Lorsque j'étais à Chicago il y a quelques semaines pour l'un de nos événements d'immersion, un participant avait une question de statistiques. Je n'entrerai pas dans tous les détails autour du problème, mais le participant a mentionné que les statistiques ont été mises à jour à l'aide de sp_updatestats . C'est une méthode de mise à jour des statistiques que je n'ai jamais recommandée; J'ai toujours recommandé une combinaison de reconstructions d'index et de UPDATE STATISTICS pour tenir les statistiques à jour. Si vous n'êtes pas familier avec sp_updatestats , il s'agit d'une commande exécutée pour l'ensemble de la base de données afin de mettre à jour les statistiques. Mais comme Kimberly l'a fait remarquer au participant, sp_updatestats mettra à jour une statistique tant qu'une ligne aura été modifiée. Waouh. J'ai immédiatement ouvert Books Online, et pour sp_updatestats vous verrez ceci :
Maintenant, j'avoue, j'ai fait une hypothèse sur ce que signifiait "… exiger une mise à jour basée sur les informations rowmodctr dans la vue du catalogue sys.sysindexes…". J'ai supposé que la décision de mise à jour suivrait la même logique que l'option de mise à jour automatique des statistiques, à savoir :
- La taille du tableau est passée de 0 à>0 lignes (test 1).
- Le nombre de lignes dans le tableau au moment de la collecte des statistiques était de 500 ou moins, et le colmodctr de la colonne principale de l'objet de statistiques a changé de plus de 500 depuis lors (test 2).
- Le tableau comportait plus de 500 lignes au moment de la collecte des statistiques, et le colmodctr de la colonne principale de l'objet de statistiques a changé de plus de 500 + 20 % du nombre de lignes du tableau au moment de la collecte des statistiques ( essai 3).
Cette logique n'est pas suivie pour sp_updatestats . En fait, la logique est si incroyablement simple que c'en est effrayant :si une ligne est modifiée, la statistique est mise à jour. Une rangée. UNE RANGÉE. Quelle est ma préoccupation ? Je m'inquiète de la surcharge de mise à jour des statistiques pour un tas de statistiques qui n'ont pas vraiment besoin d'être mises à jour. Examinons de plus près sp_updatestats .
Nous allons commencer avec une nouvelle copie de la base de données AdventureWorks2012 que vous pouvez télécharger à partir de Codeplex. Je vais d'abord mettre à jour les lignes dans trois tables différentes :
USE [AdventureWorks2012];
GO
SET NOCOUNT ON;
GO
UPDATE [Production].[Product]
SET [Name] = 'Bike Chain'
WHERE [ProductID] = 952;
UPDATE [Person].[Person]
SET [LastName] = 'Cameron'
WHERE [LastName] = 'Diaz';
GO
INSERT INTO Sales.SalesReason
(Name, ReasonType, ModifiedDate)
VALUES('Stats', 'Test', GETDATE());
GO 10000
Nous avons modifié une ligne dans Production.Product , 211 lignes dans Person.Person , et nous avons ajouté 10 000 lignes à Sales.SalesReason . Si le sp_updatestats procédure suivait la même logique pour les mises à jour que l'option de mise à jour automatique des statistiques, puis uniquement Sales.SalesReason mettrait à jour car il avait 10 lignes pour commencer (alors que les 211 lignes mises à jour dans Person.Person représentent environ un pour cent du tableau). Cependant, si nous creusons dans sp_updatestats , on voit que la logique utilisée est différente. Notez que j'extrait uniquement les déclarations de sp_updatestats qui sont utilisés pour déterminer quelles statistiques sont mises à jour.
Un curseur parcourt toutes les tables définies par l'utilisateur et les tables internes de la base de données :
declare ms_crs_tnames cursor local fast_forward read_only for select name, object_id, schema_id, type from sys.objects o where o.type = 'U' or o.type = 'IT' open ms_crs_tnames fetch next from ms_crs_tnames into @table_name, @table_id, @sch_id, @table_type
Un autre curseur parcourt les statistiques de chaque table et exclut les tas et les index et statistiques hypothétiques. Notez que sys.sysindexes est utilisé dans sp_helpstats . Sysindexes est une table système SQL Server 2000 et doit être supprimée dans une future version de SQL Server. Ceci est intéressant, car l'autre méthode pour déterminer les lignes mises à jour est le sys.dm_db_stats_properties DMF, disponible uniquement dans SQL 2008 R2 SP2 et SQL 2012 SP1.
