Introduite pour la première fois dans SQL Server 2017 Enterprise Edition, une jointure adaptative permet une transition d'exécution d'une jointure de hachage en mode batch vers une jointure indexée de boucles imbriquées corrélées en mode ligne (appliquer) au moment de l'exécution. Par souci de brièveté, je ferai référence à une "jointure indexée de boucles imbriquées corrélées" en tant que application dans tout le reste de cet article. Si vous avez besoin d'un rappel sur la différence entre les boucles imbriquées et l'application, veuillez consulter mon article précédent.
Le fait qu'une jointure adaptative passe d'une jointure par hachage à l'application au moment de l'exécution dépend d'une valeur intitulée Adaptive Threshold Rows sur la jointure adaptative opérateur du plan d'exécution. Cet article montre comment fonctionne une jointure adaptative, comprend des détails sur le calcul du seuil et couvre les implications de certains des choix de conception effectués.
Présentation
Une chose que je veux que vous gardiez à l'esprit tout au long de cet article est une jointure adaptative toujours commence à s'exécuter en tant que jointure par hachage en mode batch. Cela est vrai même si le plan d'exécution indique que la jointure adaptative s'attend à s'exécuter en mode ligne.
Comme toute jointure par hachage, une jointure adaptative lit toutes les lignes disponibles sur son entrée de génération et copie les données requises dans une table de hachage. La version en mode batch de la jointure par hachage stocke ces lignes dans un format optimisé et les partitionne à l'aide d'une ou plusieurs fonctions de hachage. Une fois l'entrée de construction consommée, la table de hachage est entièrement remplie et partitionnée, prête pour que la jointure de hachage commence à vérifier les lignes côté sonde pour les correspondances.
C'est le point où une jointure adaptative prend la décision de procéder à la jointure par hachage en mode batch ou de passer à une application en mode ligne. Si le nombre de lignes dans la table de hachage est inférieur au seuil valeur, la jointure passe à une application ; sinon, la jointure continue comme une jointure par hachage en commençant à lire les lignes à partir de l'entrée de la sonde.
Si une transition vers une jointure d'application se produit, le plan d'exécution ne relit pas les lignes utilisées pour remplir la table de hachage pour piloter l'opération d'application. Au lieu de cela, un composant interne appelé lecteur de tampon adaptatif développe les lignes déjà stockées dans la table de hachage et les rend disponibles à la demande pour l'entrée externe de l'opérateur d'application. Il y a un coût associé au lecteur de tampon adaptatif, mais il est bien inférieur au coût de rembobinage complet de l'entrée de construction.
Choisir une jointure adaptative
L'optimisation des requêtes implique une ou plusieurs étapes d'exploration logique et de mise en œuvre physique d'alternatives. À chaque étape, lorsque l'optimiseur explore les options physiques pour un logique join, il peut envisager à la fois la jointure par hachage en mode batch et les alternatives d'application en mode ligne.
Si l'une de ces options de jointure physique fait partie de la solution la moins chère trouvée au cours de l'étape actuelle—et l'autre type de jointure peut fournir les mêmes propriétés logiques requises :l'optimiseur marque le groupe de jointure logique comme potentiellement adapté à une jointure adaptative. Si ce n'est pas le cas, l'examen d'une jointure adaptative se termine ici (et aucun événement étendu de jointure adaptative n'est déclenché).
Le fonctionnement normal de l'optimiseur signifie que la solution la moins chère trouvée n'inclura qu'une des options de jointure physique, soit hacher ou appliquer, selon celle qui a le coût estimé le plus bas. La prochaine chose que fait l'optimiseur est de construire et de coûter une nouvelle implémentation du type de jointure qui n'était pas choisi comme le moins cher.
Étant donné que la phase d'optimisation actuelle s'est déjà terminée avec une solution la moins chère trouvée, un tour spécial d'exploration et de mise en œuvre d'un seul groupe est effectué pour la jointure adaptative. Enfin, l'optimiseur calcule le seuil adaptatif .
Si l'un des travaux précédents échoue, l'événement étendu adaptive_join_skipped est déclenché avec une raison.
