Dans plusieurs de mes messages au cours de l'année dernière, j'ai utilisé le thème des personnes voyant un type d'attente particulier, puis réagissant de manière « instinctive » à l'attente. En règle générale, cela signifie suivre de mauvais conseils sur Internet et prendre des mesures drastiques et inappropriées ou sauter à une conclusion sur la cause première du problème, puis perdre du temps et des efforts dans une chasse à l'oie sauvage.
L'un des types d'attente où les réactions instinctives sont les plus fortes et où certains des conseils les plus médiocres existent est l'attente CXPACKET. C'est aussi le type d'attente qui est le plus souvent le plus souvent attendu sur les serveurs des utilisateurs (selon mes deux grandes enquêtes sur les types d'attente de 2010 et 2014 - voir ici pour plus de détails), donc je vais en parler dans cet article.
Que signifie le type d'attente CXPACKET ?
L'explication la plus simple est que CXPACKET signifie que vous avez des requêtes en cours d'exécution en parallèle et que vous verrez * toujours * que CXPACKET attend une requête parallèle. Les attentes CXPACKET ne signifient PAS que vous avez un parallélisme problématique - vous devez creuser plus profondément pour le déterminer.
Comme exemple d'opérateur parallèle, considérez l'opérateur Repartition Streams, qui a l'icône suivante dans les plans de requête graphiques :

Et voici une image qui montre ce qui se passe en termes de threads parallèles pour cet opérateur, avec un degré de parallélisme (DOP) égal à 4 :
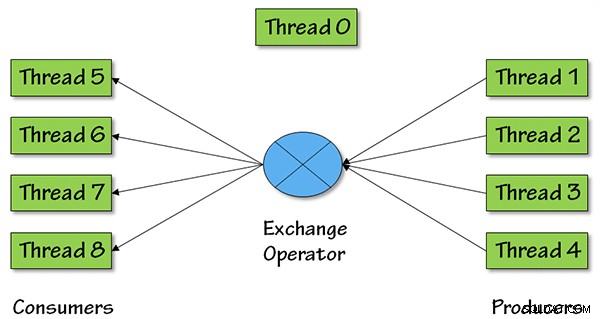
Pour DOP =4, il y aura quatre threads producteurs, extrayant des données plus tôt dans le plan de requête, les données sont ensuite renvoyées vers le reste du plan de requête via quatre threads consommateurs.
Vous pouvez voir les différents threads d'un opérateur parallèle qui attendent une ressource à l'aide de sys.dm_os_waiting_tasks DMV, dans le exec_context_id colonne (ce post a mon script pour faire cela).
Il y a toujours un thread de « contrôle » pour tout plan parallèle, qui, par accident historique, est toujours l'ID de thread 0. Le thread de contrôle enregistre toujours une attente CXPACKET, avec une durée égale à la durée d'exécution du plan. Paul White a une excellente explication des threads dans les plans parallèles ici.
La seule fois où les threads non contrôlés enregistreront les attentes CXPACKET, c'est s'ils se terminent avant les autres threads de l'opérateur. Cela peut se produire si l'un des threads reste bloqué en attendant une ressource pendant une longue période, alors regardez quel est le type d'attente du thread qui n'affiche pas CXPACKET (en utilisant mon script ci-dessus) et dépannez de manière appropriée. Cela peut également se produire en raison d'une répartition asymétrique du travail entre les threads, et j'approfondirai ce cas dans mon prochain article ici (cela est causé par des statistiques obsolètes et d'autres problèmes d'estimation de cardinalité).
Notez que dans SQL Server 2016 SP2 et SQL Server 2017 RTM CU3, les threads consommateurs n'enregistrent plus les attentes CXPACKET. Ils enregistrent les attentes CXCONSUMER, qui sont bénignes et peuvent être ignorées. Cela permet de réduire le nombre d'attentes CXPACKET générées, et les autres sont plus susceptibles d'être exploitables.
Parallélisme inattendu ?
Étant donné que CXPACKET signifie simplement que vous avez un parallélisme, la première chose à regarder est de savoir si vous vous attendez à un parallélisme pour la requête qui l'utilise. Ma requête vous donnera l'ID de nœud du plan de requête où le parallélisme se produit (il extrait l'ID de nœud du plan de requête XML si le type d'attente du thread est CXPACKET), alors recherchez cet ID de nœud et déterminez si le parallélisme a un sens .
