Cet article utilise une requête simple pour explorer certains détails internes concernant les requêtes de mise à jour.
Exemples de données et de configuration
L'exemple de script de création de données ci-dessous nécessite une table de nombres. Si vous n'en avez pas déjà un, le script ci-dessous peut être utilisé pour en créer un efficacement. Le tableau de nombres résultant contiendra une seule colonne d'entiers avec des nombres de un à un million :
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Le script ci-dessous crée un exemple de table de données en cluster avec 10 000 ID, avec environ 100 dates de début différentes par ID. La colonne de date de fin est initialement définie sur la valeur fixe '99991231'.
CREATE TABLE dbo.Example
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
EndDate date NOT NULL
);
GO
INSERT dbo.Example WITH (TABLOCKX)
(SomeID, StartDate, EndDate)
SELECT DISTINCT
1 + (N.n % 10000),
DATEADD(DAY, 50000 * RAND(CHECKSUM(NEWID())), '20010101'),
CONVERT(date, '99991231', 112)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
CREATE CLUSTERED INDEX
CX_Example_SomeID_StartDate
ON dbo.Example
(SomeID, StartDate)
WITH (MAXDOP = 1, SORT_IN_TEMPDB = ON); Bien que les points soulevés dans cet article s'appliquent assez généralement à toutes les versions actuelles de SQL Server, les informations de configuration ci-dessous peuvent être utilisées pour vous assurer que vous voyez des plans d'exécution et des effets sur les performances similaires :
- SQL Server 2012 Service Pack 3 Édition développeur x64
- Mémoire maximale du serveur définie sur 2 048 Mo
- Quatre processeurs logiques disponibles pour l'instance
- Aucun indicateur de trace activé
- Niveau d'isolement validé en lecture par défaut
- Options de base de données RCSI et SI désactivées
Déversements d'agrégats de hachage
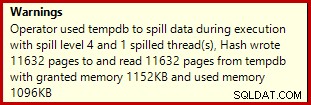
Si vous exécutez le script de création de données ci-dessus avec les plans d'exécution réels activés, l'agrégat de hachage peut déborder sur tempdb, générant une icône d'avertissement :

Lorsqu'il est exécuté sur SQL Server 2012 Service Pack 3, des informations supplémentaires sur le déversement sont affichées dans l'info-bulle :
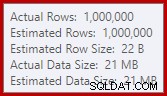
Ce débordement peut être surprenant, étant donné que les estimations des lignes d'entrée pour la correspondance de hachage sont tout à fait correctes :
Nous sommes habitués à comparer les estimations sur l'entrée pour les tris et les jointures de hachage (entrée de construction uniquement), mais les agrégats de hachage impatients sont différents. Un agrégat de hachage fonctionne en accumulant des lignes de résultats groupées dans la table de hachage, c'est donc le nombre de sorties lignes importantes :
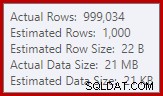
L'estimateur de cardinalité dans SQL Server 2012 fait une estimation plutôt médiocre du nombre de valeurs distinctes attendues (1 000 contre 999 034 réels); l'agrégat de hachage se déverse de manière récursive au niveau 4 lors de l'exécution en conséquence. Le « nouvel » estimateur de cardinalité disponible dans SQL Server 2014 et les versions ultérieures produit une estimation plus précise de la sortie de hachage dans cette requête, vous ne verrez donc pas de débordement de hachage dans ce cas :

Le nombre de lignes réelles peut être légèrement différent pour vous, étant donné l'utilisation d'un générateur de nombres pseudo-aléatoires dans le script. Le point important est que les déversements de Hash Aggregate dépendent du nombre de valeurs uniques en sortie, et non de la taille de l'entrée.