Si le traitement de la jointure adaptative réussit, un Concat L'opérateur est ajouté au plan interne au-dessus du hachage et applique des alternatives avec le lecteur de tampon adaptatif et tous les adaptateurs de mode batch/ligne requis. N'oubliez pas qu'une seule des alternatives de jointure s'exécutera au moment de l'exécution, en fonction du nombre de lignes réellement rencontrées par rapport au seuil adaptatif.
Le Concat L'opérateur et les alternatives individuelles de hachage/application ne sont normalement pas affichés dans le plan d'exécution final. Nous sommes plutôt présentés avec une seule jointure adaptative opérateur. Il ne s'agit que d'une simple décision de présentation :le Concat et les jointures sont toujours présentes dans le code exécuté par le moteur d'exécution SQL Server. Vous pouvez trouver plus de détails à ce sujet dans les sections Annexe et Lectures connexes de cet article.
Le seuil adaptatif
Une application est généralement moins chère qu'une jointure par hachage pour un plus petit nombre de lignes motrices. La jointure de hachage a un coût de démarrage supplémentaire pour créer sa table de hachage, mais un coût par ligne inférieur lorsqu'elle commence à rechercher des correspondances.
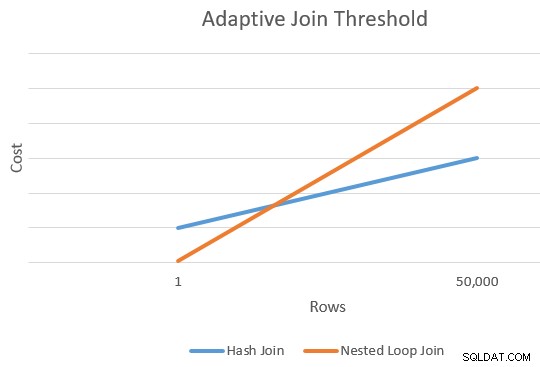
Il y a généralement un point où le coût estimé d'une jointure d'application et de hachage sera égal. Cette idée a été bien illustrée par Joe Sack dans son article, Introducing Batch Mode Adaptive Joins :
Calcul du seuil
À ce stade, l'optimiseur dispose d'une seule estimation du nombre de lignes entrant dans l'entrée de construction de la jointure de hachage et des alternatives d'application. Il a également le coût estimé du hachage et applique les opérateurs dans leur ensemble.
Cela nous donne un seul point à l'extrême droite des lignes orange et bleue dans le diagramme ci-dessus. L'optimiseur a besoin d'un autre point de référence pour chaque type de jointure afin qu'il puisse "tracer les lignes" et trouver l'intersection (il ne trace pas littéralement des lignes, mais vous voyez l'idée).
Pour trouver un deuxième point pour les lignes, l'optimiseur demande aux deux jointures de produire une nouvelle estimation de coût basée sur une cardinalité d'entrée différente (et hypothétique). Si la première estimation de cardinalité était supérieure à 100 lignes, il demande aux jointures d'estimer les nouveaux coûts pour une ligne. Si la cardinalité d'origine était inférieure ou égale à 100 lignes, le deuxième point est basé sur une cardinalité d'entrée de 10 000 lignes (il y a donc une plage suffisante pour extrapoler).
Dans tous les cas, le résultat est deux coûts et nombres de lignes différents pour chaque type de jointure, ce qui permet de "tracer" les lignes.
La formule d'intersection
Trouver l'intersection de deux lignes en fonction de deux points pour chaque ligne est un problème avec plusieurs solutions bien connues. SQL Server en utilise une basée sur des déterminants comme décrit sur Wikipédia :
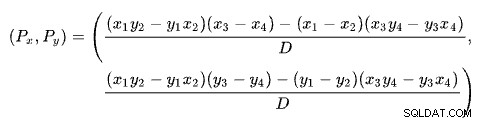
où :
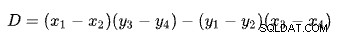
La première ligne est définie par les points (x1 , y1 ) et (x2 , y2 ). La deuxième ligne est donnée par les points (x3 , y3 ) et (x4 , y4 ). L'intersection est à (Px , Py ).
