Cet article est la onzième partie d'une série sur les expressions de table. Jusqu'à présent, j'ai couvert les tables dérivées et les CTE, et j'ai récemment commencé la couverture des vues. Dans la partie 9, j'ai comparé les vues aux tables dérivées et aux CTE, et dans la partie 10, j'ai discuté des changements DDL et des implications de l'utilisation de SELECT * dans la requête interne de la vue. Dans cet article, je me concentre sur les considérations de modification.
Comme vous le savez probablement, vous êtes autorisé à modifier indirectement les données des tables de base via des expressions de table nommées telles que des vues. Vous pouvez contrôler les autorisations de modification par rapport aux vues. En fait, vous pouvez accorder aux utilisateurs des autorisations pour modifier des données via des vues sans leur accorder des autorisations pour modifier directement les tables sous-jacentes.
Vous devez être conscient de certaines complexités et restrictions qui s'appliquent aux modifications via les vues. Fait intéressant, certaines des modifications prises en charge peuvent aboutir à des résultats surprenants, en particulier si l'utilisateur modifiant les données n'est pas conscient qu'il interagit avec une vue. Vous pouvez imposer d'autres restrictions aux modifications via les vues en utilisant une option appelée CHECK OPTION, que je couvrirai dans cet article. Dans le cadre de la couverture, je décrirai une curieuse incohérence entre la façon dont CHECK OPTION dans une vue et une contrainte CHECK dans une table gèrent les modifications, en particulier celles impliquant des valeurs NULL.
Exemple de données
Comme exemples de données pour cet article, j'utiliserai des tables appelées Orders et OrderDetails. Utilisez le code suivant pour créer ces tables dans tempdb et les remplir avec des exemples de données initiaux :
USE tempdb;
GO
DROP TABLE IF EXISTS dbo.OrderDetails, dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL
CONSTRAINT PK_Orders PRIMARY KEY,
orderdate DATE NOT NULL,
shippeddate DATE NULL
);
INSERT INTO dbo.Orders(orderid, orderdate, shippeddate)
VALUES(1, '20210802', '20210804'),
(2, '20210802', '20210805'),
(3, '20210804', '20210806'),
(4, '20210826', NULL),
(5, '20210827', NULL);
CREATE TABLE dbo.OrderDetails
(
orderid INT NOT NULL
CONSTRAINT FK_OrderDetails_Orders REFERENCES dbo.Orders,
productid INT NOT NULL,
qty INT NOT NULL,
unitprice NUMERIC(12, 2) NOT NULL,
discount NUMERIC(5, 4) NOT NULL,
CONSTRAINT PK_OrderDetails PRIMARY KEY(orderid, productid)
);
INSERT INTO dbo.OrderDetails(orderid, productid, qty, unitprice, discount)
VALUES(1, 1001, 5, 10.50, 0.05),
(1, 1004, 2, 20.00, 0.00),
(2, 1003, 1, 52.99, 0.10),
(3, 1001, 1, 10.50, 0.05),
(3, 1003, 2, 54.99, 0.10),
(4, 1001, 2, 10.50, 0.05),
(4, 1004, 1, 20.30, 0.00),
(4, 1005, 1, 30.10, 0.05),
(5, 1003, 5, 54.99, 0.00),
(5, 1006, 2, 12.30, 0.08); La table Orders contient les en-têtes de commande et la table OrderDetails contient les lignes de commande. Les commandes non expédiées ont un NULL dans la colonne de la date d'expédition. Si vous préférez une conception qui n'utilise pas de valeurs NULL, vous pouvez utiliser une date future spécifique pour les commandes non expédiées, telle que "99991231".
VERIFIER LES OPTIONS
Pour comprendre les circonstances dans lesquelles vous voudriez utiliser l'OPTION DE VÉRIFICATION dans le cadre de la définition d'une vue, nous allons d'abord examiner ce qui peut arriver lorsque vous ne l'utilisez pas.
Le code suivant crée une vue appelée FastOrders représentant les commandes expédiées dans les sept jours suivant leur passation :
CREATE OR ALTER VIEW dbo.FastOrders AS SELECT orderid, orderdate, shippeddate FROM dbo.Orders WHERE DATEDIFF(day, orderdate, shippeddate) <= 7; GO
Utilisez le code suivant pour insérer dans la vue une commande expédiée deux jours après avoir été passée :
INSERT INTO dbo.FastOrders(orderid, orderdate, shippeddate) VALUES(6, '20210805', '20210807');
Interroger la vue :
SELECT * FROM dbo.FastOrders;
Vous obtenez le résultat suivant, qui inclut la nouvelle commande :
orderid orderdate shippeddate ----------- ---------- ----------- 1 2021-08-02 2021-08-04 2 2021-08-02 2021-08-05 3 2021-08-04 2021-08-06 6 2021-08-05 2021-08-07
Interrogez la table sous-jacente :
SELECT * FROM dbo.Orders;
Vous obtenez le résultat suivant, qui inclut la nouvelle commande :
orderid orderdate shippeddate ----------- ---------- ----------- 1 2021-08-02 2021-08-04 2 2021-08-02 2021-08-05 3 2021-08-04 2021-08-06 4 2021-08-26 NULL 5 2021-08-27 NULL 6 2021-08-05 2021-08-07
La ligne a été insérée dans la table de base sous-jacente via la vue.
Ensuite, insérez dans la vue une ligne expédiée 10 jours après avoir été placée, en contradiction avec le filtre de requête interne de la vue :
INSERT INTO dbo.FastOrders(orderid, orderdate, shippeddate) VALUES(7, '20210805', '20210815');
L'instruction se termine avec succès, signalant qu'une ligne est affectée.
Interroger la vue :
SELECT * FROM dbo.FastOrders;
Vous obtenez le résultat suivant, qui exclut la nouvelle commande :
orderid orderdate shippeddate ----------- ---------- ----------- 1 2021-08-02 2021-08-04 2 2021-08-02 2021-08-05 3 2021-08-04 2021-08-06 6 2021-08-05 2021-08-07
Si vous savez que FastOrders est une vue, tout cela peut sembler sensé. Après tout, la ligne a été insérée dans la table sous-jacente et elle ne satisfait pas le filtre de requête interne de la vue. Mais si vous ne savez pas que FastOrders est une vue et non une table de base, ce comportement semblerait surprenant.