La spécification de mise à jour
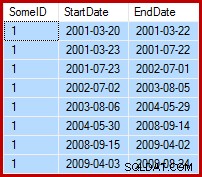
La tâche à accomplir consiste à mettre à jour les données d'exemple de sorte que les dates de fin soient définies le jour avant la date de début suivante (par SomeID). Par exemple, les premières lignes des exemples de données peuvent ressembler à ceci avant la mise à jour (toutes les dates de fin sont définies sur 9999-12-31) :

Puis comme ceci après la mise à jour :
1. Requête de mise à jour de référence
Une manière raisonnablement naturelle d'exprimer la mise à jour requise dans T-SQL est la suivante :
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate =
ISNULL
(
(
SELECT TOP (1)
DATEADD(DAY, -1, E2.StartDate)
FROM dbo.Example AS E2 WITH (TABLOCK)
WHERE
E2.SomeID = dbo.Example.SomeID
AND E2.StartDate > dbo.Example.StartDate
ORDER BY
E2.StartDate ASC
),
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Le plan d'exécution post-exécution (réel) est :
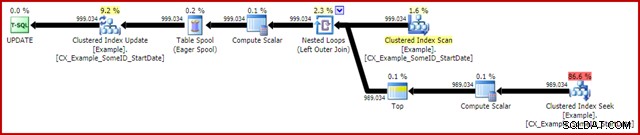
La caractéristique la plus notable est l'utilisation d'une bobine de table Eager pour fournir une protection Halloween. Ceci est nécessaire pour un fonctionnement correct ici en raison de l'auto-jointure de la table cible de mise à jour. L'effet est que tout ce qui se trouve à droite du spool est exécuté jusqu'à la fin, stockant toutes les informations nécessaires pour apporter des modifications dans une table de travail tempdb. Une fois l'opération de lecture terminée, le contenu de la table de travail est relu pour appliquer les modifications au niveau de l'itérateur Clustered Index Update.
Performances
Pour se concentrer sur le potentiel de performance maximal de ce plan d'exécution, nous pouvons exécuter plusieurs fois la même requête de mise à jour. De toute évidence, seule la première exécution entraînera des modifications des données, mais cela s'avère être une considération mineure. Si cela vous dérange, n'hésitez pas à réinitialiser la colonne de date de fin avant chaque exécution à l'aide du code suivant. Les points généraux que je ferai ne dépendent pas du nombre de modifications de données effectivement apportées.
UPDATE dbo.Example WITH (TABLOCKX) SET EndDate = CONVERT(date, '99991231', 112);
Avec la collecte de plans d'exécution désactivée, toutes les pages requises dans le pool de mémoire tampon et aucune réinitialisation des valeurs de date de fin entre les exécutions, cette requête s'exécute généralement en environ 5 700 ms Sur mon ordinateur portable. La sortie des statistiques d'E/S est la suivante :(les lectures anticipées et les compteurs LOB étaient nuls et sont omis pour des raisons d'espace)
Table 'Example'. Scan count 999035, logical reads 6186219, physical reads 0 Table 'Worktable'. Scan count 1, logical reads 2895875, physical reads 0
Le nombre d'analyses représente le nombre de fois qu'une opération d'analyse a été démarrée. Pour la table d'exemple, il s'agit de 1 pour l'analyse d'index clusterisé et de 999 034 pour chaque fois que la recherche d'index clusterisé corrélé est rebondie. La table de travail utilisée par Eager Spool a une opération de numérisation démarrée une seule fois.
Lectures logiques
L'information la plus intéressante dans la sortie IO est le nombre de lectures logiques :plus de 6 millions pour la table Exemple, et près de 3 millions pour la table de travail.
Les lectures logiques de table d'exemple sont principalement associées à la recherche et à la mise à jour. Le Seek implique 3 lectures logiques pour chaque itération :1 pour les niveaux racine, intermédiaire et feuille de l'index. La mise à jour coûte également 3 lectures à chaque fois qu'une ligne est mis à jour, tandis que le moteur navigue dans le b-tree pour localiser la ligne cible. Le Clustered Index Scan n'est responsable que de quelques milliers de lectures, une par page lire.
