Les bases de données sont conçues de différentes manières. La plupart du temps, nous pouvons utiliser des "exemples d'école":normalisez la base de données et tout fonctionnera très bien. Mais il y a des situations qui nécessiteront une autre approche. Nous pouvons supprimer les références pour gagner en flexibilité. Mais que se passe-t-il si nous devons améliorer les performances alors que tout a été fait dans les règles de l'art ? Dans ce cas, la dénormalisation est une technique à considérer. Dans cet article, nous discuterons des avantages et des inconvénients de la dénormalisation et des situations qui peuvent la justifier.
Qu'est-ce que la dénormalisation ?
La dénormalisation est une stratégie utilisée sur une base de données précédemment normalisée pour augmenter les performances. L'idée derrière cela est d'ajouter des données redondantes là où nous pensons que cela nous aidera le plus. Nous pouvons utiliser des attributs supplémentaires dans une table existante, ajouter de nouvelles tables ou même créer des instances de tables existantes. L'objectif habituel est de réduire le temps d'exécution des requêtes de sélection en rendant les données plus accessibles aux requêtes ou en générant des rapports résumés dans des tables séparées. Ce processus peut apporter de nouveaux problèmes, et nous en discuterons plus tard.
Une base de données normalisée est le point de départ du processus de dénormalisation. Il est important de faire la différence entre la base de données qui n'a pas été normalisée et la base de données qui a été normalisée en premier, puis dénormalisée plus tard. Le deuxième est correct; le premier est souvent le résultat d'une mauvaise conception de la base de données ou d'un manque de connaissances.
Exemple :un modèle normalisé pour un CRM très simple
Le modèle ci-dessous nous servira d'exemple :
Jetons un coup d'œil aux tableaux :
- Le
user_accounttable stocke des données sur les utilisateurs qui se connectent à notre application (pour simplifier le modèle, les rôles et les droits des utilisateurs en sont exclus). - Le
clienttable contient des données de base sur nos clients. - Le
productle tableau répertorie les produits proposés à nos clients. - La
tasktable contient toutes les tâches que nous avons créées. Vous pouvez considérer chaque tâche comme un ensemble d'actions liées envers les clients. Chaque tâche est associée à des appels, des réunions et des listes de produits proposés et vendus. - L'
calletmeetingles tables stockent des données sur tous les appels et réunions et les relient aux tâches et aux utilisateurs. - Les dictionnaires
task_outcome,meeting_outcomeetcall_outcomecontiennent toutes les options possibles pour l'état final d'une tâche, d'une réunion ou d'un appel. - Le
product_offeredstocke une liste de tous les produits qui ont été proposés aux clients sur certaines tâches tandis queproduct_soldcontient une liste de tous les produits que le client a effectivement achetés. - Le
supply_orderla table stocke des données sur toutes les commandes que nous avons passées et lesproducts_on_orderle tableau répertorie les produits et leur quantité pour des commandes spécifiques. - Le
writeoffle tableau est une liste de produits qui ont été radiés en raison d'accidents ou similaires (par exemple, des miroirs brisés).
La base de données est simplifiée mais elle est parfaitement normalisée. Vous ne trouverez aucune redondance et cela devrait faire l'affaire. Nous ne devrions en aucun cas rencontrer de problèmes de performances, tant que nous travaillons avec une quantité de données relativement faible.
Quand et pourquoi utiliser la dénormalisation
Comme pour presque tout, vous devez être sûr de la raison pour laquelle vous souhaitez appliquer la dénormalisation. Vous devez également vous assurer que le profit de son utilisation l'emporte sur tout préjudice. Il y a quelques situations où vous devriez absolument penser à la dénormalisation :
- Maintenir l'historique : Les données peuvent changer au fil du temps et nous devons stocker des valeurs qui étaient valides lors de la création d'un enregistrement. De quel genre de changements parlons-nous ? Eh bien, le prénom et le nom d'une personne peuvent changer; un client peut également modifier le nom de son entreprise ou toute autre donnée. Les détails de la tâche doivent contenir des valeurs qui étaient réelles au moment où une tâche a été générée. Nous ne serions pas en mesure de recréer correctement les données passées si cela ne se produisait pas. On pourrait résoudre ce problème en ajoutant un tableau contenant l'historique de ces changements. Dans ce cas, une requête de sélection renvoyant la tâche et un nom de client valide deviendrait plus compliquée. Une table supplémentaire n'est peut-être pas la meilleure solution.
