L'exécution d'un cluster Galera dans un cloud hybride doit consister en au moins deux sites géographiques différents, connectant les hôtes du cloud sur site ou privé avec ceux du cloud public. Que vous utilisiez des plates-formes de cloud privé ou de cloud public incassables, la reprise après sinistre (DR) est en effet un problème clé. Il ne s'agit pas de copier vos données sur un site de sauvegarde et de pouvoir les restaurer, il s'agit de la continuité des activités et de la rapidité avec laquelle vous pouvez récupérer les services en cas de catastrophe.
Dans cet article de blog, nous examinerons différentes manières de concevoir vos clusters Galera pour la tolérance aux pannes dans un environnement de cloud hybride.
Configuration active-active
Galera Cluster doit fonctionner avec un nombre total impair de nœuds dans un cluster, et commence généralement avec 3 nœuds. En effet, Galera Cluster utilise le quorum pour déterminer automatiquement le composant principal, où une majorité de nœuds connectés devraient pouvoir servir le cluster à la fois, en cas de partitionnement du cluster.
Pour une configuration de cloud hybride à configuration active-active, Galera nécessite au moins 3 sites différents, formant un cluster Galera sur le WAN. Généralement, vous auriez besoin d'un troisième site pour agir en tant qu'arbitre, votant pour le quorum et préservant le "composant principal" si l'un des sites est inaccessible. Cela peut être mis en place au minimum d'un cluster de 3 nœuds sur 3 sites différents (1 nœud par site), similaire au schéma suivant :
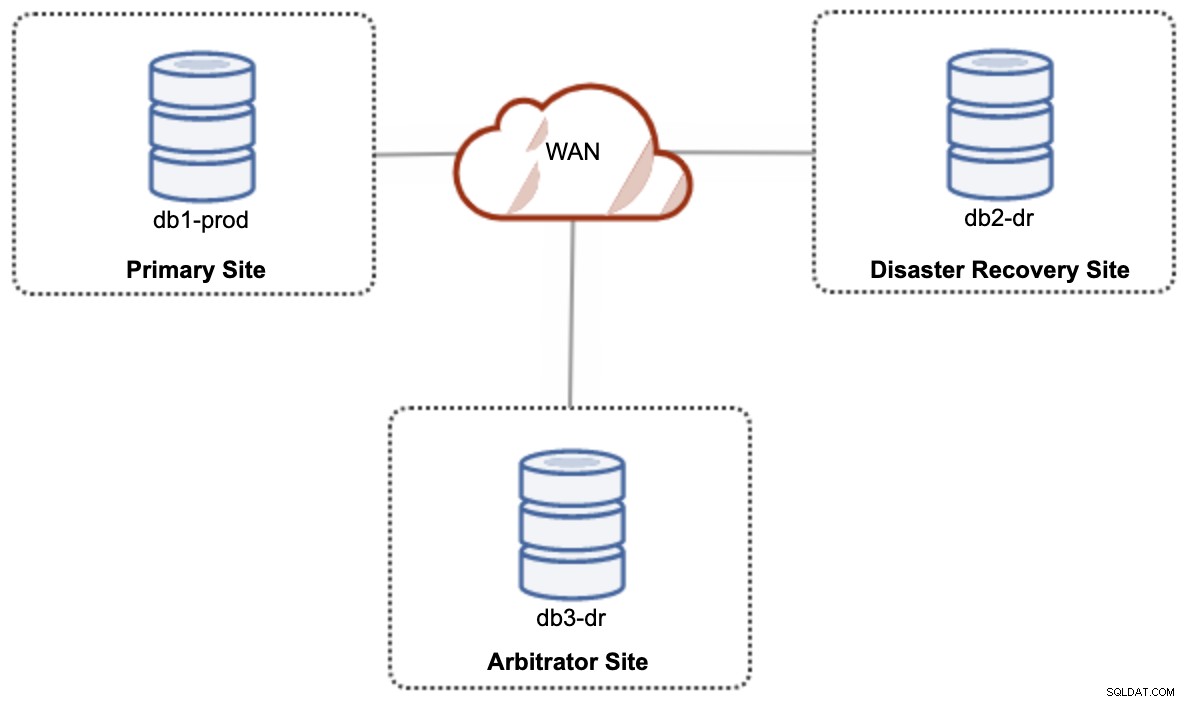
Cependant, pour des raisons de performances et de fiabilité, il est recommandé d'avoir un 7 -cluster de nœuds, comme illustré dans le schéma suivant :
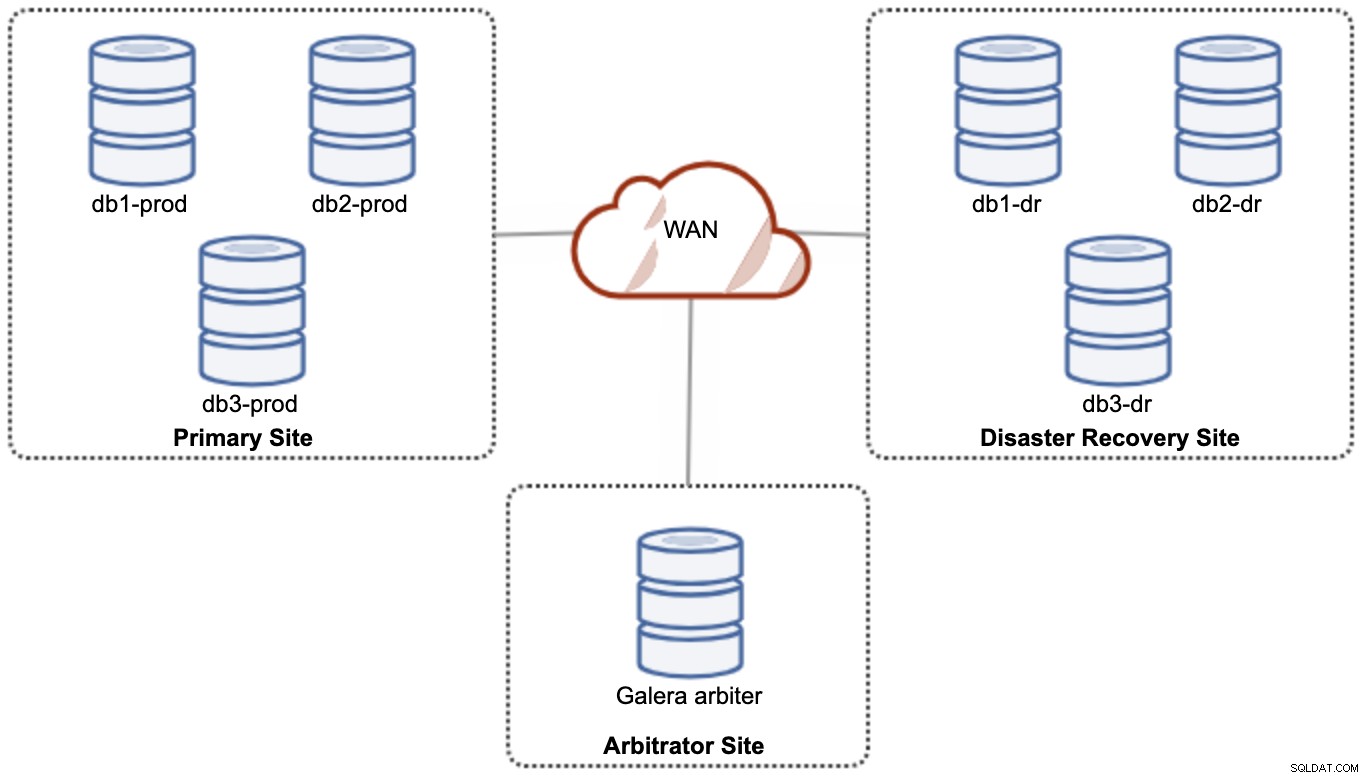
Ceci est considéré comme la meilleure topologie pour prendre en charge une configuration active-active, où le site DR doit être disponible presque immédiatement, sans aucune intervention. Les deux sites peuvent recevoir des lectures/écritures à tout moment à condition que le cluster soit dans le quorum.
