De temps en temps, je vois quelqu'un exprimer l'exigence de créer un nombre aléatoire pour une clé. Il s'agit généralement de créer un type de CustomerID ou UserID de substitution qui est un numéro unique dans une certaine plage, mais qui n'est pas émis de manière séquentielle, et est donc beaucoup moins facile à deviner qu'un IDENTITY valeur.
NEWID() résout le problème de devinette, mais la pénalité de performance est généralement un facteur déterminant, en particulier lorsqu'elle est regroupée :des clés beaucoup plus larges que les entiers et des fractionnements de page dus à des valeurs non séquentielles. NEWSEQUENTIALID() résout le problème de fractionnement de page, mais reste une clé très large, et réintroduit le problème selon lequel vous pouvez deviner la valeur suivante (ou les valeurs récemment émises) avec un certain niveau de précision.
En conséquence, ils veulent une technique pour générer un et aléatoire entier unique. Générer un nombre aléatoire par lui-même n'est pas difficile, en utilisant des méthodes comme RAND() ou CHECKSUM(NEWID()) . Le problème survient lorsque vous devez détecter les collisions. Examinons rapidement une approche typique, en supposant que nous voulons des valeurs CustomerID comprises entre 1 et 1 000 000 :
DECLARE @rc INT = 0,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
-- or ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1;
-- or CONVERT(INT, RAND() * 1000000) + 1;
WHILE @rc = 0
BEGIN
IF NOT EXISTS (SELECT 1 FROM dbo.Customers WHERE CustomerID = @CustomerID)
BEGIN
INSERT dbo.Customers(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT @CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@rc = 0;
END
END Au fur et à mesure que le tableau s'agrandit, non seulement la recherche de doublons devient plus coûteuse, mais vos chances de générer un doublon augmentent également. Cette approche peut donc sembler fonctionner correctement lorsque la table est petite, mais je soupçonne que cela doit faire de plus en plus mal avec le temps.
Une approche différente
Je suis un grand fan des tables auxiliaires; J'écris publiquement sur les tableaux de calendrier et les tableaux de nombres depuis une décennie, et je les utilise depuis bien plus longtemps. Et c'est un cas où je pense qu'un tableau pré-rempli pourrait être très utile. Pourquoi compter sur la génération de nombres aléatoires au moment de l'exécution et sur la gestion des doublons potentiels, alors que vous pouvez remplir toutes ces valeurs à l'avance et savoir - avec une certitude à 100 %, si vous protégez vos tables contre le DML non autorisé - que la prochaine valeur que vous sélectionnez n'a jamais été déjà utilisé ?
CREATE TABLE dbo.RandomNumbers1
(
RowID INT,
Value INT, --UNIQUE,
PRIMARY KEY (RowID, Value)
);
;WITH x AS
(
SELECT TOP (1000000) s1.[object_id]
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
ORDER BY s1.[object_id]
)
INSERT dbo.RandomNumbers(RowID, Value)
SELECT
r = ROW_NUMBER() OVER (ORDER BY [object_id]),
n = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM x
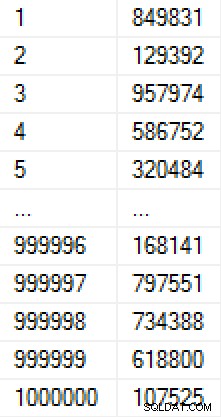
ORDER BY r; Cette population a pris 9 secondes à créer (dans une machine virtuelle sur un ordinateur portable) et a occupé environ 17 Mo sur disque. Les données du tableau ressemblent à ceci :
(Si nous étions inquiets de la façon dont les nombres étaient remplis, nous pourrions ajouter une contrainte unique sur la colonne Valeur, ce qui ferait 30 Mo de table. Si nous avions appliqué la compression de page, cela aurait été de 11 Mo ou 25 Mo, respectivement. )
J'ai créé une autre copie de la table et l'ai remplie avec les mêmes valeurs, afin de pouvoir tester deux méthodes différentes pour dériver la valeur suivante :
CREATE TABLE dbo.RandomNumbers2 ( RowID INT, Value INT, -- UNIQUE PRIMARY KEY (RowID, Value) ); INSERT dbo.RandomNumbers2(RowID, Value) SELECT RowID, Value FROM dbo.RandomNumbers1;
Maintenant, chaque fois que nous voulons un nouveau nombre aléatoire, nous pouvons simplement en retirer un de la pile de nombres existants et le supprimer. Cela nous évite d'avoir à nous soucier des doublons et nous permet d'extraire des nombres - à l'aide d'un index clusterisé - qui sont en fait déjà dans un ordre aléatoire. (Strictement parlant, nous n'avons pas à supprimer les nombres tels que nous les utilisons; nous pourrions ajouter une colonne pour indiquer si une valeur a été utilisée - cela faciliterait le rétablissement et la réutilisation de cette valeur dans le cas où un client serait supprimé ultérieurement ou si quelque chose se passait mal en dehors de cette transaction mais avant qu'ils ne soient entièrement créés.)