Interrogez la table Orders sous-jacente :
SELECT * FROM dbo.Orders;
Vous obtenez le résultat suivant, qui inclut la nouvelle commande :
orderid orderdate shippeddate ----------- ---------- ----------- 1 2021-08-02 2021-08-04 2 2021-08-02 2021-08-05 3 2021-08-04 2021-08-06 4 2021-08-26 NULL 5 2021-08-27 NULL 6 2021-08-05 2021-08-07 7 2021-08-05 2021-08-15
Vous pouvez rencontrer un comportement surprenant similaire si vous mettez à jour via la vue la valeur de la date d'expédition dans une ligne qui fait actuellement partie de la vue à une date qui ne la qualifie plus comme faisant partie de la vue. Une telle mise à jour est normalement autorisée, mais encore une fois, elle a lieu dans la table de base sous-jacente. Si vous interrogez la vue après une telle mise à jour, la ligne modifiée semble avoir disparu. En pratique, il est toujours là dans la table sous-jacente, il n'est simplement plus considéré comme faisant partie de la vue.
Exécutez le code suivant pour supprimer les lignes que vous avez ajoutées précédemment :
DELETE FROM dbo.Orders WHERE orderid >= 6;
Si vous souhaitez empêcher les modifications qui entrent en conflit avec le filtre de requête interne de la vue, ajoutez WITH CHECK OPTION à la fin de la requête interne dans le cadre de la définition de la vue, comme ceci :
CREATE OR ALTER VIEW dbo.FastOrders AS SELECT orderid, orderdate, shippeddate FROM dbo.Orders WHERE DATEDIFF(day, orderdate, shippeddate) <= 7 WITH CHECK OPTION; GO
Les insertions et les mises à jour via la vue sont autorisées tant qu'elles respectent le filtre de la requête interne. Sinon, ils sont rejetés.
Par exemple, utilisez le code suivant pour insérer dans la vue une ligne qui n'entre pas en conflit avec le filtre de requête interne :
INSERT INTO dbo.FastOrders(orderid, orderdate, shippeddate) VALUES(6, '20210805', '20210807');
La ligne est ajoutée avec succès.
Essayez d'insérer une ligne qui entre en conflit avec le filtre :
INSERT INTO dbo.FastOrders(orderid, orderdate, shippeddate) VALUES(7, '20210805', '20210815');
Cette fois, la ligne est rejetée avec l'erreur suivante :
Niveau 16, État 1, Ligne 135La tentative d'insertion ou de mise à jour a échoué car la vue cible spécifie WITH CHECK OPTION ou s'étend sur une vue qui spécifie WITH CHECK OPTION et une ou plusieurs lignes résultant de l'opération n'étaient pas qualifiées sous le Contrainte CHECK OPTION.
Incohérences NULL
Si vous travaillez avec T-SQL depuis un certain temps, vous êtes probablement bien conscient des complexités de modification susmentionnées et de la fonction CHECK OPTION sert. Souvent, même les personnes expérimentées trouvent la gestion NULL de CHECK OPTION surprenante. Pendant des années, j'avais l'habitude de penser que CHECK OPTION dans une vue remplissait la même fonction qu'une contrainte CHECK dans la définition d'une table de base. C'est aussi ainsi que j'avais l'habitude de décrire cette option lors de l'écriture ou de l'enseignement à ce sujet. En effet, tant qu'il n'y a pas de NULL impliqués dans le prédicat de filtre, il est pratique de penser aux deux en termes similaires. Ils se comportent de manière cohérente dans un tel cas, acceptant les lignes qui sont en accord avec le prédicat et rejetant celles qui sont en conflit avec lui. Cependant, les deux gèrent les valeurs NULL de manière incohérente.
Lors de l'utilisation de CHECK OPTION, une modification est autorisée via la vue tant que le prédicat est évalué à vrai, sinon il est rejeté. Cela signifie qu'il est rejeté lorsque le prédicat de la vue est évalué à faux ou inconnu (lorsqu'un NULL est impliqué). Avec une contrainte CHECK, la modification est autorisée lorsque le prédicat de la contrainte est évalué à vrai ou inconnu, et rejetée lorsque le prédicat est évalué à faux. C'est une différence intéressante ! Voyons d'abord cela en action, puis nous essaierons de comprendre la logique derrière cette incohérence.
Essayez d'insérer dans la vue une ligne avec une date d'expédition NULL :
INSERT INTO dbo.FastOrders(orderid, orderdate, shippeddate) VALUES(8, '20210828', NULL);
Le prédicat de la vue est évalué comme inconnu et la ligne est rejetée avec l'erreur suivante :
Msg 550, Niveau 16, État 1, Ligne 147La tentative d'insertion ou de mise à jour a échoué car la vue cible spécifie WITH CHECK OPTION ou s'étend sur une vue qui spécifie WITH CHECK OPTION et une ou plusieurs lignes résultant de l'opération n'ont pas se qualifier sous la contrainte CHECK OPTION.
Essayons une insertion similaire sur une table de base avec une contrainte CHECK. Utilisez le code suivant pour ajouter une telle contrainte à la définition de la table de notre commande :
ALTER TABLE dbo.Orders
ADD CONSTRAINT CHK_Orders_FastOrder
CHECK(DATEDIFF(day, orderdate, shippeddate) <= 7); Tout d'abord, pour vous assurer que la contrainte fonctionne lorsqu'il n'y a pas de valeur NULL, essayez d'insérer la commande suivante avec une date d'expédition à 10 jours de la date de commande :
INSERT INTO dbo.Orders(orderid, orderdate, shippeddate) VALUES(7, '20210805', '20210815');
Cette tentative d'insertion est rejetée avec l'erreur suivante :
Msg 547, Niveau 16, État 0, Ligne 159L'instruction INSERT est en conflit avec la contrainte CHECK "CHK_Orders_FastOrder". Le conflit s'est produit dans la base de données "tempdb", table "dbo.Orders".
