Cet article est le quatrième volet d'une série sur les bogues, les pièges et les meilleures pratiques de T-SQL. Auparavant, j'ai couvert le déterminisme, les sous-requêtes et les jointures. L'article de ce mois-ci se concentre sur les bogues, les pièges et les meilleures pratiques liés aux fonctions de fenêtre. Merci Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man et Paul White pour avoir proposé vos idées !
Dans mes exemples, j'utiliserai un exemple de base de données appelé TSQLV5. Vous pouvez trouver le script qui crée et remplit cette base de données ici, et son diagramme ER ici.
Il existe deux pièges courants impliquant les fonctions de fenêtre, qui sont tous deux le résultat de valeurs par défaut implicites contre-intuitives imposées par la norme SQL. Un écueil concerne les calculs de totaux cumulés où vous obtenez un cadre de fenêtre avec l'option implicite RANGE. Un autre écueil est quelque peu lié, mais a des conséquences plus graves, impliquant une définition de cadre implicite pour les fonctions FIRST_VALUE et LAST_VALUE.
Cadre de fenêtre avec option RANGE implicite
Notre premier écueil implique le calcul des totaux cumulés à l'aide d'une fonction de fenêtre d'agrégation, où vous spécifiez explicitement la clause d'ordre de fenêtre, mais vous ne spécifiez pas explicitement l'unité de cadre de fenêtre (ROWS ou RANGE) et son étendue de cadre de fenêtre associée, par exemple, ROWS PRÉCÉDENT SANS LIMITE. La valeur par défaut implicite est contre-intuitive et ses conséquences pourraient être surprenantes et douloureuses.
Pour illustrer cet écueil, je vais utiliser un tableau appelé Transactions contenant deux millions de transactions de compte bancaire avec des crédits (valeurs positives) et des débits (valeurs négatives). Exécutez le code suivant pour créer la table Transactions et la remplir avec des exemples de données :
SET NOCOUNT ON ; UTILISEZ TSQLV5 ; -- https://tsql.solidq.com/SampleDatabases/TSQLV5.zip SUPPRIMER LA TABLE SI EXISTE dbo.Transactions; CREATE TABLE dbo.Transactions ( actid INT NOT NULL, tranid INT NOT NULL, val MONEY NOT NULL, CONSTRAINT PK_Transactions PRIMARY KEY(actid, tranid) -- crée un index POC ); DECLARE @num_partitions AS INT =100, @rows_per_partition AS INT =20000 ; INSERT INTO dbo.Transactions WITH (TABLOCK) (actid, tranid, val) SELECT NP.n, RPP.n, (ABS(CHECKSUM(NEWID())%2)*2-1) * (1 + ABS(CHECKSUM( NEWID())%5)) FROM dbo.GetNums(1, @num_partitions) AS NP CROSS JOIN dbo.GetNums(1, @rows_per_partition) AS RPP ;
Notre écueil a à la fois un côté logique avec un bogue logique potentiel et un côté performance avec une pénalité de performance. La pénalité de performance n'est pertinente que lorsque la fonction de fenêtre est optimisée avec des opérateurs de traitement en mode ligne. SQL Server 2016 introduit l'opérateur Window Aggregate en mode batch, qui supprime la partie pénalisante en termes de performances de l'écueil, mais avant SQL Server 2019, cet opérateur n'est utilisé que si vous avez un index columnstore présent sur les données. SQL Server 2019 introduit le mode batch sur la prise en charge du rowstore, de sorte que vous pouvez obtenir un traitement en mode batch même s'il n'y a pas d'index columnstore présents sur les données. Pour illustrer la dégradation des performances avec le traitement en mode ligne, si vous exécutez les exemples de code de cet article sur SQL Server 2019 ou version ultérieure, ou sur Azure SQL Database, utilisez le code suivant pour définir le niveau de compatibilité de la base de données sur 140 afin que pour ne pas encore activer le mode batch sur le magasin de lignes :
ALTER DATABASE TSQLV5 SET COMPATIBILITY_LEVEL =140 ;
Utilisez le code suivant pour activer les statistiques de temps et d'E/S dans la session :
SET STATISTICS TIME, IO ON ;
Pour éviter d'attendre que deux millions de lignes soient imprimées dans SSMS, je suggère d'exécuter les exemples de code de cette section avec l'option Supprimer les résultats après l'exécution activée (allez dans Options de requête, Résultats, Grille et cochez Supprimer les résultats après l'exécution).
