Si vous utilisez le partitionnement de table avec une ou plusieurs partitions stockées sur un groupe de fichiers en lecture seule, les instructions SQL de mise à jour et de suppression peuvent échouer avec une erreur. Bien sûr, c'est le comportement attendu si l'une des modifications nécessite l'écriture dans un groupe de fichiers en lecture seule; cependant, il est également possible de rencontrer cette condition d'erreur où les modifications sont limitées aux groupes de fichiers marqués en lecture-écriture.
Exemple de base de données
Pour illustrer le problème, nous allons créer une base de données simple avec un seul groupe de fichiers personnalisé que nous marquerons plus tard comme étant en lecture seule. Notez que vous devrez ajouter le chemin du nom de fichier en fonction de votre instance de test.
USE master;
GO
CREATE DATABASE Test;
GO
-- This filegroup will be marked read-only later
ALTER DATABASE Test
ADD FILEGROUP ReadOnlyFileGroup;
GO
-- Add a file to the new filegroup
ALTER DATABASE Test
ADD FILE
(
NAME = 'Test_RO',
FILENAME = '<...your path...>\MSSQL\DATA\Test_ReadOnly.ndf'
)
TO FILEGROUP ReadOnlyFileGroup; Fonction et schéma de partition
Nous allons maintenant créer une fonction et un schéma de partitionnement de base qui dirigeront les lignes avec des données avant le 1er janvier 2000 à la partition en lecture seule. Les données ultérieures seront conservées dans le groupe de fichiers principal en lecture-écriture :
USE Test;
GO
CREATE PARTITION FUNCTION PF (datetime)
AS RANGE RIGHT
FOR VALUES ({D '2000-01-01'});
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
TO (ReadOnlyFileGroup, [PRIMARY]); La spécification de plage droite signifie que les lignes avec la valeur limite 1er janvier 2000 seront dans la partition en lecture-écriture.
Table et index partitionnés
Nous pouvons maintenant créer notre table de test :
CREATE TABLE dbo.Test
(
dt datetime NOT NULL,
c1 integer NOT NULL,
c2 integer NOT NULL,
CONSTRAINT PK_dbo_Test__c1_dt
PRIMARY KEY CLUSTERED (dt)
ON PS (dt)
)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c1
ON dbo.Test (c1)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c2
ON dbo.Test (c2)
ON PS (dt); La table a une clé primaire en cluster sur la colonne datetime et est également partitionnée sur cette colonne. Il existe des index non clusterisés sur les deux autres colonnes d'entiers, qui sont partitionnés de la même manière (les index sont alignés sur la table de base).
Exemples de données
Enfin, nous ajoutons quelques lignes d'exemples de données et rendons la partition de données antérieure à 2000 en lecture seule :
INSERT dbo.Test WITH (TABLOCKX)
(dt, c1, c2)
VALUES
({D '1999-12-31'}, 1, 1), -- Read only
({D '2000-01-01'}, 2, 2); -- Writable
GO
ALTER DATABASE Test
MODIFY FILEGROUP
ReadOnlyFileGroup READ_ONLY;
Vous pouvez utiliser les instructions de mise à jour de test suivantes pour confirmer que les données de la partition en lecture seule ne peuvent pas être modifiées, tandis que les données avec un dt la valeur au 1er janvier 2000 ou après cette date peut être écrite dans :
-- Will fail, as expected
UPDATE dbo.Test
SET c2 = 1
WHERE dt = {D '1999-12-31'};
-- Will succeed, as expected
UPDATE dbo.Test
SET c2 = 999
WHERE dt = {D '2000-01-01'};
-- Reset the value of c2
UPDATE dbo.Test
SET c2 = 2
WHERE dt = {D '2000-01-01'}; Un échec inattendu
Nous avons deux lignes :une en lecture seule (1999-12-31); et une lecture-écriture (2000-01-01) :

Essayez maintenant la requête suivante. Il identifie la même ligne inscriptible "2000-01-01" que nous venons de mettre à jour avec succès, mais utilise un prédicat de clause where différent :
UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;
Le plan estimé (pré-exécution) est :

Les quatre (!) Compute Scalars ne sont pas importants pour cette discussion. Ils sont utilisés pour déterminer si l'index non clusterisé doit être maintenu pour chaque ligne qui arrive à l'opérateur de mise à jour de l'index clusterisé.