Utilisez le code suivant pour insérer une ligne avec une date d'expédition NULL :
INSERT INTO dbo.Orders(orderid, orderdate, shippeddate) VALUES(8, '20210828', NULL);
Une contrainte CHECK est censée rejeter les faux cas, mais dans notre cas, le prédicat est évalué comme inconnu, donc la ligne est ajoutée avec succès.
Interrogez la table Commandes :
SELECT * FROM dbo.Orders;
Vous pouvez voir la nouvelle commande dans la sortie :
orderid orderdate shippeddate ----------- ---------- ----------- 1 2021-08-02 2021-08-04 2 2021-08-02 2021-08-05 3 2021-08-04 2021-08-06 4 2021-08-26 NULL 5 2021-08-27 NULL 6 2021-08-05 2021-08-07 8 2021-08-28 NULL
Quelle est la logique derrière cette incohérence ? Vous pourriez soutenir qu'une contrainte CHECK ne devrait être appliquée que lorsque le prédicat de la contrainte est clairement violé, c'est-à-dire lorsqu'il est évalué à faux. De cette façon, si vous choisissez d'autoriser les valeurs NULL dans la colonne en question, les lignes contenant des valeurs NULL dans la colonne sont autorisées même si le prédicat de la contrainte est évalué comme inconnu. Dans notre cas, nous représentons les commandes non expédiées avec un NULL dans la colonne de date d'expédition, et nous autorisons les commandes non expédiées dans le tableau tout en appliquant la règle des "commandes rapides" uniquement pour les commandes expédiées.
L'argument pour utiliser une logique différente avec une vue est qu'une modification ne doit être autorisée via la vue que si la ligne de résultat est une partie valide de la vue. Si le prédicat de la vue est évalué comme inconnu, par exemple, lorsque la date d'expédition est NULL, la ligne de résultat n'est pas une partie valide de la vue, elle est donc rejetée. Seules les lignes pour lesquelles le prédicat est évalué comme vrai font partie de la vue et sont donc autorisées.
Les valeurs NULL ajoutent beaucoup de complexité au langage. Que vous les aimiez ou non, si vos données les prennent en charge, vous voulez vous assurer que vous comprenez comment T-SQL les gère.
À ce stade, vous pouvez supprimer la contrainte CHECK de la table Orders et également supprimer la vue FastOrders pour le nettoyage :
ALTER TABLE dbo.Orders DROP CONSTRAINT CHK_Orders_FastOrder; DROP VIEW IF EXISTS dbo.FastOrders;
Restriction TOP/OFFSET-FETCH
Les modifications via les vues impliquant les filtres TOP et OFFSET-FETCH sont normalement autorisées. Cependant, comme dans notre discussion précédente sur les vues définies sans l'OPTION DE VÉRIFICATION, le résultat d'une telle modification peut sembler étrange à l'utilisateur s'il ne sait pas qu'il interagit avec une vue.
Prenons comme exemple la vue suivante représentant les commandes récentes :
CREATE OR ALTER VIEW dbo.RecentOrders AS SELECT TOP (5) orderid, orderdate, shippeddate FROM dbo.Orders ORDER BY orderdate DESC, orderid DESC; GO
Utilisez le code suivant pour insérer dans la vue Commandes récentes six commandes :
INSERT INTO dbo.RecentOrders(orderid, orderdate, shippeddate)
VALUES(9, '20210801', '20210803'),
(10, '20210802', '20210804'),
(11, '20210829', '20210831'),
(12, '20210830', '20210902'),
(13, '20210830', '20210903'),
(14, '20210831', '20210903'); Interroger la vue :
SELECT * FROM dbo.RecentOrders;
Vous obtenez le résultat suivant :
orderid orderdate shippeddate ----------- ---------- ----------- 14 2021-08-31 2021-09-03 13 2021-08-30 2021-09-03 12 2021-08-30 2021-09-02 11 2021-08-29 2021-08-31 8 2021-08-28 NULL
Sur les six commandes insérées, seules quatre font partie de la vue. Cela semble parfaitement logique si vous savez que vous interrogez une vue basée sur une requête avec un filtre TOP. Mais cela peut sembler étrange si vous pensez que vous interrogez une table de base.
Interrogez directement la table Orders sous-jacente :
SELECT * FROM dbo.Orders;
Vous obtenez la sortie suivante montrant toutes les commandes ajoutées :
orderid orderdate shippeddate ----------- ---------- ----------- 1 2021-08-02 2021-08-04 2 2021-08-02 2021-08-05 3 2021-08-04 2021-08-06 4 2021-08-26 NULL 5 2021-08-27 NULL 6 2021-08-05 2021-08-07 8 2021-08-28 NULL 9 2021-08-01 2021-08-03 10 2021-08-02 2021-08-04 11 2021-08-29 2021-08-31 12 2021-08-30 2021-09-02 13 2021-08-30 2021-09-03 14 2021-08-31 2021-09-03
Si vous ajoutez CHECK OPTION à la définition de la vue, les instructions INSERT et UPDATE sur la vue seront rejetées. Utilisez le code suivant pour appliquer ce changement :
CREATE OR ALTER VIEW dbo.RecentOrders AS SELECT TOP (5) orderid, orderdate, shippeddate FROM dbo.Orders ORDER BY orderdate DESC, orderid DESC WITH CHECK OPTION; GO
Essayez d'ajouter une commande via la vue :
INSERT INTO dbo.RecentOrders(orderid, orderdate, shippeddate) VALUES(15, '20210801', '20210805');
Vous obtenez l'erreur suivante :
Msg 4427, Niveau 16, État 1, Ligne 247Impossible de mettre à jour la vue "dbo.RecentOrders" car elle ou une vue à laquelle elle fait référence a été créée avec WITH CHECK OPTION et sa définition contient une clause TOP ou OFFSET.