Avant d'arriver au piège, considérons la requête suivante (appelez-la Requête 1) qui calcule le solde du compte bancaire après chaque transaction en appliquant un total cumulé à l'aide d'une fonction d'agrégation de fenêtre avec une spécification de cadre explicite :
SELECT actid, tranid, val, SUM(val) OVER( PARTITION BY actid ORDER BY tranid ROWS UNBOUNDED PRECEDING ) AS balance FROM dbo.Transactions;
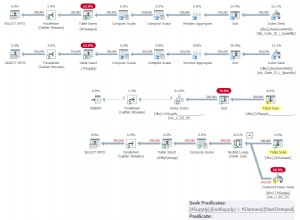
Le plan de cette requête, utilisant le traitement en mode ligne, est illustré à la figure 1.
 Figure 1 :Plan pour la requête 1, traitement en mode ligne
Figure 1 :Plan pour la requête 1, traitement en mode ligne
Le plan extrait les données pré-ordonnées de l'index clusterisé de la table. Ensuite, il utilise les opérateurs Segment et Sequence Project pour calculer les numéros de ligne afin de déterminer quelles lignes appartiennent au cadre de la ligne actuelle. Ensuite, il utilise les opérateurs Segment, Window Spool et Stream Aggregate pour calculer la fonction d'agrégation de fenêtre. L'opérateur Window Spool est utilisé pour spouler les lignes de trame qui doivent ensuite être agrégées. Sans aucune optimisation spéciale, le plan aurait dû écrire par ligne toutes ses lignes de trame applicables dans le spool, puis les agréger. Cela aurait entraîné une complexité quadratique ou N. La bonne nouvelle est que lorsque le cadre commence par UNBOUNDED PRECEDING, SQL Server identifie le cas comme une voie rapide cas, dans lequel il prend simplement le total cumulé de la ligne précédente et ajoute la valeur de la ligne actuelle pour calculer le total cumulé de la ligne actuelle, ce qui entraîne une mise à l'échelle linéaire. Dans ce mode accéléré, le plan n'écrit que deux lignes dans le spool par ligne d'entrée :une avec l'agrégat et l'autre avec le détail.
Le Window Spool peut être implémenté physiquement de deux manières. Soit en tant que spool rapide en mémoire spécialement conçu pour les fonctions de fenêtre, soit en tant que spool lent sur disque, qui est essentiellement une table temporaire dans tempdb. Si le nombre de lignes qui doivent être écrites dans le spool par ligne sous-jacente peut dépasser 10 000, ou si SQL Server ne peut pas prédire le nombre, il utilisera le spool sur disque le plus lent. Dans notre plan de requête, nous avons exactement deux lignes écrites dans le spool par ligne sous-jacente, donc SQL Server utilise le spool en mémoire. Malheureusement, il n'y a aucun moyen de savoir à partir du plan quel type de bobine vous obtenez. Il y a deux façons de comprendre cela. L'une consiste à utiliser un événement étendu appelé window_spool_ondisk_warning. Une autre option consiste à activer STATISTICS IO et à vérifier le nombre de lectures logiques signalées pour une table appelée Worktable. Un nombre supérieur à zéro signifie que vous avez obtenu la bobine sur disque. Zéro signifie que vous avez le spool en mémoire. Voici les statistiques d'E/S pour notre requête :
La logique de la table 'Table de travail' lit :0. La logique de la table 'Transactions' lit :6208.Comme vous pouvez le voir, nous avons utilisé le spool en mémoire. C'est généralement le cas lorsque vous utilisez l'unité de cadre de fenêtre ROWS avec UNBOUNDED PRECEDING comme premier délimiteur.
Voici les statistiques de temps pour notre requête :
Temps CPU :4297 ms, temps écoulé :4441 ms.Il a fallu environ 4,5 secondes pour terminer cette requête sur ma machine, les résultats étant ignorés.
