Cela fait presque deux mois maintenant que nous avons publié SCUMM (Severalnines ClusterControl Unified Management and Monitoring). SCUMM utilise Prometheus comme méthode sous-jacente pour collecter des données de séries chronologiques à partir d'exportateurs s'exécutant sur des instances de base de données et des équilibreurs de charge. Ce blog vous montrera comment résoudre les problèmes lorsque les exportateurs Prometheus ne s'exécutent pas, ou si les graphiques n'affichent pas de données ou affichent "Aucun point de données".
Qu'est-ce que Prométhée ?
Prometheus est un système de surveillance open source avec un modèle de données dimensionnel, un langage de requête flexible, une base de données de séries chronologiques efficace et une approche d'alerte moderne. Il s'agit d'une plate-forme de surveillance qui collecte des métriques à partir de cibles surveillées en grattant les métriques des points de terminaison HTTP sur ces cibles. Il fournit des données dimensionnelles, des requêtes puissantes, une excellente visualisation, un stockage efficace, un fonctionnement simple, des alertes précises, de nombreuses bibliothèques clientes et de nombreuses intégrations.
Prometheus en action pour les tableaux de bord SCUMM
Prometheus collecte les données de métriques des exportateurs, chaque exportateur s'exécutant sur un hôte de base de données ou d'équilibreur de charge. Le schéma ci-dessous vous montre comment ces exportateurs sont liés au serveur hébergeant le processus Prometheus. Il montre que le nœud ClusterControl exécute Prometheus où il exécute également process_exporter et node_exporter.
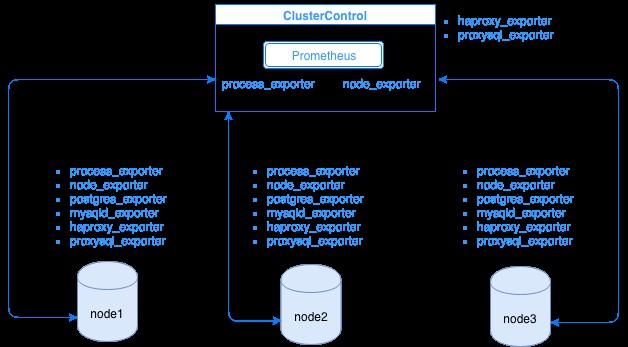
Le diagramme montre que Prometheus s'exécute sur l'hôte ClusterControl et les exportateurs process_exporter et node_exporter sont également en cours d'exécution pour collecter des métriques à partir de son propre nœud. En option, vous pouvez également faire de votre hôte ClusterControl la cible dans laquelle vous pouvez configurer HAProxy ou ProxySQL.
Pour les nœuds de cluster ci-dessus (nœud1, nœud2 et nœud3), il peut y avoir mysqld_exporter ou postgres_exporter en cours d'exécution, qui sont les agents qui récupèrent les données en interne dans ce nœud et les transmettent au serveur Prometheus et les stockent dans son propre stockage de données. Vous pouvez localiser ses données physiques via /var/lib/prometheus/data dans l'hôte où Prometheus est installé.
Lorsque vous configurez Prometheus, par exemple, dans l'hôte ClusterControl, les ports suivants doivent être ouverts. Voir ci-dessous :
[example@sqldat.com share]# netstat -tnvlp46|egrep 'ex[p]|prometheu[s]'
tcp6 0 0 :::9100 :::* LISTEN 16189/node_exporter
tcp6 0 0 :::9011 :::* LISTEN 19318/process_expor
tcp6 0 0 :::42004 :::* LISTEN 16080/proxysql_expo
tcp6 0 0 :::9090 :::* LISTEN 31856/prometheusSur la base de la sortie, ProxySQL s'exécute également sur l'hôte testccnode dans lequel ClusterControl est hébergé.
Problèmes courants avec les tableaux de bord SCUMM utilisant Prometheus
Lorsque les tableaux de bord sont activés, le ClusterControl installe et déploie des fichiers binaires et des exportateurs tels que node_exporter, process_exporter, mysqld_exporter, postgres_exporter et daemon. Il s'agit des ensembles de packages communs aux nœuds de base de données. Lorsque ceux-ci sont configurés et installés, les commandes de démon suivantes sont lancées et exécutées comme indiqué ci-dessous :
[example@sqldat.com bin]# ps axufww|egrep 'exporte[r]'
prometh+ 3604 0.0 0.0 10828 364 ? S Nov28 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 3605 0.2 0.3 256300 14924 ? Sl Nov28 4:06 \_ process_exporter
prometh+ 3838 0.0 0.0 10828 564 ? S Nov28 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 3839 0.0 0.4 44636 15568 ? Sl Nov28 1:08 \_ node_exporter
prometh+ 4038 0.0 0.0 10828 568 ? S Nov28 0:00 daemon --name=mysqld_exporter --output=/var/log/prometheus/mysqld_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/mysqld_exporter.pid --user=prometheus -- mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_status
prometh+ 4039 0.1 0.2 17368 11544 ? Sl Nov28 1:47 \_ mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_statusPour un nœud PostgreSQL,
[example@sqldat.com vagrant]# ps axufww|egrep 'ex[p]'
postgres 1901 0.0 0.4 1169024 8904 ? Ss 18:00 0:04 \_ postgres: postgres_exporter postgres ::1(51118) idle
prometh+ 1516 0.0 0.0 10828 360 ? S 18:00 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 1517 0.2 0.7 117032 14636 ? Sl 18:00 0:35 \_ process_exporter
prometh+ 1700 0.0 0.0 10828 572 ? S 18:00 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 1701 0.0 0.7 44380 14932 ? Sl 18:00 0:10 \_ node_exporter
prometh+ 1897 0.0 0.0 10828 568 ? S 18:00 0:00 daemon --name=postgres_exporter --output=/var/log/prometheus/postgres_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --env=DATA_SOURCE_NAME=postgresql://postgres_exporter:example@sqldat.com:5432/postgres?sslmode=disable --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/postgres_exporter.pid --user=prometheus -- postgres_exporter
prometh+ 1898 0.0 0.5 16548 11204 ? Sl 18:00 0:06 \_ postgres_exporterIl a les mêmes exportateurs que pour un nœud MySQL, mais ne diffère que sur le postgres_exporter puisqu'il s'agit d'un nœud de base de données PostgreSQL.
Cependant, lorsqu'un nœud souffre d'une coupure de courant, d'un plantage du système ou d'un redémarrage du système, ces exportateurs cessent de fonctionner. Prometheus signalera qu'un exportateur est en panne. ClusterControl échantillonne Prometheus lui-même et demande les statuts de l'exportateur. Il agit donc en fonction de ces informations et redémarrera l'exportateur s'il est en panne.