SQL Server n'essaie pas d'être trop intelligent ici. Il va rejeter la modification même si la ligne que vous tentez d'insérer deviendrait une partie valide de la vue à ce stade. Par exemple, essayez d'ajouter une commande avec une date plus récente qui tomberait dans le top 5 à ce stade :
INSERT INTO dbo.RecentOrders(orderid, orderdate, shippeddate) VALUES(15, '20210904', '20210906');
La tentative d'insertion est toujours rejetée avec l'erreur suivante :
Msg 4427, Niveau 16, État 1, Ligne 254Impossible de mettre à jour la vue "dbo.RecentOrders" car elle ou une vue à laquelle elle fait référence a été créée avec WITH CHECK OPTION et sa définition contient une clause TOP ou OFFSET.
Essayez de mettre à jour une ligne dans la vue :
UPDATE dbo.RecentOrders SET shippeddate = DATEADD(day, 2, orderdate);
Dans ce cas, la tentative de modification est également rejetée avec l'erreur suivante :
Msg 4427, Niveau 16, État 1, Ligne 260Impossible de mettre à jour la vue "dbo.RecentOrders" car elle ou une vue à laquelle elle fait référence a été créée avec WITH CHECK OPTION et sa définition contient une clause TOP ou OFFSET.
Sachez que la définition d'une vue basée sur une requête avec TOP ou OFFSET-FETCH et CHECK OPTION entraînera l'absence de prise en charge des instructions INSERT et UPDATE via la vue.
Les suppressions via une telle vue sont prises en charge. Exécutez le code suivant pour supprimer les cinq commandes les plus récentes :
DELETE FROM dbo.RecentOrders;
La commande se termine avec succès.
Interroger la table :
SELECT * FROM dbo.Orders;
Vous obtenez la sortie suivante après la suppression des commandes avec les ID 8, 11, 12, 13 et 14.
orderid orderdate shippeddate ----------- ---------- ----------- 1 2021-08-02 2021-08-04 2 2021-08-02 2021-08-05 3 2021-08-04 2021-08-06 4 2021-08-26 NULL 5 2021-08-27 NULL 6 2021-08-05 2021-08-07 9 2021-08-01 2021-08-03 10 2021-08-02 2021-08-04
À ce stade, exécutez le code suivant pour le nettoyage avant d'exécuter les exemples de la section suivante :
DELETE FROM dbo.Orders WHERE orderid > 5; DROP VIEW IF EXISTS dbo.RecentOrders;
Joints
La mise à jour d'une vue qui joint plusieurs tables est prise en charge, tant qu'une seule des tables de base sous-jacentes est affectée par la modification.
Prenons l'exemple de la vue suivante joignant Orders et OrderDetails :
CREATE OR ALTER VIEW dbo.OrdersOrderDetails
AS
SELECT
O.orderid, O.orderdate, O.shippeddate,
OD.productid, OD.qty, OD.unitprice, OD.discount
FROM dbo.Orders AS O
INNER JOIN dbo.OrderDetails AS OD
ON O.orderid = OD.orderid;
GO Essayez d'insérer une ligne dans la vue, afin que les deux tables de base sous-jacentes soient affectées :
INSERT INTO dbo.OrdersOrderDetails(orderid, orderdate, shippeddate, productid, qty, unitprice, discount) VALUES(6, '20210828', NULL, 1001, 5, 10.50, 0.05);
Vous obtenez l'erreur suivante :
Msg 4405, Niveau 16, État 1, Ligne 306La vue ou la fonction 'dbo.OrdersOrderDetails' ne peut pas être mise à jour car la modification affecte plusieurs tables de base.
Essayez d'insérer une ligne dans la vue, afin que seule la table Commandes soit affectée :
INSERT INTO dbo.OrdersOrderDetails(orderid, orderdate, shippeddate) VALUES(6, '20210828', NULL);
Cette commande se termine avec succès et la ligne est insérée dans la table Orders sous-jacente.
Mais que se passe-t-il si vous souhaitez également pouvoir insérer une ligne via la vue dans la table OrderDetails ? Avec la définition de vue actuelle, cela est impossible (au lieu des déclencheurs mis à part) car la vue renvoie la colonne orderid de la table Orders et non de la table OrderDetails. Il suffit qu'une colonne de la table OrderDetails qui ne peut pas obtenir sa valeur automatiquement ne fasse pas partie de la vue pour empêcher les insertions dans OrderDetails via la vue. Bien sûr, vous pouvez toujours décider que la vue inclura à la fois l'ID de commande de Orders et l'ID de commande de OrderDetails. Dans ce cas, vous devrez attribuer aux deux colonnes des alias différents car l'en-tête de la table représentée par la vue doit avoir des noms de colonne uniques.
Utilisez le code suivant pour modifier la définition de la vue afin d'inclure les deux colonnes, en aliasant celle de Orders en tant que O_orderid et celle de OrderDetails en tant que OD_orderid :
CREATE OR ALTER VIEW dbo.OrdersOrderDetails
AS
SELECT
O.orderid AS O_orderid, O.orderdate, O.shippeddate,
OD.orderid AS OD_orderid,OD.productid, OD.qty, OD.unitprice, OD.discount
FROM dbo.Orders AS O
INNER JOIN dbo.OrderDetails AS OD
ON O.orderid = OD.orderid;
GO Vous pouvez désormais insérer des lignes via la vue dans Orders ou OrderDetails, selon la table d'où provient la liste de colonnes cible. Voici un exemple d'insertion de quelques lignes de commande associées à la commande 6 via la vue dans OrderDetails :
INSERT INTO dbo.OrdersOrderDetails(OD_orderid, productid, qty, unitprice, discount)
VALUES(6, 1001, 5, 10.50, 0.05),
(6, 1002, 5, 20.00, 0.05); Les lignes sont ajoutées avec succès.