set @index_names = cursor local fast_forward read_only for select name, indid, rowmodctr from sys.sysindexes where id = @table_id and indid > 0 and indexproperty(id, name, 'ishypothetical') = 0 order by indid
Après un peu de préparation et de logique supplémentaire, nous arrivons à un IF déclaration qui révèle que sp_updatestats filtre les statistiques qui n'ont pas eu de lignes mises à jour… confirmant que même si une seule ligne a été modifiée, la statistique sera mise à jour. Il y a aussi une vérification pour @is_ver_current , qui est déterminé par une fonction interne intégrée.
if ((@ind_rowmodctr <> 0) or ((@is_ver_current is not null) and (@is_ver_current = 0)))
Quelques vérifications supplémentaires liées à l'échantillonnage et au niveau de compatibilité, puis la UPDATE instruction s'exécute pour la statistique. Avant d'exécuter réellement sp_updatestats, nous pouvons interroger sys.sysindexes pour voir quelles statistiques seront mises à jour :
SELECT [o].[name], [si].[indid], [si].[name], [si].[rowmodctr], [si].[rowcnt], [o].[type] FROM [sys].[objects] [o] JOIN [sys].[sysindexes] [si] ON [o].[object_id] = [si].[id] WHERE ([o].[type] = 'U' OR [o].[type] = 'IT') AND [si].[indid] > 0 AND [si].[rowmodctr] <> 0 ORDER BY [o].[type] DESC, [o].[name];
En plus des trois tables que nous avons modifiées, il existe une autre statistique pour une table utilisateur (dbo.DatabaseLog ) et trois statistiques internes qui seront mises à jour :
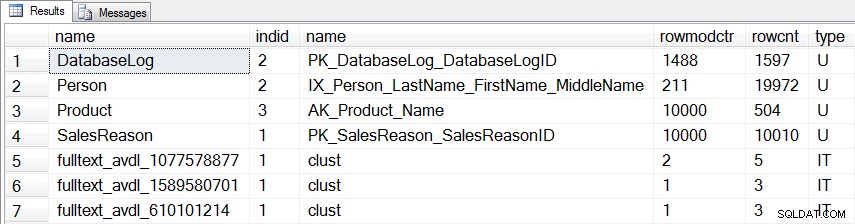
Statistiques qui seront mises à jour
Si nous exécutons sp_updatestats pour la base de données AdventureWorks, la sortie répertorie chaque table et les statistiques mises à jour. La sortie ci-dessous est modifiée pour afficher uniquement les statistiques mises à jour :
La mise à jour de [sys].[fulltext_avdl_1589580701]
[clust] a été mise à jour…
1 index(s)/statistique(s) ont été mis à jour, 0 n'a pas nécessité de mise à jour.
…
La mise à jour de [dbo].[DatabaseLog]
[PK_DatabaseLog_DatabaseLogID] a été mise à jour…
1 index(s)/statistique(s) ont été mis à jour, 0 n'a pas nécessité de mise à jour.
…
La mise à jour de [sys].[fulltext_avdl_1077578877]
[clust] a été mise à jour…
1 index(s)/statistique(s) ont été mis à jour, 0 n'a pas nécessité de mise à jour.
…
Mise à jour de [Person].[Person]
[PK_Person_BusinessEntityID], la mise à jour n'est pas nécessaire…
[IX_Person_LastName_FirstName_MiddleName] a été mis à jour…
[AK_Person_rowguid], la mise à jour n'est pas nécessaire…
1 index(s)/statistique(s) ont été mis à jour, 2 n'ont pas nécessité de mise à jour.
…
La mise à jour de [Sales].[SalesReason]
[PK_SalesReason_SalesReasonID] a été mise à jour…
1 index(s)/statistique(s) ont été mis à jour, 0 n'a pas nécessité de mise à jour.
…
Mise à jour de [Production].[Product]
[PK_Product_ProductID], la mise à jour n'est pas nécessaire…
[AK_Product_ProductNumber], la mise à jour n'est pas nécessaire…
[AK_Product_Name] a été mis à jour…
[ AK_Product_rowguid], la mise à jour n'est pas nécessaire…
[_WA_Sys_00000013_75A278F5], la mise à jour n'est pas nécessaire…
[_WA_Sys_00000014_75A278F5], la mise à jour n'est pas nécessaire…
[_WA_Sys_0000000D_75A278F5], la mise à jour n'est pas nécessaire…
[_WA_Sys_0000000C_75A278F5], la mise à jour n'est pas nécessaire…
1 index(s)/statistique(s) ont été mis à jour, 7 n'ont pas nécessité de mise à jour.