La chose la plus intéressante est que cette instruction de mise à jour échoue avec une erreur semblable à :
Msg 652, Niveau 16, État 1L'index "PK_dbo_Test__c1_dt" pour la table "dbo.Test" (RowsetId 72057594039042048) réside sur un groupe de fichiers en lecture seule ("ReadOnlyFileGroup"), qui ne peut pas être modifié.
Pas d'élimination de partition
Si vous avez déjà travaillé avec le partitionnement, vous pensez peut-être que "l'élimination des partitions" pourrait en être la cause. La logique ressemblerait à ceci :
Dans les instructions précédentes, une valeur littérale pour la colonne de partitionnement était fournie dans la clause where, afin que SQL Server puisse déterminer immédiatement à quelle(s) partition(s) accéder. En modifiant la clause where pour qu'elle ne fasse plus référence à la colonne de partitionnement, nous avons forcé SQL Server à accéder à chaque partition à l'aide d'un balayage d'index clusterisé.
Tout cela est vrai, en général, mais ce n'est pas la raison pour laquelle l'instruction de mise à jour échoue ici.
Le comportement attendu est que SQL Server doit pouvoir lire de toutes les partitions lors de l'exécution de la requête. Une opération de modification de données ne devrait que échouer si le moteur d'exécution essaie réellement de modifier une ligne stockée sur un groupe de fichiers en lecture seule.
Pour illustrer cela, apportons une petite modification à la requête précédente :
UPDATE dbo.Test
SET c2 = 2,
dt = dt
WHERE c1 = 2; La clause where est exactement la même qu'avant. La seule différence est que nous définissons maintenant (délibérément) la colonne de partitionnement égale à elle-même. Cela ne changera pas la valeur stockée dans cette colonne, mais cela affectera le résultat. La mise à jour réussit maintenant (mais avec un plan d'exécution plus complexe) :

L'optimiseur a introduit de nouveaux opérateurs Fractionner, Trier et Réduire, et a ajouté la machinerie nécessaire pour gérer séparément chaque index non cluster potentiellement affecté (en utilisant une stratégie large ou par index).
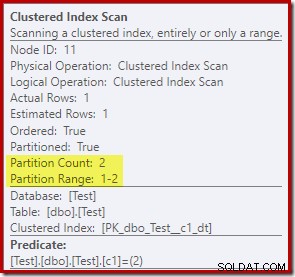
Les propriétés Clustered Index Scan indiquent que les deux partitions du tableau ont été accédés lors de la lecture :
En revanche, la mise à jour de l'index clusterisé montre que seule la partition en lecture-écriture a été accessible en écriture :
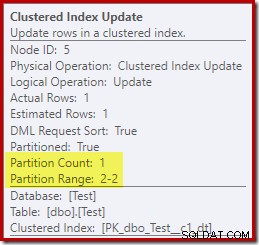
Chacun des opérateurs de mise à jour d'index non cluster affiche des informations similaires :seule la partition accessible en écriture (#2) a été modifiée au moment de l'exécution, donc aucune erreur ne s'est produite.
La raison révélée
Le nouveau plan ne réussit pas parce que les index non clusterisés sont gérés séparément ; ni est-ce (directement) dû à la combinaison Split-Sort-Collapse nécessaire pour éviter les erreurs transitoires de clé en double dans l'index unique.
La vraie raison est quelque chose que j'ai mentionné brièvement dans mon article précédent, "Optimisation des requêtes de mise à jour" - une optimisation interne connue sous le nom de Partage d'ensemble de lignes . Lorsque cela est utilisé, la mise à jour de l'index clusterisé partage le même ensemble de lignes du moteur de stockage sous-jacent qu'un balayage, une recherche ou une recherche de clé de l'index clusterisé du côté lecture du plan.
