Le partitionnement est une fonctionnalité de SQL Server souvent implémentée pour atténuer les problèmes liés à la gérabilité, aux tâches de maintenance ou au verrouillage et au blocage. L'administration de grandes tables peut devenir plus facile avec le partitionnement, et cela peut améliorer l'évolutivité et la disponibilité. En outre, un sous-produit du partitionnement peut être l'amélioration des performances des requêtes. Ce n'est pas une garantie ou une donnée, et ce n'est pas la raison principale pour implémenter le partitionnement, mais c'est quelque chose qui mérite d'être examiné lorsque vous partitionnez une grande table.
Contexte
En bref, la fonctionnalité de partitionnement de SQL Server n'est disponible que dans les éditions Enterprise et Developer. Le partitionnement peut être implémenté lors de la conception initiale de la base de données, ou il peut être mis en place après qu'une table contient déjà des données. Comprenez que la modification d'une table existante contenant des données en une table partitionnée n'est pas toujours simple et rapide, mais c'est tout à fait faisable avec une bonne planification et les avantages peuvent être rapidement réalisés.
Une table partitionnée est une table dans laquelle les données sont séparées en structures physiques plus petites en fonction de la valeur d'une colonne spécifique (appelée colonne de partitionnement, qui est définie dans la fonction de partition). Si vous souhaitez séparer les données par année, vous pouvez utiliser une colonne appelée DateSold comme colonne de partitionnement, et toutes les données pour 2013 résideraient dans une structure, toutes les données pour 2012 résideraient dans une structure différente, etc. Ces ensembles de données séparés permettre une maintenance ciblée (vous pouvez reconstruire uniquement une partition d'un index, plutôt que l'intégralité de l'index) et permettre l'ajout et la suppression rapides de données, car elles peuvent être échelonnées avant d'être réellement ajoutées ou supprimées de la table.
La configuration
Pour examiner les différences de performances de requête pour une table partitionnée par rapport à une table non partitionnée, j'ai créé deux copies de la table Sales.SalesOrderHeader à partir de la base de données AdventureWorks2012. La table non partitionnée a été créée avec uniquement un index clusterisé sur SalesOrderID, la clé primaire traditionnelle de la table. La deuxième table a été partitionnée sur OrderDate, avec OrderDate et SalesOrderID comme clé de clustering, et n'avait pas d'index supplémentaires. Notez qu'il existe de nombreux facteurs à prendre en compte lors du choix de la colonne à utiliser pour le partitionnement. Le partitionnement utilise souvent, mais certainement pas toujours, un champ de date pour définir les limites de la partition. En tant que tel, OrderDate a été sélectionné pour cet exemple, et des exemples de requêtes ont été utilisés pour simuler une activité typique par rapport à la table SalesOrderHeader. Les instructions pour créer et remplir les deux tables peuvent être téléchargées ici.
Après avoir créé les tables et ajouté des données, les index existants ont été vérifiés puis les statistiques mises à jour avec FULLSCAN :
EXEC sp_helpindex 'Sales.Big_SalesOrderHeader'; GO EXEC sp_helpindex 'Sales.Part_SalesOrderHeader'; GO UPDATE STATISTICS [Sales].[Big_SalesOrderHeader] WITH FULLSCAN; GO UPDATE STATISTICS [Sales].[Part_SalesOrderHeader] WITH FULLSCAN; GO SELECT sch.name + '.' + so.name AS [Table], ss.name AS [Statistic], sp.last_updated AS [Stats Last Updated], sp.rows AS [Rows], sp.rows_sampled AS [Rows Sampled], sp.modification_counter AS [Row Modifications] FROM sys.stats AS ss INNER JOIN sys.objects AS so ON ss.[object_id] = so.[object_id] INNER JOIN sys.schemas AS sch ON so.[schema_id] = sch.[schema_id] OUTER APPLY sys.dm_db_stats_properties(so.[object_id], ss.stats_id) AS sp WHERE so.[object_id] IN (OBJECT_ID(N'Sales.Big_SalesOrderHeader'), OBJECT_ID(N'Sales.Part_SalesOrderHeader')) AND ss.stats_id = 1;
De plus, les deux tables ont exactement la même distribution de données et une fragmentation minimale.
Performances pour une requête simple
Avant d'ajouter des index supplémentaires, une requête de base a été exécutée sur les deux tables pour calculer les totaux gagnés par le vendeur pour les commandes passées en décembre 2012 :
SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Big_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GO SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GOSORTIE E/S STATISTIQUES
Tableau 'Table de travail'. Nombre de balayages 0, lectures logiques 0, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Table 'Big_SalesOrderHeader'. Nombre de balayages 9, lectures logiques 2710440, lectures physiques 2226, lectures anticipées 2658769, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Tableau 'Table de travail'. Nombre de balayages 0, lectures logiques 0, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Table 'Part_SalesOrderHeader'. Nombre de balayages 9, lectures logiques 248128, lectures physiques 3, lectures anticipées 245030, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.