Maintenant pour la prise. Si vous utilisez l'option RANGE au lieu de ROWS, avec les mêmes délimiteurs, il peut y avoir une légère différence de sens, mais une grande différence de performances en mode ligne. La différence de sens n'est pertinente que si vous n'avez pas de commande totale, c'est-à-dire si vous commandez par quelque chose qui n'est pas unique. L'option ROWS UNBOUNDED PRECEDING s'arrête à la ligne actuelle, donc en cas d'égalité, le calcul est non déterministe. Inversement, l'option RANGE UNBOUNDED PRECEDING regarde en avant de la ligne actuelle et inclut les liens s'ils sont présents. Elle utilise une logique similaire à l'option TOP WITH TIES. Lorsque vous avez une commande totale, c'est-à-dire que vous commandez par quelque chose d'unique, il n'y a pas de liens à inclure, et donc ROWS et RANGE deviennent logiquement équivalents dans un tel cas. Le problème est que lorsque vous utilisez RANGE, SQL Server utilise toujours le spool sur disque sous le traitement en mode ligne car lors du traitement d'une ligne donnée, il ne peut pas prédire combien de lignes supplémentaires seront incluses. Cela peut avoir de graves conséquences sur les performances.
Considérez la requête suivante (appelez-la Requête 2), qui est identique à la requête 1, en utilisant uniquement l'option RANGE au lieu de ROWS :
SELECT actid, tranid, val, SUM(val) OVER( PARTITION BY actid ORDER BY tranid RANGE UNBOUNDED PRECEDING ) AS balance FROM dbo.Transactions;
Le plan de cette requête est illustré à la figure 2.
 Figure 2 :Plan pour la requête 2, traitement en mode ligne
Figure 2 :Plan pour la requête 2, traitement en mode ligne
La requête 2 est logiquement équivalente à la requête 1 car nous avons la commande totale; cependant, comme il utilise RANGE, il est optimisé avec le spool sur disque. Observez que dans le plan de la requête 2, le spool de fenêtre a le même aspect que dans le plan de la requête 1, et les coûts estimés sont les mêmes.
Voici les statistiques de temps et d'E/S pour l'exécution de la requête 2 :
Temps CPU :19 515 ms, temps écoulé :20 201 ms.Lectures logiques de la table "Table de travail" :12044701. Lectures logiques de la table "Transactions" :6208.
Notez le grand nombre de lectures logiques par rapport à Worktable, indiquant que vous avez obtenu le spool sur disque. Le temps d'exécution est plus de quatre fois plus long que pour la requête 1.
Si vous pensez que si tel est le cas, vous éviterez simplement d'utiliser l'option RANGE, à moins que vous n'ayez vraiment besoin d'inclure des liens, c'est une bonne idée. Le problème est que si vous utilisez une fonction de fenêtre qui prend en charge un cadre (agrégats, FIRST_VALUE, LAST_VALUE) avec une clause d'ordre de fenêtre explicite, mais aucune mention de l'unité de cadre de fenêtre et de son étendue associée, vous obtenez RANGE UNBOUNDED PRECEDING par défaut . Cette valeur par défaut est dictée par la norme SQL, et la norme l'a choisie car elle préfère généralement des options plus déterministes comme valeurs par défaut. La requête suivante (appelez-la Requête 3) est un exemple qui tombe dans ce piège :
SELECT actid, tranid, val, SUM(val) OVER( PARTITION BY actid ORDER BY tranid ) AS balance FROM dbo.Transactions;
Souvent, les gens écrivent comme ceci en supposant qu'ils obtiennent ROWS UNBOUNDED PRECEDING par défaut, sans se rendre compte qu'ils obtiennent en fait RANGE UNBOUNDED PRECEDING. Le fait est que puisque la fonction utilise l'ordre total, vous obtenez le même résultat qu'avec ROWS, vous ne pouvez donc pas dire qu'il y a un problème à partir du résultat. Mais les chiffres de performance que vous obtiendrez sont les mêmes que pour la requête 2. Je vois des gens tomber tout le temps dans ce piège.