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding;
J'ai utilisé une variable de table pour contenir la sortie intermédiaire, car il existe diverses limitations avec DML composable qui peuvent rendre impossible l'insertion dans la table Customers directement à partir de DELETE (par exemple, la présence de clés étrangères). Néanmoins, reconnaissant que cela ne sera pas toujours possible, j'ai également voulu tester cette méthode :
DELETE TOP (1) dbo.RandomNumbers2 OUTPUT deleted.Value, ...other params... INTO dbo.Customers(CustomerID, ...other columns...);
Notez qu'aucune de ces solutions ne garantit vraiment un ordre aléatoire, en particulier si la table des nombres aléatoires a d'autres index (comme un index unique sur la colonne Valeur). Il n'y a aucun moyen de définir une commande pour un DELETE en utilisant TOP; de la documentation :
Donc, si vous voulez garantir un ordre aléatoire, vous pouvez plutôt faire quelque chose comme ceci :
DECLARE @holding TABLE(CustomerID INT);
;WITH x AS
(
SELECT TOP (1) Value
FROM dbo.RandomNumbers2
ORDER BY RowID
)
DELETE x OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding; Une autre considération ici est que, pour ces tests, les tables Customers ont une clé primaire en cluster sur la colonne CustomerID; cela entraînera certainement des fractionnements de page lorsque vous insérez des valeurs aléatoires. Dans le monde réel, si vous aviez cette exigence, vous finiriez probablement par vous regrouper sur une colonne différente.
Notez que j'ai également omis les transactions et la gestion des erreurs ici, mais celles-ci devraient également être prises en compte pour le code de production.
Tests de performances
Pour établir des comparaisons de performances réalistes, j'ai créé cinq procédures stockées, représentant les scénarios suivants (vitesse de test, distribution et fréquence de collision des différentes méthodes aléatoires, ainsi que la vitesse d'utilisation d'une table prédéfinie de nombres aléatoires) :
- Génération d'exécution à l'aide de
CHECKSUM(NEWID()) - Génération d'exécution à l'aide de
CRYPT_GEN_RANDOM() - Génération d'exécution à l'aide de