Cependant, il est très coûteux d'avoir 3 sites et 7 nœuds de base de données (le 7e nœud peut être remplacé par un garbd car il est très peu susceptible d'être utilisé pour fournir des données aux clients/applications). Ce déploiement n'est généralement pas populaire au début du projet en raison de l'énorme coût initial et de la sensibilité de la communication et de la réplication du groupe Galera à la latence du réseau.
Configuration active-passive
Dans une configuration active-passive, au moins 2 sites sont requis et un seul site est actif à la fois, appelé site principal et les nœuds sur le site secondaire ne répliquent que les données provenant du site principal serveur/grappe. Pour Galera Cluster, nous pouvons utiliser la réplication asynchrone MySQL (réplication maître-esclave) ou nous pouvons également utiliser la réplication virtuellement synchrone de Galera avec quelques réglages pour atténuer sa réplication en écriture afin qu'elle agisse comme une réplication asynchrone.
Le site secondaire doit être protégé contre les écritures accidentelles, en utilisant le drapeau de lecture seule, le pare-feu applicatif, le proxy inverse ou tout autre moyen puisque le flux de données provient toujours du site principal vers le site secondaire, sauf si un basculement a initié et promu le site secondaire en tant que site principal.
Utiliser la réplication asynchrone
Une bonne chose à propos de la réplication asynchrone est que la réplication n'a pas d'impact sur le serveur/cluster source, mais qu'elle peut être en retard sur le maître. Cette configuration rendra le site principal et le site DR indépendants l'un de l'autre, faiblement connectés avec une réplication asynchrone. Cela peut être configuré comme un cluster de 4 nœuds minimum sur 2 sites différents, similaire au schéma suivant :
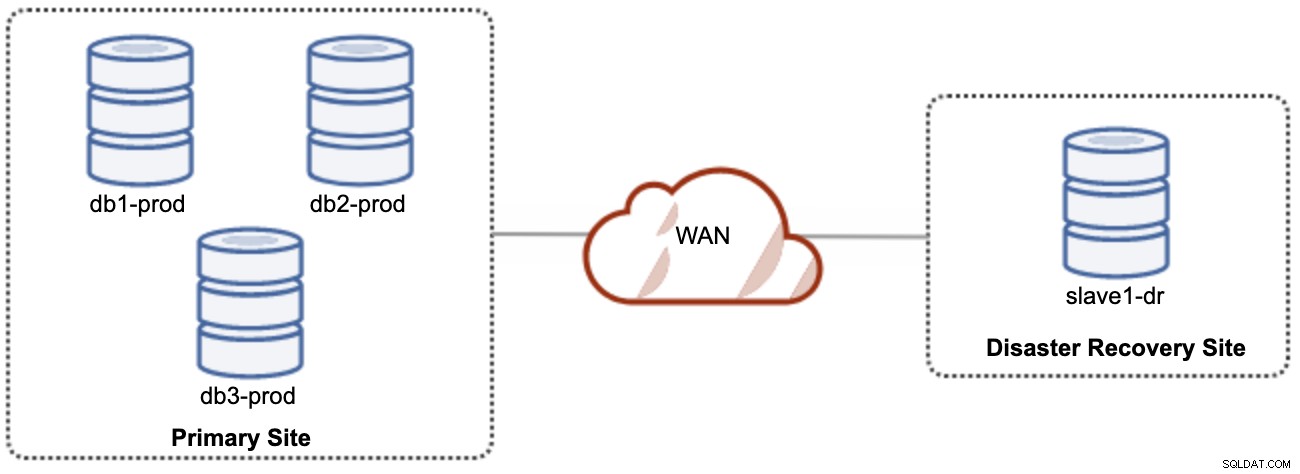
L'un des nœuds Galera du site DR sera un esclave, qui se répliquera à partir de l'un des nœuds Galera (maître) du site principal. Les deux sites doivent produire des journaux binaires avec GTID et log_slave_updates sont activés - les mises à jour provenant du flux de réplication asynchrone seront appliquées aux autres nœuds du cluster. Cependant, pour une utilisation en production, nous vous recommandons d'avoir deux ensembles de clusters sur les deux sites, comme illustré dans le schéma suivant :