Avec l'optimisation du partage d'ensemble de lignes, SQL Server vérifie les groupes de fichiers hors ligne ou en lecture seule lors de la lecture. Dans les plans où la mise à jour de l'index clusterisé utilise un ensemble de lignes distinct, la vérification hors ligne/en lecture seule n'est effectuée que pour chaque ligne au niveau de l'itérateur de mise à jour (ou de suppression).
Solutions non documentées
Éliminons d'abord les choses amusantes, geek, mais peu pratiques.
L'optimisation de l'ensemble de lignes partagé ne peut être appliquée que lorsque la route à partir de la recherche, de l'analyse ou de la recherche de clé d'index clusterisé est un pipeline . Aucun opérateur bloquant ou semi-bloquant n'est autorisé. Autrement dit, chaque ligne doit pouvoir passer de la source de lecture à la destination d'écriture avant que la ligne suivante ne soit lue.
Pour rappel, voici les exemples de données, de déclaration et de plan d'exécution pour l'échec mettre à jour à nouveau :
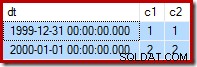
--Change the read-write row UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;

Protection d'Halloween
Une façon d'introduire un opérateur de blocage dans le plan consiste à exiger une protection Halloween (HP) explicite pour cette mise à jour. Séparer la lecture de l'écriture avec un opérateur bloquant empêchera l'utilisation de l'optimisation du partage de lignes (pas de pipeline). L'indicateur de trace 8692 non documenté et non pris en charge (système de test uniquement !) ajoute un spool de table Eager pour HP explicite :
-- Works (explicit HP) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8692);
Le plan d'exécution réel (disponible car l'erreur n'est plus renvoyée) est :

La combinaison Trier dans la combinaison Fractionner-Trier-Réduire vue dans la mise à jour réussie précédente fournit le blocage nécessaire pour désactiver le partage d'ensemble de lignes dans cette instance.
L'indicateur de trace anti-partage d'ensembles de lignes
Il existe un autre indicateur de trace non documenté qui désactive l'optimisation du partage de l'ensemble de lignes. Cela a l'avantage de ne pas introduire d'opérateur de blocage potentiellement coûteux. Il ne peut pas être utilisé dans la pratique bien sûr (sauf si vous contactez le support Microsoft et obtenez quelque chose par écrit vous recommandant de l'activer, je suppose). Néanmoins, à des fins de divertissement, voici l'indicateur de trace 8746 en action :
-- Works (no rowset sharing) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8746);
Le plan d'exécution réel pour cette instruction est :

N'hésitez pas à expérimenter différentes valeurs (celles qui changent réellement les valeurs stockées si vous le souhaitez) pour vous convaincre de la différence ici. Comme mentionné dans mon article précédent, vous pouvez également utiliser l'indicateur de trace non documenté 8666 pour exposer la propriété de partage d'ensemble de lignes dans le plan d'exécution.
Si vous souhaitez voir l'erreur de partage de l'ensemble de lignes avec une instruction de suppression, remplacez simplement les clauses update et set par une suppression, tout en utilisant la même clause where.
Solutions prises en charge
Il existe un certain nombre de façons potentielles de s'assurer que le partage d'ensembles de lignes n'est pas appliqué dans les requêtes du monde réel sans utiliser d'indicateurs de trace. Maintenant que vous savez que le problème principal nécessite un plan de lecture et d'écriture d'index cluster partagé et en pipeline, vous pouvez probablement créer le vôtre. Néanmoins, il existe quelques exemples qui valent particulièrement la peine d'être examinés ici.