Interroger la vue :
SELECT * FROM dbo.OrdersOrderDetails WHERE O_orderid = 6;
Vous obtenez le résultat suivant :
O_orderid orderdate shippeddate OD_orderid productid qty unitprice discount ----------- ---------- ----------- ----------- ----------- ---- ---------- --------- 6 2021-08-28 NULL 6 1001 5 10.50 0.0500 6 2021-08-28 NULL 6 1002 5 20.00 0.0500
Une restriction similaire s'applique aux instructions UPDATE via la vue. Les mises à jour sont autorisées tant qu'une seule table de base sous-jacente est affectée. Mais vous êtes autorisé à référencer des colonnes des deux côtés dans la déclaration tant qu'un seul côté est modifié.
Par exemple, l'instruction UPDATE suivante via la vue définit la date de commande de la ligne où l'ID de commande de la ligne de commande est 6 et l'ID de produit est 1001 sur "20210901 :"
UPDATE dbo.OrdersOrderDetails SET orderdate = '20210901' WHERE OD_orderid = 6 AND productid = 1001;
Nous appellerons cette déclaration la déclaration de mise à jour 1.
La mise à jour se termine avec succès avec le message suivant :
(1 row affected)
Ce qu'il est important de noter ici, c'est que l'instruction filtre par éléments de la table OrderDetails, mais la colonne modifiée orderdate provient de la table Orders. Ainsi, dans le plan que SQL Server construit pour cette instruction, il doit déterminer quelles commandes doivent être modifiées dans la table Orders. Le plan de cette déclaration est illustré à la figure 1.
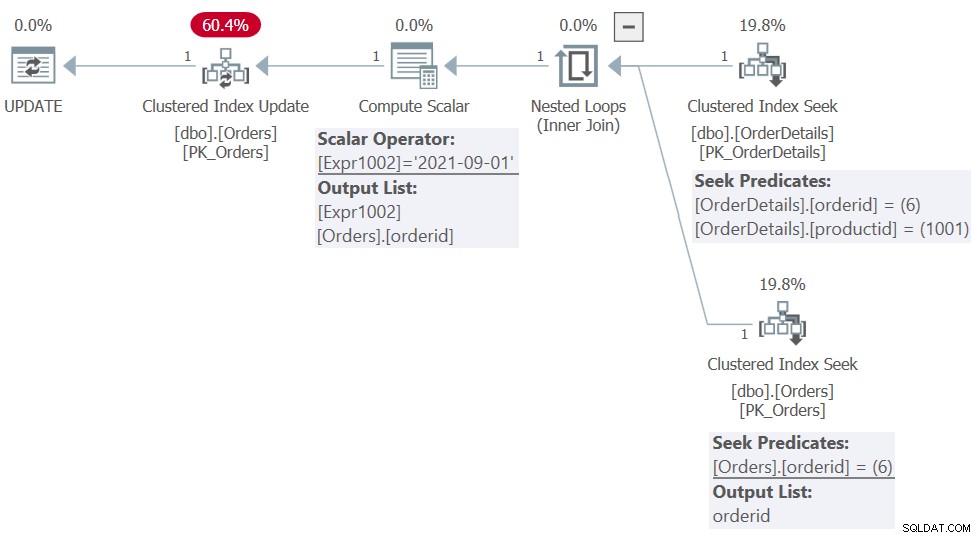 Figure 1 :Planifier l'instruction de mise à jour 1
Figure 1 :Planifier l'instruction de mise à jour 1
Vous pouvez voir comment le plan commence en filtrant le côté OrderDetails par orderid =6 et productid =1001, et le côté Orders par orderid =6, joignant les deux. Le résultat est une seule ligne. La seule partie pertinente à conserver de cette activité est de savoir quels ID de commande dans la table Commandes représentent les lignes qui doivent être mises à jour. Dans notre cas, il s'agit de la commande avec l'ID de commande 6. De plus, l'opérateur Compute Scalar prépare un membre appelé Expr1002 avec la valeur que l'instruction attribuera à la colonne orderdate de la commande cible. La dernière partie du plan avec l'opérateur Mise à jour de l'index clusterisé applique la mise à jour réelle à la ligne dans Commandes avec l'ID de commande 6, en définissant sa valeur de date de commande sur Expr1002.
Le point clé à souligner ici est qu'une seule ligne avec orderid 6 dans la table Orders a été mise à jour. Pourtant, cette ligne a deux correspondances dans le résultat de la jointure avec la table OrderDetails :une avec l'ID de produit 1001 (que la mise à jour d'origine a filtré) et une autre avec l'ID de produit 1002 (que la mise à jour d'origine n'a pas filtré). Interrogez la vue à ce stade, en filtrant toutes les lignes avec l'ID de commande 6 :
SELECT * FROM dbo.OrdersOrderDetails WHERE O_orderid = 6;
Vous obtenez le résultat suivant :
O_orderid orderdate shippeddate OD_orderid productid qty unitprice discount ----------- ---------- ----------- ----------- ----------- ---- ---------- --------- 6 2021-09-01 NULL 6 1001 5 10.50 0.0500 6 2021-09-01 NULL 6 1002 5 20.00 0.0500
Les deux lignes affichent la nouvelle date de commande, même si la mise à jour d'origine n'a filtré que la ligne avec l'ID de produit 1001. Encore une fois, cela devrait sembler parfaitement logique si vous savez que vous interagissez avec une vue qui joint deux tables de base sous les couvertures, mais peut sembler très étrange si vous ne vous en rendez pas compte.
Curieusement, SQL Server prend même en charge les mises à jour non déterministes où plusieurs lignes source (de OrderDetails dans notre cas) correspondent à une seule ligne cible (dans Orders dans notre cas). Théoriquement, une façon de traiter un tel cas serait de le rejeter. En effet, avec une instruction MERGE où plusieurs lignes source correspondent à une ligne cible, SQL Server rejette la tentative. Mais pas avec un UPDATE basé sur une jointure, que ce soit directement ou indirectement via une expression de table nommée comme une vue. SQL Server le gère simplement comme une mise à jour non déterministe.