La table de travail Spool est également structurée en interne sous la forme d'un b-tree et compte plusieurs lectures lorsque le spool localise la position d'insertion tout en consommant son entrée. Peut-être contre-intuitivement, le spool ne compte aucune lecture logique pendant qu'il est en cours de lecture pour piloter la mise à jour de l'index clusterisé. C'est simplement une conséquence de l'implémentation :une lecture logique est comptée chaque fois que le code exécute le BPool::Get méthode. L'écriture dans le spool appelle cette méthode à chaque niveau de l'index; la lecture à partir du spool suit un chemin de code différent qui n'appelle pas BPool::Get du tout.
Notez également que la sortie IO des statistiques signale un seul total pour la table Example, malgré le fait qu'elle est accessible par trois itérateurs différents dans le plan d'exécution (Scan, Seek et Update). Ce dernier fait rend difficile la corrélation des lectures logiques avec l'itérateur qui les a provoquées. J'espère que cette limitation sera résolue dans une future version du produit.
2. Mettre à jour en utilisant les numéros de ligne
Une autre façon d'exprimer la requête de mise à jour consiste à numéroter les lignes par ID et à les joindre :
WITH Numbered AS
(
SELECT
E.SomeID,
E.StartDate,
E.EndDate,
rn = ROW_NUMBER() OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate ASC)
FROM dbo.Example AS E
)
UPDATE This WITH (TABLOCKX)
SET EndDate =
ISNULL
(
DATEADD(DAY, -1, NextRow.StartDate),
CONVERT(date, '99991231', 112)
)
FROM Numbered AS This
LEFT JOIN Numbered AS NextRow WITH (TABLOCK)
ON NextRow.SomeID = This.SomeID
AND NextRow.rn = This.rn + 1
OPTION (MAXDOP 1, MERGE JOIN); Le plan de post-exécution est le suivant :
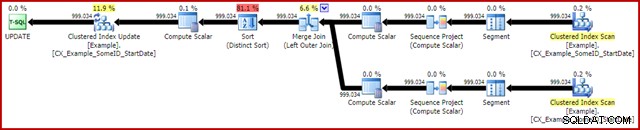
Cette requête s'exécute généralement en 2 950 ms sur mon ordinateur portable, ce qui se compare favorablement aux 5700 ms (dans les mêmes circonstances) observés pour la déclaration de mise à jour d'origine. La sortie d'E/S des statistiques est :
Table 'Example'. Scan count 2, logical reads 3001808, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Cela montre deux analyses démarrées pour la table Example (une pour chaque itérateur Clustered Index Scan). Les lectures logiques sont à nouveau un agrégat sur tous les itérateurs qui accèdent à cette table dans le plan de requête. Comme précédemment, l'absence de ventilation rend impossible de déterminer quel itérateur (des deux Scans et de la Mise à jour) était responsable des 3 millions de lectures.
Néanmoins, je peux vous dire que les Clustered Index Scans ne comptent que quelques milliers de lectures logiques chacun. La grande majorité des lectures logiques sont causées par la mise à jour de l'index clusterisé naviguant dans l'arborescence d'index pour trouver la position de mise à jour pour chaque ligne qu'elle traite. Vous devrez me croire sur parole pour le moment; plus d'explications seront bientôt disponibles.
Les inconvénients
C'est à peu près la fin des bonnes nouvelles pour cette forme de requête. Il fonctionne bien mieux que l'original, mais il est beaucoup moins satisfaisant pour un certain nombre d'autres raisons. Le problème principal est causé par une limitation de l'optimiseur, ce qui signifie qu'il ne reconnaît pas que l'opération de numérotation des lignes produit un numéro unique pour chaque ligne dans une partition SomeID.
