L'année dernière, Andy Mallon a blogué sur la migration d'une colonne de int en bigint sans temps d'arrêt. (Pourquoi ce n'est pas une opération de métadonnées uniquement dans les versions modernes de SQL Server, cela me dépasse, mais c'est un autre article.)
Habituellement, lorsque nous traitons ce problème, ce sont des tables larges et massives (à la fois en nombre de lignes et en taille), et la colonne que nous devons modifier est la seule/principale colonne de la clé de clustering. Il y a généralement d'autres complications impliquées également - contraintes de clé étrangère entrante, beaucoup d'index non clusterisés et une base de données occupée qui est ultra-sensible à l'activité des journaux (car elle est impliquée dans le suivi des modifications, la réplication, les groupes de disponibilité ou les trois ).
Pour cette raison, nous devons adopter une approche comme celle décrite par Andy, où nous construisons une table fantôme avec le nouveau schéma, créons des déclencheurs pour garder les deux copies synchronisées, puis regroupons/remplissons au rythme de cette équipe jusqu'à ce qu'ils soient prêts à échanger dans la copie comme la vraie affaire.
Mais je suis paresseux !
Il y a des cas où vous pouvez changer la colonne directement, si vous pouvez vous permettre une petite fenêtre de temps d'arrêt/blocage, et cela devient une opération beaucoup plus simple. La semaine dernière, un tel cas est apparu, avec une table de plus de 1 To, mais seulement 100 000 lignes. Presque toutes les données étaient hors ligne (LOB), ils pouvaient se permettre une petite fenêtre de temps d'arrêt si nécessaire, et ils prévoyaient de désactiver le suivi des modifications et de le reconfigurer de toute façon. Convaincu que la recréation du PK en cluster n'aurait pas à toucher (beaucoup) aux données LOB, j'ai suggéré que cela pourrait être un cas où nous pouvons simplement appliquer le changement directement.
Dans un scénario isolé (pas de clés étrangères entrantes, pas d'index supplémentaires, pas d'activités dépendant du lecteur de journal et pas de soucis de concurrence), j'ai lancé quelques tests pour voir, dans le vide, ce que ce changement nécessiterait en termes de durée et l'impact sur le journal des transactions. La principale question à laquelle je ne savais pas répondre à l'avance était :"Quel est le coût supplémentaire de la mise à jour des tables sur place lorsqu'il existe de grandes quantités de données non clés ?"
Je vais essayer de rassembler beaucoup de choses dans un seul article ici. J'ai fait beaucoup de tests, et tout est lié, même si tous les scénarios de test ne s'appliquent pas à vous. Veuillez patienter avec moi.
Les tableaux
J'ai créé 6 tables, dont une ligne de base qui seulement avait la colonne clé, une table avec 4K stockés dans la ligne, puis quatre tables chacune avec une colonne varchar(max) remplie avec différentes quantités de données de chaîne (4K, 16K, 64K et 256K).