La meilleure pratique pour éviter ce problème est dans les cas où vous utilisez une fonction de fenêtre avec un cadre, soyez explicite sur l'unité de cadre de fenêtre et son étendue, et préférez généralement ROWS. Réservez l'utilisation de RANGE uniquement aux cas où la commande n'est pas unique et où vous devez inclure des liens.
Considérez la requête suivante illustrant un cas où il existe une différence conceptuelle entre ROWS et RANGE :
SELECT orderdate, orderid, val, SUM(val) OVER( ORDER BY orderdate ROWS UNBOUNDED PRECEDING ) AS sumrows, SUM(val) OVER( ORDER BY orderdate RANGE UNBOUNDED PRECEDING ) AS sumrange FROM Sales.OrderValues ORDER BY orderdate;Cette requête génère la sortie suivante :
orderdate orderid val sumrows sumrange ---------- -------- -------- -------- -------- - 2017-07-04 10248 440.00 440.00 440.00 2017-07-05 10249 1863.40 2303.40 2303.40 2017-07-08 10250 1552.60 3856.00 4510.06 4510.08 10251 654.06 4510.06 4510.0602.52020.520.520.520.520.520.520.520.520.590.090606 4510.06 4510.060ELICTOR /pré>Observez la différence dans les résultats pour les lignes où la même date de commande apparaît plus d'une fois, comme c'est le cas pour le 8 juillet 2017. Remarquez comment l'option ROWS n'inclut pas les liens et est donc non déterministe, et comment l'option RANGE le fait inclut les liens, et est donc toujours déterministe.
Il est cependant discutable si, dans la pratique, vous avez des cas où vous commandez par quelque chose qui n'est pas unique, et vous avez vraiment besoin d'inclure des liens pour rendre le calcul déterministe. Ce qui est probablement beaucoup plus courant dans la pratique est de faire l'une des deux choses. L'une consiste à rompre les liens en ajoutant quelque chose à l'ordre de la fenêtre pour le rendre unique et ainsi aboutir à un calcul déterministe, comme ceci :
SELECT orderdate, orderid, val, SUM(val) OVER( ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING ) AS runningsum FROM Sales.OrderValues ORDER BY orderdate;Cette requête génère la sortie suivante :
orderdate orderid val runningsum ---------- -------- --------- ----------- 2017-07-04 10248 440.00 440.00 2017-07-05 10249 1863.40 2303.40 2017-07-08 10250 1552.60 3856.00 2017-07-08 10251 654.06 4510.06 2017-07-09 10252 3597.90 8107.96 ...Une autre option consiste à appliquer un regroupement préalable, dans notre cas, par date de commande, comme ceci :
SELECT orderdate, SUM(val) AS daytotal, SUM(SUM(val)) OVER( ORDER BY orderdate ROWS UNBOUNDED PRECEDING ) AS runningsum FROM Sales.OrderValues GROUP BY orderdate ORDER BY orderdate;Cette requête génère la sortie suivante où chaque date de commande n'apparaît qu'une seule fois :
orderdate daytotal runningsum ---------- --------- ----------- 2017-07-04 440.00 440.00 2017-07-05 1863.40 2303.40 2017-07-08 2206.66 4510.06 2017-07-09 3597.90 8107.96 ...Dans tous les cas, assurez-vous de vous souvenir des meilleures pratiques ici !
La bonne nouvelle est que si vous exécutez sur SQL Server 2016 ou version ultérieure et que vous avez un index columnstore présent sur les données (même s'il s'agit d'un faux index columnstore filtré), ou si vous exécutez sur SQL Server 2019 ou version ultérieure, ou sur Azure SQL Database, indépendamment de la présence d'index columnstore, les trois requêtes susmentionnées sont optimisées avec l'opérateur Window Aggregate en mode batch. Avec cet opérateur, de nombreuses inefficacités de traitement en mode ligne sont éliminées. Cet opérateur n'utilise pas du tout de spool, il n'y a donc pas de problème de spool en mémoire par rapport au spool sur disque. Il utilise un traitement plus sophistiqué où il peut appliquer plusieurs passages parallèles sur la fenêtre de lignes en mémoire pour ROWS et RANGE.