Notre schéma a le nombre de lignes sur l'axe des x et le coût estimé sur l'axe des y. Nous sommes intéressés par le nombre de lignes où les lignes se croisent. Ceci est donné par la formule pour Px . Si nous voulions connaître le coût estimé à l'intersection, ce serait Py .
Pour Px lignes, les coûts estimés des solutions d'application et de jointure par hachage seraient égaux. C'est le seuil adaptatif dont nous avons besoin.
Un exemple pratique
Voici un exemple utilisant l'exemple de base de données AdventureWorks2017 et l'astuce d'indexation suivante d'Itzik Ben-Gan pour obtenir une prise en compte inconditionnelle de l'exécution en mode batch :
-- Itzik's trick
CREATE NONCLUSTERED COLUMNSTORE INDEX BatchMode
ON Sales.SalesOrderHeader (SalesOrderID)
WHERE SalesOrderID = -1
AND SalesOrderID = -2;
-- Test query
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123; Le plan d'exécution affiche une jointure adaptative avec un seuil de 1 502,07 lignes :
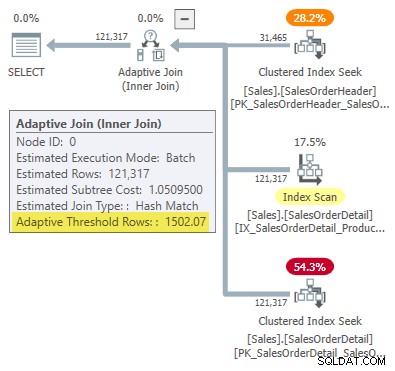
Le nombre estimé de lignes entraînant la jointure adaptative est de 31 465 .
Coûts d'adhésion
Dans ce cas simplifié, nous pouvons trouver les coûts de sous-arborescence estimés pour le hachage et appliquer des alternatives de jointure à l'aide d'astuces :
-- Hash
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (HASH JOIN, MAXDOP 1);

-- Apply
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (LOOP JOIN, MAXDOP 1);
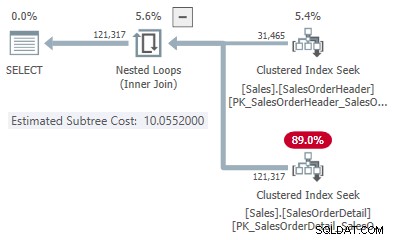
Cela nous donne un point sur la ligne pour chaque type de jointure :
- 31 465 lignes
- Coût de hachage 1,05083
- Appliquer le coût 10,0552
Le deuxième point sur la ligne
Étant donné que le nombre estimé de lignes est supérieur à 100, les deuxièmes points de référence proviennent d'estimations internes spéciales basées sur une ligne d'entrée de jointure. Malheureusement, il n'y a pas de moyen facile d'obtenir les chiffres exacts des coûts pour ce calcul interne (j'en reparlerai plus en détail sous peu).
Pour l'instant, je vais juste vous montrer les chiffres des coûts (en utilisant la précision interne complète plutôt que les six chiffres significatifs présentés dans les plans d'exécution) :
- Une ligne (calcul interne)
- Coût de hachage 0,999027422729
- Appliquer le coût 0,547927305023
- 31 465 lignes
- Coût de hachage 1,05082787359
- Appliquer le coût 10,0552890166
Comme prévu, la jointure d'application est moins chère que le hachage pour une petite cardinalité d'entrée, mais beaucoup plus chère pour la cardinalité attendue de 31 465 lignes.