CREATE TABLE dbo.withJustId( id int NOT NULL, CONTRAINTE pk_withJustId PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withoutLob( id int NOT NULL, extradata varchar(4000) NOT NULL DEFAULT (REPLICATE('x', 4000)), CONTRAINTE pk_withoutLob PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob004( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE('x', 4000)), CONTRAINTE pk_withLob004 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob016( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 16000)), CONSTRAINT pk_withLob016 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob064 ( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 64000)), CONSTRAINT pk_withLob064 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob256 ( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 256000)), CONSTRAINT pk_withLob256 PRIMARY KEY CLUSTERED (id));
J'ai rempli chacun avec 100 000 lignes :
INSERT dbo.withJustId (id) SELECT TOP (100000) id =ROW_NUMBER() OVER (ORDER BY c1.name) FROM sys.all_columns AS c1 CROSS JOIN sys.all_objects; INSERT dbo.withLob (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob004 (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob016 (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob064 (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob256 (id) SELECT id FROM dbo.withJustId;
Je reconnais que ce qui précède est irréaliste ; combien de fois avons-nous une table qui est juste un identifiant + des données LOB ? J'ai refait les tests avec ces quatre colonnes supplémentaires pour donner aux pages de données non LOB un peu plus de substance réelle :
fill1 char(320) NOT NULL DEFAULT ('x'), count1 int NOT NULL DEFAULT (0), count2 int NOT NULL DEFAULT (0), dt datetime2 NOT NULL DEFAULT sysutcdatetime(),
Ces tables ne sont que légèrement plus grandes en termes de taille globale, mais l'augmentation proportionnelle de la quantité de données non LOB (non illustrées dans ce graphique) est la différence majeure mais cachée :
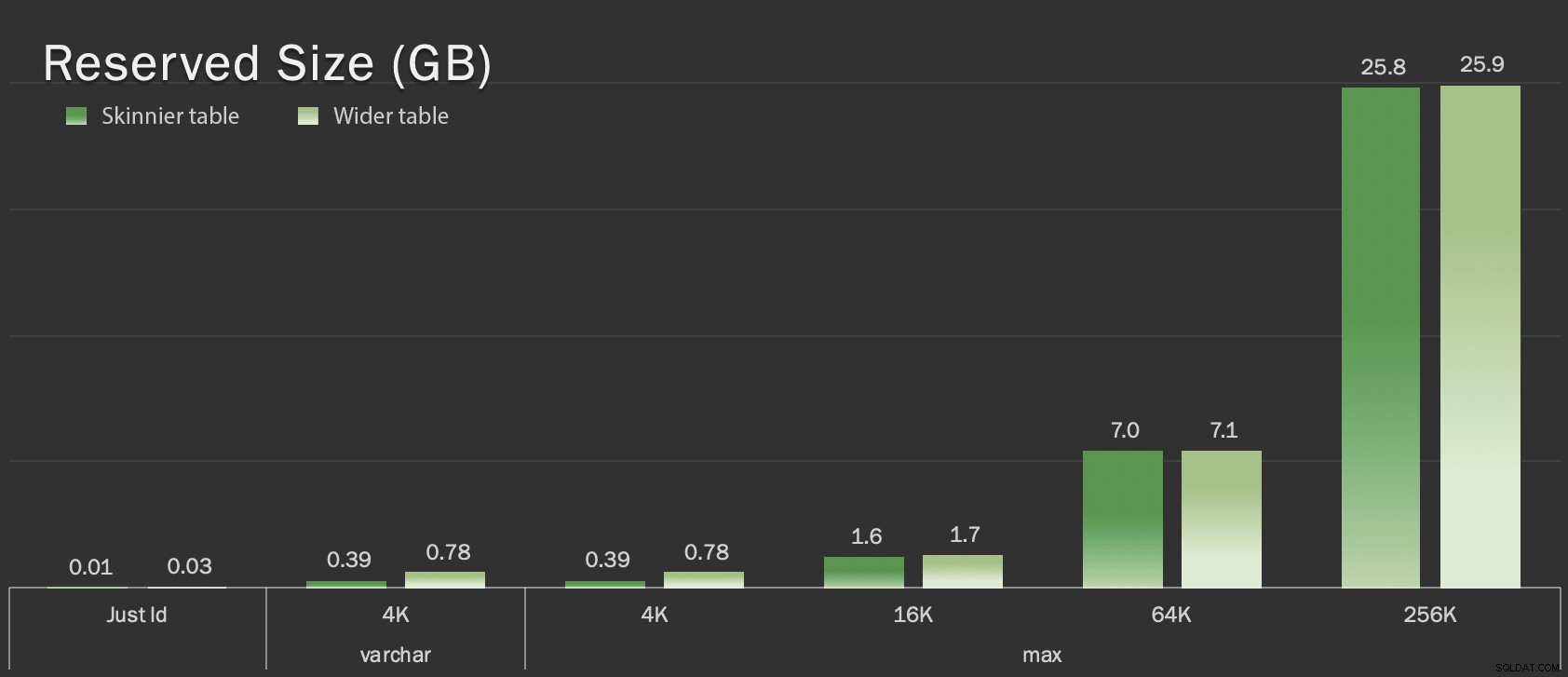 Taille réservée des tables, en Go
Taille réservée des tables, en Go
Les épreuves
Ensuite, j'ai chronométré et collecté des données de journal pour chacune de ces opérations (avec et sans ONLINE = ON ) par rapport à chaque variante du tableau :
ALTER TABLE dbo. DROP CONSTRAINT pk_ ; ALTER TABLE dbo. ALTER COLUMN id bigint NOT NULL ; -- AVEC (EN LIGNE =ON); ALTER TABLE dbo. ADD CONSTRAINT pk_ PRIMARY KEY CLUSTERED (id);
En réalité, j'ai utilisé du SQL dynamique pour générer tous ces tests, afin de ne pas manipuler manuellement les scripts avant chaque test.
Dans un autre article, je partagerai le SQL dynamique que j'ai utilisé pour générer ces tests et collecterai les temps à chaque étape.