Pour démontrer l'utilisation de l'optimisation en mode batch, assurez-vous que le niveau de compatibilité de votre base de données est défini sur 150 ou plus :
ALTER DATABASE TSQLV5 SET COMPATIBILITY_LEVEL =150 ;Exécutez à nouveau la requête 1 :
SELECT actid, tranid, val, SUM(val) OVER( PARTITION BY actid ORDER BY tranid ROWS UNBOUNDED PRECEDING ) AS balance FROM dbo.Transactions;Le plan de cette requête est illustré à la figure 3.
Figure 3 :Plan pour la requête 1, traitement en mode batch
Voici les statistiques de performances que j'ai obtenues pour cette requête :
Temps CPU :937 ms, temps écoulé :983 ms.
Lectures logiques de la table 'Transactions' :6 208.Le temps d'exécution est tombé à 1 seconde !
Exécutez à nouveau la requête 2 avec l'option RANGE explicite :
SELECT actid, tranid, val, SUM(val) OVER( PARTITION BY actid ORDER BY tranid RANGE UNBOUNDED PRECEDING ) AS balance FROM dbo.Transactions;Le plan de cette requête est illustré à la figure 4.
Figure 2 :Plan pour la requête 2, traitement en mode batch
Voici les statistiques de performances que j'ai obtenues pour cette requête :
Temps CPU :969 ms, temps écoulé :1048 ms.
Table 'Transactions' lectures logiques :6208.Les performances sont les mêmes que pour la requête 1.
Exécutez à nouveau la requête 3, avec l'option implicite RANGE :
SELECT actid, tranid, val, SUM(val) OVER( PARTITION BY actid ORDER BY tranid ) AS balance FROM dbo.Transactions;Le plan et les chiffres de performance sont bien sûr les mêmes que pour la requête 2.
Lorsque vous avez terminé, exécutez le code suivant pour désactiver les statistiques de performances :
SET STATISTICS TIME, IO OFF ;N'oubliez pas non plus de désactiver l'option Supprimer les résultats après l'exécution dans SSMS.
Cadre implicite avec FIRST_VALUE et LAST_VALUE
Les fonctions FIRST_VALUE et LAST_VALUE sont des fonctions de fenêtre décalées qui renvoient respectivement une expression à partir de la première ou de la dernière ligne du cadre de fenêtre. La partie délicate à leur sujet est que souvent, lorsque les gens les utilisent pour la première fois, ils ne réalisent pas qu'ils prennent en charge un cadre, mais pensent plutôt qu'ils s'appliquent à l'ensemble de la partition.
Considérez la tentative suivante pour renvoyer les informations de commande, ainsi que les valeurs des première et dernière commandes du client :
SELECT custid, orderdate, orderid, val, FIRST_VALUE(val) OVER( PARTITION BY custid ORDER BY orderdate, orderid ) AS firstval, LAST_VALUE(val) OVER( PARTITION BY custid ORDER BY orderdate, orderid ) AS lastval FROM Sales. OrderValues ORDER BY custid, orderdate, orderid;Si vous pensez à tort que ces fonctions fonctionnent sur toute la partition de la fenêtre, ce que pensent de nombreuses personnes qui utilisent ces fonctions pour la première fois, vous vous attendez naturellement à ce que FIRST_VALUE renvoie la valeur de la première commande du client et que LAST_VALUE renvoie la valeur de la dernière commande du client. En pratique, cependant, ces fonctions prennent en charge un cadre. Pour rappel, avec les fonctions qui supportent un cadre, lorsque vous spécifiez la clause d'ordre de fenêtre mais pas l'unité de cadre de fenêtre et son étendue associée, vous obtenez RANGE UNBOUNDED PRECEDING par défaut. Avec la fonction FIRST_VALUE, vous obtiendrez le résultat attendu, mais si votre requête est optimisée avec des opérateurs en mode ligne, vous paierez la pénalité d'utilisation du spool sur disque. Avec la fonction LAST_VALUE c'est encore pire. Non seulement vous paierez la pénalité du spool sur disque, mais au lieu d'obtenir la valeur de la dernière ligne de la partition, vous obtiendrez la valeur de la ligne actuelle !