- Amélioration des performances des requêtes : Certaines des requêtes peuvent utiliser plusieurs tables pour accéder aux données dont nous avons fréquemment besoin. Pensez à une situation où nous aurions besoin de joindre 10 tables pour renvoyer le nom du client et les produits qui lui ont été vendus. Certaines tables le long du chemin peuvent également contenir de grandes quantités de données. Dans ce cas, il serait peut-être judicieux d'ajouter un
client_idattribuer directement auproducts_soldtableau. - Accélération des rapports : Nous avons très fréquemment besoin de certaines statistiques. Leur création à partir de données en direct prend beaucoup de temps et peut affecter les performances globales du système. Disons que nous voulons suivre les ventes des clients au cours de certaines années pour certains ou tous les clients. La génération de tels rapports à partir de données en direct «creuserait» presque toute la base de données et la ralentirait beaucoup. Et que se passe-t-il si nous utilisons souvent cette statistique ?
- Calcul à l'avance des valeurs couramment nécessaires : Nous voulons que certaines valeurs soient déjà calculées afin de ne pas avoir à les générer en temps réel.
Il est important de souligner que vous n'avez pas besoin d'utiliser la dénormalisation s'il n'y a pas de problèmes de performances Dans l'application. Mais si vous remarquez que le système ralentit - ou si vous êtes conscient que cela pourrait arriver - alors vous devriez penser à appliquer cette technique. Avant d'y aller, cependant, considérez d'autres options, comme l'optimisation des requêtes et une indexation appropriée. Vous pouvez également utiliser la dénormalisation si vous êtes déjà en production, mais il est préférable de résoudre les problèmes lors de la phase de développement.
Quels sont les inconvénients de la dénormalisation ?
De toute évidence, le plus grand avantage du processus de dénormalisation est l'augmentation des performances. Mais nous devons en payer le prix, et ce prix peut consister en :
- Espace disque : C'est normal, car nous aurons des données en double.
- Anomalies de données : Nous devons être très conscients du fait que les données peuvent maintenant être modifiées à plus d'un endroit. Nous devons ajuster chaque élément de données en double en conséquence. Cela s'applique également aux valeurs calculées et aux rapports. Nous pouvons y parvenir en utilisant des déclencheurs, des transactions et/ou des procédures pour toutes les opérations qui doivent être effectuées ensemble.
- Documents : Nous devons documenter correctement chaque règle de dénormalisation que nous avons appliquée. Si nous modifions la conception de la base de données ultérieurement, nous devrons examiner toutes nos exceptions et les prendre en considération une fois de plus. Peut-être que nous n'en avons plus besoin parce que nous avons résolu le problème. Ou peut-être devons-nous ajouter des règles de dénormalisation existantes. (Par exemple :nous avons ajouté un nouvel attribut à la table client et nous voulons stocker sa valeur d'historique avec tout ce que nous stockons déjà. Nous devrons modifier les règles de dénormalisation existantes pour y parvenir).
- Ralentir d'autres opérations : Nous pouvons nous attendre à ralentir les opérations d'insertion, de modification et de suppression de données. Si ces opérations se produisent relativement rarement, cela pourrait être un avantage. Fondamentalement, nous diviserions une sélection lente en un plus grand nombre de requêtes d'insertion/mise à jour/suppression plus lentes. Bien qu'une requête de sélection très complexe puisse techniquement ralentir sensiblement l'ensemble du système, le ralentissement de plusieurs opérations "plus petites" ne devrait pas nuire à la convivialité de notre application.
- Plus de codage : Les règles 2 et 3 nécessiteront un codage supplémentaire, mais en même temps, elles simplifieront beaucoup certaines requêtes sélectionnées. Si nous dénormalisons une base de données existante, nous devrons modifier ces requêtes sélectionnées pour tirer parti de notre travail. Nous devrons également mettre à jour les valeurs des attributs nouvellement ajoutés pour les enregistrements existants. Cela aussi nécessitera un peu plus de codage.
