Dans mes articles de cette année, j'ai discuté des réactions instinctives à divers types d'attente, et dans cet article, je vais continuer avec le thème des statistiques d'attente et discuter du PAGEIOLATCH_XX Attendez. Je dis "attendez" mais il y a vraiment plusieurs types de PAGEIOLATCH attend, ce que j'ai signifié avec le XX à la fin. Les exemples les plus courants sont :
PAGEIOLATCH_SH– (SH sont) en attente qu'une page de fichier de données soit importée du disque dans le pool de mémoire tampon afin que son contenu puisse être luPAGEIOLATCH_EXouPAGEIOLATCH_UP– (EX exclusif ou UP date) attendant qu'une page de fichier de données soit importée du disque dans le pool de mémoire tampon afin que son contenu puisse être modifié
Parmi ceux-ci, le type de loin le plus courant est PAGEIOLATCH_SH .
Lorsque ce type d'attente est le plus répandu sur un serveur, la réaction instinctive est que le sous-système d'E/S doit avoir un problème et c'est donc là que les investigations doivent se concentrer.
La première chose à faire est de comparer le PAGEIOLATCH_SH le nombre et la durée d'attente par rapport à votre ligne de base. Si le volume d'attentes est plus ou moins le même, mais que la durée de chaque attente de lecture est devenue beaucoup plus longue, alors je serais préoccupé par un problème de sous-système d'E/S, tel que :
- Mauvaise configuration/dysfonctionnement au niveau du sous-système d'E/S
- Latence du réseau
- Une autre charge de travail d'E/S provoquant un conflit avec notre charge de travail
- Configuration de la réplication/de la mise en miroir du sous-système d'E/S synchrone
D'après mon expérience, le modèle est souvent que le nombre de PAGEIOLATCH_SH le nombre d'attentes a considérablement augmenté par rapport à la quantité de référence (normale) et la durée d'attente a également augmenté (c'est-à-dire que le temps d'une E/S de lecture a augmenté), car le grand nombre de lectures surcharge le sous-système d'E/S. Ce n'est pas un problème de sous-système d'E/S - c'est SQL Server qui pilote plus d'E/S qu'il ne devrait l'être. Le focus doit maintenant passer à SQL Server pour identifier la cause des E/S supplémentaires.
Causes d'un grand nombre d'E/S de lecture
SQL Server a deux types de lectures :les E/S logiques et les E/S physiques. Lorsque la partie Méthodes d'accès du moteur de stockage doit accéder à une page, elle demande au pool de mémoire tampon un pointeur vers la page en mémoire (appelée E/S logique) et le pool de mémoire tampon vérifie ses métadonnées pour voir si cette page est déjà en mémoire.
Si la page est en mémoire, le Buffer Pool donne le pointeur aux méthodes d'accès et l'E/S reste une E/S logique. Si la page n'est pas en mémoire, le pool de tampons émet une "vraie" E/S (appelée E/S physique) et le thread doit attendre qu'elle se termine, ce qui entraîne un PAGEIOLATCH_XX Attendez. Une fois l'E/S terminée et le pointeur disponible, le thread est notifié et peut continuer à s'exécuter.
Dans un monde idéal, l'intégralité de votre charge de travail tiendrait en mémoire. Ainsi, une fois que le pool de mémoire tampon s'est "réchauffé" et contient toute la charge de travail, plus aucune lecture n'est requise, seules les écritures de données mises à jour. Ce n'est pas un monde idéal cependant, et la plupart d'entre vous n'ont pas ce luxe, donc certaines lectures sont inévitables. Tant que le nombre de lectures reste autour de votre montant de référence, il n'y a pas de problème.
Lorsqu'un grand nombre de lectures sont requises soudainement et de manière inattendue, c'est un signe qu'il y a un changement significatif dans la charge de travail, la quantité de mémoire tampon disponible pour stocker des copies de pages en mémoire, ou les deux.