L'un des cas courants de parallélisme inattendu est lorsqu'une analyse de table se produit lorsque vous attendez une recherche ou une analyse d'index plus petite. Vous le verrez soit dans le plan de requête, soit vous verrez de nombreuses attentes PAGEIOLATCH_SH (discutées en détail ici) ainsi que les attentes CXPACKET (un modèle classique de statistiques d'attente à surveiller). Il existe diverses causes d'analyses de table inattendues, notamment :
- Manque d'index non-cluster donc une analyse de table est la seule alternative
- Statistiques obsolètes, de sorte que l'optimiseur de requêtes pense qu'une analyse de table est la meilleure méthode d'accès aux données à utiliser
- Une conversion implicite, en raison d'une incompatibilité de type de données entre une colonne de table et une variable ou un paramètre, ce qui signifie qu'un index non clusterisé ne peut pas être utilisé
- L'arithmétique est effectuée sur une colonne de table au lieu d'une variable ou d'un paramètre, ce qui signifie qu'un index non clusterisé ne peut pas être utilisé
Dans tous ces cas, la solution est dictée par ce que vous trouvez être la cause première.
Mais que se passe-t-il s'il n'y a pas de cas racine évident et que la requête est juste jugée suffisamment coûteuse pour justifier un plan parallèle ?
Éviter le parallélisme
Entre autres choses, l'optimiseur de requête décide de produire un plan de requête parallèle si le plan en série a un coût supérieur au cost threshold for parallelism , un paramètre sp_configure pour l'instance. Le seuil de coût pour le parallélisme (ou CTFP) est fixé à cinq par défaut, ce qui signifie qu'un plan n'a pas besoin d'être très coûteux pour déclencher la création d'un plan parallèle.
L'un des moyens les plus simples d'empêcher le parallélisme indésirable consiste à augmenter le CTFP à un nombre beaucoup plus élevé. Plus vous le définissez, moins il est probable que des plans parallèles soient créés. Certaines personnes préconisent de régler le CTFP entre 25 et 50, mais comme pour tous les paramètres modifiables, il est préférable de tester différentes valeurs et de voir ce qui fonctionne le mieux pour votre environnement. Si vous souhaitez un peu plus d'une méthode programmatique pour vous aider à choisir une bonne valeur CTFP, Jonathan a écrit un article de blog montrant une requête pour analyser le cache du plan et produire une valeur suggérée pour CTFP. À titre d'exemple, nous avons un client avec CTFP défini sur 200, et un autre défini sur le maximum - 32767 - comme moyen d'empêcher de force tout parallélisme.
Vous vous demandez peut-être pourquoi le deuxième client a dû utiliser CTFP comme méthode de marteau pour empêcher le parallélisme alors que vous penseriez qu'il pourrait simplement définir le "degré maximum de parallélisme" (ou MAXDOP) du serveur sur 1. Eh bien, n'importe qui avec n'importe quel niveau d'autorisation peut spécifiez un indicateur MAXDOP de requête et remplacez le paramètre MAXDOP du serveur, mais CTFP ne peut pas être remplacé.
Et c'est une autre méthode pour limiter le parallélisme - définir un indice MAXDOP sur la requête que vous ne voulez pas mettre en parallèle.
Vous pouvez également réduire le paramètre MAXDOP du serveur, mais c'est une solution drastique car cela peut empêcher tout d'utiliser le parallélisme. De nos jours, il est courant que les serveurs aient des charges de travail mixtes, par exemple avec certaines requêtes OLTP et certaines requêtes de création de rapports. Si vous réduisez le MAXDOP du serveur, vous allez entraver les performances des requêtes de création de rapports.
Une meilleure solution lorsqu'il y a une charge de travail mixte serait d'utiliser CTFP comme je l'ai décrit ci-dessus ou d'utiliser Resource Governor (qui est réservé aux entreprises, j'en ai peur). Vous pouvez utiliser le gouverneur de ressources pour séparer les charges de travail en groupes de charge de travail, puis définir un MAX_DOP (le trait de soulignement n'est pas une faute de frappe) pour chaque groupe de charge de travail. Et la bonne chose à propos de l'utilisation du gouverneur de ressources est que le MAX_DOP ne peut pas être remplacé par un indicateur de requête MAXDOP.
Résumé
Ne tombez pas dans le piège de penser que CXPACKET attend automatiquement signifie que vous avez un mauvais parallélisme, et ne suivez certainement pas certains des conseils Internet que j'ai vus de claquer le serveur en réglant MAXDOP sur 1. Prenez le temps pour déterminer pourquoi vous voyez des attentes CXPACKET et s'il s'agit d'un problème à résoudre ou simplement d'un artefact d'une charge de travail qui s'exécute correctement.
En ce qui concerne les statistiques d'attente générales, vous pouvez trouver plus d'informations sur leur utilisation pour le dépannage des performances dans :
- Ma série d'articles de blog SQLskills, en commençant par les statistiques d'attente, ou dites-moi où ça fait mal ;
- Bibliothèque de mes types d'attente et de mes classes de verrouillage ici
- Ma formation en ligne Pluralsight SQL Server :Dépannage des performances à l'aide des statistiques d'attente
- Conseiller de performances SQL Sentry
Dans le prochain article de la série, je discuterai du parallélisme asymétrique et vous donnerai un moyen simple de le voir se produire. En attendant, bon dépannage !