Les fonctions OVER et PARTITION BY sont toutes deux des fonctions utilisées pour fractionner un ensemble de résultats selon des critères spécifiés.
Cet article explique comment ces deux fonctions peuvent être utilisées conjointement pour récupérer des données partitionnées de manière très spécifique.
Préparer quelques exemples de données
Pour exécuter nos exemples de requêtes, créons d'abord une base de données nommée "studentdb".
Exécutez la commande suivante dans votre fenêtre de requête :
CRÉER BASE DE DONNÉES schooldb ;
Ensuite, nous devons créer la table "student" dans la base de données "studentdb". Le tableau des étudiants comportera cinq colonnes :id, name, age, gender et total_score.
Comme toujours, assurez-vous d'être bien sauvegardé avant d'expérimenter un nouveau code. Consultez cet article sur la sauvegarde des bases de données SQL Server si vous n'êtes pas sûr.
Exécutez la requête suivante pour créer la table des étudiants.
USE schooldbCREATE TABLE étudiant( id INT PRIMARY KEY IDENTITY, name VARCHAR(50) NOT NULL, gender VARCHAR(50) NOT NULL, age INT NOT NULL, total_score INT NOT NULL, )
Enfin, nous devons insérer des données factices avec lesquelles nous pourrons travailler dans la base de données.
USE schooldbINSERT INTO student VALUES ('Jolly', 'Female', 20, 500), ('Jon', 'Male', 22, 545), ('Sara', 'Female', 25, 600), ('Laura', 'Femme', 18, 400), ('Alan', 'Homme', 20, 500), ('Kate', 'Femme', 22, 500), ('Joseph', 'Homme' , 18, 643), ('Souris', 'Mâle', 23, 543), ('Sage', 'Mâle', 21, 499), ('Elis', 'Femelle', 27, 400);
Nous sommes maintenant prêts à travailler sur un problème et à voir qui nous pouvons utiliser Over et Partition By pour le résoudre.
Problème
Nous avons 10 enregistrements dans la table des étudiants et nous souhaitons afficher le nom, l'identifiant et le sexe de tous les étudiants. De plus, nous souhaitons également afficher le nombre total d'étudiants appartenant à chaque sexe, l'âge moyen des étudiants de chaque sexe et la somme des valeurs dans la colonne total_score pour chaque sexe.
L'ensemble de résultats que nous recherchons est le suivant :
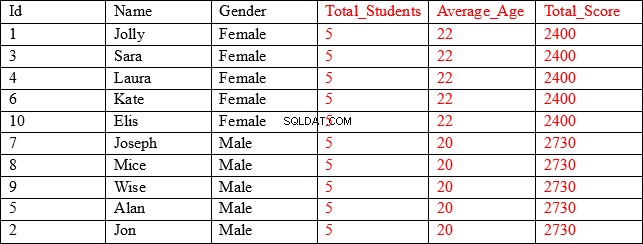
Comme vous pouvez le voir, les trois premières colonnes (affichées en noir) contiennent des valeurs individuelles pour chaque enregistrement, tandis que les trois dernières colonnes (affichées en rouge) contiennent des valeurs agrégées regroupées par la colonne sexe. Par exemple, dans la colonne Average_Age, les cinq premières lignes affichent l'âge moyen et le score total de tous les enregistrements où le sexe est Femme.
Notre jeu de résultats contient des résultats agrégés joints à des colonnes non agrégées.
Pour récupérer les résultats agrégés, regroupés par une colonne particulière, nous pouvons utiliser la clause GROUP BY comme d'habitude.
USE schooldbSELECT gender, count(gender) AS Total_Students, AVG(age) as Average_Age, SUM(total_score) as Total_ScoreFROM studentGROUP BY gender
Voyons comment nous pouvons récupérer Total_Students, Average_Age et Total_Score des étudiants regroupés par sexe.
Vous verrez les résultats suivants :

Maintenant, étendons cela et ajoutons 'id' et 'name' (les colonnes non agrégées dans l'instruction SELECT) et voyons si nous pouvons obtenir le résultat souhaité.