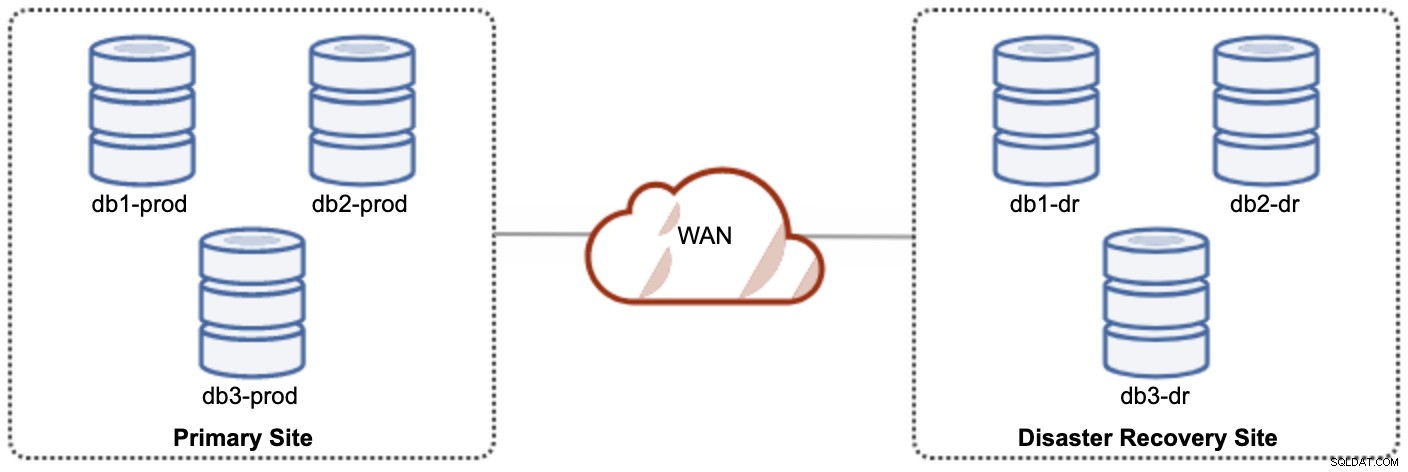
En ayant deux clusters séparés, ils seront faiblement couplés et n'auront pas d'impact l'un sur l'autre, par ex. une panne de cluster sur le site principal n'affectera pas le site DR. En termes de performances, la latence WAN n'aura pas d'impact sur les mises à jour sur le cluster actif. Ceux-ci sont expédiés de manière asynchrone vers le site de sauvegarde. Le cluster DR peut potentiellement s'exécuter sur des instances plus petites dans un environnement de cloud public, tant qu'elles peuvent suivre le cluster principal. Les instances peuvent être mises à niveau si nécessaire. Les applications doivent envoyer des écritures au site principal et le site secondaire doit être configuré pour s'exécuter en mode lecture seule. Le site de récupération après sinistre peut être utilisé à d'autres fins telles que la sauvegarde de la base de données, la sauvegarde des journaux binaires et la création de rapports ou le traitement de requêtes analytiques (OLAP).
En revanche, il y a un risque de perte de données lors du basculement/retour si l'esclave était en retard. Par conséquent, il est recommandé d'activer la réplication semi-synchrone pour réduire le risque de perte de données. Notez que l'utilisation de la réplication semi-synchrone ne fournit toujours pas de garanties solides contre la perte de données, si on la compare à la réplication virtuellement synchrone de Galera. Lisez attentivement ce manuel MySQL, par exemple ces phrases :
"Avec la réplication semi-synchrone, si la source tombe en panne et qu'un basculement vers une réplique est effectué, la source défaillante ne doit pas être réutilisée comme source de réplication et doit être supprimée. Elle pourrait avoir des transactions qui ont été non reconnues par aucune réplique, qui n'ont donc pas été validées avant le basculement."
Le processus de basculement est assez simple. Pour promouvoir le site de récupération après sinistre, désactivez simplement l'indicateur de lecture seule et commencez à diriger l'application vers les nœuds de base de données du site DR. La stratégie de secours est cependant un peu délicate et nécessite une certaine expertise dans la mise en scène des données sur les deux sites, la commutation du rôle maître/esclave d'un cluster et la redirection du flux de réplication esclave dans le sens opposé.