Cependant, notez que pour les exportateurs qui n'ont pas été installés via ClusterControl, ils ne seront pas redémarrés après un crash. La raison en est qu'ils ne sont pas surveillés par systemd ou un démon qui agit comme un script de sécurité qui redémarrerait un processus en cas de plantage ou d'arrêt anormal. Par conséquent, la capture d'écran ci-dessous montrera à quoi cela ressemble lorsque les exportateurs ne fonctionnent pas. Voir ci-dessous :
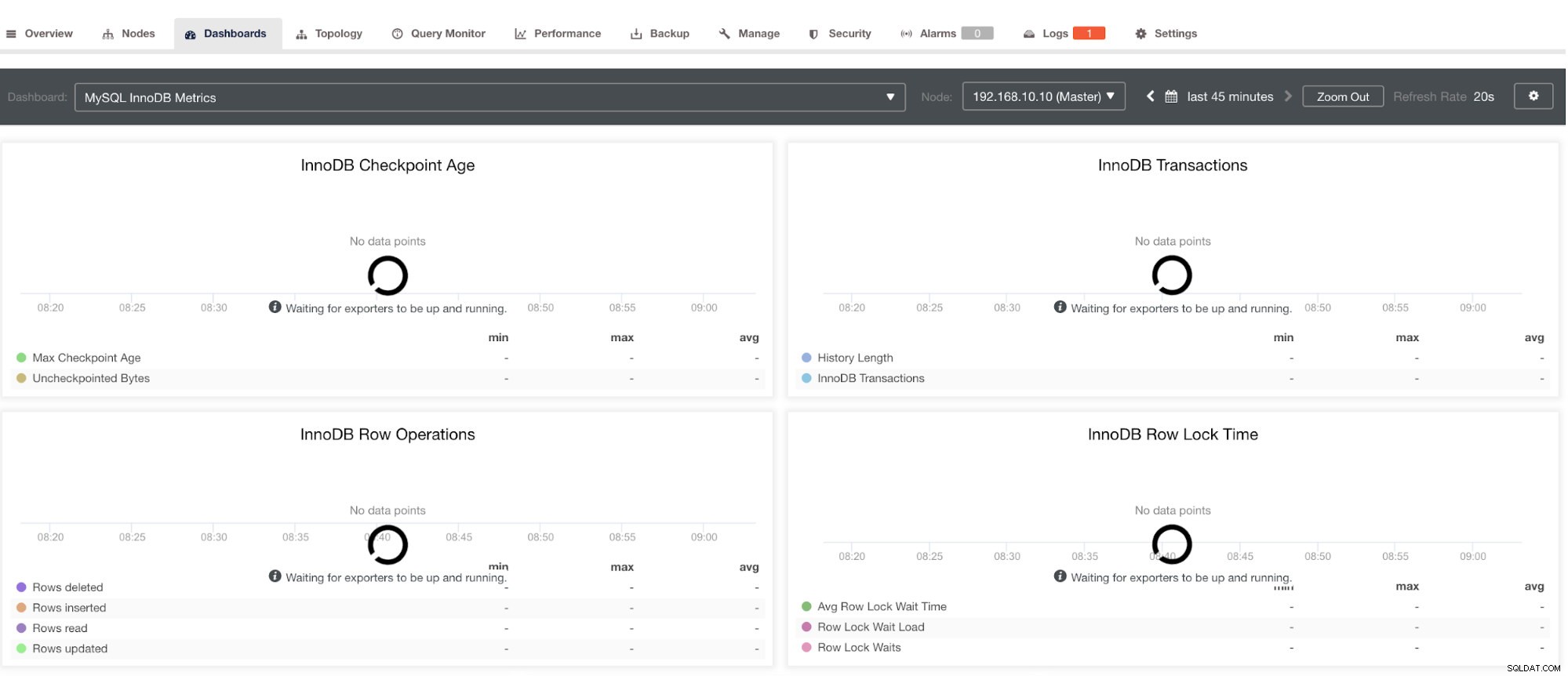
et dans le tableau de bord PostgreSQL, aura la même icône de chargement avec l'étiquette "Aucun point de données" dans le graphique. Voir ci-dessous :
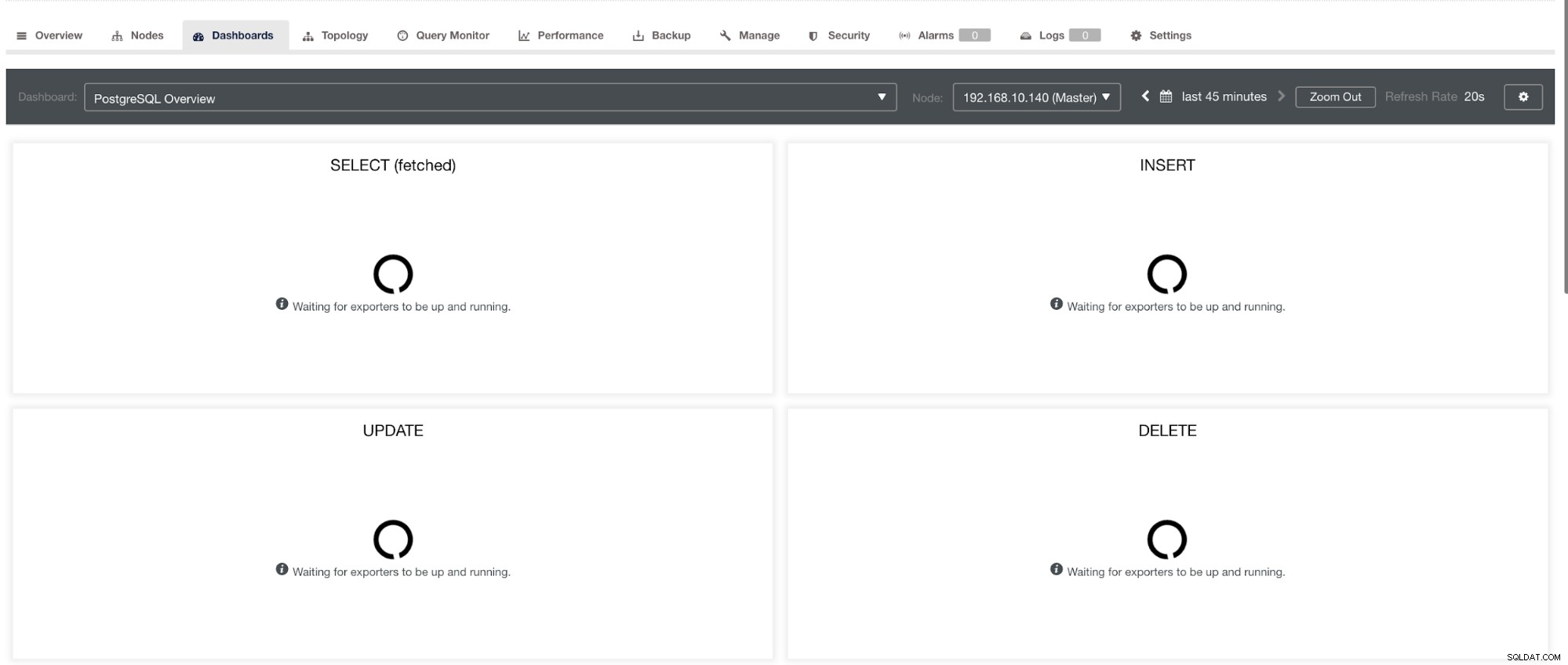
Par conséquent, ceux-ci peuvent être résolus grâce à diverses techniques qui suivront dans les sections suivantes.