Totaux par vendeur pour décembre – Tableau non partitionné
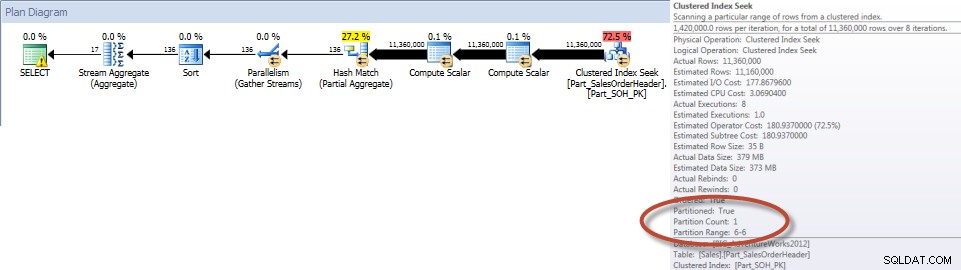
Totaux par vendeur pour décembre – Tableau partitionné
Comme prévu, la requête sur la table non partitionnée a dû effectuer une analyse complète de la table car il n'y avait pas d'index pour la prendre en charge. En revanche, la requête sur la table partitionnée n'avait besoin d'accéder qu'à une partition de la table.
Pour être juste, s'il s'agissait d'une requête exécutée à plusieurs reprises avec différentes plages de dates, l'index non clusterisé approprié existerait. Par exemple :
CREATE NONCLUSTERED INDEX [Big_SalesOrderHeader_SalesPersonID] ON [Sales].[Big_SalesOrderHeader] ([OrderDate]) INCLUDE ([SalesPersonID], [TotalDue]);
Avec cet index créé, lorsque la requête est réexécutée, les statistiques d'E/S chutent et le plan change pour utiliser l'index non cluster :
SORTIE E/S STATISTIQUES
Tableau 'Table de travail'. Nombre de balayages 0, lectures logiques 0, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Table 'Big_SalesOrderHeader'. Nombre de balayages 9, lectures logiques 42901, lectures physiques 3, lectures anticipées 42346, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.

Totaux par vendeur pour décembre – NCI sur table non partitionnée
Avec un index de prise en charge, la requête sur Sales.Big_SalesOrderHeader nécessite beaucoup moins de lectures que l'analyse de l'index clusterisé sur Sales.Part_SalesOrderHeader, ce qui n'est pas inattendu puisque l'index clusterisé est beaucoup plus large. Si nous créons un index non clusterisé comparable pour Sales.Part_SalesOrderHeader, nous voyons des numéros d'E/S similaires :
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_SalesPersonID] ON [Sales].[Part_SalesOrderHeader]([SalesPersonID]) INCLUDE ([TotalDue]);SORTIE E/S STATISTIQUES
Tableau 'Part_SalesOrderHeader'. Nombre de balayages 9, lectures logiques 42894, lectures physiques 1, lectures anticipées 42378, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
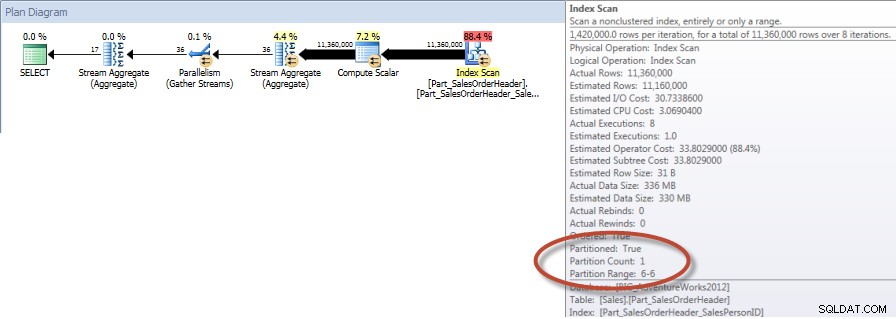
Totaux par vendeur pour décembre – NCI sur table partitionnée avec élimination
Et si nous examinons les propriétés de l'analyse d'index non clusterisée, nous pouvons vérifier que le moteur n'a accédé qu'à une seule partition (6).
Comme indiqué à l'origine, le partitionnement n'est généralement pas mis en œuvre pour améliorer les performances. Dans l'exemple ci-dessus, la requête sur la table partitionnée ne fonctionne pas beaucoup mieux tant que l'index non clusterisé approprié existe.
