Prédicats uniques
L'estimation du nombre de lignes qualifiées par un seul prédicat de requête est souvent simple. Lorsqu'un prédicat fait une comparaison simple entre une colonne et une valeur scalaire, il y a de fortes chances que l'estimateur de cardinalité sera en mesure de dériver une estimation de bonne qualité à partir de l'histogramme des statistiques. Par exemple, la requête AdventureWorks suivante produit une estimation parfaitement correcte de 203 lignes (en supposant qu'aucune modification n'a été apportée aux données depuis la création des statistiques) :
SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.TransactionDate = '20070903';
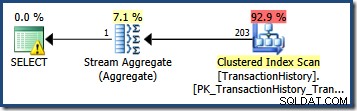
En regardant l'histogramme des statistiques pour le TransactionDate colonne, il est clair de voir d'où vient cette estimation :
DBCC SHOW_STATISTICS (
'Production.TransactionHistory',
'TransactionDate')
WITH HISTOGRAM;
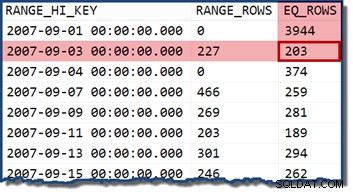
Si nous modifions la requête pour spécifier une date qui tombe dans un compartiment d'histogramme, l'estimateur de cardinalité suppose que les valeurs sont uniformément réparties. Utilisation d'une date de 2007-09-02 produit une estimation de 227 lignes (de la RANGE_ROWS entrée). Comme remarque intéressante, l'estimation reste à 227 lignes, quelle que soit la portion de temps que nous pourrions ajouter à la valeur de date (le TransactionDate la colonne est un datetime type de données).
Si nous essayons à nouveau la requête avec une date de 2007-09-05 ou 2007-09-06 (tous deux compris entre le 2007-09-04 et 2007-09-07 étapes de l'histogramme), l'estimateur de cardinalité suppose les 466 RANGE_ROWS sont réparties de manière égale entre les deux valeurs, en estimant 233 lignes dans les deux cas.
Il existe de nombreux autres détails concernant l'estimation de la cardinalité pour les prédicats simples, mais ce qui précède servira de rappel pour nos objectifs actuels.
Les problèmes des prédicats multiples
Lorsqu'une requête contient plusieurs prédicats de colonne, l'estimation de la cardinalité devient plus difficile. Considérez la requête suivante avec deux prédicats simples (dont chacun est facile à estimer seul) :
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'; Les plages de valeurs spécifiques de la requête sont délibérément choisies de sorte que les deux prédicats identifient exactement les mêmes lignes. Nous pourrions facilement modifier les valeurs de la requête pour aboutir à n'importe quelle quantité de chevauchement, y compris aucun chevauchement du tout. Imaginez maintenant que vous êtes l'estimateur de cardinalité :comment dériveriez-vous une estimation de cardinalité pour cette requête ?
Le problème est plus difficile qu'il n'y paraît au premier abord. Par défaut, SQL Server crée automatiquement des statistiques à colonne unique sur les deux colonnes de prédicat. Nous pouvons également créer manuellement des statistiques multi-colonnes. Cela nous donne-t-il suffisamment d'informations pour produire une bonne estimation de ces valeurs spécifiques ? Qu'en est-il du cas plus général où il pourrait y avoir tout degré de chevauchement ?
En utilisant les deux objets statistiques à une seule colonne, nous pouvons facilement dériver une estimation pour chaque prédicat en utilisant la méthode d'histogramme décrite dans la section précédente. Pour les valeurs spécifiques de la requête ci-dessus, les histogrammes montrent que le TransactionID la plage devrait correspondre à 68412.4 lignes et la TransactionDate la plage devrait correspondre à 68 413 Lignes. (Si les histogrammes étaient parfaits, ces deux nombres seraient exactement les mêmes.)
Ce que les histogrammes ne peuvent pas dites-nous combien de ces deux ensembles de lignes seront les mêmes lignes . Tout ce que nous pouvons dire sur la base des informations de l'histogramme, c'est que notre estimation devrait se situer entre zéro (pour aucun chevauchement) et 68 412,4 lignes (chevauchement complet).