Utiliser la réplication Galera
Pour une configuration active-passive, nous pouvons placer la majorité des nœuds situés dans le site principal tandis que la minorité des nœuds situés dans le site de reprise après sinistre, comme illustré dans la capture d'écran suivante pour un 3- noeud Grappe Galera :
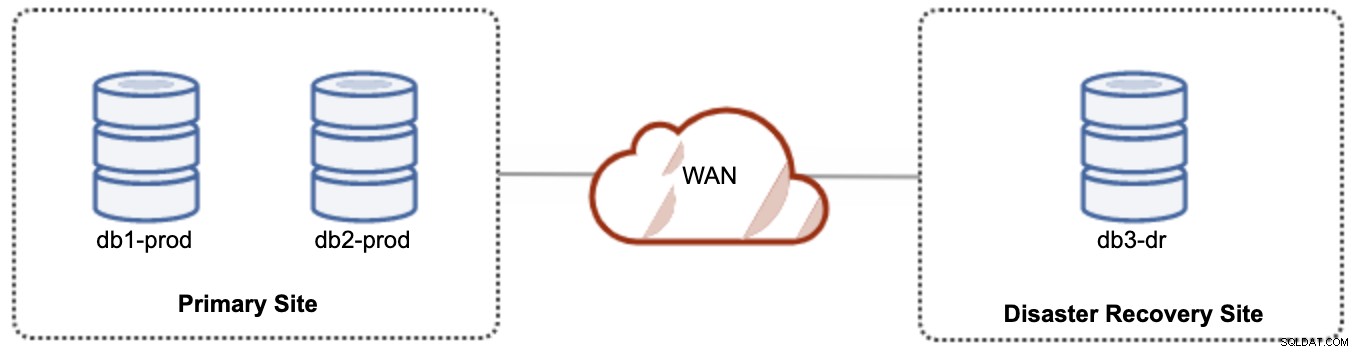
Si le site principal est en panne, le cluster échouera car il n'a plus de quorum. Le nœud Galera sur le site de reprise après sinistre (db3-dr) devra être démarré manuellement en tant que composant principal à nœud unique. Une fois le site principal redémarré, les deux nœuds du site principal (db1-prod et db2-prod) doivent rejoindre galera3 pour être synchronisés. Avoir un gcache assez volumineux devrait aider à réduire le risque de SST sur le WAN. Cette architecture est facile à configurer et à administrer et très économique.
Le basculement est manuel, car l'administrateur doit promouvoir le nœud unique en tant que composant principal (bootstrap db3-dr ou utilisez set pc.bootstrap=1 dans le paramètre wsrep_provider_options. Il y aurait un temps d'arrêt entre-temps . Les performances peuvent être un problème, car le site DR s'exécutera avec un plus petit nombre de nœuds (puisque le site DR est toujours minoritaire) pour exécuter toute la charge. Il peut être possible d'effectuer un scale-out avec plus de nœuds après le passage au DR site mais attention à la charge supplémentaire.
Notez que Galera Cluster est sensible au réseau en raison de sa nature virtuellement synchrone. Plus les nœuds Galera sont éloignés dans un cluster donné, plus la latence et sa capacité d'écriture pour distribuer et certifier les jeux d'écriture sont élevées. De plus, si la connectivité n'est pas stable, le partitionnement du cluster peut facilement se produire, ce qui peut déclencher la synchronisation du cluster sur les nœuds de jointure. Dans certains cas, cela peut introduire une instabilité dans le cluster. Cela nécessite un peu de réglage sur les paramètres de Galera, comme indiqué dans ce billet de blog, Déploiement d'un environnement d'infrastructure hybride pour le cluster Percona XtraDB.
Réflexions finales
Galera Cluster est une excellente technologie qui peut être déployée de différentes manières :un cluster étendu sur plusieurs sites, plusieurs clusters synchronisés via la réplication asynchrone, un mélange de réplication synchrone et asynchrone, etc. La solution réelle sera dictée par des facteurs tels que la latence WAN, la cohérence des données éventuelle ou forte et le budget.