables Numbers et Calendar, et testé une plage d'une semaine, une plage d'un mois et une plage d'un an. J'ai également exécuté des requêtes avec un cache froid et un cache chaud, mais cela s'est avéré largement sans conséquence.
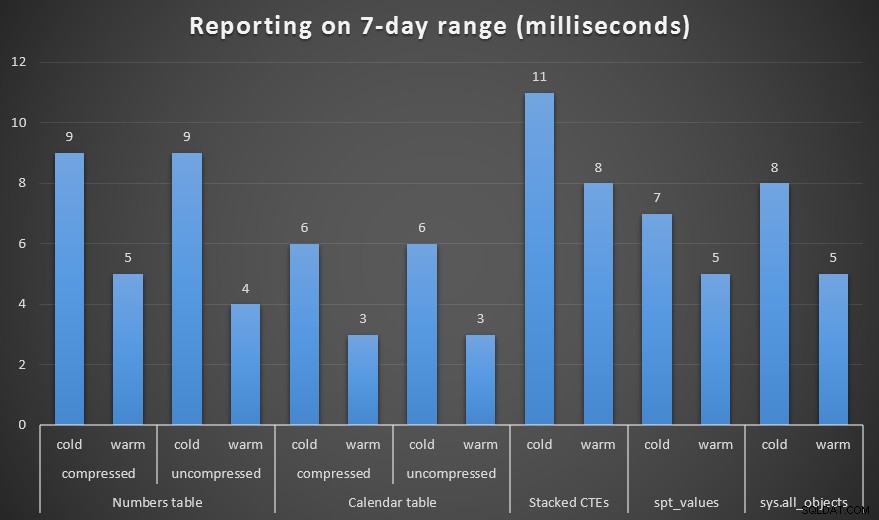
Durée, en millisecondes, pour générer une plage d'une semaine
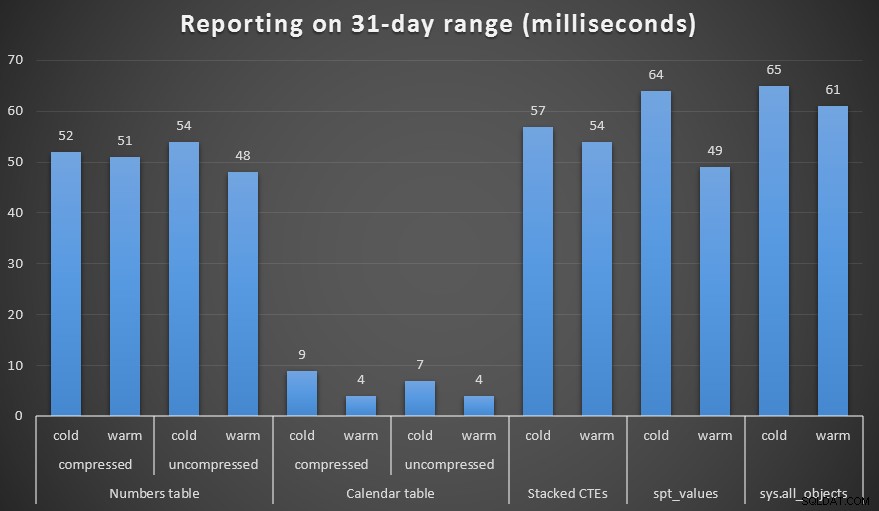
Durée, en millisecondes, pour générer une plage d'un mois
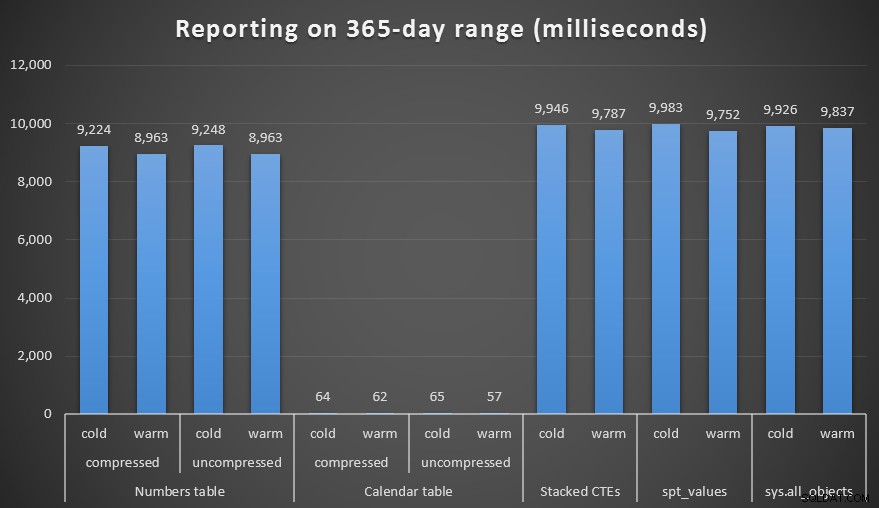
Durée, en millisecondes, pour générer une plage d'un an
Avenant
Paul White (blog | @SQL_Kiwi) a souligné que vous pouvez contraindre la table Numbers à produire un plan beaucoup plus efficace en utilisant la requête suivante :
SELECT OrderDate = DATEADD(DAY, n, 0), OrderCount = COUNT(s.SalesOrderID) FROM dbo.Numbers AS n LEFT OUTER JOIN Sales.SalesOrderHeader AS s ON s.OrderDate >= CONVERT(DATETIME, @s) AND s.OrderDate < DATEADD(DAY, 1, CONVERT(DATETIME, @e)) AND DATEDIFF(DAY, 0, OrderDate) = n WHERE n.n >= DATEDIFF(DAY, 0, @s) AND n.n <= DATEDIFF(DAY, 0, @e) GROUP BY n ORDER BY n;
À ce stade, je ne vais pas relancer tous les tests de performances (exercice pour le lecteur !), mais je supposerai que cela générera des timings meilleurs ou similaires. Pourtant, je pense qu'une table de calendrier est une chose utile à avoir même si ce n'est pas strictement nécessaire.
Conclusion
Les résultats parlent d'eux-mêmes. Pour générer une série de nombres, l'approche de la table des nombres l'emporte, mais seulement de manière marginale - même à 1 000 000 de lignes. Et pour une série de dates, à l'extrémité inférieure, vous ne verrez pas beaucoup de différence entre les différentes techniques. Cependant, il est tout à fait clair qu'à mesure que votre plage de dates s'élargit, en particulier lorsque vous avez affaire à une grande table source, la table Calendar démontre vraiment sa valeur, en particulier compte tenu de sa faible empreinte mémoire. Même avec le système métrique farfelu du Canada, 60 millisecondes sont bien meilleures qu'environ 10 *secondes* lorsqu'elles n'engrangent que 200 Ko sur le disque.
J'espère que vous avez apprécié cette petite série; c'est un sujet que j'avais l'intention de revoir depuis des lustres.
[ Partie 1 | Partie 2 | Partie 3 ]