À titre de comparaison, j'ai également testé la méthode d'Andy (mais sans traitement par lots, et uniquement sur la version allégée du tableau) :
CREATE TABLE dbo._copy ( id bigint NOT NULL -- <, colonne extradata le cas échéant> CONSTRAINT pk_copy_ PRIMARY KEY CLUSTERED (id)); INSERT dbo._copy SELECT * FROM dbo. ; EXEC sys.sp_rename N'dbo.', N'dbo._old', N'OBJECT';EXEC sys.sp_rename N'dbo._copy', N'dbo.' , N'OBJECT';
J'ai sauté les tables plus larges ici; Je ne voulais pas introduire la complexité du codage et de la mesure des opérations par lots. Le problème évident ici est que, contrairement à la modification de la colonne sur place, avec la méthode shadow, vous devez copier chaque octet de ces données LOB. Le traitement par lots peut minimiser l'impact important d'essayer de le faire en une seule transaction, mais tout ce remaniement devra éventuellement être refait en aval. Le traitement par lots à la source ne permet pas de contrôler complètement l'ampleur de la douleur à la destination.
Les résultats
Les premiers résultats que je vais montrer ne sont que les durées moyennes des modifications sur place, pour les 12 configurations de table, et avec et sans ONLINE = ON :
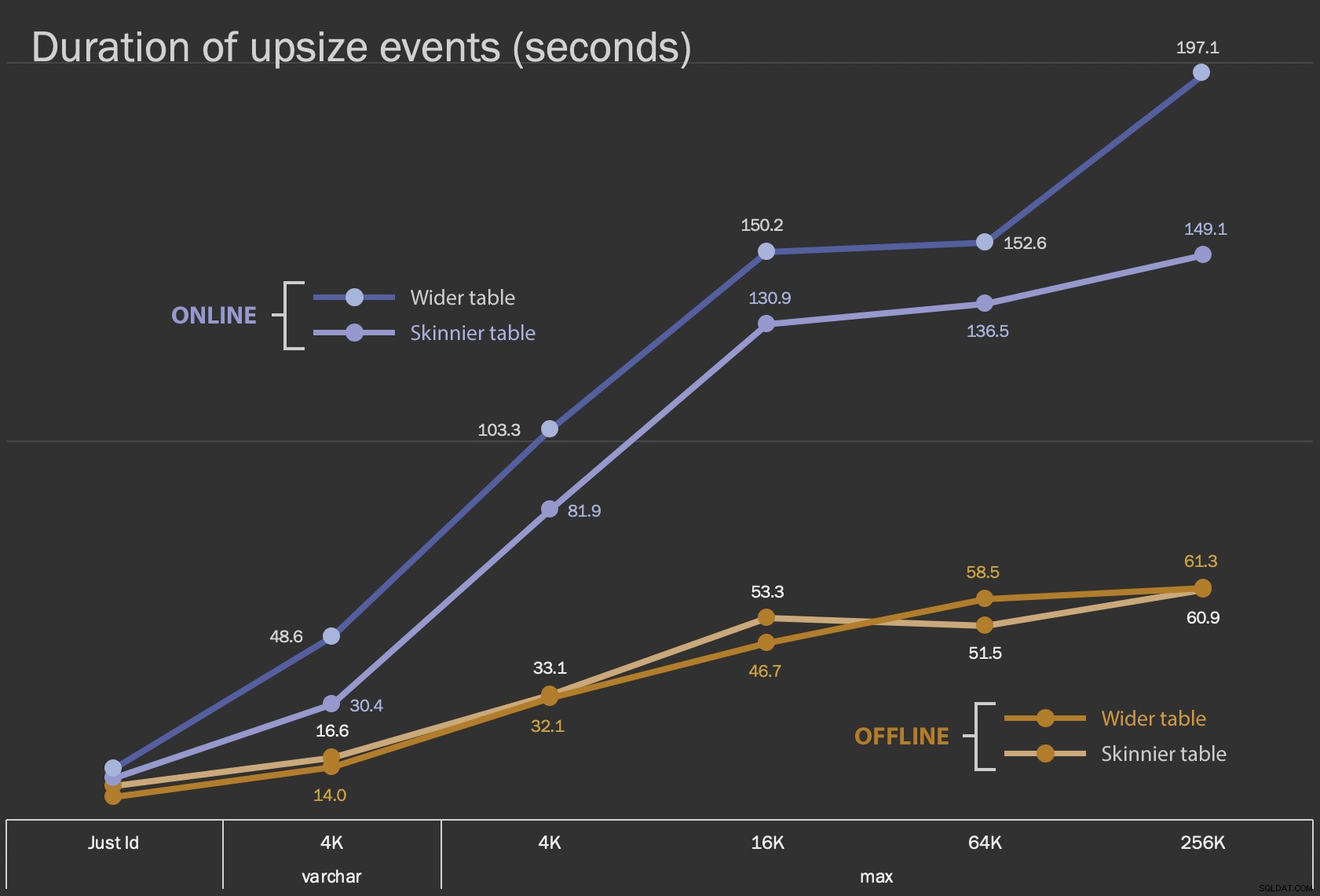 Durée, en secondes, de modification de la colonne sur place
Durée, en secondes, de modification de la colonne sur place
L'exécution de cette opération en ligne prend plus de temps (200 secondes dans le pire des cas), mais ne bloque pas les utilisateurs. Il semble augmenter parallèlement à la taille, mais pas de manière tout à fait linéaire. L'exécution de cette opération hors ligne provoque un blocage, mais elle est beaucoup plus rapide et ne change pas aussi radicalement que la table s'agrandit (même à la plus grande taille, cela s'est quand même produit en une minute environ).