Résoudre les problèmes avec Prometheus
Les agents Prometheus, connus sous le nom d'exportateurs, utilisent les ports suivants :9100 (node_exporter), 9011 (process_exporter), 9187 (postgres_exporter), 9104 (mysqld_exporter), 42004 (proxysql_exporter) et le propre 9090 qui appartient à un prometheus processus. Ce sont les ports de ces agents qui sont utilisés par ClusterControl.
Pour commencer à résoudre les problèmes du tableau de bord SCUMM, vous pouvez commencer par vérifier les ports ouverts à partir du nœud de base de données. Vous pouvez suivre les listes ci-dessous :
-
Vérifiez si les ports sont ouverts
ex.
## Use netstat and check the ports [example@sqldat.com vagrant]# netstat -tnvlp46|egrep 'ex[p]' tcp6 0 0 :::9100 :::* LISTEN 5036/node_exporter tcp6 0 0 :::9011 :::* LISTEN 4852/process_export tcp6 0 0 :::9187 :::* LISTEN 5230/postgres_exporIl est possible que les ports ne soient pas ouverts à cause d'un pare-feu (comme iptables ou firewalld) qui l'empêche d'ouvrir le port ou que le démon de processus lui-même ne soit pas en cours d'exécution.
-
Utilisez curl depuis le moniteur hôte et vérifiez si le port est accessible et ouvert.
ex.
## Using curl and grep mysql list of available metric names used in PromQL. [example@sqldat.com prometheus]# curl -sv mariadb_g01:9104/metrics|grep 'mysql'|head -25 * About to connect() to mariadb_g01 port 9104 (#0) * Trying 192.168.10.10... * Connected to mariadb_g01 (192.168.10.10) port 9104 (#0) > GET /metrics HTTP/1.1 > User-Agent: curl/7.29.0 > Host: mariadb_g01:9104 > Accept: */* > < HTTP/1.1 200 OK < Content-Length: 213633 < Content-Type: text/plain; version=0.0.4; charset=utf-8 < Date: Sat, 01 Dec 2018 04:23:21 GMT < { [data not shown] # HELP mysql_binlog_file_number The last binlog file number. # TYPE mysql_binlog_file_number gauge mysql_binlog_file_number 114 # HELP mysql_binlog_files Number of registered binlog files. # TYPE mysql_binlog_files gauge mysql_binlog_files 26 # HELP mysql_binlog_size_bytes Combined size of all registered binlog files. # TYPE mysql_binlog_size_bytes gauge mysql_binlog_size_bytes 8.233181e+06 # HELP mysql_exporter_collector_duration_seconds Collector time duration. # TYPE mysql_exporter_collector_duration_seconds gauge mysql_exporter_collector_duration_seconds{collector="collect.binlog_size"} 0.008825006 mysql_exporter_collector_duration_seconds{collector="collect.global_status"} 0.006489491 mysql_exporter_collector_duration_seconds{collector="collect.global_variables"} 