La création de statistiques multi-colonnes ne fournit aucune assistance pour cette requête (ou pour les requêtes de plage en général). Les statistiques multi-colonnes ne créent toujours qu'un histogramme sur la première colonne nommée, dupliquant essentiellement l'histogramme associé à l'une des statistiques créées automatiquement. La densité supplémentaire les informations fournies par la statistique multi-colonnes peuvent être utiles pour fournir des informations de cas moyen pour les requêtes contenant plusieurs prédicats d'égalité, mais elles ne nous sont d'aucune utilité ici.
Pour produire une estimation avec un degré de confiance élevé, nous aurions besoin de SQL Server pour fournir de meilleures informations sur la distribution des données - quelque chose comme un multidimensionnel histogramme statistique. Autant que je sache, aucun moteur de base de données commercial n'offre actuellement une telle fonctionnalité, bien que plusieurs articles techniques aient été publiés sur le sujet (dont un de Microsoft Research qui utilisait un développement interne de SQL Server 2000).
Sans rien savoir des corrélations et des chevauchements de données pour des plages de valeurs particulières, il n'est pas clair comment nous devrions procéder pour produire une bonne estimation pour notre requête. Alors, que fait SQL Server ici ?
SQL Server 7 – 2012
L'estimateur de cardinalité dans ces versions de SQL Server suppose généralement que les valeurs des différents attributs d'une table sont distribuées complètement indépendamment les unes des autres. Cette hypothèse d'indépendance est rarement un reflet exact des données réelles, mais il a l'avantage de simplifier les calculs.
ET Sélectivité
En utilisant l'hypothèse d'indépendance, deux prédicats connectés par AND (appelée conjonction ) avec des sélectivités S1 et S2 , se traduisent par une sélectivité combinée de :
(S1 * S2)
Si le terme ne vous est pas familier, sélectivité est un nombre compris entre 0 et 1, représentant la fraction de lignes de la table qui passent le prédicat. Par exemple, si un prédicat sélectionne 12 lignes dans une table de 100 lignes, la sélectivité est (12/100) =0,12.
Dans notre exemple, le TransactionHistory table contient 113 443 lignes au total. Le prédicat sur TransactionID est estimé (à partir de l'histogramme) pour qualifier 68 412,4 lignes, donc la sélectivité est (68 412,4 / 113 443) ou environ 0,603055 . Le prédicat sur TransactionDate est également estimé avoir une sélectivité de (68 413 / 113 443) =environ 0,603061 .
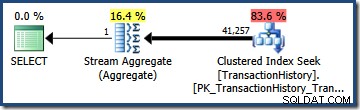
La multiplication des deux sélectivités (à l'aide de la formule ci-dessus) donne une estimation de sélectivité combinée de 0,363679 . La multiplication de cette sélectivité par la cardinalité du tableau (113 443) donne l'estimation finale de 41 256,8 lignes :
OU Sélectivité
Deux prédicats reliés par OR (une disjonction ) avec des sélectivités S1 et S2 , donne une sélectivité combinée de :
(S1 + S2) – (S1 * S2)
L'intuition derrière la formule est d'additionner les deux sélectivités, puis de soustraire l'estimation de leur conjonction (en utilisant la formule précédente). Il est clair que nous pourrions avoir deux prédicats, chacun de sélectivité 0,8, mais le simple fait de les additionner produirait une sélectivité combinée impossible de 1,6. Malgré l'hypothèse d'indépendance, nous devons reconnaître que les deux prédicats peuvent avoir un chevauchement, donc pour éviter le double comptage, la sélectivité estimée de la conjonction est soustraite.
Nous pouvons facilement modifier notre exemple courant pour utiliser OR :
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
OR TH.TransactionDate BETWEEN '20070901' AND '20080313';
Substitution des sélectivités de prédicat dans le OR formule donne une sélectivité combinée de :
(0.603055 + 0.603061) - (0.603055 * 0.603061) = 0.842437
Multipliée par le nombre de lignes dans le tableau, cette sélectivité nous donne l'estimation finale de la cardinalité de 95 568,6 :
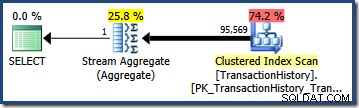
Aucune estimation (41 257 pour le AND requête; 95 569 pour le OR query) est particulièrement bon car les deux sont basés sur une hypothèse de modélisation qui ne correspond pas très bien à la distribution des données. Les deux requêtes renvoient en fait 68 413 lignes (car les prédicats identifient exactement les mêmes lignes).