Ce simple fait entraîne un certain nombre de conséquences indésirables. D'une part, la jointure de fusion est configurée pour s'exécuter en mode de jointure plusieurs-à-plusieurs. C'est la raison de la table de travail (inutilisée) dans les statistiques IO (la fusion plusieurs-à-plusieurs nécessite une table de travail pour les rembobinages de clé de jointure en double). S'attendre à une jointure plusieurs-à-plusieurs signifie également que l'estimation de la cardinalité pour la sortie de la jointure est désespérément erronée :
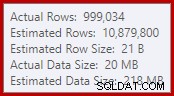
En conséquence, le tri demande beaucoup trop d'allocation de mémoire. Les propriétés du nœud racine montrent que le tri aurait aimé 812 752 Ko de mémoire, bien qu'il n'ait reçu que 379 440 Ko en raison du paramètre de mémoire maximale du serveur restreint (2 048 Mo). Le tri a en fait utilisé un maximum de 58 968 Ko lors de l'exécution :
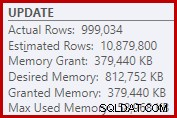
Des allocations de mémoire excessives détournent de la mémoire d'autres utilisations productives et peuvent entraîner des requêtes en attente jusqu'à ce que la mémoire soit disponible. À bien des égards, des allocations de mémoire excessives peuvent être plus problématiques que des sous-estimations.
La limitation de l'optimiseur explique également pourquoi un indicateur de jointure de fusion était nécessaire sur la requête pour de meilleures performances. Sans cet indice, l'optimiseur évalue à tort qu'une jointure par hachage serait moins chère qu'une jointure par fusion plusieurs-à-plusieurs. Le plan de jointure par hachage s'exécute en 3 350 ms en moyenne.
Comme dernière conséquence négative, notez que le tri dans le plan est un tri distinct. Maintenant, il y a quelques raisons à ce tri (notamment parce qu'il peut fournir la protection d'Halloween requise), mais ce n'est qu'un distinct Trier car l'optimiseur manque les informations d'unicité. Dans l'ensemble, il est difficile d'aimer beaucoup ce plan d'exécution au-delà de la performance.
3. Mise à jour à l'aide de la fonction analytique LEAD
Étant donné que cet article cible principalement SQL Server 2012 et versions ultérieures, nous pouvons exprimer la requête de mise à jour assez naturellement à l'aide de la fonction analytique LEAD. Dans un monde idéal, nous pourrions utiliser une syntaxe très compacte comme :
-- Not allowed
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate = LEAD(StartDate) OVER (
PARTITION BY SomeID ORDER BY StartDate); Malheureusement, ce n'est pas légal. Il en résulte le message d'erreur 4108, "Les fonctions fenêtrées ne peuvent apparaître que dans les clauses SELECT ou ORDER BY". C'est un peu frustrant car nous espérions un plan d'exécution qui pourrait éviter une auto-jointure (et la mise à jour associée Halloween Protection).
La bonne nouvelle est que nous pouvons toujours éviter l'auto-jointure en utilisant une expression de table commune ou une table dérivée. La syntaxe est un peu plus détaillée, mais l'idée est à peu près la même :
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Le plan de post-exécution est :

Cela prend généralement environ 3 400 ms sur mon ordinateur portable, qui est plus lent que la solution de numéro de ligne (2950 ms) mais toujours beaucoup plus rapide que l'original (5700 ms). Une chose qui ressort du plan d'exécution est le déversement de tri (encore une fois, des informations supplémentaires sur le déversement grâce aux améliorations du SP3) :
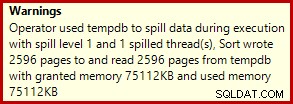
Il s'agit d'un petit déversement, mais il pourrait encore affecter les performances dans une certaine mesure. Ce qui est étrange, c'est que l'estimation d'entrée dans le tri est tout à fait correcte :
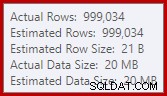
Heureusement, il existe un "correctif" pour cette condition spécifique dans SQL Server 2012 SP2 CU8 (et d'autres versions - voir l'article de la base de connaissances pour plus de détails). L'exécution de la requête avec le correctif et l'indicateur de trace requis 7470 activé signifie que le tri demande suffisamment de mémoire pour garantir qu'il ne se répandra jamais sur le disque si la taille de tri d'entrée estimée n'est pas dépassée.