Considérez l'exemple suivant, que nous appellerons Déclaration 2 :
UPDATE dbo.OrdersOrderDetails
SET orderdate = CASE
WHEN unitprice >= 20.00 THEN '20210902'
ELSE '20210903'
END
WHERE OD_orderid = 6; J'espère que vous me pardonnerez que c'est un exemple artificiel, mais il illustre ce point.
Il y a deux lignes qualifiées dans la vue, représentant deux lignes de ligne de commande source qualifiées de la table OrderDetails sous-jacente. Mais il n'y a qu'une seule ligne cible éligible dans la table Orders sous-jacente. De plus, dans une ligne source OrderDetails, l'expression CASE affectée renvoie une valeur ('20210902') et dans l'autre ligne source OrderDetails, elle renvoie une autre valeur ('20210903'). Que doit faire SQL Server dans ce cas ? Comme mentionné, une situation similaire avec l'instruction MERGE entraînerait une erreur, rejetant la tentative de modification. Pourtant, avec une instruction UPDATE, SQL Server lance simplement une pièce. Techniquement, cela se fait à l'aide d'une fonction d'agrégation interne appelée ANY.
Ainsi, notre mise à jour se termine avec succès, signalant 1 ligne affectée. Le plan de cette déclaration est illustré à la figure 2.
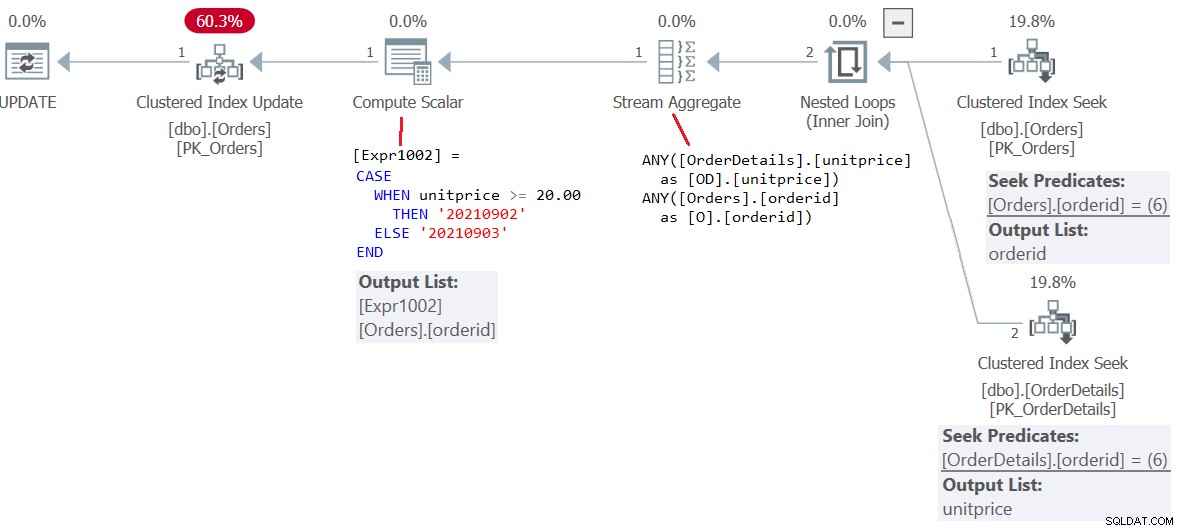
Figure 2 :Plan de mise à jour 2
Il y a deux lignes dans le résultat de la jointure. Ces deux lignes deviennent les lignes source de la mise à jour. Mais ensuite, un opérateur d'agrégation appliquant la fonction ANY sélectionne une (toute) valeur d'ID de commande et une (toute) valeur de prix unitaire à partir de ces lignes source. Les deux lignes source ont la même valeur orderid, donc le bon ordre sera modifié. Mais en fonction des valeurs de prix unitaire source que l'agrégat ANY finit par choisir, cela déterminera la valeur renvoyée par l'expression CASE, qui sera ensuite utilisée comme valeur de date de commande mise à jour dans la commande cible. Vous pouvez certainement voir un argument contre la prise en charge d'une telle mise à jour, mais elle est entièrement prise en charge dans SQL Server.
Interrogeons la vue pour voir le résultat de ce changement (il est maintenant temps de faire votre pari quant au résultat) :
SELECT * FROM dbo.OrdersOrderDetails WHERE O_orderid = 6;
J'ai obtenu le résultat suivant :
O_orderid orderdate shippeddate OD_orderid productid qty unitprice discount ----------- ---------- ----------- ----------- ----------- ---- ---------- --------- 6 2021-09-03 NULL 6 1001 5 10.50 0.0500 6 2021-09-03 NULL 6 1002 5 20.00 0.0500
Une seule des deux valeurs de prix unitaire source a été sélectionnée et utilisée pour déterminer la date de commande de la commande cible unique, mais lors de l'interrogation de la vue, la valeur de la date de commande est répétée pour les deux lignes de commande correspondantes. Comme vous pouvez vous en rendre compte, le résultat aurait tout aussi bien pu être l'autre date (2021-09-02) puisque le choix de la valeur du prix unitaire était non déterministe. Des trucs farfelus !
Ainsi, sous certaines conditions, les instructions INSERT et UPDATE sont autorisées via des vues qui joignent plusieurs tables sous-jacentes. Les suppressions, cependant, ne sont pas autorisées contre de telles vues. Comment SQL Server peut-il dire lequel des côtés est censé être la cible de la suppression ?
Voici une tentative d'appliquer une telle suppression via la vue :
DELETE FROM dbo.OrdersOrderDetails WHERE O_orderid = 6;
Cette tentative est rejetée avec l'erreur suivante :
Msg 4405, Niveau 16, État 1, Ligne 377La vue ou la fonction 'dbo.OrdersOrderDetails' ne peut pas être mise à jour car la modification affecte plusieurs tables de base.