RAND() - Tableau de nombres prédéfinis avec variable de tableau
- Tableau de nombres prédéfinis avec insertion directe
Ils utilisent une table de journalisation pour suivre la durée et le nombre de collisions :
CREATE TABLE dbo.CustomerLog ( LogID INT IDENTITY(1,1) PRIMARY KEY, pid INT, collisions INT, duration INT -- microseconds );
Le code des procédures suit (cliquez pour afficher/masquer) :
/* Runtime using CHECKSUM(NEWID()) */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Checksum]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Checksum
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Checksum(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 1, @collisions, @duration;
END
GO
/* runtime using CRYPT_GEN_RANDOM() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_CryptGen]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_CryptGen
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_CryptGen(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 2, @collisions, @duration;
END
GO
/* runtime using RAND() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Rand]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = CONVERT(INT, RAND() * 1000000) + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Rand
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Rand(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = CONVERT(INT, RAND() * 1000000) + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 3, @collisions, @duration;
END
GO
/* pre-defined using a table variable */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_TableVariable]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers_Predefined_TableVariable(CustomerID)
SELECT CustomerID FROM @holding;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 4, @duration;
END
GO
/* pre-defined using a direct insert */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_Direct]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DELETE TOP (1) dbo.RandomNumbers2
OUTPUT deleted.Value INTO dbo.Customers_Predefined_Direct;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 5, @duration;
END