Index forcé / Index de recouvrement
Une idée naturelle consiste à forcer le côté lecture du plan à utiliser un index non clusterisé au lieu de l'index clusterisé. Nous ne pouvons pas ajouter un indice d'index directement à la requête de test telle qu'elle est écrite, mais l'aliasing de la table permet ceci :
UPDATE T SET c2 = 2 FROM dbo.Test AS T WITH (INDEX(IX_dbo_Test_c1)) WHERE c1 = 2;
Cela peut sembler être la solution que l'optimiseur de requête aurait dû choisir en premier lieu, puisque nous avons un index non clusterisé sur la colonne de prédicat de la clause where c1. Le plan d'exécution montre pourquoi l'optimiseur a choisi ce qu'il a fait :
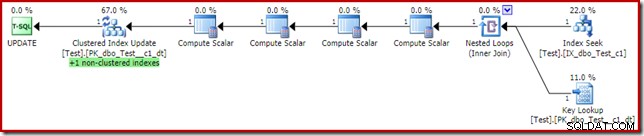
Le coût de la recherche de clé est suffisant pour convaincre l'optimiseur d'utiliser l'index clusterisé pour la lecture. La recherche est nécessaire pour récupérer la valeur actuelle de la colonne c2, afin que les scalaires de calcul puissent décider si l'index non clusterisé doit être maintenu.
L'ajout de la colonne c2 à l'index non clusterisé (clé ou inclusion) éviterait le problème. L'optimiseur choisirait l'index maintenant couvrant au lieu de l'index clusterisé.
Cela dit, il n'est pas toujours possible d'anticiper quelles colonnes seront nécessaires, ou de toutes les inclure même si l'ensemble est connu. N'oubliez pas que la colonne est nécessaire car c2 est dans la clause set de la déclaration de mise à jour. Si les requêtes sont ad hoc (par exemple, soumises par des utilisateurs ou générées par un outil), chaque index non clusterisé devra inclure toutes les colonnes pour en faire une option robuste.
Une chose intéressante à propos du plan avec la recherche de clé ci-dessus est qu'il ne le fait pas générer une erreur. Ceci malgré la recherche de clé et la mise à jour de l'index clusterisé à l'aide d'un ensemble de lignes partagé. La raison en est que l'Index Seek non clusterisé localise la ligne avec c1 =2 avant la recherche de clé touche l'index clusterisé. La vérification de l'ensemble de lignes partagé pour les groupes de fichiers hors ligne/en lecture seule est toujours effectuée lors de la recherche, mais elle ne touche pas la partition en lecture seule, donc aucune erreur n'est générée. Comme point d'intérêt final (connexe), notez que la recherche d'index touche les deux partitions, mais que la recherche de clé n'en touche qu'une.
Exclure la partition en lecture seule
Une solution triviale consiste à s'appuyer sur l'élimination des partitions afin que le côté lecture du plan ne touche jamais la partition en lecture seule. Cela peut être fait avec un prédicat explicite, par exemple l'un de ceux-ci :
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND dt >= {D '2000-01-01'};
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND $PARTITION.PF(dt) > 1; -- Not partition #1 Lorsqu'il est impossible ou peu pratique de modifier chaque requête pour ajouter un prédicat d'élimination de partition, d'autres solutions telles que la mise à jour via une vue peuvent convenir. Par exemple :
CREATE VIEW dbo.TestWritablePartitions
WITH SCHEMABINDING
AS
-- Only the writable portion of the table
SELECT
T.dt,
T.c1,
T.c2
FROM dbo.Test AS T
WHERE
$PARTITION.PF(dt) > 1;
GO
-- Succeeds
UPDATE dbo.TestWritablePartitions
SET c2 = 2
WHERE c1 = 2; L'un des inconvénients de l'utilisation d'une vue est qu'une mise à jour ou une suppression qui cible la partie en lecture seule de la table de base réussira sans qu'aucune ligne ne soit affectée, au lieu d'échouer avec une erreur. Un déclencheur au lieu de sur la table ou la vue peut être une solution de contournement pour cela dans certaines situations, mais peut également introduire plus de problèmes… mais je m'éloigne du sujet.
Comme mentionné précédemment, il existe de nombreuses solutions potentielles prises en charge. Le but de cet article est de montrer comment le partage d'ensemble de lignes a causé l'erreur de mise à jour inattendue.