Le calcul de l'intersection
En insérant ces numéros de cardinalité et de coût dans la formule d'intersection de ligne, vous obtenez ce qui suit :
-- Hash points (x = cardinality; y = cost)
DECLARE
@x1 float = 1,
@y1 float = 0.999027422729,
@x2 float = 31465,
@y2 float = 1.05082787359;
-- Apply points (x = cardinality; y = cost)
DECLARE
@x3 float = 1,
@y3 float = 0.547927305023,
@x4 float = 31465,
@y4 float = 10.0552890166;
-- Formula:
SELECT Threshold =
(
(@x1 * @y2 - @y1 * @x2) * (@x3 - @x4) -
(@x1 - @x2) * (@x3 * @y4 - @y3 * @x4)
)
/
(
(@x1 - @x2) * (@y3 - @y4) -
(@y1 - @y2) * (@x3 - @x4)
);
-- Returns 1502.06521571273 Arrondi à six chiffres significatifs, ce résultat correspond au 1502.07 lignes affichées dans le plan d'exécution de la jointure adaptative :
Défaut ou conception ?
N'oubliez pas que SQL Server a besoin de quatre points pour "dessiner" le nombre de lignes par rapport aux lignes de coût pour trouver le seuil de jointure adaptative. Dans le cas présent, cela signifie trouver des estimations de coût pour les cardinalités à une ligne et à 31 465 lignes pour les implémentations d'application et de jointure par hachage.
L'optimiseur appelle une routine nommée sqllang!CuNewJoinEstimate pour calculer ces quatre coûts pour une jointure adaptative. Malheureusement, il n'y a pas d'indicateurs de trace ou d'événements étendus pour fournir un aperçu pratique de cette activité. Les indicateurs de trace normaux utilisés pour étudier le comportement de l'optimiseur et afficher les coûts ne fonctionnent pas ici (voir l'annexe si vous souhaitez plus de détails).
Le seul moyen d'obtenir les estimations de coût sur une ligne consiste à attacher un débogueur et à définir un point d'arrêt après le quatrième appel à CuNewJoinEstimate dans le code de sqllang!CardSolveForSwitch . J'ai utilisé WinDbg pour obtenir cette pile d'appels sur SQL Server 2019 CU12 :

À ce stade du code, les coûts en virgule flottante double précision sont stockés dans quatre emplacements de mémoire pointés par des adresses à rsp+b0 , rsp+d0 , rsp+30 , et rsp+28 (où rsp est un registre CPU et les décalages sont en hexadécimal):

Les numéros de coût de la sous-arborescence de l'opérateur affichés correspondent à ceux utilisés dans la formule de calcul du seuil de jointure adaptative.
À propos de ces estimations de coût à une ligne
Vous avez peut-être remarqué que les coûts estimés des sous-arborescences pour les jointures à une ligne semblent assez élevés pour la quantité de travail nécessaire pour joindre une ligne :
- Une ligne
- Coût de hachage 0,999027422729
- Appliquer le coût 0,547927305023
Si vous essayez de produire des plans d'exécution d'entrée à une ligne pour la jointure de hachage et d'appliquer des exemples, vous verrez beaucoup coûts de sous-arborescence estimés inférieurs à la jointure que ceux indiqués ci-dessus. De même, l'exécution de la requête d'origine avec un objectif de ligne de un (ou le nombre de lignes de sortie de jointure attendues pour une entrée d'une ligne) produira également un coût estimé manière inférieur à celui indiqué.
La raison est CuNewJoinEstimate la routine estime la valeur sur une ligne cas d'une manière que je pense que la plupart des gens ne trouveraient pas intuitive.
Le coût final est composé de trois éléments principaux :
- Le coût de la sous-arborescence d'entrée de construction
- Le coût local de la jointure
- Le coût du sous-arbre d'entrée de la sonde
Les éléments 2 et 3 dépendent du type de jointure. Pour une jointure par hachage, ils représentent le coût de la lecture de toutes les lignes à partir de l'entrée de la sonde, de leur correspondance (ou non) avec la ligne de la table de hachage et de la transmission des résultats à l'opérateur suivant. Pour une application, les coûts couvrent une recherche sur l'entrée inférieure de la jointure, le coût interne de la jointure elle-même et le renvoi des lignes correspondantes à l'opérateur parent.
Rien de tout cela n'est inhabituel ou surprenant.