Le modèle d'exemple, dénormalisé
Dans le modèle ci-dessous, j'ai appliqué certaines des règles de dénormalisation susmentionnées. Les tableaux roses ont été modifiés, tandis que le tableau bleu clair est complètement nouveau.
Quels changements sont appliqués et pourquoi ?

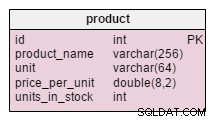
Le seul changement dans le product table est l'addition des units_in_stock attribut. Dans un modèle normalisé, nous pourrions calculer ces données comme unités commandées - unités vendues - (unités offertes) - unités radiées . Nous répéterions le calcul chaque fois qu'un client demanderait ce produit, ce qui prendrait énormément de temps. Au lieu de cela, nous calculerons la valeur à l'avance ; lorsqu'un client nous le demande, nous le préparons. Bien sûr, cela simplifie beaucoup la requête de sélection. En revanche, les units_in_stock l'attribut doit être ajusté après chaque insertion, mise à jour ou suppression dans le products_on_order , writeoff , product_offered et product_sold tableaux.
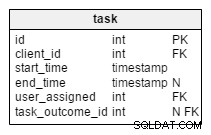
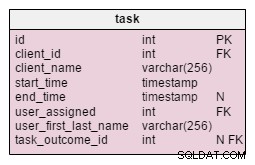
Dans la task table, nous trouvons deux nouveaux attributs :client_name et user_first_last_name . Les deux stockent des valeurs lors de la création de la tâche. La raison en est que ces deux valeurs peuvent changer au cours du temps. Nous conserverons également une clé étrangère qui les relie au client et à l'ID utilisateur d'origine. Il y a plus de valeurs que nous aimerions stocker, comme l'adresse du client, le numéro de TVA, etc.




Le product_offered la table a deux nouveaux attributs, price_per_unit et price . Le price_per_unit l'attribut est stocké car nous devons stocker le prix réel lorsque le produit a été proposé . Le modèle normalisé ne montrerait que son état actuel, donc lorsque le prix du produit changerait, nos prix « historiques » changeraient également. Notre changement ne se contente pas d'accélérer le fonctionnement de la base de données :il la rend également plus efficace. Le price l'attribut est la valeur calculée units_sold * price_per_unit . Je l'ai ajouté ici pour éviter de faire ce calcul à chaque fois que l'on veut jeter un œil à une liste de produits proposés. C'est un petit coût, mais cela améliore les performances.
Les modifications apportées sur le product_sold tableau sont très similaires. La structure de la table est la même, mais elle stocke une liste des articles vendus.
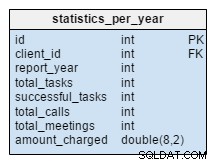
Les statistics_per_year La table est complètement nouvelle pour notre modèle. Nous devrions le considérer comme une table dénormalisée car toutes ses données peuvent être calculées à partir des autres tables. L'idée derrière ce tableau est de stocker le nombre de tâches, de tâches réussies, de réunions et d'appels liés à un client donné. Il gère également la somme totale facturée chaque année. Après avoir inséré, mis à jour ou supprimé quoi que ce soit dans la task , meeting , call et product_sold tables, nous devrions recalculer les données de cette table pour ce client et l'année correspondante. Nous pouvons nous attendre à ce que nous n'ayons principalement des changements que pour l'année en cours. Les rapports des années précédentes ne devraient pas avoir à changer.
Les valeurs de ce tableau sont calculées à l'avance, nous passerons donc moins de temps et de ressources au moment où nous aurons besoin du résultat du calcul. Pensez aux valeurs dont vous aurez souvent besoin. Peut-être que vous n'en aurez pas besoin régulièrement et que vous risquez d'en calculer certains en direct.
La dénormalisation est un concept très intéressant et puissant. Bien que ce ne soit pas la première chose que vous devriez avoir à l'esprit pour améliorer les performances, dans certaines situations, cela peut être la meilleure ou même la seule solution.
Avant de choisir d'utiliser la dénormalisation, assurez-vous que vous le souhaitez. Effectuez une analyse et suivez les performances. Vous déciderez probablement d'opter pour la dénormalisation une fois que vous serez déjà en ligne. N'ayez pas peur de l'utiliser, mais suivez les modifications et vous ne devriez rencontrer aucun problème (c'est-à-dire les redoutables anomalies de données).