Requête de mise à jour LEAD sans débordement de tri
Pour plus de variété, la requête avec correction ci-dessous utilise une syntaxe de table dérivée au lieu d'un CTE :
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate, CONVERT(date, '99991231', 112)
)
FROM
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
) AS CED
OPTION (MAXDOP 1, QUERYTRACEON 7470); Le nouveau plan post-exécution est :

L'élimination du petit déversement améliore les performances de 3 400 ms à 3 250 ms . La sortie d'E/S des statistiques est :
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Si vous comparez cela avec les lectures logiques pour la requête numérotée par ligne, vous verrez que les lectures logiques ont diminué de 3 001 808 à 2 999 455 - une différence de 2 353 lectures. Cela correspond exactement à la suppression d'un seul Clustered Index Scan (une lecture par page).
Vous vous souvenez peut-être que j'ai mentionné que la grande majorité des lectures logiques pour ces requêtes de mise à jour sont associées à la mise à jour de l'index clusterisé et que les analyses étaient associées à "seulement quelques milliers de lectures". Nous pouvons maintenant voir cela un peu plus directement en exécutant une simple requête de comptage de lignes sur la table Exemple :
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.Example WITH (TABLOCK); SET STATISTICS IO OFF;
La sortie IO montre exactement la différence de lecture logique de 2 353 entre le numéro de ligne et les mises à jour de piste :
Table 'Example'. Scan count 1, logical reads 2353, physical reads 0
Autre amélioration ?
La requête de plomb corrigée en cas de déversement (3250 ms) est toujours un peu plus lente que la requête numérotée à double ligne (2950 ms), ce qui peut être un peu surprenant. Intuitivement, on pourrait s'attendre à ce qu'une seule fonction d'analyse et d'analyse (Window Spool et Stream Aggregate) soit plus rapide que deux analyses, deux ensembles de numérotation de lignes et une jointure.
Quoi qu'il en soit, ce qui ressort du plan d'exécution de la requête principale est le tri. Il était également présent dans la requête numérotée par ligne, où il contribuait à la protection Halloween ainsi qu'à un ordre de tri optimisé pour la mise à jour de l'index clusterisé (qui a la propriété DMLRequestSort définie).
Le fait est que ce tri est totalement inutile dans le plan de requête de prospect. Il n'est pas nécessaire pour la protection d'Halloween car l'auto-jointure a disparu. Il n'est pas non plus nécessaire pour l'ordre de tri des insertions optimisé :les lignes sont lues dans l'ordre des clés de cluster et rien dans le plan ne perturbe cet ordre. Le vrai problème peut être vu en regardant les propriétés de tri :

Remarquez la section Trier par ici. Le tri trie par SomeID et StartDate (les clés d'index groupées) mais aussi par [Uniq1002], qui est l'unificateur. C'est une conséquence de ne pas déclarer l'index clusterisé comme unique, même si nous avons pris des mesures dans la requête de population de données pour nous assurer que la combinaison de SomeID et StartDate serait en fait unique. (C'était délibéré, donc je pouvais en parler.)
Même ainsi, c'est une limitation. Les lignes sont lues à partir de l'index clusterisé dans l'ordre, et les garanties internes nécessaires existent pour que l'optimiseur puisse éviter ce tri en toute sécurité. C'est simplement un oubli que l'optimiseur ne reconnaît pas que le flux entrant est trié par uniquificateur ainsi que par SomeID et StartDate. Il reconnaît que l'ordre (SomeID, StartDate) peut être préservé, mais pas (SomeID, StartDate, uniquifier). Encore une fois, j'espère que cela sera résolu dans une future version.