GO Et pour tester cela, j'exécuterais chaque procédure stockée 1 000 000 fois :
EXEC dbo.AddCustomer_Runtime_Checksum; EXEC dbo.AddCustomer_Runtime_CryptGen; EXEC dbo.AddCustomer_Runtime_Rand; EXEC dbo.AddCustomer_Predefined_TableVariable; EXEC dbo.AddCustomer_Predefined_Direct; GO 1000000
Sans surprise, les méthodes utilisant la table prédéfinie de nombres aléatoires ont pris un peu plus de temps *au début du test*, car elles devaient effectuer à la fois des E/S de lecture et d'écriture à chaque fois. En gardant à l'esprit que ces chiffres sont en microsecondes , voici les durées moyennes pour chaque procédure, à différents intervalles en cours de route (moyenne sur les 10 000 premières exécutions, les 10 000 exécutions intermédiaires, les 10 000 dernières exécutions et les 1 000 dernières exécutions) :
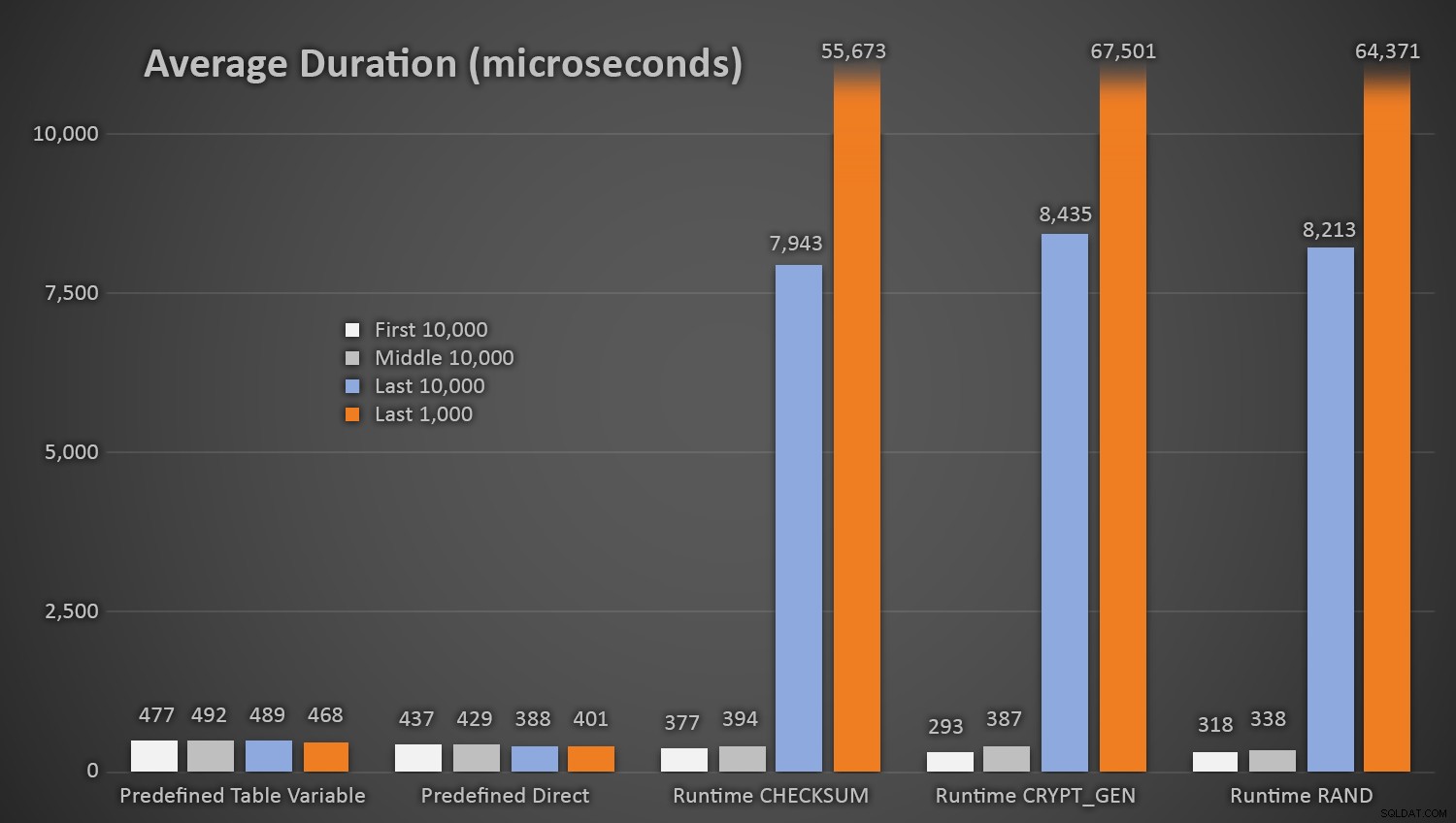
Durée moyenne (en microsecondes) de génération aléatoire en utilisant différentes approches
Cela fonctionne bien pour toutes les méthodes lorsqu'il y a peu de lignes dans la table Customers, mais à mesure que la table devient de plus en plus grande, le coût de la vérification du nouveau nombre aléatoire par rapport aux données existantes à l'aide des méthodes d'exécution augmente considérablement, à la fois en raison de l'augmentation de I /O et aussi parce que le nombre de collisions augmente (vous obligeant à essayer et réessayer). Comparez la durée moyenne dans les plages suivantes de nombre de collisions (et rappelez-vous que ce modèle n'affecte que les méthodes d'exécution) :
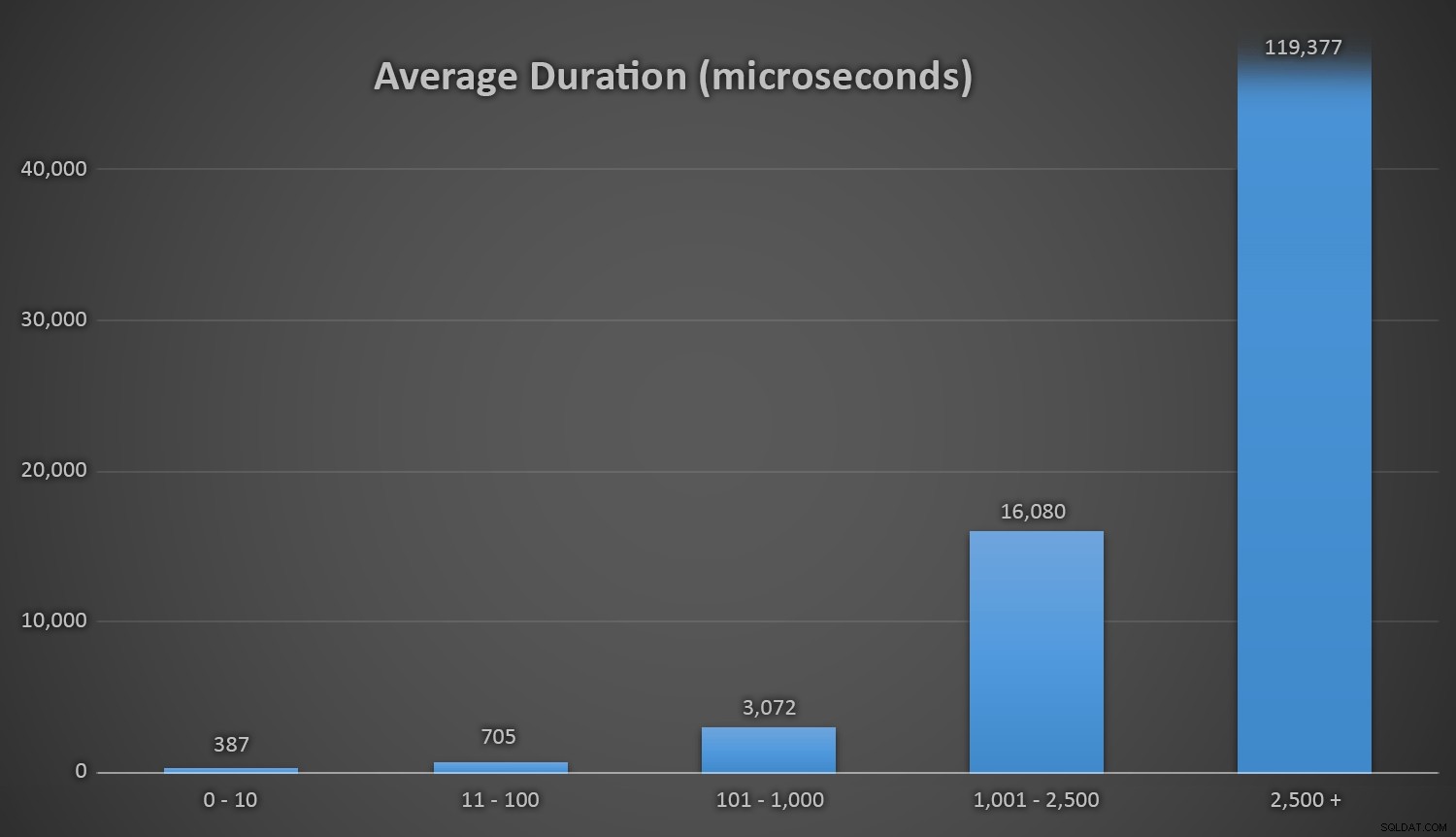
Durée moyenne (en microsecondes) pendant différentes plages de collisions
J'aimerais qu'il y ait un moyen simple de représenter graphiquement la durée par rapport au nombre de collisions. Je vous laisse avec cette friandise :lors des trois dernières insertions, les méthodes d'exécution suivantes ont dû effectuer autant de tentatives avant de finalement tomber sur le dernier identifiant unique qu'elles recherchaient, et voici le temps que cela a pris :
| Nombre de collisions | Durée (microsecondes) | ||
|---|---|---|---|