Drapeau de suivi 4137 - Sélectivité minimale
Pour SQL Server 2008 (R1) à 2012 inclus, Microsoft a publié un correctif qui modifie la façon dont la sélectivité est calculée pour le AND cas (prédicats conjonctifs) uniquement. L'article de la base de connaissances dans ce lien ne contient pas beaucoup de détails, mais il s'avère que le correctif modifie la formule de sélectivité utilisée. Au lieu de multiplier les sélectivités individuelles, l'estimation de cardinalité pour les prédicats conjonctifs utilise désormais uniquement la sélectivité la plus faible.
Pour activer le comportement modifié, l'indicateur de trace pris en charge 4137 est requis. Un article distinct de la base de connaissances indique que cet indicateur de trace est également pris en charge pour une utilisation par requête via QUERYTRACEON indice :
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'
OPTION (QUERYTRACEON 4137); Avec cet indicateur actif, l'estimation de la cardinalité utilise la sélectivité minimale des deux prédicats, ce qui donne une estimation de 68 412,4 lignes :
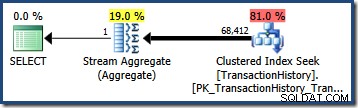
Cela se trouve être à peu près parfait pour notre requête car nos prédicats de test sont exactement corrélés (et les estimations dérivées des histogrammes de base sont également très bonnes).
Il est raisonnablement rare que des prédicats soient ainsi parfaitement corrélés avec des données réelles, mais l'indicateur de trace peut néanmoins aider dans certains cas. Notez que le comportement de sélectivité minimum s'appliquera à toutes les conjonctives (AND ) prédicats dans la requête ; il n'existe aucun moyen de spécifier le comportement à un niveau plus granulaire.
Il n'y a pas d'indicateur de trace correspondant pour estimer la disjonction (OR ) prédicats utilisant une sélectivité minimale.
SQL Server 2014
Le calcul de la sélectivité dans SQL Server 2014 se comporte de la même manière que les versions précédentes (et l'indicateur de trace 4137 fonctionne comme avant) si le niveau de compatibilité de la base de données est inférieur à 120, ou si l'indicateur de trace 9481 c'est actif. La définition du niveau de compatibilité de la base de données est officielle façon d'utiliser l'estimateur de cardinalité pré-2014 dans SQL Server 2014. L'indicateur de trace 9481 est efficace pour faire la même chose qu'au moment de la rédaction, et fonctionne également avec QUERYTRACEON , bien qu'il ne soit pas documenté pour le faire. Il n'y a aucun moyen de savoir quel sera le comportement RTM de ce drapeau.
Si le nouvel estimateur de cardinalité est actif, SQL Server 2014 utilise une formule par défaut différente pour combiner les prédicats conjonctif et disjonctif. Bien que non documentée, la formule de sélectivité pour les conjonctions a été découverte et documentée à plusieurs reprises maintenant. Le premier dont je me souviens avoir vu se trouve dans cet article de blog portugais et la deuxième partie de suivi a été publiée quelques semaines plus tard. Pour résumer, l'approche 2014 des prédicats conjonctifs consiste à utiliser l'intervalle exponentiel : étant donné une table de cardinalité C, et des sélectivités de prédicat S1 , S2 , S3 … Sn , où S1 est le plus sélectif et Sn le moins :
Estimate = C * S1 * SQRT(S2) * SQRT(SQRT(S3)) * SQRT(SQRT(SQRT(S4))) …
L'estimation est calculée en multipliant le prédicat le plus sélectif par la cardinalité de la table, multiplié par la racine carrée du prédicat le plus sélectif suivant, et ainsi de suite, chaque nouvelle sélectivité gagnant une racine carrée supplémentaire.
En rappelant que la sélectivité est un nombre compris entre 0 et 1, il est clair que l'application d'une racine carrée rapproche le nombre de 1. L'effet est de prendre en compte tous les prédicats dans l'estimation finale, mais de réduire l'impact des prédicats les moins sélectifs exponentiellement. Il y a sans doute plus de logique à cette idée que sous l'hypothèse d'indépendance , mais il s'agit toujours d'une formule fixe :elle ne change pas en fonction du degré réel de corrélation des données.