0.00324821 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.innodb_metrics"} 0.008209824 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.processlist"} 0.007524068 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tables"} 0.010236411 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tablestats"} 0.000610684 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.eventswaits"} 0.009132491 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_events"} 0.009235416 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_instances"} 0.009451361 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.indexiowaits"} 0.009568397 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tableiowaits"} 0.008418406 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tablelocks"} 0.008656682 mysql_exporter_collector_duration_seconds{collector="collect.slave_status"} 0.009924652 * Failed writing body (96 != 14480) * Closing connection 0Idéalement, j'ai pratiquement trouvé cette approche faisable pour moi car je peux grep et déboguer facilement depuis le terminal.
-
Pourquoi ne pas utiliser l'interface Web ?
-
Prometheus expose le port 9090 qui est utilisé par ClusterControl dans nos tableaux de bord SCUMM. En dehors de cela, les ports que les exportateurs exposent peuvent également être utilisés pour dépanner et déterminer les noms de métriques disponibles à l'aide de PromQL. Sur le serveur sur lequel le Prometheus est exécuté, vous pouvez visiter https://
:9090/targets . La capture d'écran ci-dessous le montre en action :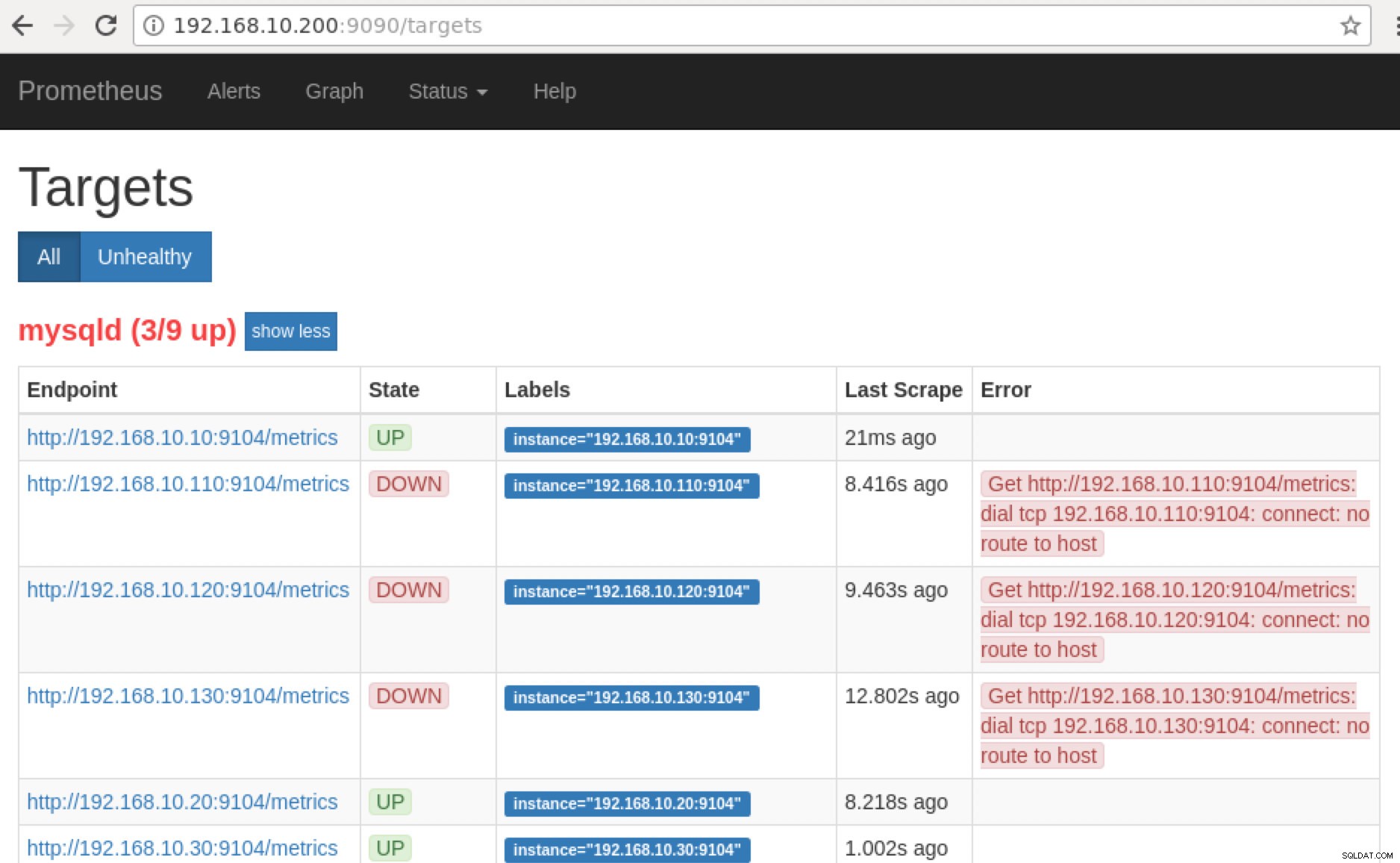
et en cliquant sur "Endpoints", vous pouvez vérifier les métriques ainsi que la capture d'écran ci-dessous :
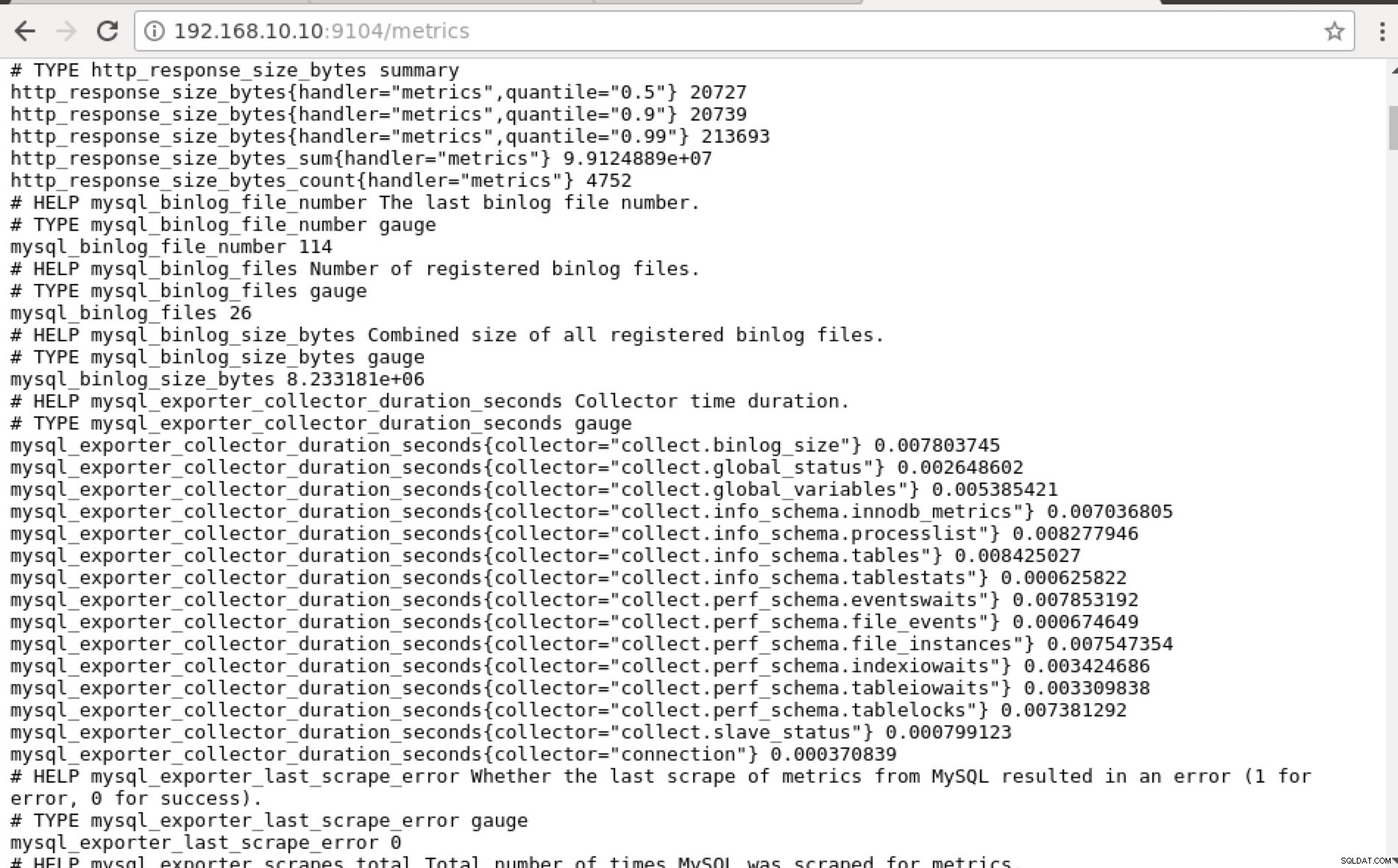
Au lieu d'utiliser l'adresse IP, vous pouvez également vérifier cela localement via localhost sur ce nœud spécifique, par exemple en visitant https://localhost:9104/metrics soit dans une interface Web UI, soit en utilisant cURL.
Maintenant, si nous revenons aux "Cibles », vous pouvez voir la liste des nœuds où il peut y avoir un problème avec le port. Les raisons pouvant en être la cause sont répertoriées ci-dessous :
- Le serveur est en panne
- Le réseau est inaccessible ou les ports ne sont pas ouverts en raison d'un pare-feu en cours d'exécution
- Le démon ne s'exécute pas là où
_exporter ne fonctionne pas. Par exemple, mysqld_exporter n'est pas en cours d'exécution.