Pour contourner ce problème, nous pouvons faire ce que nous aurions dû faire en premier lieu :créer l'index clusterisé comme unique :
CREATE UNIQUE CLUSTERED INDEX CX_Example_SomeID_StartDate ON dbo.Example (SomeID, StartDate) WITH (DROP_EXISTING = ON, MAXDOP = 1);
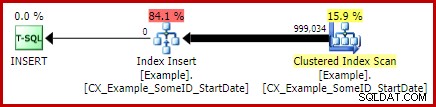
Je vais laisser le lecteur en exercice pour montrer que les deux premières requêtes (non LEAD) ne bénéficient pas de ce changement d'indexation (omis uniquement pour des raisons d'espace - il y a beaucoup à couvrir).
La forme finale de la requête de mise à jour du prospect
Avec l'unique index clusterisé en place, la même requête LEAD (CTE ou table dérivée à votre guise) produit le plan estimé (pré-exécution) que nous attendons :

Cela semble assez optimal. Une seule opération de lecture et d'écriture avec un minimum d'opérateurs intermédiaires. Certes, cela semble bien meilleur que la version précédente avec le tri inutile, qui s'exécutait en 3250 ms une fois le déversement évitable supprimé (au prix d'une augmentation un peu de l'allocation de mémoire).
Le plan post-exécution (réel) est presque exactement le même que le plan pré-exécution :

Toutes les estimations sont exactement correctes, à l'exception de la sortie du Window Spool, qui est décalée de 2 lignes. Les informations d'E/S statistiques sont exactement les mêmes qu'avant la suppression du tri, comme on peut s'y attendre :
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Pour résumer brièvement, la seule différence apparente entre ce nouveau plan et le précédent immédiat est que le tri (avec une contribution aux coûts estimée à près de 80 %) a été supprimé.
Il peut alors être surprenant d'apprendre que la nouvelle requête - sans le tri - s'exécute en 5000 ms . C'est bien pire que les 3250 ms avec le tri, et presque aussi longtemps que la requête de jointure de boucle d'origine de 5700 ms. La solution de numérotation à double rangée est toujours en avance à 2 950 ms.
Explication
L'explication est quelque peu ésotérique et concerne la manière dont les verrous sont gérés pour la dernière requête. Nous pouvons montrer cet effet de plusieurs manières, mais la plus simple consiste probablement à examiner les statistiques d'attente et de verrouillage à l'aide des DMV :
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
DBCC SQLPERF('sys.dm_os_latch_stats', CLEAR);
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1);
SELECT * FROM sys.dm_os_latch_stats AS DOLS
WHERE DOLS.waiting_requests_count > 0
ORDER BY DOLS.latch_class;
SELECT * FROM sys.dm_os_wait_stats AS DOWS
WHERE DOWS.waiting_tasks_count > 0
ORDER BY DOWS.waiting_tasks_count DESC; Lorsque l'index clusterisé n'est pas unique et qu'il existe un tri dans le plan, il n'y a pas d'attentes significatives, juste quelques attentes PAGEIOLATCH_UP et les SOS_SCHEDULER_YIELD attendus.
Lorsque l'index clusterisé est unique et que le tri est supprimé, les attentes sont :
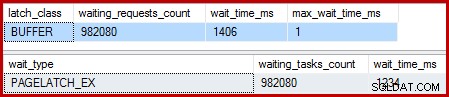
Il y a 982 080 verrous de page exclusifs, avec un temps d'attente qui explique à peu près tout le temps d'exécution supplémentaire. Pour souligner, c'est presque une attente de verrouillage par ligne mise à jour ! Nous pourrions nous attendre à un changement de verrou par ligne, mais pas à un verrou attendre , en particulier lorsque la requête de test est la seule activité sur l'instance. Les délais d'attente sont courts, mais il y en a énormément.
Verrous paresseux
Suite à l'exécution de la requête avec un débogueur et un analyseur attachés, l'explication est la suivante.
