Le vide est l'une des fonctionnalités les plus importantes pour récupérer les tuples supprimés dans les tables et les index. Sans vide, les tables et les index continueraient à grossir sans limites. Ce billet de blog décrit l'option PARALLEL pour la commande VACUUM, qui est nouvellement introduite dans PostgreSQL13.
Phases de traitement sous vide
Avant de discuter de la nouvelle option en profondeur, passons en revue les détails du fonctionnement du vide.
Le vide (sans l'option FULL) se compose de cinq phases. Par exemple, pour une table à deux index, cela fonctionne comme suit :
- Phase d'analyse du tas
- Balayer la table à partir du haut et collecter les tuples inutiles en mémoire.
- Phase de vide d'indice
- Aspirez les deux index un par un.
- Phase de vide de tas
- Aspirez le tas (table).
- Phase de nettoyage de l'index
- Nettoyez les deux index un par un.
- Phase de troncature de tas
- Tronquer les pages vides à la fin du tableau.
Dans la phase d'analyse du tas, le vide peut utiliser la carte de visibilité pour ignorer le traitement des pages qui sont connues comme n'ayant pas de déchets, tandis que dans la phase de vide d'index et la phase de nettoyage de l'index, selon les méthodes d'accès à l'index, une analyse complète de l'index est requis.
Par exemple, les index btree, le type d'index le plus populaire, nécessitent une analyse complète de l'index pour supprimer les tuples inutiles et effectuer le nettoyage de l'index. Comme le vide est toujours effectué par un seul processus, les index sont traités un par un. Le temps d'exécution plus long de vide sur une grande table en particulier agace souvent les utilisateurs.
Option PARALLÈLE
Pour résoudre ce problème, j'ai proposé un correctif pour paralléliser vacuum en 2016. Après un long processus de révision et de nombreuses réformes, l'option PARALLEL a été introduite dans PostgreSQL 13. Avec cette option, vacuum peut effectuer la phase de vide d'index et la phase de nettoyage d'index avec travailleurs parallèles. Les travailleurs sous vide parallèles se lancent avant d'entrer dans la phase de vide d'index ou la phase de nettoyage d'index et sortent à la fin de la phase. Un travailleur individuel est affecté à un index. Le vide parallèle est toujours désactivé dans le vide automatique.
L'option PARALLEL sans option d'argument entier calculera automatiquement le degré parallèle en fonction du nombre d'index sur la table.
VACUUM (PARALLEL) tbl;
Étant donné que le processus leader traite toujours un index, le nombre maximal de travailleurs parallèles sera (le nombre d'index dans la table - 1), qui est en outre limité à max_parallel_maintenance_workers. L'index cible doit être supérieur ou égal à min_parallel_index_scan_size.
L'option PARALLEL nous permet de spécifier le degré parallèle en passant une valeur entière non nulle. L'exemple suivant utilise trois nœuds de calcul, pour un total de quatre processus en parallèle.
VACUUM (PARALLEL 3) tbl;
L'option PARALLELE est activée par défaut; pour désactiver le vide parallèle, définissez max_parallel_maintenance_workers sur 0 ou spécifiez PARALLEL 0 .
VACUUM (PARALLEL 0) tbl; -- disable parallel vacuum
En regardant la sortie VACUUM VERBOSE, nous pouvons voir qu'un travailleur traite l'index.
Les informations imprimées comme "par travailleur parallèle" sont rapportées par le travailleur.
VACUUM (PARALLEL, VERBOSE) tbl; INFO: vacuuming "public.tbl" INFO: launched 2 parallel vacuum workers for index vacuuming (planned: 2) INFO: scanned index "i1" to remove 112834 row versions DETAIL: CPU: user: 9.80 s, system: 3.76 s, elapsed: 23.20 s INFO: scanned index "i2" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.64 s, system: 8.98 s, elapsed: 42.84 s INFO: scanned index "i3" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.65 s, system: 8.98 s, elapsed: 43.96 s INFO: "tbl": removed 112834 row versions in 112834 pages DETAIL: CPU: user: 1.12 s, system: 2.31 s, elapsed: 22.01 s INFO: index "i1" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i2" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i3" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: "tbl": found 112834 removable, 112833240 nonremovable row versions in 553105 out of 735295 pages DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 430046 There were 444 unused item identifiers. Skipped 0 pages due to buffer pins, 0 frozen pages. 0 pages are entirely empty. CPU: user: 18.00 s, system: 8.99 s, elapsed: 91.73 s. VACUUM
Méthodes d'accès à l'index et degré de parallélisme
Le vide n'effectue pas toujours nécessairement la phase de vide d'index et la phase de nettoyage d'index en parallèle. Si la taille de l'index est petite ou si l'on sait que le processus peut être terminé rapidement, le coût de lancement et de gestion des travailleurs parallèles pour la parallélisation entraîne plutôt une surcharge. Selon les méthodes d'accès à l'index et sa taille, il est préférable de ne pas effectuer ces phases par un processus parallèle de travail sous vide.