Voici quelques causes profondes possibles (liste non exhaustive) :
- Surpression de la mémoire externe de Windows sur SQL Server entraînant une réduction de la taille du pool de mémoire tampon par le gestionnaire de mémoire
- Planifiez un gonflement du cache entraînant l'emprunt de mémoire supplémentaire à partir du pool de mémoire tampon
- Un plan de requête effectuant une analyse de table/d'index cluster (au lieu d'une recherche d'index) à cause de :
- une augmentation du volume de la charge de travail
- un problème de détection de paramètres
- un index non cluster requis qui a été supprimé ou modifié
- une conversion implicite
Un modèle à rechercher qui suggérerait qu'une analyse de table/index clusterisé est la cause voit également un grand nombre de CXPACKET attend avec le PAGEIOLATCH_SH attend. Il s'agit d'un modèle courant qui indique que de grandes analyses parallèles de table/d'index cluster se produisent.
Dans tous les cas, vous pouvez rechercher quel plan de requête est à l'origine du PAGEIOLATCH_SH attend en utilisant sys.dm_os_waiting_tasks et d'autres DMV, et vous pouvez obtenir le code pour le faire dans mon article de blog ici. Si vous disposez d'un outil de surveillance tiers, il pourra peut-être vous aider à identifier le coupable sans vous salir les mains.
Exemple de workflow avec SQL Sentry et Plan Explorer
Dans un exemple simple (évidemment artificiel), supposons que je suis sur un système client utilisant la suite d'outils de SQL Sentry et que je vois un pic d'attente d'E/S dans la vue du tableau de bord de SQL Sentry, comme indiqué ci-dessous :
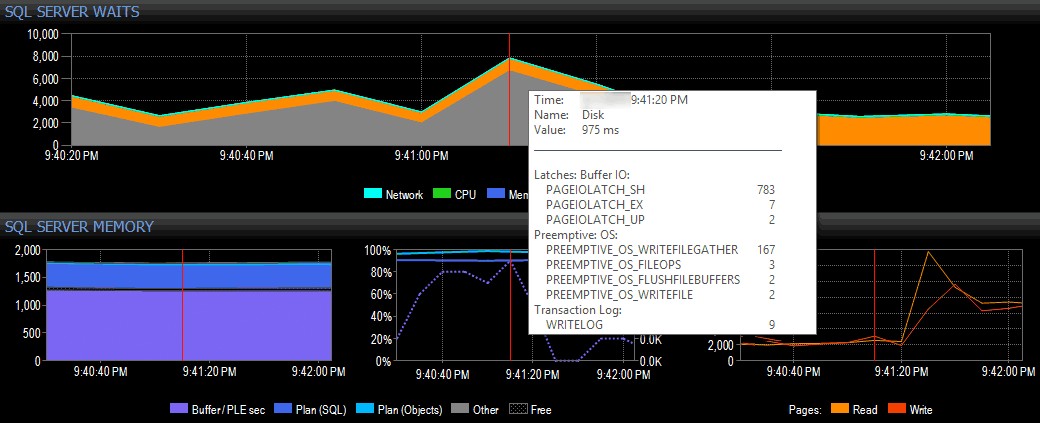
Repérage d'un pic d'attente d'E/S dans SQL Sentry
Je décide d'enquêter en cliquant avec le bouton droit sur un intervalle de temps sélectionné autour de l'heure du pic, puis en passant à la vue Top SQL, qui va me montrer les requêtes les plus coûteuses qui ont été exécutées :