À ce stade, exécutez le code suivant pour le nettoyage :
DELETE FROM dbo.OrderDetails WHERE orderid = 6; DELETE FROM dbo.Orders WHERE orderid = 6; DROP VIEW IF EXISTS dbo.OrdersOrderDetails;
Colonnes dérivées
Une autre restriction aux modifications via les vues concerne les colonnes dérivées. Si une colonne de vue est le résultat d'un calcul, SQL Server n'essaiera pas de désosser sa formule lorsque vous tenterez d'insérer ou de mettre à jour des données via la vue. Il rejettera plutôt ces modifications.
Considérez la vue suivante comme exemple :
CREATE OR ALTER VIEW dbo.OrderDetailsNetPrice AS SELECT orderid, productid, qty, unitprice * (1.0 - discount) AS netunitprice, discount FROM dbo.OrderDetails; GO
La vue calcule la colonne netunitprice en fonction des colonnes sous-jacentes de la table OrderDetails unitprice et discount.
Interroger la vue :
SELECT * FROM dbo.OrderDetailsNetPrice;
Vous obtenez le résultat suivant :
orderid productid qty netunitprice discount ----------- ----------- ----------- ------------- --------- 1 1001 5 9.975000 0.0500 1 1004 2 20.000000 0.0000 2 1003 1 47.691000 0.1000 3 1001 1 9.975000 0.0500 3 1003 2 49.491000 0.1000 4 1001 2 9.975000 0.0500 4 1004 1 20.300000 0.0000 4 1005 1 28.595000 0.0500 5 1003 5 54.990000 0.0000 5 1006 2 11.316000 0.0800
Essayez d'insérer une ligne dans la vue :
INSERT INTO dbo.OrderDetailsNetPrice(orderid, productid, qty, netunitprice, discount) VALUES(1, 1005, 1, 28.595, 0.05);
Théoriquement, vous pouvez déterminer quelle ligne doit être insérée dans la table OrderDetails sous-jacente en procédant à l'ingénierie inverse de la valeur de prix unitaire de la table de base à partir des valeurs de prix unitaire net et de remise de la vue. SQL Server ne tente pas une telle ingénierie inverse, mais rejette la tentative d'insertion avec l'erreur suivante :
Msg 4406, Niveau 16, État 1, Ligne 412La mise à jour ou l'insertion de la vue ou de la fonction 'dbo.OrderDetailsNetPrice' a échoué car elle contient un champ dérivé ou constant.
Essayez d'omettre la colonne calculée de l'insertion :
INSERT INTO dbo.OrderDetailsNetPrice(orderid, productid, qty, discount) VALUES(1, 1005, 1, 0.05);
Nous revenons maintenant à l'exigence selon laquelle toutes les colonnes de la table sous-jacente qui n'obtiennent pas leurs valeurs automatiquement doivent faire partie de l'insertion, et ici il nous manque la colonne de prix unitaire. Cette insertion échoue avec l'erreur suivante :
Msg 515, Niveau 16, État 2, Ligne 421Impossible d'insérer la valeur NULL dans la colonne 'prix unitaire', table 'tempdb.dbo.OrderDetails' ; la colonne n'autorise pas les valeurs nulles. L'insertion échoue.
Si vous souhaitez prendre en charge les insertions via la vue, vous avez essentiellement deux options. One is to include the unitprice column in the view definition. Another is to create an instead of trigger on the view where you handle the reverse engineering logic yourself.
At this point, run the following code for cleanup:
DROP VIEW IF EXISTS dbo.OrderDetailsNetPrice;
Set Operators
As mentioned in the last section, you’re not allowed to modify a column in a view if the column is a result of a computation. The columns modified in the view using INSERT and UPDATE statements have to map directly to the underlying base table’s columns with no manipulation. In the list of restrictions to modifications through views, T-SQL’s documentation specifies that columns formed by using the set operators UNION, UNION ALL, EXCEPT, and INTERSECT amount to a computation and therefore are also not updatable.
One exception to this restriction is when using the UNION ALL operator to combine rows from different tables to form an updatable partitioned view. That’s a big topic in its own right. I’ll cover it briefly here to give you a sense, and you can investigate it further if you like in the product’s documentation.
Partitioned views predates table and index partitioning in SQL Server. The basic idea is that you can store disjoint subsets of rows in different base tables and have a view that unifies the rows from the different tables using a UNION ALL operator. If certain requirements are met, you can not only read the data through the view but also modify it through the view. SQL Server will figure out how to direct the modifications through the view to the right underlying tables.
The requirements for supporting modifications through such a view include having a partitioning column. Each of the underlying tables needs to have a CHECK constraint based on the partitioning column that defines a disjoint subset of rows. Also, the partitioning column needs to be part of the table’s primary key, meaning it cannot allow NULLs.
Consider the Orders table you used earlier in this article. Suppose that instead of holding all orders in one table, you want to store unshipped orders in one table (called UnshippedOrders) and shipped orders in another table (called ShippedOrders). You also want to create a view called Orders combining the rows from both tables. You want the view to be updatable.
Let’s start by removing any existing objects before creating the new ones:
DROP VIEW IF EXISTS dbo.Orders; DROP TABLE IF EXISTS dbo.OrderDetails, dbo.Orders; DROP TABLE IF EXISTS dbo.ShippedOrders, dbo.UnshippedOrders;
The partitioning column in our example is the shippeddate column. Our first obstacle is that we want to represent unshipped orders with a NULL shippeddate, but the partitioning column cannot allow NULLs. One possible workaround is to decide on some specific future date to represent unshipped orders. For example, the maximum supported date December 31st, 9999. Then you could have a CHECK constraint in the UnshippedOrders table checking that the shipped date is this specific one, and a CHECK constraint in the ShippedOrders table checking that the shipped date is before this one. This will meet the requirement for disjoint sets of rows.
Another obstacle is that the partitioning column needs to be part of the primary key. Originally the primary key was based on the orderid column alone. Now it will need to be extended to be based on (orderid, shippeddate). You will probably still want to enforce uniqueness based on orderid alone. To achieve this, you’ll need to add a unique constraint based on orderid.