La surprise du coût
La surprise vient du côté construction de la jointure (élément 1 de la liste). On pourrait s'attendre à ce que l'optimiseur fasse des calculs sophistiqués pour réduire le coût du sous-arbre déjà calculé pour 31 465 lignes à une ligne moyenne, ou quelque chose comme ça.
En fait, les estimations de hachage et d'application de jointure sur une ligne utilisent simplement le coût total du sous-arbre pour l'original estimation de cardinalité de 31 465 lignes. Dans notre exemple d'exécution, ce "sous-arbre" est le 0.54456 coût de la recherche d'index clusterisé en mode batch sur la table d'en-tête :
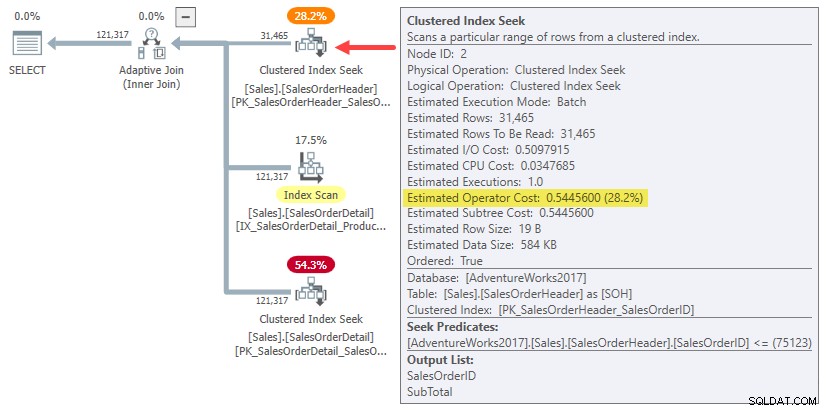
Pour être clair :les coûts estimés côté construction pour les alternatives de jointure à une ligne utilisent un coût d'entrée calculé pour 31 465 lignes. Cela devrait vous sembler un peu étrange.
Pour rappel, les coûts d'une ligne calculés par CuNewJoinEstimate étaient les suivants :
- Une ligne
- Coût de hachage 0,999027422729
- Appliquer le coût 0,547927305023
Vous pouvez voir que le coût total d'application (~0,54793) est dominé par 0,54456 coût de la sous-arborescence côté construction, avec un petit supplément pour la recherche interne unique, traitant le petit nombre de lignes résultantes dans la jointure et les transmettant à l'opérateur parent.
Le coût estimé de la jointure de hachage à une ligne est plus élevé car le côté sonde du plan consiste en une analyse complète de l'index, où toutes les lignes résultantes doivent passer par la jointure. Le coût total de la jointure par hachage à une ligne est légèrement inférieur au coût initial de 1,05095 pour l'exemple de 31 465 lignes, car il n'y a plus qu'une seule ligne dans la table de hachage.
Implications
On pourrait s'attendre à ce qu'une estimation de jointure à une ligne soit basée, en partie, sur le coût de livraison d'une ligne à l'entrée de jointure de conduite. Comme nous l'avons vu, ce n'est pas le cas pour une jointure adaptative :les alternatives d'application et de hachage sont soumises au coût total estimé pour 31 465 lignes. Le reste de la jointure est facturé à peu près comme on pourrait s'y attendre pour une entrée de construction à une ligne.
Cet arrangement intuitivement étrange est la raison pour laquelle il est difficile (voire impossible) de montrer un plan d'exécution reflétant les coûts calculés. Nous aurions besoin de construire un plan fournissant 31 465 lignes à l'entrée de jointure supérieure, mais en coûtant la jointure elle-même et son entrée interne comme si une seule ligne était présente. Une question difficile.
L'effet de tout cela est d'élever le point le plus à gauche sur notre diagramme de lignes d'intersection sur l'axe des ordonnées. Cela affecte la pente de la ligne et donc le point d'intersection.
Un autre effet pratique est que le seuil de jointure adaptative calculé dépend désormais de l'estimation de cardinalité d'origine à l'entrée de construction de hachage, comme l'a noté Joe Obbish dans son article de blog de 2017. Par exemple, si nous modifions le WHERE clause dans la requête de test à SOH.SalesOrderID <= 55000 , le seuil adaptatif réduit de 1502.07 à 1259.8 sans modifier le hachage du plan de requête. Même plan, seuil différent.