Par exemple, lors de l'aspiration d'un index btree suffisamment grand, la phase d'aspiration de l'index de l'index peut être effectuée par un aspirateur parallèle, car elle nécessite toujours une analyse complète de l'index, tandis que la phase de nettoyage de l'index est effectuée par un aspirateur parallèle si l'index le vide n'est pas effectué (par exemple, il n'y a pas de déchets sur la table). En effet, ce dont les index btree ont besoin dans la phase de nettoyage de l'index, c'est de collecter les statistiques de l'index, qui sont également collectées pendant la phase de vide de l'index. D'un autre côté, les index de hachage ne nécessitent toujours pas d'analyse de l'index lors de la phase de nettoyage de l'index.
Pour prendre en charge différents types de stratégies de vide d'index, les développeurs de méthodes d'accès à l'index peuvent spécifier ces comportements en définissant des drapeaux sur les amparallelvacuumoptions champ de l'IndexAmRoutine structure. Les drapeaux disponibles sont les suivants :
- VACUUM_OPTION_NO_PARALLEL (par défaut)
- le vide parallèle est désactivé dans les deux phases.
- VACUUM_OPTION_PARALLEL_BULKDEL
- la phase de vide d'index peut être effectuée en parallèle.
- VACUUM_OPTION_PARALLEL_COND_CLEANUP
- la phase de nettoyage d'index peut être effectuée en parallèle si la phase de vide d'index n'est pas encore effectuée.
- VACUUM_OPTION_PARALLEL_CLEANUP
- la phase de nettoyage de l'index peut être effectuée en parallèle même si la phase de vide de l'index a déjà traité l'index.
Le tableau ci-dessous montre comment l'index AM intégré à PostgreSQL prend en charge le vide parallèle.
| nbtree | hachage | gin | essentiel | spgist | brin | floraison | |
| VACUUM_OPTION_PARALLEL_BULKDEL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| VACUUM_OPTION_PARALLEL_COND_CLEANUP | ✓ | ✓ | ✓ | ||||
| VACUUM_OPTION_CLEANUP | ✓ | ✓ | ✓ |
Voir 'src/include/command/vacuum.h' pour plus de détails.
Vérification des performances
J'ai évalué les performances de l'aspirateur parallèle sur mon ordinateur portable (Core i7 2,6 GHz, 16 Go de RAM, 512 Go de SSD). La taille de la table est de 6 Go et comporte huit index de 3 Go. La relation totale est de 30 Go, ce qui ne correspond pas à la RAM de la machine. Pour chaque évaluation, j'ai fait plusieurs pour cent de la table sale uniformément après avoir passé l'aspirateur, puis j'ai effectué le vide tout en changeant le degré parallèle. Le graphique ci-dessous montre le temps d'exécution du vide.
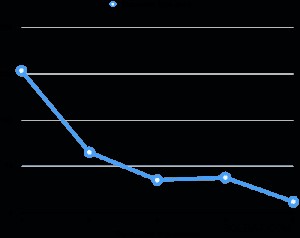
Dans toutes les évaluations, le temps d'exécution du vide d'index représentait plus de 95 % du temps d'exécution total. Par conséquent, la parallélisation de la phase de vide d'index a permis de réduire considérablement le temps d'exécution du vide.
Merci
Un merci spécial à Amit Kapila pour sa révision dévouée, ses conseils et l'engagement de cette fonctionnalité dans PostgreSQL 13. J'apprécie tous les développeurs qui ont été impliqués dans cette fonctionnalité pour la révision, les tests et la discussion.