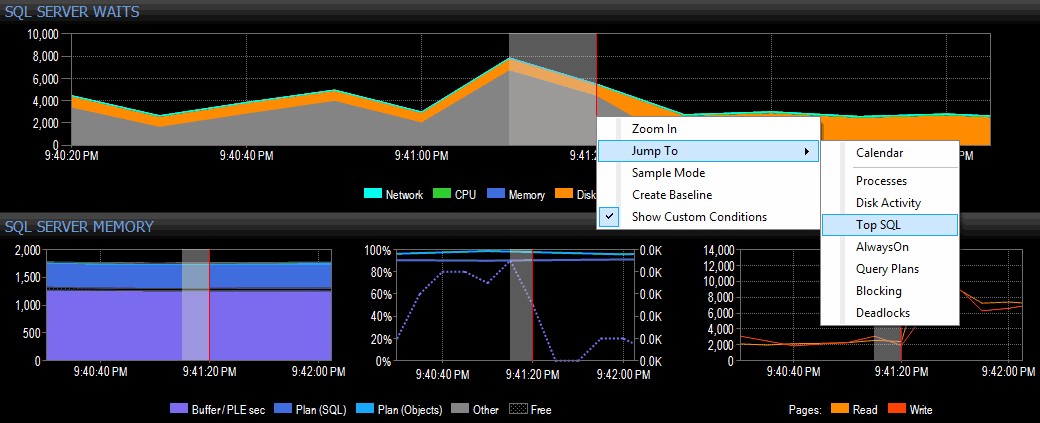
Mise en surbrillance d'une plage horaire et navigation vers Top SQL
Dans cette vue, je peux voir quelles requêtes d'E/S de longue durée ou élevées étaient en cours d'exécution au moment où le pic s'est produit, puis choisir d'explorer leurs plans de requête (dans ce cas, il n'y a qu'une seule requête de longue durée, qui a duré près d'une minute) :
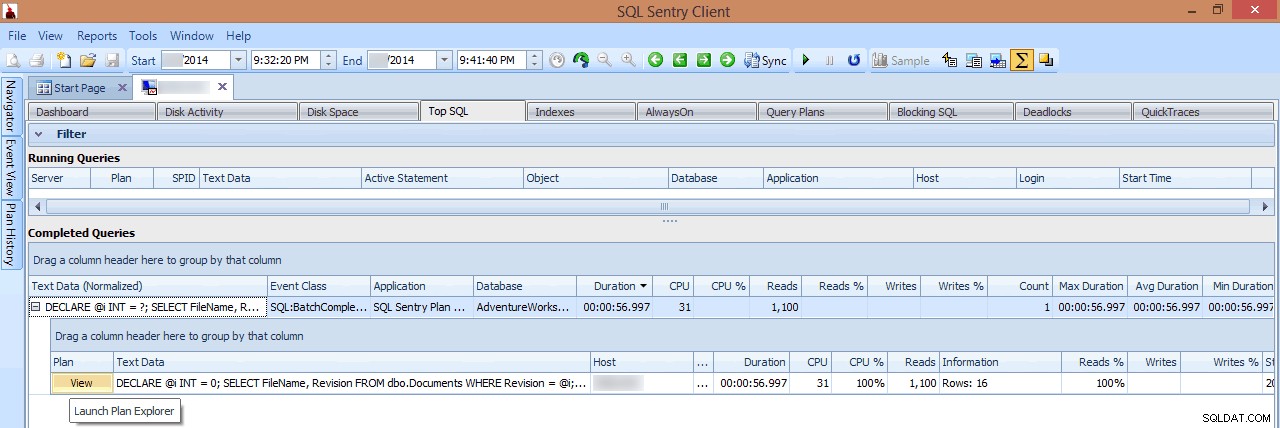
Examen d'une requête de longue durée dans Top SQL
Si je regarde le plan dans le client SQL Sentry ou que je l'ouvre dans l'explorateur de plans SQL Sentry, je vois immédiatement plusieurs problèmes. Le nombre de lectures nécessaires pour renvoyer 7 lignes semble bien trop élevé, le delta entre les lignes estimées et réelles est important, et le plan montre une analyse d'index se produisant là où je m'attendais à une recherche :
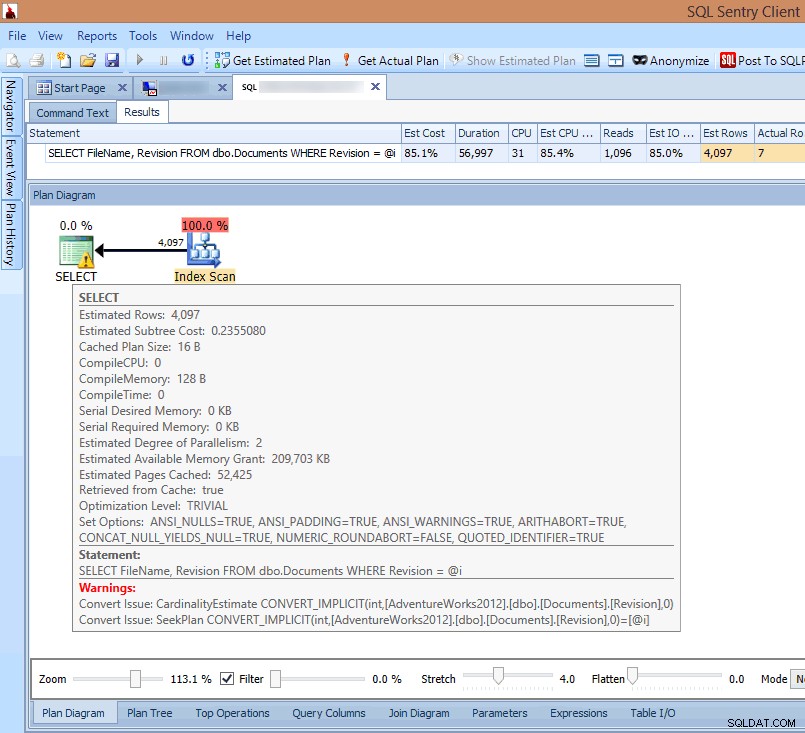
Voir les avertissements de conversion implicites dans le plan de requête
La cause de tout cela est mise en évidence dans l'avertissement sur le SELECT opérateur :C'est une conversion implicite !
Les conversions implicites sont un problème insidieux provoqué par une incompatibilité entre le type de données du prédicat de recherche et le type de données de la colonne recherchée, ou un calcul effectué sur la colonne de table plutôt que sur le prédicat de recherche. Dans les deux cas, SQL Server ne peut pas utiliser une recherche d'index sur la colonne de table et doit utiliser une analyse à la place.
Cela peut apparaître dans un code apparemment innocent, et un exemple courant consiste à utiliser un calcul de date. Si vous avez une table qui stocke l'âge des clients et que vous souhaitez effectuer un calcul pour voir combien ont 21 ans ou plus aujourd'hui, vous pouvez écrire un code comme celui-ci :