-
Lorsque ces exportateurs sont en cours d'exécution, vous pouvez lancer et exécuter le processus à l'aide de daemon commande. Vous pouvez vous référer aux processus en cours d'exécution disponibles que j'avais utilisés dans l'exemple ci-dessus, ou mentionnés dans la section précédente de ce blog.
Qu'en est-il de ces graphiques "Aucun point de données" dans mon tableau de bord ?
Les tableaux de bord SCUMM proposent un scénario de cas d'utilisation général qui est couramment utilisé par MySQL. Cependant, il existe certaines variables lorsque l'invocation d'une telle métrique peut ne pas être disponible dans une version MySQL particulière ou un fournisseur MySQL, tel que MariaDB ou Percona Server.
Permettez-moi de montrer un exemple ci-dessous :
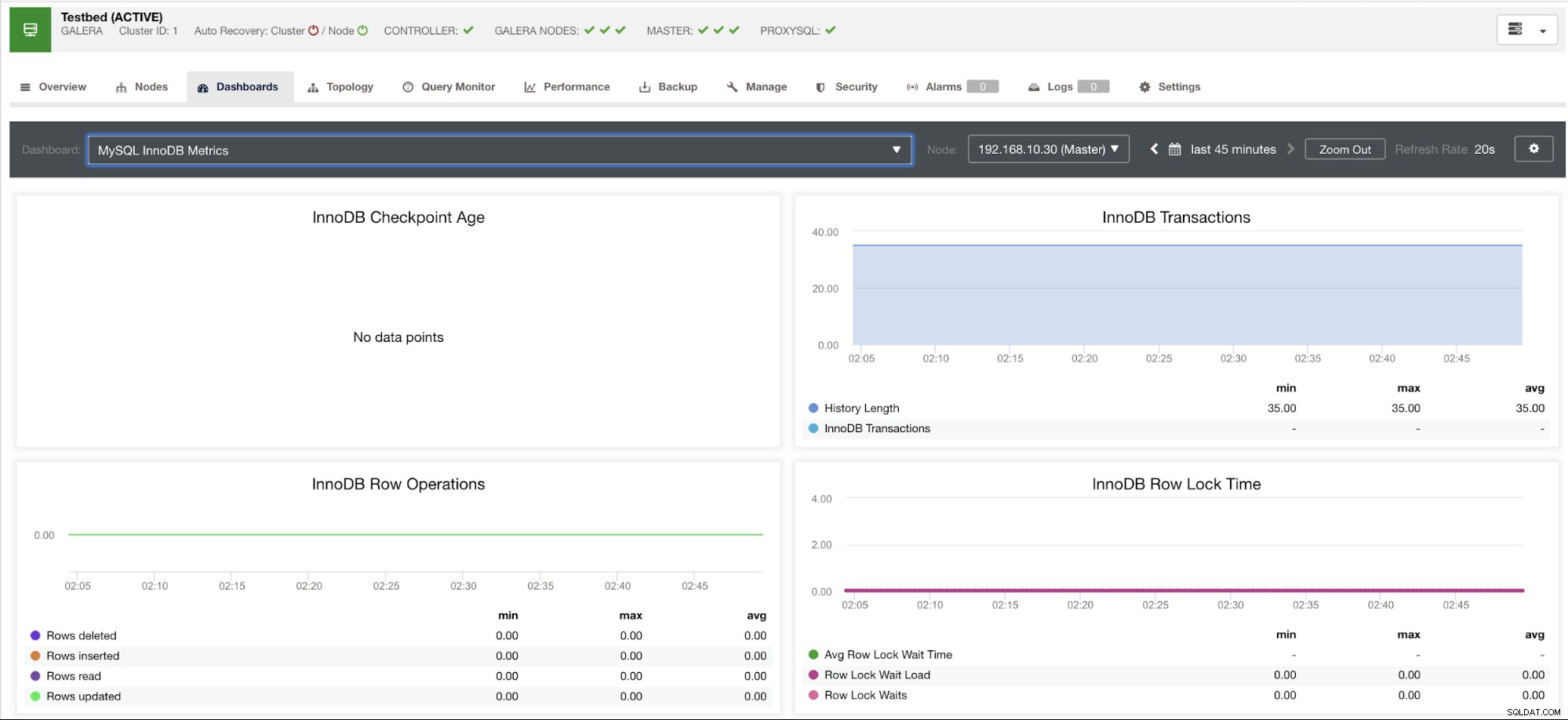
Ce graphique a été pris sur un serveur de base de données exécuté sur un serveur MariaDB version 10.3.9-MariaDB-log avec wsrep_patch_version de l'instance wsrep_25.23. Maintenant, la question est, pourquoi n'y a-t-il pas de chargement de points de données ? Eh bien, comme j'ai interrogé le nœud pour un statut d'âge de point de contrôle, il révèle qu'il est vide ou qu'aucune variable n'a été trouvée. Voir ci-dessous :
MariaDB [(none)]> show global status like 'Innodb_checkpoint_max_age';
Empty set (0.000 sec)Je ne sais pas pourquoi MariaDB n'a pas cette variable (veuillez nous le faire savoir dans la section commentaires de ce blog si vous avez la réponse). Cela contraste avec un serveur de cluster Percona XtraDB où la variable Innodb_checkpoint_max_age existe. Voir ci-dessous :
mysql> show global status like 'Innodb_checkpoint_max_age';
+---------------------------+-----------+
| Variable_name | Value |
+---------------------------+-----------+
| Innodb_checkpoint_max_age | 865244898 |
+---------------------------+-----------+
1 row in set (0.00 sec)Cela signifie cependant qu'il peut y avoir des graphiques qui n'ont pas de points de données collectés car aucune donnée n'est collectée sur cette métrique particulière lorsqu'une requête Prometheus a été exécutée.
Cependant, un graphique qui n'a pas de points de données ne signifie pas que votre version actuelle de MySQL ou sa variante ne le prend pas en charge. Par exemple, certains graphiques nécessitent certaines variables qui doivent être correctement configurées ou activées.
La section suivante montrera ce que sont ces graphiques.
Graphique déroulant de condition d'index (ICP)

Ce graphique a été mentionné dans mon blog précédent. Il repose sur une variable globale MySQL nommée innodb_monitor_enable. Cette variable est dynamique, vous pouvez donc la définir sans redémarrage brutal de votre base de données MySQL. Il nécessite également innodb_monitor_enable =module_icp ou vous pouvez définir cette variable globale sur innodb_monitor_enable =all. En règle générale, pour éviter de tels cas et des confusions sur la raison pour laquelle un tel graphique ne montre aucun point de données, vous devrez peut-être tout utiliser, mais avec précaution. Il peut y avoir une certaine surcharge lorsque cette variable est activée et définie sur tous.