Cela se produit parce que, comme nous l'avons vu, l'estimation du coût interne d'une ligne dépend du coût d'entrée de construction pour l'estimation de cardinalité d'origine. Cela signifie que différentes estimations initiales côté construction donneront un «coup de pouce» différent sur l'axe y à l'estimation à une ligne. À son tour, la ligne aura une pente différente et un point d'intersection différent.
L'intuition suggérerait que l'estimation d'une ligne pour la même jointure devrait toujours donner la même valeur quelle que soit l'autre estimation de cardinalité sur la ligne (étant donné que la même jointure exacte avec les mêmes propriétés et tailles de ligne a une relation proche de linéaire entre la conduite lignes et coût). Ce n'est pas le cas pour une jointure adaptative.
Par conception ?
Je peux vous dire en toute confiance ce que SQL Server fait lors du calcul du seuil de jointure adaptative. Je n'ai aucune idée particulière de pourquoi il le fait de cette façon.
Pourtant, il y a des raisons de penser que cet arrangement est délibéré et a été réalisé après mûre réflexion et après les commentaires des tests. Le reste de cette section couvre certaines de mes réflexions sur cet aspect.
Une jointure adaptative n'est pas un choix direct entre une jointure par hachage en mode application normale et par lots. Une jointure adaptative commence toujours par remplir entièrement la table de hachage. Ce n'est qu'une fois ce travail terminé que la décision est prise de passer ou non à une implémentation d'application.
À ce stade, nous avons déjà engagé des coûts potentiellement importants en remplissant et en partitionnant la jointure de hachage en mémoire. Cela n'a peut-être pas beaucoup d'importance pour le cas à une ligne, mais cela devient progressivement plus important à mesure que la cardinalité augmente. Le « boost » inattendu peut être un moyen d'intégrer ces réalités dans le calcul tout en conservant un coût de calcul raisonnable.
Le modèle de coût de SQL Server a longtemps été un peu biaisé par rapport aux jointures de boucles imbriquées, sans doute avec une certaine justification. Même le cas d'application indexé idéal peut être lent en pratique si les données nécessaires ne sont pas déjà en mémoire et que le sous-système d'E / S n'est pas flash, en particulier avec un modèle d'accès quelque peu aléatoire. Des quantités limitées de mémoire et des E/S lentes ne seront pas tout à fait inconnues des utilisateurs de moteurs de base de données bas de gamme basés sur le cloud, par exemple.
Il est possible que des tests pratiques dans de tels environnements aient révélé qu'une jointure adaptative intuitivement chiffrée était trop rapide pour passer à une application. La théorie n'est parfois excellente qu'en théorie.
Pourtant, la situation actuelle n'est pas idéale; la mise en cache d'un plan basé sur une estimation de cardinalité inhabituellement faible produira une jointure adaptative beaucoup plus réticente à passer à une application qu'elle ne l'aurait été avec une estimation initiale plus importante. Il s'agit d'une variété du problème de sensibilité aux paramètres, mais ce sera une nouvelle considération de ce type pour beaucoup d'entre nous.
Maintenant, c'est aussi possible l'utilisation du coût complet du sous-arbre d'entrée de construction pour le point le plus à gauche des lignes de coût d'intersection est simplement une erreur ou un oubli non corrigé. Mon sentiment est que l'implémentation actuelle est probablement un compromis pratique délibéré, mais vous auriez besoin de quelqu'un ayant accès aux documents de conception et au code source pour en être sûr.
Résumé
Une jointure adaptative permet à SQL Server de passer d'une jointure de hachage en mode batch à une application une fois que la table de hachage a été entièrement remplie. Il prend cette décision en comparant le nombre de lignes de la table de hachage avec un seuil adaptatif précalculé.
Le seuil est calculé en prédisant où les coûts d'application et de jointure de hachage sont égaux. Pour trouver ce point, SQL Server produit une deuxième estimation du coût de jointure interne pour une cardinalité d'entrée de build différente, normalement une ligne.