WHERE DATEADD (YEAR, 21, [MyTable].[BirthDate]) <= @today;
Avec ce code, le calcul est sur la colonne de la table et donc une recherche d'index ne peut pas être utilisée, ce qui entraîne une expression impossible à rechercher (techniquement connue sous le nom d'expression non SARGable) et une analyse de table/index clusterisé. Ceci peut être résolu en déplaçant le calcul de l'autre côté de l'opérateur :
WHERE [MyTable].[BirthDate] <= DATEADD (YEAR, -21, @today);
Pour savoir quand une comparaison de colonne de base nécessite une conversion de type de données pouvant entraîner une conversion implicite, mon collègue Jonathan Kehayias a écrit un excellent article de blog qui compare chaque combinaison de types de données et indique quand une conversion implicite sera requise.
Résumé
Ne tombez pas dans le piège de penser qu'un PAGEIOLATCH_XX excessif les attentes sont causées par le sous-système d'E/S. D'après mon expérience, ils sont généralement causés par quelque chose à voir avec SQL Server et c'est là que je commencerais le dépannage.
En ce qui concerne les statistiques d'attente générales, vous pouvez trouver plus d'informations sur leur utilisation pour le dépannage des performances dans :
- Ma série d'articles de blog SQLskills, en commençant par les statistiques d'attente, ou s'il vous plaît dites-moi où ça fait mal
- Bibliothèque de mes types d'attente et de mes classes de verrouillage ici
- Ma formation en ligne Pluralsight SQL Server :Dépannage des performances à l'aide des statistiques d'attente
- Sentry SQL
Dans le prochain article de la série, je discuterai d'un autre type d'attente qui est une cause fréquente de réactions instinctives. En attendant, bon dépannage !