Graphiques du schéma de performances MySQL
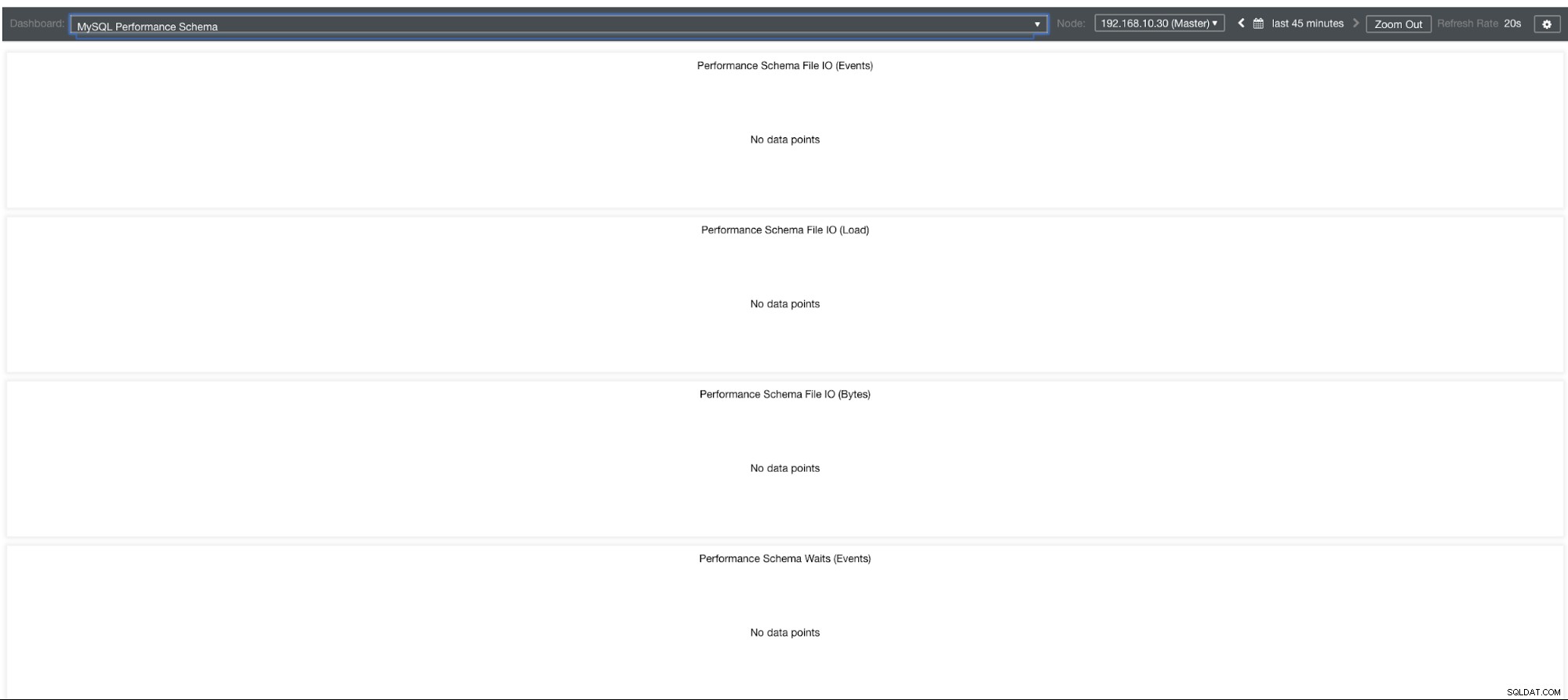
Alors pourquoi ces graphiques affichent "Aucun point de données" ? Lorsque vous créez un cluster à l'aide de ClusterControl à l'aide de nos modèles, il définira par défaut des variables performance_schema. Par exemple, ces variables ci-dessous sont définies :
performance_schema = ON
performance-schema-max-mutex-classes = 0
performance-schema-max-mutex-instances = 0Cependant, si performance_schema =OFF, c'est la raison pour laquelle les graphiques associés afficheraient "Aucun point de données".
Mais j'ai activé performance_schema, pourquoi d'autres graphiques posent-ils toujours problème ?
Eh bien, il y a encore des graphiques qui nécessitent que plusieurs variables soient définies. Cela a déjà été abordé dans notre blog précédent. Ainsi, vous devez définir innodb_monitor_enable =all et userstat=1. Le résultat ressemblerait à ceci :
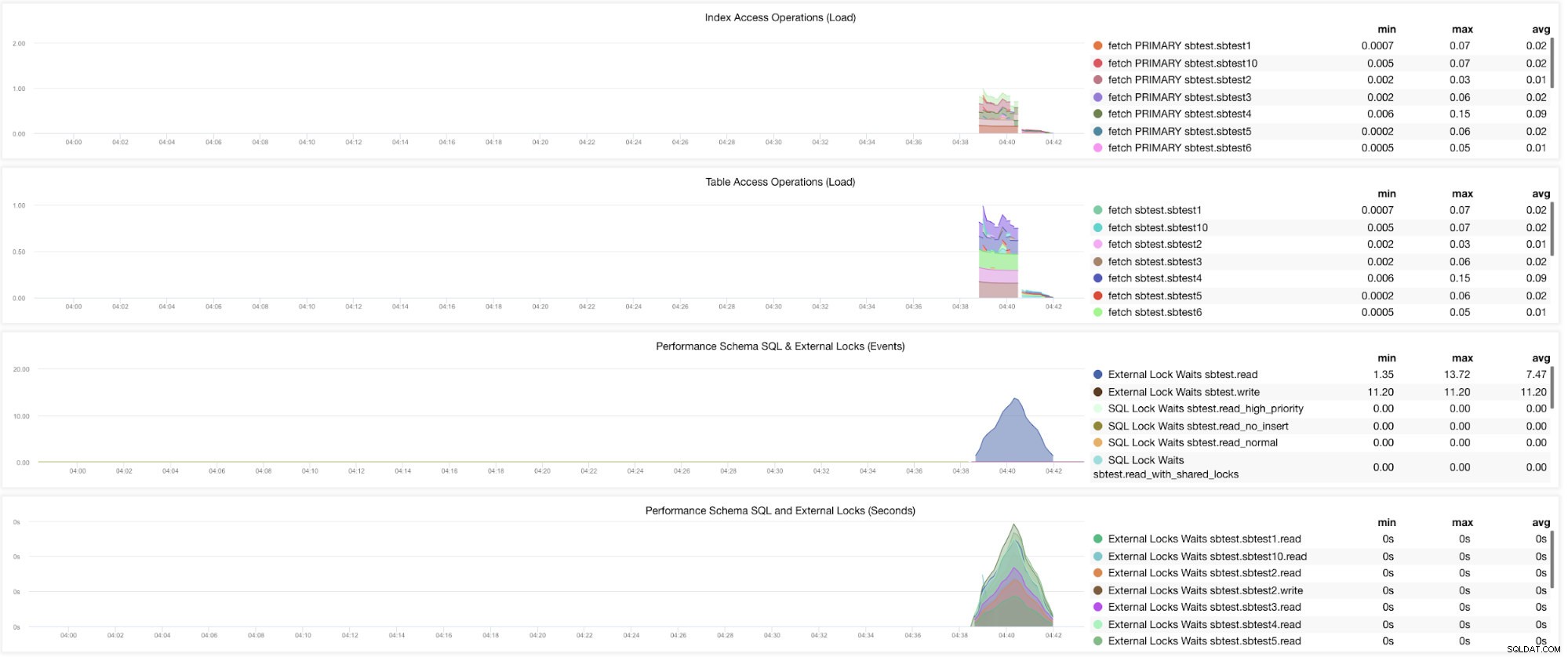
Cependant, je remarque que dans la version de MariaDB 10.3 (en particulier 10.3.11), le paramètre performance_schema=ON remplira les métriques nécessaires au tableau de bord du schéma de performances MySQL. C'est un grand avantage car il n'est pas nécessaire de définir innodb_monitor_enable=ON, ce qui ajouterait une charge supplémentaire sur le serveur de base de données.