USE schooldbSELECT id, name, gender, count(gender) AS total_students, AVG(age) as Average_Age, SUM(total_score) as Total_ScoreFROM studentGROUP BY gender
Lorsque vous exécuterez la requête ci-dessus, vous verrez une erreur :

L'erreur indique que la colonne id de la table des étudiants n'est pas valide dans l'instruction SELECT puisque nous utilisons la clause GROUP BY dans la requête.
Cela signifie que nous devrons appliquer une fonction d'agrégation sur la colonne id ou nous devrons l'utiliser dans la clause GROUP BY. Bref, ce schéma ne résout pas notre problème.
Solution utilisant l'instruction JOIN
Une solution à cela serait d'utiliser l'instruction JOIN pour joindre les colonnes avec des résultats agrégés aux colonnes contenant des résultats non agrégés.
Pour ce faire, vous avez besoin d'une sous-requête qui récupère le sexe, Total_Students, Average_Age et le Total_Score des étudiants regroupés par sexe. Ces résultats peuvent ensuite être joints aux résultats obtenus à partir de la sous-requête avec l'instruction SELECT externe. Ceci sera appliqué à la colonne sexe de la sous-requête contenant le résultat agrégé et à la colonne sexe de la table des étudiants. L'instruction SELECT externe inclurait des colonnes non agrégées, c'est-à-dire 'id' et 'name', comme ci-dessous.
USE schooldbSELECT id, name, Aggregation.gender, Aggregation.Total_students, Aggregation.Average_Age, Aggregation.Total_ScoreFROM studentINNER JOIN(SELECT gender, count(sexe) AS Total_students, AVG(age) AS Average_Age, SUM(total_score) AS Total_ScoreFROM studentGROUP BY gender) AS Aggregationon Aggregation.gender =student.gender
La requête ci-dessus vous donnera le résultat souhaité mais n'est pas la solution optimale. Nous avons dû utiliser une instruction JOIN et une sous-requête qui augmente la complexité du script. Ce n'est pas une solution élégante ou efficace.
Une meilleure approche consiste à utiliser les clauses OVER et PARTITION BY conjointement.
Solution utilisant OVER et PARTITION BY
Pour utiliser les clauses OVER et PARTITION BY, il vous suffit de spécifier la colonne par laquelle vous souhaitez partitionner vos résultats agrégés. Ceci est mieux expliqué à l'aide d'un exemple.
Voyons comment obtenir notre résultat en utilisant OVER et PARTITION BY.
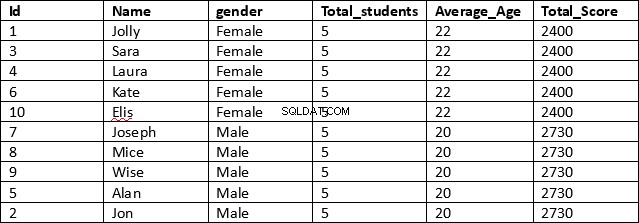
USE schooldbSELECT id, name, gender,COUNT(sexe) OVER (PARTITION BY gender) AS Total_students,AVG(age) OVER (PARTITION BY gender) AS Average_Age,SUM(total_score) OVER (PARTITION BY gender) AS Total_ScoreFROM étudiant
C'est un résultat beaucoup plus efficace. Dans la première ligne du script, les colonnes id, name et gender sont récupérées. Ces colonnes ne contiennent aucun résultat agrégé.
Ensuite, pour les colonnes qui contiennent des résultats agrégés, nous spécifions simplement la fonction agrégée, suivie de la clause OVER puis, entre parenthèses, nous spécifions la clause PARTITION BY suivie du nom de la colonne que nous voulons que nos résultats soient partitionnés comme indiqué ci-dessous.
Références
- Microsoft – Comprendre la clause OVER
- Midnight DBA – Introduction à OVER et PARTITION BY
- StackOverflow - Différence entre PARTITION BY et GROUP BY