| CHECKSUM(NEWID()) | 3e à la dernière ligne | 63 545 | 639 358 |
| 2ème à dernière ligne | 164 807 | 1 605 695 | |
| Dernière ligne | 30 630 | 296 207 | |
| CRYPT_GEN_RANDOM() | 3e à la dernière ligne | 219 766 | 2 229 166 |
| 2ème à dernière ligne | 255 463 | 2 681 468 | |
| Dernière ligne | 136 342 | 1 434 725 | |
| RAND() | 3e à la dernière ligne | 129 764 | 1 215 994 |
| 2ème à dernière ligne | 220 195 | 2 088 992 | |
| Dernière ligne | 440 765 | 4 161 925 | |
Durée excessive et collisions près de la fin de la ligne
Il est intéressant de noter que la dernière ligne n'est pas toujours celle qui produit le plus grand nombre de collisions, cela peut donc devenir un vrai problème bien avant que vous ayez utilisé plus de 999 000 valeurs.
Une autre considération
Vous pouvez envisager de configurer une sorte d'alerte ou de notification lorsque la table RandomNumbers commence à descendre en dessous d'un certain nombre de lignes (à ce stade, vous pouvez remplir à nouveau la table avec un nouvel ensemble de 1 000 001 à 2 000 000, par exemple). Vous auriez à faire quelque chose de similaire si vous génériez des nombres aléatoires à la volée - si vous maintenez cela dans une plage de 1 à 1 000 000, vous devrez alors modifier le code pour générer des nombres à partir d'une plage différente une fois que vous ' J'ai utilisé toutes ces valeurs.
Si vous utilisez la méthode du nombre aléatoire à l'exécution, vous pouvez éviter cette situation en modifiant constamment la taille du pool à partir duquel vous tirez un nombre aléatoire (ce qui devrait également se stabiliser et réduire considérablement le nombre de collisions). Par exemple, au lieu de :
DECLARE @CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
Vous pouvez baser le pool sur le nombre de lignes déjà présentes dans le tableau :
DECLARE @total INT = 1000000 + ISNULL(
(SELECT SUM(row_count) FROM sys.dm_db_partition_stats
WHERE [object_id] = OBJECT_ID('dbo.Customers') AND index_id = 1),0);
Maintenant, votre seul véritable souci est lorsque vous approchez de la limite supérieure pour INT …
Remarque :J'ai également écrit récemment une astuce à ce sujet sur MSSQLTips.com.