Dépannage avancé
Y a-t-il un dépannage avancé que je peux recommander ? Oui il y a! Cependant, vous avez besoin de quelques compétences en JavaScript, au moins. Étant donné que les tableaux de bord SCUMM utilisant Prometheus reposent sur des highcharts, la manière dont les métriques utilisées pour les requêtes PromQL peuvent être déterminées via le script app.js illustré ci-dessous :
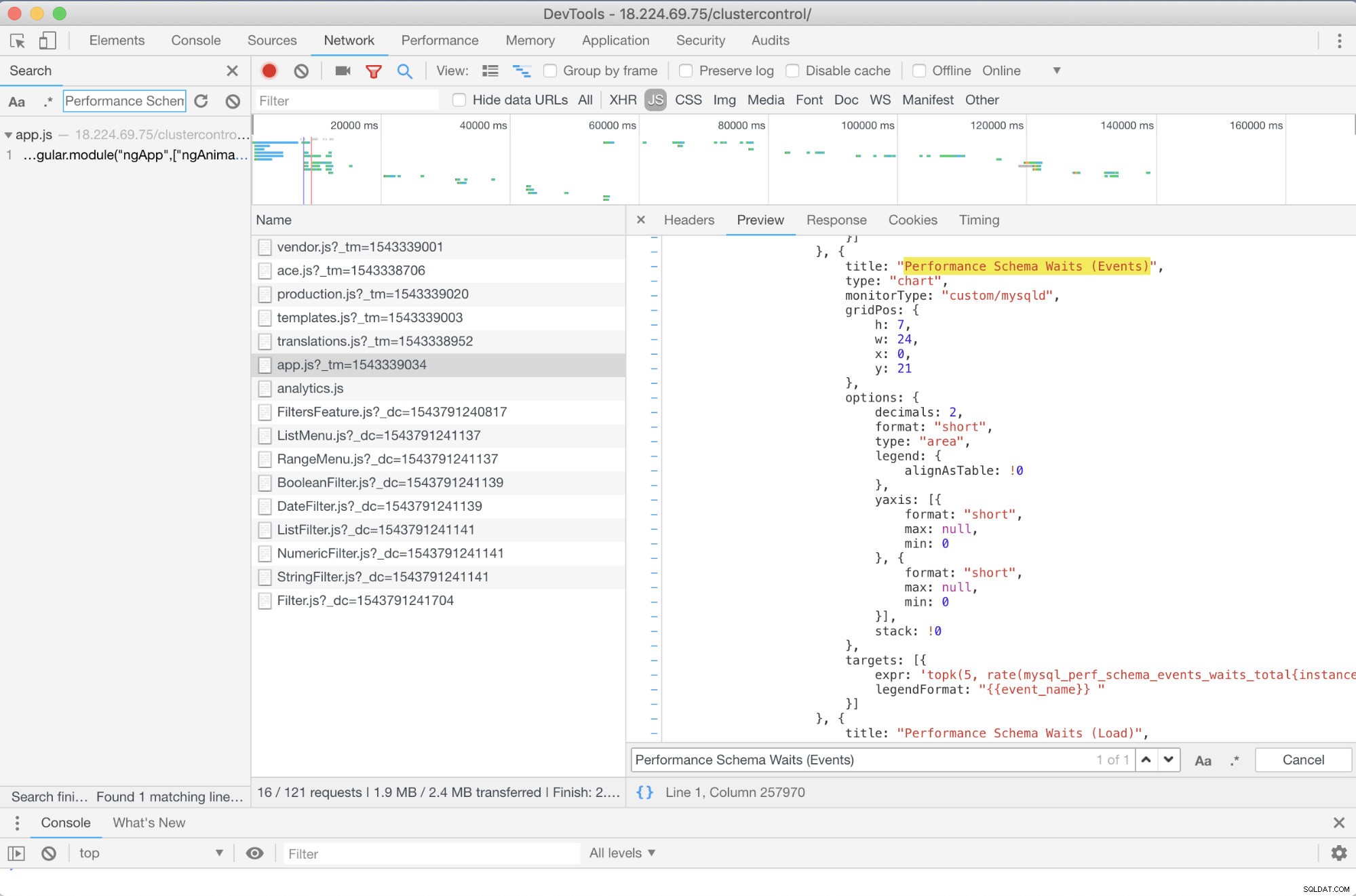
Donc, dans ce cas, j'utilise les DevTools de Google Chrome et j'ai essayé de rechercher Performance Schema Waits (Events) . Comment cela peut-il aider ? Eh bien, si vous regardez les cibles, vous verrez :
targets: [{
expr: 'topk(5, rate(mysql_perf_schema_events_waits_total{instance="$instance"}[$interval])>0) or topk(5, irate(mysql_perf_schema_events_waits_total{instance="$instance"}[5m])>0)',
legendFormat: "{{event_name}} "
}]
Maintenant, vous pouvez utiliser les métriques demandées qui sont mysql_perf_schema_events_waits_total. Vous pouvez vérifier cela, par exemple, en passant par https://
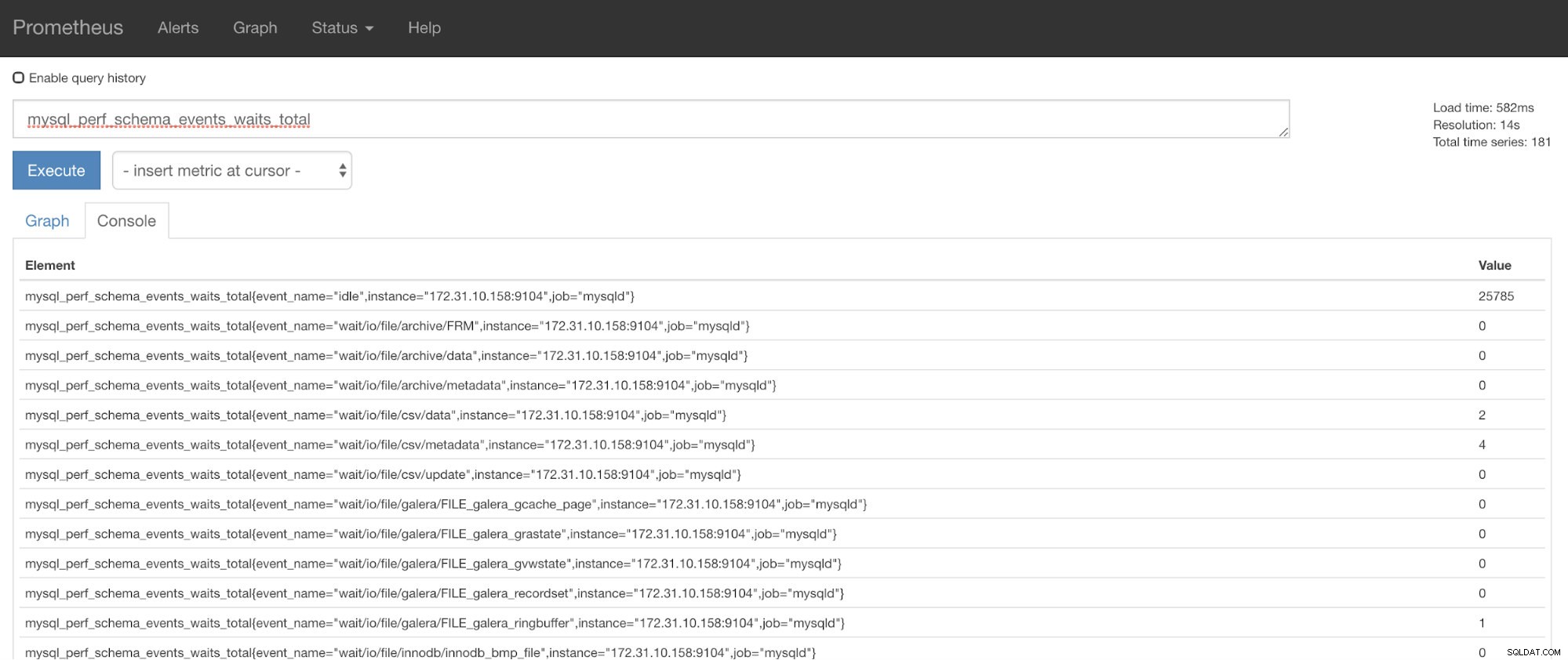
ClusterControl Auto-Recovery à la rescousse !
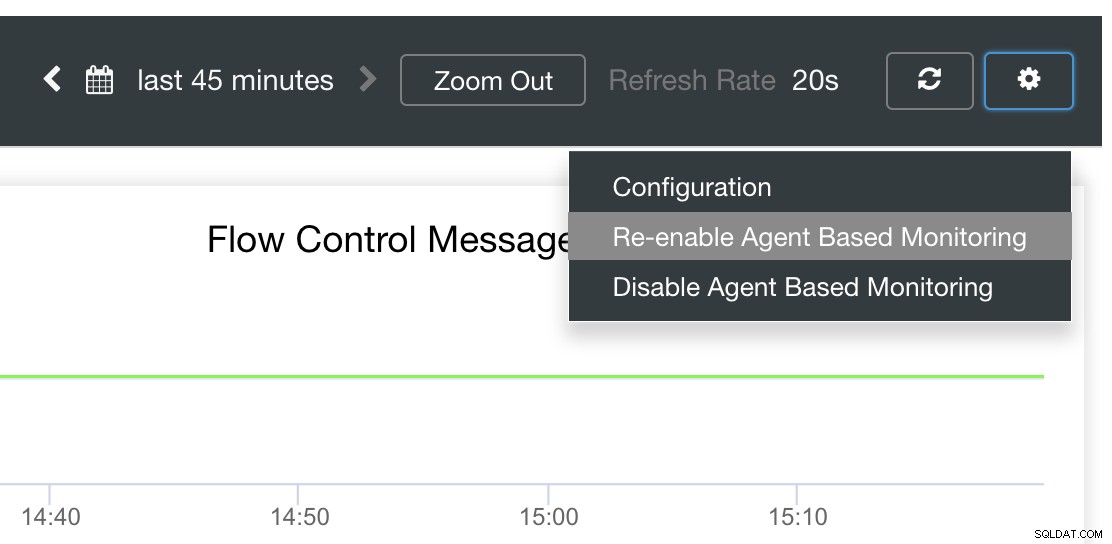