With all this in mind, here are the definitions of the ShippedOrders and UnshippedOrders tables:
CREATE TABLE dbo.ShippedOrders
(
orderid INT NOT NULL,
orderdate DATE NOT NULL,
shippeddate DATE NOT NULL,
CONSTRAINT PK_ShippedOrders PRIMARY KEY(orderid, shippeddate),
CONSTRAINT UNQ_ShippedOrders_orderid UNIQUE(orderid),
CONSTRAINT CHK_ShippedOrders_shippeddate CHECK(shippeddate < '99991231')
);
CREATE TABLE dbo.UnshippedOrders
(
orderid INT NOT NULL,
orderdate DATE NOT NULL,
shippeddate DATE NOT NULL DEFAULT('99991231'),
CONSTRAINT PK_UnshippedOrders PRIMARY KEY(orderid, shippeddate),
CONSTRAINT UNQ_UnshippedOrders_orderid UNIQUE(orderid),
CONSTRAINT CHK_UnshippedOrders_shippeddate CHECK(shippeddate = '99991231')
); You then create the Orders view, unifying the rows from the two tables using the UNION ALL operator, like so:
CREATE OR ALTER VIEW dbo.Orders AS SELECT orderid, orderdate, shippeddate FROM dbo.ShippedOrders UNION ALL SELECT orderid, orderdate, shippeddate FROM dbo.UnshippedOrders; GO
Since this view meets all requirements for updatability, you can insert, update, and delete rows through the view. SQL Server will direct the changes to the right underlying tables. As an example, the following statement inserts a few rows, including both shipped and unshipped orders:
INSERT INTO dbo.Orders(orderid, orderdate, shippeddate)
VALUES(1, '20210802', '20210804'),
(2, '20210802', '20210805'),
(3, '20210804', '20210806'),
(4, '20210826', '99991231'),
(5, '20210827', '99991231'); The plan for this code is shown in Figure 3.
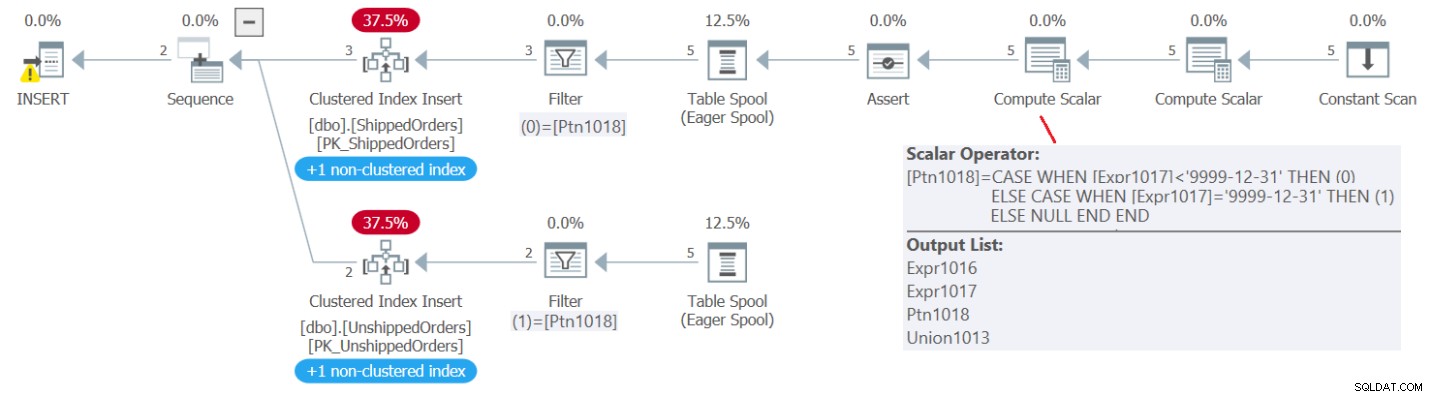 Figure 3:Plan for INSERT statement against partitioned view
Figure 3:Plan for INSERT statement against partitioned view
As you can see, a Compute Scalar operator computes for each source row a member called Ptn1018. This member is set to 0 for shipped orders (shippeddate <'9999-12-31') and 1 for unshipped orders (shippeddate ='9999-12-31'). The rows are spooled along with the member Ptn1018, and then the spool is read twice. Once filtering the rows where Ptn1018 =0, inserting those into the underlying ShippedOrders table, and another time filtering the rows where Ptn1018 =1, inserting those into the underlying UnshippedOrders table.If this seems like an attractive option, consider it very carefully. Remember this is an old feature, predating table and index partitioning. There are many requirements, restrictions, and complications, including optimization complications, integrity enforcement complications, and others. As mentioned, here I just wanted to cover it briefly to describe the exception to the modification restriction involving set operators.When you’re done, run the following code for cleanup:
DROP VIEW IF EXISTS dbo.Orders; DROP TABLE IF EXISTS dbo.OrderDetails, dbo.Orders; DROP TABLE IF EXISTS dbo.ShippedOrders, dbo.UnshippedOrders;
Résumé
When I started the coverage of views, one of the first things I explained was that a view is a table. You can read data from a view and you can modify data through a view. But you need to understand that modifications through the view are restricted in a few ways, and the outcome of such modifications could be surprising in some cases.
Using the CHECK OPTION, you’re only allowed to update and insert rows through the view as long as the result rows are considered a valid part of the view. This means unlike a CHECK constraint in a table, the CHECK OPTION rejects changes where the inner query’s filter evaluates to unknown (when a NULL is involved). You’re not allowed to insert or update rows through a view if it’s defined with the CHECK OPTION and uses the TOP or OFFSET-FETCH filters. But you’re allowed to delete rows through such a view.
If a view joins multiple base tables, inserts and updates through the view are allowed provided that only one underlying base table is affected. Oddly, if a modification of a single target row involves multiple related source rows, the modification is allowed but is processed as a nondeterministic one. In such a case, SQL Server uses the internal ANY aggregate the pick a single value from the source rows.
You cannot update or insert rows through a view where at least one of the updated columns is a derived one resulting from a computation. The same applies when using a set operator, with an exception when using the UNION ALL operator to create an updatable partitioned view.