Performances pour une requête ad hoc
Une requête sur la table partitionnée peut surpassent la même requête sur la table non partitionnée dans certains cas, par exemple lorsque la requête doit utiliser l'index clusterisé. Bien qu'il soit idéal que la majorité des requêtes soient prises en charge par des index non clusterisés, certains systèmes autorisent les requêtes ad hoc des utilisateurs, et d'autres ont des requêtes qui peuvent s'exécuter si rarement qu'elles ne justifient pas la prise en charge des index. Dans la table SalesOrderHeader, un utilisateur peut exécuter la requête suivante pour rechercher les commandes de décembre 2012 qui devaient être expédiées d'ici la fin de l'année, mais qui ne l'ont pas été, pour un ensemble particulier de clients et avec un TotalDue supérieur à 1 000 USD :
SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Big_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GO SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Part_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GOSORTIE E/S STATISTIQUES
Tableau 'Big_SalesOrderHeader'. Nombre de balayages 9, lectures logiques 2711220, lectures physiques 8386, lectures anticipées 2662400, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Table 'Part_SalesOrderHeader'. Nombre de balayages 9, lectures logiques 248128, lectures physiques 0, lectures anticipées 243792, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
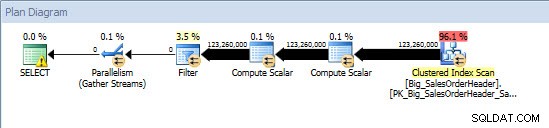
Requête ad hoc – Table non partitionnée
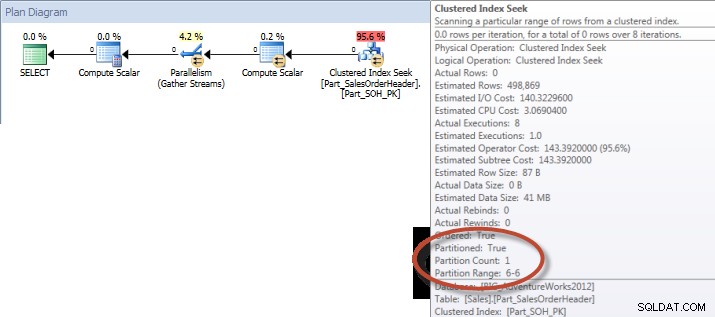
Requête ad hoc – Table partitionnée
Sur la table non partitionnée, la requête nécessitait une analyse complète de l'index clusterisé, mais sur la table partitionnée, la requête effectuait une recherche d'index de l'index clusterisé, car le moteur utilisait l'élimination de partition et ne lisait que les données dont il avait absolument besoin. Dans cet exemple, il s'agit d'une différence significative en termes d'E/S, et selon le matériel, cela pourrait être une différence considérable dans le temps d'exécution. La requête peut être optimisée en ajoutant l'index approprié, mais il n'est généralement pas possible d'indexer pour chaque célibataire requête. En particulier, pour les solutions qui permettent des requêtes ad hoc, il est juste de dire que vous ne savez jamais ce que les utilisateurs vont faire. Une requête peut s'exécuter une fois et ne plus jamais s'exécuter, et créer un index après coup est futile. Par conséquent, lors du passage d'une table non partitionnée à une table partitionnée, il est important d'appliquer le même effort et la même approche que le réglage d'index régulier ; vous souhaitez vérifier que les index appropriés existent pour prendre en charge la majorité des requêtes.
Performances et alignement des index
Un facteur supplémentaire à prendre en compte lors de la création d'index pour une table partitionnée est de savoir s'il faut aligner l'index ou non. Les index doivent être alignés avec la table si vous prévoyez de basculer des données dans et hors des partitions. La création d'un index non clusterisé sur une table partitionnée crée un index aligné par défaut, où la colonne de partitionnement est ajoutée en tant que colonne incluse à l'index.
Un index non aligné est créé en spécifiant un schéma de partition différent ou un groupe de fichiers différent. La colonne de partitionnement peut faire partie de l'index en tant que colonne clé ou colonne incluse, mais si le schéma de partition de la table n'est pas utilisé, ou si un groupe de fichiers différent est utilisé, l'index ne sera pas aligné.