Voici le résultat de la requête ci-dessus :
custid orderdate orderid val firstval lastval ------- ---------- -------- ---------- ------ ---- ---------- 1 2018-08-25 10643 814.50 814.50 814.50 1 2018-10-03 10692 878.00 814.50 878.00 1 2018-10-13 10702 330.00 814.50 330.00 1 2015-1 2018 10835 845.80 814.50 845.80 1 2019-03-16 10952 471.20 814.50 471.20 1 2019-04-09 11011 933.50 814.50 933.50 2 2017-09-18 10308 88.80 88.80 88.80 28-08-08-08 10625 475.75 8.8028-08-08-08 10625 475 8.80 28-08-080 10759 320.00 88.80 320.00 2 2019-03-04 10926 514.40 88.80 514.40 3 2017-11-27 10365 403.20 403.20 403.20 3 2018-04-15 10507 749.06 403.20 749.06 3 2018-05-13 10535 1940.85 403.20 1940.85 3 2018-06-19 10573 2082.00 403.20 2082.00 3 2018-09-22 10677 813.37 403.20 813.37 3 2018-09-25 10682 375,50 403,20 375,50 3 2019-01-28 10856 660,00 403,20 660,00 ...Souvent, lorsque les gens voient une telle sortie pour la première fois, ils pensent que SQL Server a un bogue. Mais bien sûr, ce n'est pas le cas; c'est simplement la valeur par défaut du standard SQL. Il y a un bogue dans la requête. Réalisant qu'il y a un cadre impliqué, vous voulez être explicite sur la spécification du cadre et utiliser le cadre minimum qui capture la ligne que vous recherchez. Assurez-vous également que vous utilisez l'unité ROWS. Ainsi, pour obtenir la première ligne de la partition, utilisez la fonction FIRST_VALUE avec le cadre ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. Pour obtenir la dernière ligne de la partition, utilisez la fonction LAST_VALUE avec le cadre ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING.
Voici notre requête révisée avec le bogue corrigé :
SELECT custid, orderdate, orderid, val, FIRST_VALUE(val) OVER( PARTITION BY custid ORDER BY orderdate, orderid ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ) AS firstval, LAST_VALUE(val) OVER( PARTITION BY custid ORDER BY orderdate, orderid ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS lastval FROM Sales.OrderValues ORDER BY custid, orderdate, orderid;Cette fois, vous obtenez le bon résultat :
custid orderdate orderid val firstval lastval ------- ---------- -------- ---------- ------ ---- ---------- 1 2018-08-25 10643 814.50 814.50 933.50 1 2018-10-03 10692 878.00 814.50 933.50 1 2018-10-13 10702 330.00 814.50 933.50 1 2019-1 2019-1 10835 845.80 814.50 933.50 1 2019-03-16 10952 471.20 814.50 933.50 1 2019-04-09 11011 933.50 814.50 933.50 2 2017-09-18 10308 88.80 88.80 514.40 318-08-08-08108 10625 479.75 880218-08-08/20 10759 320.00 88.80 514.40 2 2019-03-04 10926 514.40 88.80 514.40 3 2017-11-27 10365 403.20 403.20 660.00 3 2018-04-15 10507 749.06 403.20 660.00 3 2018-05-13 10535 1940.85 403.20 660.00 3 2018-06-19 10573 2082.00 403.20 660.00 3 2018-09-22 10677 813.37 403.20 660.00 3 2018-09-25 10682 375,50 403,20 660,00 3 2019-01-28 10856 660,00 403,20 660,00 ...On se demande quelle était la motivation pour que la norme supporte même un cadre avec ces fonctions. Si vous y réfléchissez, vous les utiliserez principalement pour obtenir quelque chose de la première ou de la dernière ligne de la partition. Si vous avez besoin de la valeur de, disons, deux lignes avant le courant, au lieu d'utiliser FIRST_VALUE avec un cadre qui commence par 2 PRECEDING, n'est-il pas beaucoup plus facile d'utiliser LAG avec un décalage explicite de 2, comme ceci :
SELECT custid, orderdate, orderid, val, LAG(val, 2) OVER( PARTITION BY custid ORDER BY orderdate, orderid ) AS prevtwoval FROM Sales.OrderValues ORDER BY custid, orderdate, orderid;Cette requête génère la sortie suivante :