…
Les statistiques de toutes les tables ont été mises à jour.
La dernière ligne de la sortie est un peu trompeuse - les statistiques de toutes les tables n'ont pas été mises à jour, seules les statistiques qui ont eu une ou plusieurs lignes modifiées ont été mises à jour. Et encore une fois, l'inconvénient de cela est que des ressources ont peut-être été utilisées alors qu'elles n'avaient pas besoin de l'être. Si une statistique n'a qu'une seule ligne modifiée, doit-elle être mise à jour ? Non. Si 10 000 lignes ont été mises à jour, doivent-elles être mises à jour ? Eh bien, cela dépend. Si la table ne contient que 5 000 lignes, alors absolument ; si le tableau comporte 1 million de lignes, alors non, car seulement 1 % du tableau a été modifié.
Le point à retenir ici est que si vous utilisez sp_updatestats pour mettre à jour vos statistiques, vous gaspillez très probablement des ressources, y compris le processeur, les E/S et tempdb. De plus, la mise à jour de chaque statistique prend du temps, et si vous avez une fenêtre de maintenance serrée, vous avez probablement d'autres tâches de maintenance qui peuvent s'exécuter pendant cette période, au lieu de mises à jour inutiles. Enfin, vous n'apportez probablement aucun avantage en termes de performances en mettant à jour les statistiques lorsque si peu de lignes ont été modifiées. Le changement de distribution est probablement insignifiant si seul un petit pourcentage de lignes a été modifié, de sorte que les valeurs d'histogramme et de densité ne changent pas beaucoup. De plus, n'oubliez pas que la mise à jour des statistiques invalide les plans de requête qui utilisent ces statistiques. Lorsque ces requêtes s'exécutent, les plans sont régénérés et le plan sera probablement exactement le même qu'avant, car il n'y a pas eu de changement significatif dans l'histogramme. La recompilation des plans de requête a un coût. Ce n'est pas toujours facile à mesurer, mais il ne faut pas l'ignorer.
Une meilleure méthode pour gérer les statistiques, car vous avez besoin de gérer les statistiques, consiste à implémenter une tâche planifiée qui se met à jour en fonction des pourcentages de lignes qui ont été modifiées. Vous pouvez utiliser la requête susmentionnée qui interroge sys.sysindexes , ou vous pouvez utiliser la requête ci-dessous qui tire parti du nouveau DMF ajouté dans SQL Server 2008 R2 SP2 et SQL Server 2012 SP1 :
SELECT [sch].[name] + '.' + [so].[name] AS [TableName] , [ss].[name] AS [Statistic], [sp].[last_updated] AS [StatsLastUpdated] , [sp].[rows] AS [RowsInTable] , [sp].[rows_sampled] AS [RowsSampled] , [sp].[modification_counter] AS [RowModifications] FROM [sys].[stats] [ss] JOIN [sys].[objects] [so] ON [ss].[object_id] = [so].[object_id] JOIN [sys].[schemas] [sch] ON [so].[schema_id] = [sch].[schema_id] OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id], [ss].[stats_id]) sp WHERE [so].[type] = 'U' AND [sp].[modification_counter] > 0 ORDER BY [sp].[last_updated] DESC;
Sachez que différentes tables peuvent avoir des seuils différents et vous devrez modifier la requête ci-dessus pour vos bases de données. Pour certaines tables, attendre que 15 % ou 20 % des lignes aient été modifiées peut être acceptable. Mais pour d'autres, vous devrez peut-être mettre à jour à 10% ou même 5%, selon les valeurs réelles et leur biais. Il n'y a pas de solution miracle. Même si nous aimons les absolus, ils existent rarement dans SQL Server et les statistiques ne font pas exception. Vous souhaitez toujours laisser les statistiques de mise à jour automatique activées - c'est une sécurité qui se déclenchera si vous manquez quelque chose, tout comme la croissance automatique pour vos fichiers de base de données. Mais votre meilleur pari est de connaître vos données et de mettre en œuvre une méthodologie qui vous permet de mettre à jour les statistiques en fonction du pourcentage de lignes modifiées.