L'estimateur de cardinalité de 2014 utilise une formule d'attente exponentielle pour les deux prédicats conjonctif et disjonctif, bien que la formule utilisée dans le disjonctif (OR ) le cas n'a pas encore été documenté (officiellement ou autrement).
Indicateurs de trace de sélectivité SQL Server 2014
L'indicateur de trace 4137 (pour utiliser la sélectivité minimale) ne fait pas fonctionnent dans SQL Server 2014, si le nouvel estimateur de cardinalité est utilisé lors de la compilation d'une requête. Au lieu de cela, il y a un nouvel indicateur de trace 9471 . Lorsque cet indicateur est actif, la sélectivité minimale est utilisée pour estimer plusieurs valeurs conjonctives et disjonctives prédicats. C'est un changement par rapport au comportement 4137, qui n'affectait que les prédicats conjonctifs.
De même, l'indicateur de trace 9472 peut être spécifié pour assumer l'indépendance pour plusieurs prédicats, comme le faisaient les versions précédentes. Cet indicateur est différent de 9481 (pour utiliser l'estimateur de cardinalité antérieur à 2014) car sous 9472, le nouvel estimateur de cardinalité sera toujours utilisé, seule la formule de sélectivité pour plusieurs prédicats est affectée.
Ni 9471 ni 9472 ne sont documentés au moment de la rédaction (bien qu'ils puissent être chez RTM).
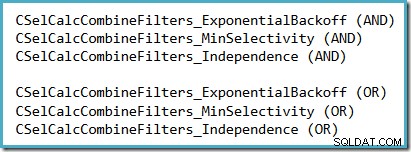
Un moyen pratique de voir quelle hypothèse de sélectivité est utilisée dans SQL Server 2014 (avec le nouvel estimateur de cardinalité actif) consiste à examiner la sortie de débogage du calcul de sélectivité produite lorsque les indicateurs de trace 2363 et 3604 sont actifs. La section à rechercher concerne le calculateur de sélectivité qui combine des filtres, où vous verrez l'un des éléments suivants, selon l'hypothèse utilisée :
Il n'y a aucune perspective réaliste que 2363 soit documenté ou pris en charge.
Réflexions finales
Il n'y a rien de magique dans le backoff exponentiel, la sélectivité minimale ou l'indépendance. Chaque approche représente une hypothèse (extrêmement) simplificatrice qui peut ou non produire une estimation acceptable pour une requête ou une distribution de données particulière.
À certains égards, l'intervalle de temps exponentiel représente un compromis entre les deux extrêmes de l'indépendance et sélectivité minimale . Même ainsi, il est important de ne pas avoir d'attentes déraisonnables à son égard. Jusqu'à ce qu'un moyen plus précis soit trouvé pour estimer la sélectivité pour plusieurs prédicats (avec des caractéristiques de performance raisonnables), il reste important d'être conscient des limites du modèle et de faire attention aux erreurs d'estimation (potentielles) en conséquence.
Les divers indicateurs de trace fournissent un certain contrôle sur l'hypothèse utilisée, mais la situation est loin d'être parfaite. D'une part, la granularité la plus fine à laquelle un indicateur peut être appliqué est une requête unique - le comportement d'estimation ne peut pas être spécifié au niveau du prédicat. Si vous avez une requête où certains prédicats sont corrélés et d'autres indépendants, les indicateurs de trace peuvent ne pas vous aider beaucoup sans refactoriser la requête d'une manière ou d'une autre. De même, une requête problématique peut avoir des corrélations de prédicats qui ne sont pas bien modélisées par aucune des options disponibles.
L'utilisation ad hoc des indicateurs de trace nécessite les mêmes autorisations que DBCC TRACEON – à savoir sysadmin . C'est probablement bien pour les tests personnels, mais pour la production, utilisez un guide de plan utilisant le QUERYTRACEON l'indice est une meilleure option. Avec un repère de plan, aucune autorisation supplémentaire n'est requise pour exécuter la requête (bien que des autorisations élevées soient nécessaires pour créer le repère de plan, bien sûr).