Enfin, la principale question est de savoir s'il existe un moyen simple de redémarrer les exportateurs défaillants ? Oui! Nous avons mentionné précédemment que ClusterControl surveille l'état des exportations et les redémarre si nécessaire. Si vous remarquez que les tableaux de bord SCUMM ne chargent pas les graphiques normalement, assurez-vous que la récupération automatique est activée. Voir l'image ci-dessous :

Lorsque cette option est activée, cela garantira que les
Il est également possible de réinstaller ou de reconfigurer les exportateurs.
Conclusion
Dans ce blog, nous avons vu comment ClusterControl utilise Prometheus pour proposer des tableaux de bord SCUMM. Il fournit un ensemble puissant de fonctionnalités, à partir de données de surveillance haute résolution et de graphiques riches. Vous avez appris qu'avec PromQL, vous pouvez déterminer et dépanner nos tableaux de bord SCUMM qui vous permettent d'agréger les données de séries chronologiques en temps réel. Vous pouvez également générer des graphiques ou afficher via la console toutes les mesures qui ont été collectées.
Vous avez également appris à déboguer nos tableaux de bord SCUMM, en particulier lorsqu'aucun point de données n'est collecté.
Si vous avez des questions, n'hésitez pas à ajouter vos commentaires ou à nous en faire part via nos forums communautaires.