Il est difficile de comparer ces opérations sur place à l'opération d'échange et de suppression à l'aide d'un graphique linéaire en raison de la différence d'échelle massive. Au lieu de cela, je vais montrer un graphique à barres horizontales pour la durée impliquée avec chaque configuration de table. Lorsque la recréation sera plus rapide, je peindrai l'arrière-plan de cette ligne en vert; lorsqu'il est plus lent (ou se situe entre les méthodes hors ligne et en ligne), je n'en ai probablement pas besoin, mais je peindrai l'arrière-plan de cette ligne en rouge.
| Taille LOB | Approche | Configuration du tableau | Durée (secondes) | ||
|---|---|---|---|
| Just Id | ALTER Hors ligne | Tableau plus fin (10 Mo) | 8.8 |
| Tableau plus large (30 Mo) | 6.3 | ||
| ALTER en ligne | Tableau plus fin | 11.0 | |
| Tableau plus large | 13.6 | ||
| Recréer | Tableau plus fin | 3.4 | |
| varchar 4K | Hors ligne | Tableau plus mince (390 Mo) | 16.6 |
| Tableau plus large (780 Mo) | 14.0 | ||
| En ligne | Tableau plus fin | 30.4 | |
| Tableau plus large | 48.6 | ||
| Recréer | Tableau plus fin | 1 290,0 | |
| max 4k | Hors ligne | Tableau plus mince (390 Mo) | 33.1 |
| Tableau plus large (780 Mo) | 32.1 | ||
| En ligne | Tableau plus fin | 81.9 | |
| Tableau plus large | 103.3 | ||
| Recréer | Tableau plus fin | 28.9 | |
| max 16k | Hors ligne | Tableau plus fin (1,6 Go) | 53.3 |
| Tableau plus large (1,7 Go) | 46.7 | ||
| En ligne | Tableau plus fin | 130,9 | |
| Tableau plus large | 150.2 | ||
| Recréer | Tableau plus fin | 81.8 | |
| max 64k | Hors ligne | Tableau plus fin (7,0 Go) | 51.5 |
| Tableau plus large (7,1 Go) | 58,5 | ||
| En ligne | Tableau plus fin | 136,5 | |
| Tableau plus large | 152.6 | ||
| Recréer | Tableau plus fin | 226.5 | |
| max 256k | Hors ligne | Tableau plus fin (25,8 Go) | 60.9 |
| Tableau plus large (25,9 Go) | 61.3 | ||
| En ligne | Tableau plus fin | 149.1 | |
| Tableau plus large | 197.1 | ||
| Recréer | Tableau plus fin | 1 576,7 | |
C'est une secousse injuste à la méthode d'Andy, car - dans le monde réel - vous n'effectueriez pas toute cette opération en une seule fois. Je n'ai pas montré l'utilisation du journal des transactions ici par souci de brièveté, mais il serait également plus facile de contrôler cela via le traitement par lots dans une opération côte à côte. Bien que son approche nécessite plus de travail en amont, elle est beaucoup plus sûre en termes de temps d'arrêt et/ou de blocage. Mais vous pouvez voir dans les cas où vous avez beaucoup de données hors ligne et pouvez vous permettre une brève panne, que modifier directement la colonne est beaucoup moins douloureux. "Trop grand pour changer sur place" est subjectif et peut produire des résultats différents selon ce que "grand" signifie. Avant de s'engager dans une approche, il peut être judicieux de tester la modification par rapport à une copie raisonnable, car l'opération en place peut représenter un compromis acceptable.
Conclusion
Je n'ai pas écrit ceci pour me disputer avec Andy. L'approche du message d'origine est solide, fiable à 100% et nous l'utilisons tout le temps. Cependant, lorsque la force brute est valorisée par rapport à la précision chirurgicale, et surtout si vous pouvez prendre une tranche de temps d'arrêt, l'approche plus simple peut être utile pour certaines formes de table.