L'analyse de l'index clusterisé utilise des loquets paresseux – une optimisation qui signifie que les verrous ne sont libérés que lorsqu'un autre thread nécessite l'accès à la page. Normalement, les verrous sont libérés immédiatement après la lecture ou l'écriture. Les verrous paresseux optimisent le cas où la numérisation d'une page entière acquerrait et libérerait le même verrou de page pour chaque ligne. Lorsque le verrouillage différé est utilisé sans conflit, un seul verrou est utilisé pour toute la page.
Le problème est que la nature en pipeline du plan d'exécution (pas d'opérateurs bloquants) signifie que les lectures se chevauchent avec les écritures. Lorsque la mise à jour de l'index clusterisé tente d'acquérir un verrou EX pour modifier une ligne, elle trouvera presque toujours que la page est déjà verrouillée SH (le verrou paresseux pris par le balayage de l'index clusterisé). Cette situation entraîne une attente de verrouillage.
Dans le cadre de la préparation de l'attente et du passage à l'élément exécutable suivant sur le planificateur, le code prend soin de libérer tous les verrous paresseux. Relâcher le loquet paresseux signale le premier serveur éligible, qui se trouve être lui-même. Nous avons donc la situation étrange où un thread se bloque, libère son verrou paresseux, puis se signale qu'il est à nouveau exécutable. Le thread reprend et continue, mais seulement après que tout ce travail inutile de suspension et de commutation, de signalisation et de reprise a été effectué. Comme je l'ai déjà dit, les attentes sont courtes, mais elles sont nombreuses.
Pour autant que je sache, cette étrange séquence d'événements est intentionnelle et pour de bonnes raisons internes. Même ainsi, il est indéniable que cela a un effet assez dramatique sur les performances ici. Je vais me renseigner à ce sujet et mettre à jour l'article s'il y a une déclaration publique à faire. Dans l'intervalle, les attentes de verrouillage automatique excessives peuvent être quelque chose à surveiller avec les requêtes de mise à jour en pipeline, bien que ce qu'il convient de faire à ce sujet du point de vue de l'auteur de la requête ne soit pas clair.
Cela signifie-t-il que l'approche de double numérotation des lignes est la meilleure que nous puissions faire pour cette requête ? Pas tout à fait.
4. Protection Halloween manuelle
Cette dernière option peut sembler et sembler un peu folle. L'idée générale est d'écrire toutes les informations nécessaires pour apporter les modifications à une variable de table, puis d'effectuer la mise à jour en une étape distincte.
Faute d'une meilleure description, j'appelle cela l'approche "HP manuelle" car elle est conceptuellement similaire à l'écriture de toutes les informations de modification dans un spool de table Eager (comme on le voit dans la première requête) avant de piloter la mise à jour à partir de ce spool.
Quoi qu'il en soit, le code est le suivant :
DECLARE @U AS table
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
NewEndDate date NULL,
PRIMARY KEY CLUSTERED (SomeID, StartDate)
);
INSERT @U
(SomeID, StartDate, NewEndDate)
SELECT
E.SomeID,
E.StartDate,
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E WITH (TABLOCK)
OPTION (MAXDOP 1);
UPDATE E WITH (TABLOCKX)
SET E.EndDate =
ISNULL
(
U.NewEndDate, CONVERT(date, '99991231', 112)
)
FROM dbo.Example AS E
JOIN @U AS U
ON U.SomeID = E.SomeID
AND U.StartDate = E.StartDate
OPTION (MAXDOP 1, MERGE JOIN); Ce code utilise délibérément une variable de table pour éviter le coût des statistiques créées automatiquement qu'entraînerait l'utilisation d'une table temporaire. C'est OK ici parce que je connais la forme de plan que je veux, et cela ne dépend pas d'estimations de coûts ou d'informations statistiques.
Le seul inconvénient de la variable de table (sans indicateur de trace) est que l'optimiseur estimera généralement une seule ligne et choisira des boucles imbriquées pour la mise à jour. Pour éviter cela, j'ai utilisé un indice de jointure de fusion. Encore une fois, cela dépend de la connaissance exacte de la forme du plan à réaliser.