Étonnamment, le coût estimé pour l'estimation à une ligne inclut le coût total du sous-arbre côté construction pour l'estimation de cardinalité d'origine (non mis à l'échelle sur une ligne). Cela signifie que la valeur de seuil dépend de l'estimation de cardinalité d'origine à l'entrée de construction.
Par conséquent, une jointure adaptative peut avoir une valeur de seuil étonnamment basse, ce qui signifie que la jointure adaptative est beaucoup moins susceptible de s'éloigner d'une jointure par hachage. Il n'est pas clair si ce comportement est intentionnel.
Lecture connexe
- Présentation des jointures adaptatives en mode batch par Joe Sack
- Comprendre les jointures adaptatives dans la documentation du produit
- Internes de jointure adaptative par Dima Pilugin
- Comment fonctionnent les jointures adaptatives en mode batch ? sur Database Administrators Stack Exchange par Erik Darling
- Une régression de jointure adaptative par Joe Obbish
- Si vous voulez des jointures adaptatives, vous avez besoin d'index plus larges et est-ce mieux ? par Erik Darling
- Renifleur de paramètres :jointures adaptatives par Brent Ozar
- Questions et réponses sur le traitement intelligent des requêtes par Joe Sack
Annexe
Cette section couvre quelques aspects de jointure adaptative qui étaient difficiles à inclure dans le texte principal de manière naturelle.
Le plan adaptatif étendu
Vous pouvez essayer de regarder une représentation visuelle du plan interne en utilisant l'indicateur de trace non documenté 9415, tel que fourni par Dima Pilugin dans son excellent article interne sur les jointures adaptatives lié ci-dessus. Avec cet indicateur actif, le plan de jointure adaptative pour notre exemple en cours d'exécution devient le suivant :
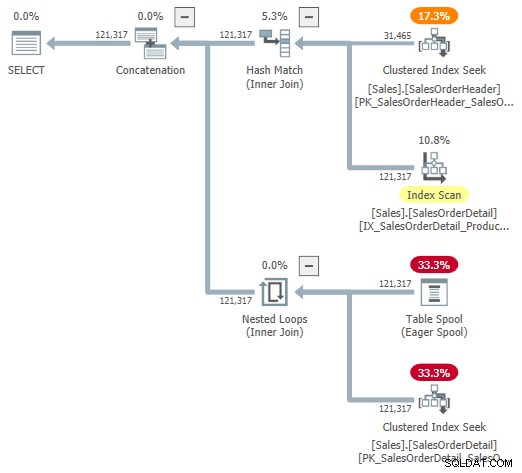
Il s'agit d'une représentation utile pour faciliter la compréhension, mais elle n'est pas entièrement exacte, complète ou cohérente. Par exemple, le spool de table n'existe pas :il s'agit d'une représentation par défaut pour le lecteur de tampon adaptatif lire les lignes directement à partir de la table de hachage en mode batch.
Les propriétés de l'opérateur et les estimations de cardinalité sont également un peu partout. La sortie du lecteur de tampon adaptatif ("spool") doit être de 31 465 lignes, et non de 121 317. Le coût du sous-arbre de l'application est incorrectement plafonné par le coût de l'opérateur parent. C'est normal pour showplan, mais cela n'a aucun sens dans un contexte de jointure adaptative.
Il existe également d'autres incohérences - trop nombreuses pour être énumérées de manière utile - mais cela peut se produire avec des indicateurs de trace non documentés. Le plan étendu présenté ci-dessus n'est pas destiné à être utilisé par les utilisateurs finaux, il n'est donc peut-être pas tout à fait surprenant. Le message ici est de ne pas trop se fier aux chiffres et aux propriétés indiqués dans ce formulaire non documenté.
Je devrais également mentionner en passant que l'opérateur de plan de jointure adaptatif standard fini n'est pas entièrement sans ses propres problèmes de cohérence. Celles-ci proviennent à peu près exclusivement des détails cachés.