custid orderdate orderid val prevtwoval ------- ---------- -------- ---------- ------- ---- 1 2018-08-25 10643 814.50 null 1 2018-10-03 10692 878.00 NULL 1 2018-10-13 10702 330.00 814.50 1 2019-01-15 10835 845.80 878.00 1 2019-03-16 10952 471.20 330.00 1 2019-04-09 11011 933.50 845.80 2 2017-09-18 10308 88.80 NULL 2 2018-08-08 10625 479.75 NULL 2 2018-11-28 10759 320.00 88.80 2 2019-03-04 10926 514.40 479.75 3 2017-11-27 10365 403.20 null 3 2018-04-15 10507 749.06 NULL 3 2018-05-13 10535 1940.85 403.20 3 2018-06-19 10573 2082.00 749.06 3 2018-09-22 10677 813.37 1940.85 3 2018-09-25 10682 375 -01-28 10856 660.00 813.37 ...Apparemment, il existe une différence sémantique entre l'utilisation ci-dessus de la fonction LAG et FIRST_VALUE avec un cadre qui commence par 2 PRECEDING. Avec le premier, si une ligne n'existe pas dans le décalage souhaité, vous obtenez un NULL par défaut. Avec ce dernier, vous obtenez toujours la valeur de la première ligne présente, c'est-à-dire la valeur de la première ligne de la partition. Considérez la requête suivante :
SELECT custid, orderdate, orderid, val, FIRST_VALUE(val) OVER( PARTITION BY custid ORDER BY orderdate, orderid ROWS BETWEEN 2 PRECEDING AND CURRENT ROW ) AS prevtwoval FROM Sales.OrderValues ORDER BY custid, orderdate, orderid;Cette requête génère la sortie suivante :
custid orderdate orderid val prevtwoval ------- ---------- -------- ---------- ------- ---- 1 2018-08-25 10643 814.50 814.50 1 2018-10-03 10692 878.00 814.50 1 2018-10-13 10702 330.00 814.50 1 2019-01-15 10835 845.80 878.00 1 2019-03-16 10952 471.20 330.00 1 2019-04-09 11011 933.50 845.80 2 2017-09-18 10308 88.80 88.80 2 2018-08-08 10625 479.75 88.80 2 2018-11-28 10759 320.00 88.80 2 2019-03-04 10926 514.40 479.75 3 2017-03-04 10926 514.40 479.75 3 2017-03-04 10365 403.20 403.20 3 2018-04-15 10507 749.06 403.20 3 2018-05-13 10535 1940.85 403.20 3 2018-06-19 10573 2082.00 749.06 3 2018-09-22 10677 813.37 1940.85 3 2018-09 -01-28 10856 660.00 813.37 ...Observez que cette fois il n'y a pas de NULL dans la sortie. Il est donc utile de prendre en charge une trame avec FIRST_VALUE et LAST_VALUE. Assurez-vous simplement que vous vous souvenez de la meilleure pratique consistant à toujours être explicite sur la spécification du cadre avec ces fonctions et à utiliser l'option ROWS avec le cadre minimal contenant la ligne que vous recherchez.
Conclusion
Cet article s'est concentré sur les bogues, les pièges et les meilleures pratiques liés aux fonctions de fenêtre. N'oubliez pas que les fonctions d'agrégation de fenêtre et les fonctions de décalage de fenêtre FIRST_VALUE et LAST_VALUE prennent en charge un cadre, et que si vous spécifiez la clause d'ordre de fenêtre mais que vous ne spécifiez pas l'unité de cadre de fenêtre et son étendue associée, vous obtenez RANGE UNBOUNDED PRECEDING de défaut. Cela entraîne une baisse des performances lorsque la requête est optimisée avec des opérateurs en mode ligne. Avec la fonction LAST_VALUE, cela se traduit par l'obtention des valeurs de la ligne actuelle au lieu de la dernière ligne de la partition. N'oubliez pas d'être explicite sur le cadre et de préférer généralement l'option ROWS à RANGE. C'est formidable de voir les améliorations de performances avec l'opérateur Window Aggregate en mode batch. Lorsqu'il est applicable, au moins l'écueil des performances est éliminé.