Le plan de post-exécution pour l'insertion de la variable de table ressemble exactement à la requête qui avait le problème avec les attentes du verrou :

L'avantage de ce plan est qu'il ne modifie pas la même table à partir de laquelle il lit. Aucune protection Halloween n'est requise et il n'y a aucune chance d'interférence de verrouillage. De plus, il existe d'importantes optimisations internes pour les objets tempdb (verrouillage et journalisation) et d'autres optimisations normales de chargement en masse sont également appliquées. N'oubliez pas que les optimisations groupées ne sont disponibles que pour les insertions, pas pour les mises à jour ou les suppressions.
Le plan de post-exécution pour l'instruction de mise à jour est :
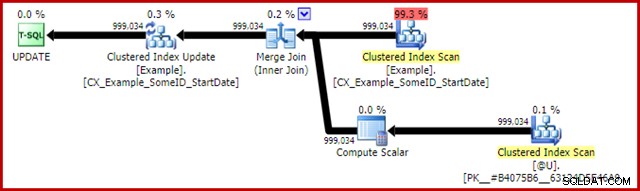
La jointure de fusion ici est le type un-à-plusieurs efficace. Plus précisément, ce plan se qualifie pour une optimisation spéciale, ce qui signifie que l'analyse de l'index clusterisé et la mise à jour de l'index clusterisé partagent le même ensemble de lignes. La conséquence importante est que la mise à jour n'a plus à localiser la ligne à mettre à jour - elle est déjà correctement positionnée par la lecture. Cela permet d'économiser énormément de lectures logiques (et d'autres activités) lors de la mise à jour.
Il n'y a rien dans les plans d'exécution normaux pour montrer où cette optimisation de l'ensemble de lignes partagé est appliquée, mais l'activation de l'indicateur de trace non documenté 8666 expose des propriétés supplémentaires sur la mise à jour et l'analyse qui montrent que le partage de l'ensemble de lignes est en cours d'utilisation et que des mesures sont prises pour s'assurer que la mise à jour est sûre. du problème d'Halloween.
La sortie d'E/S de statistiques pour les deux requêtes est la suivante :
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0 Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 (999034 row(s) affected) Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 Table '#B9C034B8'. Scan count 1, logical reads 2353, physical reads 0
Les deux lectures de la table Exemple impliquent un seul parcours et une lecture logique par page (voir la requête de comptage de lignes simple précédemment). La table #B9C034B8 est le nom de l'objet tempdb interne qui sauvegarde la variable de table. Le nombre total de lectures logiques pour les deux requêtes est de 3 * 2353 =7 059. La table de travail est le stockage interne en mémoire utilisé par le Window Spool.
Le temps d'exécution typique pour cette requête est de 2 300 ms . Enfin, nous avons quelque chose qui bat la requête à double numérotation des lignes (2 950 ms), aussi improbable que cela puisse paraître.
Réflexions finales
Il peut y avoir encore de meilleures façons d'écrire cette mise à jour qui fonctionnent encore mieux que la solution "HP manuelle" ci-dessus. Les résultats de performances peuvent même être différents sur votre configuration matérielle et SQL Server, mais aucun de ces éléments n'est le point principal de cet article. Cela ne veut pas dire que je ne suis pas intéressé à voir de meilleures requêtes ou comparaisons de performances - je le suis.
Le fait est qu'il se passe beaucoup plus de choses dans SQL Server que ce qui est exposé dans les plans d'exécution. Espérons que certains des détails abordés dans cet article plutôt long seront intéressants ou même utiles à certaines personnes.
Il est bon d'avoir des attentes de performance et de savoir quelles formes et propriétés de plan sont généralement bénéfiques. Ce type d'expérience et de connaissances vous sera utile pour 99 % ou plus des requêtes qu'il vous sera demandé de régler. Parfois, cependant, il est bon d'essayer quelque chose d'un peu bizarre ou inhabituel juste pour voir ce qui se passe et pour valider ces attentes.