Par exemple, les propriétés de jointure adaptative affichées proviennent d'un mélange du Concat sous-jacent. , jointure par hachage , et Appliquer les opérateurs. Vous pouvez voir une jointure adaptative signaler l'exécution en mode batch pour la jointure de boucles imbriquées (ce qui est impossible), et le temps écoulé affiché est en fait copié à partir du Concat caché , pas la jointure particulière exécutée lors de l'exécution.
Les suspects habituels
Nous pouvons obtenir des informations utiles à partir des types d'indicateurs de trace non documentés normalement utilisés pour examiner la sortie de l'optimiseur. Par exemple :
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (
QUERYTRACEON 3604,
QUERYTRACEON 8607,
QUERYTRACEON 8612); Sortie (fortement modifiée pour plus de lisibilité) :
*** Arbre de sortie :***PhyOp_ExecutionModeAdapter(BatchToRow) Card=121317 Cost=1.05095
- PhyOp_Concat (lot) Carte=121317 Coût=1,05325
- PhyOp_HashJoinx_jtInner (lot) Card=121317 Cost=1.05083
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Cost=0.54456
- PhyOp_Filter(batch) Card=121317 Cost=0.397185
- PhyOp_Range Sales.SalesOrderDetail Card=121317 Cost=0.338953
- PhyOp_ExecutionModeAdapter(RowToBatch) Card=121317 Cost=10.0798
- PhyOp_Apply Card=121317 Cost=10.0553
- PhyOp_ExecutionModeAdapter(BatchToRow) Card=31465 Cost=0.544623
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Cost=0.54456 [** 3 **]
- Carte PhyOp_Filter=3.85562 Coût=9.00356
- PhyOp_Range Sales.SalesOrderDetail Card=3.85562 Cost=8.94533
- PhyOp_ExecutionModeAdapter(BatchToRow) Card=31465 Cost=0.544623
- PhyOp_Apply Card=121317 Cost=10.0553
Cela donne un aperçu des coûts estimés pour le cas de cardinalité complète avec hachage et applique des alternatives sans écrire de requêtes séparées et en utilisant des conseils. Comme mentionné dans le texte principal, ces indicateurs de trace ne sont pas efficaces dans CuNewJoinEstimate , nous ne pouvons donc pas voir directement les calculs répétés pour le cas de 31 465 lignes ou les détails des estimations à une ligne de cette manière.
Jointure par fusion et jointure par hachage en mode ligne
Les jointures adaptatives n'offrent qu'une transition de la jointure par hachage en mode par lots au mode ligne. Pour les raisons pour lesquelles la jointure par hachage en mode ligne n'est pas prise en charge, consultez les questions et réponses sur le traitement intelligent des requêtes dans la section Lecture connexe. En bref, on pense que les jointures par hachage en mode ligne seraient trop sujettes aux régressions de performances.
Passer à une jointure de fusion en mode ligne serait une autre option, mais l'optimiseur n'en tient pas compte actuellement. Si je comprends bien, il est peu probable qu'il soit étendu dans cette direction à l'avenir.
Certaines des considérations sont les mêmes que pour la jointure par hachage en mode ligne. De plus, les plans de jointure par fusion ont tendance à être moins facilement interchangeables avec la jointure par hachage, même si nous nous limitons à la jointure par fusion indexée (pas de tri explicite).
Il existe également une distinction beaucoup plus grande entre le hachage et l'application qu'entre le hachage et la fusion. Le hachage et la fusion conviennent aux entrées plus importantes, et l'application est mieux adaptée à une entrée de conduite plus petite. La jointure par fusion n'est pas aussi facilement parallélisée que la jointure par hachage et n'évolue pas aussi bien avec l'augmentation du nombre de threads.
Étant donné que la motivation des jointures adaptatives est de mieux gérer de manière significative différentes tailles d'entrée - et seule la jointure par hachage prend en charge le traitement en mode batch - le choix du hachage par lot par rapport à l'application de ligne est le plus naturel. Enfin, avoir trois choix de jointure adaptative compliquerait considérablement le calcul du seuil pour un gain potentiellement faible.