Un index aligné est partitionné comme la table - les données existeront dans des structures séparées - et donc l'élimination de la partition peut se produire. Un index non aligné existe en tant que structure physique unique et peut ne pas fournir l'avantage attendu pour une requête, selon le prédicat. Considérons une requête qui compte les ventes par numéro de compte, regroupées par mois :
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);
Si vous n'êtes pas familier avec le partitionnement, vous pouvez créer un index comme celui-ci pour prendre en charge la requête (notez que le groupe de fichiers PRIMARY est spécifié) :
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_NotAL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]) ON [PRIMARY];
Cet index n'est pas aligné, même s'il inclut OrderDate car il fait partie de la clé primaire. Les colonnes sont également incluses si nous créons un index aligné, mais notez la différence de syntaxe :
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_AL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]);
Nous pouvons vérifier quelles colonnes existent dans l'index en utilisant le sp_helpindex de Kimberly Tripp :
EXEC sp_SQLskills_SQL2008_helpindex 'Sales.Part_SalesOrderHeader’;

sp_helpindex pour Sales.Part_SalesOrderHeader
Lorsque nous exécutons notre requête et que nous la forçons à utiliser l'index non aligné, l'intégralité de l'index est analysée. Même si OrderDate fait partie de l'index, ce n'est pas la colonne principale. Le moteur doit donc vérifier la valeur OrderDate pour chaque AccountNumber pour voir si elle se situe entre le 1er janvier 2013 et le 31 juillet 2013 :
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_NotAL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);SORTIE E/S STATISTIQUES
Tableau 'Table de travail'. Nombre de balayages 0, lectures logiques 0, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Table 'Part_SalesOrderHeader'. Nombre de balayages 9, lectures logiques 786861, lectures physiques 1, lectures anticipées 770929, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
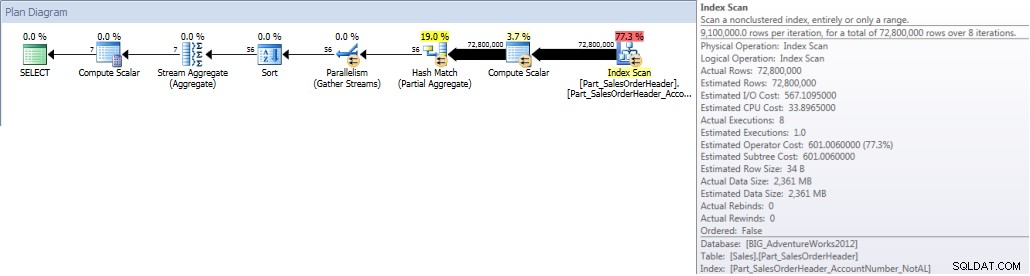
Totaux des comptes par mois (janvier – juillet 2013) à l'aide de non- NCI aligné (forcé)
En revanche, lorsque la requête est forcée d'utiliser l'index aligné, l'élimination de partition peut être utilisée et moins d'E/S sont nécessaires, même si OrderDate n'est pas une colonne de tête dans l'index.
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_AL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);SORTIE E/S STATISTIQUES
Tableau 'Table de travail'. Nombre de balayages 0, lectures logiques 0, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Table 'Part_SalesOrderHeader'. Nombre de balayages 9, lectures logiques 456258, lectures physiques 16, lectures anticipées 453241, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
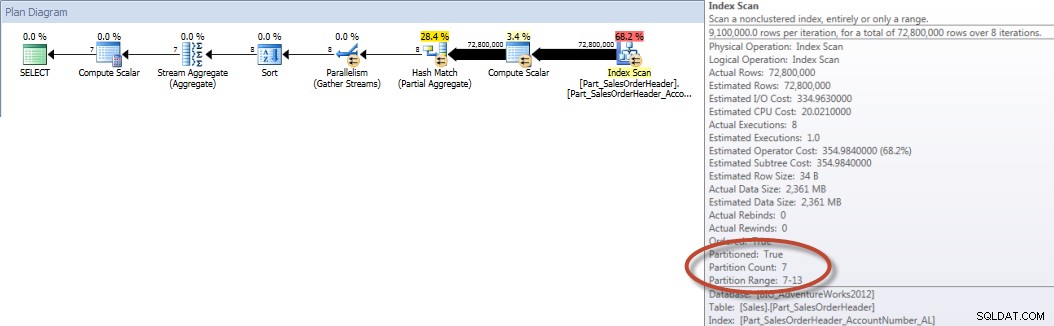
Totaux des comptes par mois (janvier – juillet 2013) à l'aide du NCI aligné (forcé)
Résumé
La décision de mettre en œuvre le partitionnement est une décision qui nécessite une réflexion et une planification appropriées. La facilité de gestion, l'évolutivité et la disponibilité améliorées et la réduction des blocages sont des raisons courantes de partitionner les tables. L'amélioration des performances des requêtes n'est pas une raison d'utiliser le partitionnement, même si cela peut être un effet secondaire bénéfique dans certains cas. En termes de performances, il est important de s'assurer que votre plan de mise en œuvre inclut un examen des performances des requêtes. Confirmez que vos index continuent de prendre en charge de manière appropriée vos requêtes après la table est partitionnée et vérifiez que les requêtes utilisant les index clusterisés et non clusterisés bénéficient de l'élimination des partitions, le cas échéant.