La gestion NULL est l'un des aspects les plus délicats de la modélisation et de la manipulation des données avec SQL. Commençons par le fait qu'une tentative d'expliquer exactement ce qu'est un NULL n'est pas négligeable en soi. Même parmi les personnes qui ont une bonne compréhension de la théorie relationnelle et de SQL, vous entendrez des opinions très fortes à la fois en faveur et contre l'utilisation de NULL dans votre base de données. Que vous les aimiez ou non, en tant que spécialiste des bases de données, vous devez souvent les gérer, et étant donné que les valeurs NULL ajoutent de la complexité à votre écriture de code SQL, c'est une bonne idée de faire de leur bonne compréhension une priorité. De cette façon, vous pouvez éviter les bogues et les pièges inutiles.
Cet article est le premier d'une série sur les complexités NULL. Je commence par couvrir ce que sont les NULL et comment ils se comportent dans les comparaisons. Je couvre ensuite les incohérences de traitement NULL dans différents éléments de langage. Enfin, je couvre les fonctionnalités standard manquantes liées à la gestion de NULL dans T-SQL et suggère des alternatives disponibles dans T-SQL.
La plupart de la couverture est pertinente pour toute plate-forme qui implémente un dialecte SQL, mais dans certains cas, je mentionne des aspects spécifiques à T-SQL.
Dans mes exemples, j'utiliserai un exemple de base de données appelé TSQLV5. Vous pouvez trouver le script qui crée et remplit cette base de données ici, et son diagramme ER ici.
NULL comme marqueur d'une valeur manquante
Commençons par comprendre ce que sont les NULL. En SQL, un NULL est un marqueur, ou un espace réservé, pour une valeur manquante. C'est la tentative de SQL de représenter dans votre base de données une réalité où une certaine valeur d'attribut est parfois présente et parfois manquante. Par exemple, supposons que vous ayez besoin de stocker des données sur les employés dans une table Employés. Vous avez des attributs pour le prénom, le deuxième prénom et le nom de famille. Les attributs firstname et lastname sont obligatoires, et donc vous les définissez comme n'autorisant pas les NULL. L'attribut middlename est facultatif, et donc vous le définissez comme autorisant les valeurs NULL.
Si vous vous demandez ce que le modèle relationnel a à dire sur les valeurs manquantes, le créateur du modèle, Edgar F. Codd, y croyait. En fait, il a même fait une distinction entre deux types de valeurs manquantes :Missing But Applicable (marqueur A-Values) et Missing But Inapplicable (marqueur I-Values). Si nous prenons l'attribut middlename comme exemple, dans le cas où un employé a un deuxième prénom, mais choisit de ne pas partager les informations pour des raisons de confidentialité, vous utiliserez le marqueur A-Values. Dans le cas où un employé n'a pas du tout de deuxième prénom, vous utiliseriez le marqueur I-Values. Ici, le même attribut peut parfois être pertinent et présent, parfois manquant mais applicable et parfois manquant mais inapplicable. D'autres cas pourraient être plus clairs, ne prenant en charge qu'un seul type de valeurs manquantes. Par exemple, supposons que vous ayez une table Orders avec un attribut appelé shipdate contenant la date d'expédition de la commande. Une commande qui a été expédiée aura toujours une date d'expédition actuelle et pertinente. Le seul cas pour ne pas avoir de date d'expédition connue serait pour les commandes qui n'ont pas encore été expédiées. Donc ici, soit une valeur de date d'expédition pertinente doit être présente, soit le marqueur I-Values doit être utilisé.
Les concepteurs de SQL ont choisi de ne pas entrer dans la distinction entre les valeurs manquantes applicables et inapplicables, et nous ont fourni le NULL comme marqueur pour tout type de valeur manquante. Pour l'essentiel, SQL a été conçu pour supposer que les valeurs NULL représentent le type de valeur manquante manquant mais applicable. Par conséquent, en particulier lorsque vous utilisez NULL comme espace réservé pour une valeur inapplicable, la gestion SQL NULL par défaut peut ne pas être celle que vous percevez comme correcte. Parfois, vous devrez ajouter une logique de gestion NULL explicite pour obtenir le traitement que vous considérez comme le bon pour vous.
Comme meilleure pratique, si vous savez qu'un attribut n'est pas censé autoriser les valeurs NULL, assurez-vous de l'appliquer avec une contrainte NOT NULL dans le cadre de la définition de la colonne. Il y a quelques raisons importantes à cela. Une des raisons est que si vous ne l'appliquez pas, à un moment ou à un autre, les NULL y arriveront. Cela peut être le résultat d'un bogue dans l'application ou de l'importation de mauvaises données. En utilisant une contrainte, vous savez que les valeurs NULL n'atteindront jamais la table. Une autre raison est que l'optimiseur évalue les contraintes telles que NOT NULL pour une meilleure optimisation, en évitant un travail inutile de recherche de NULL et en activant certaines règles de transformation.
Comparaisons impliquant des valeurs NULL
Il y a une certaine difficulté dans l'évaluation des prédicats par SQL lorsque des valeurs NULL sont impliquées. Je couvrirai d'abord les comparaisons impliquant des constantes. Plus tard, je couvrirai les comparaisons impliquant des variables, des paramètres et des colonnes.
Lorsque vous utilisez des prédicats qui comparent des opérandes dans des éléments de requête tels que WHERE, ON et HAVING, les résultats possibles de la comparaison dépendent du fait que l'un des opérandes peut être NULL. Si vous savez avec certitude qu'aucun des opérandes ne peut être NULL, le résultat du prédicat sera toujours TRUE ou FALSE. C'est ce qu'on appelle la logique des prédicats à deux valeurs, ou en bref, simplement la logique à deux valeurs. C'est le cas, par exemple, lorsque vous comparez une colonne définie comme n'autorisant pas les valeurs NULL avec un autre opérande non NULL.
Si l'un des opérandes de la comparaison peut être un NULL, par exemple une colonne qui autorise les NULL, en utilisant à la fois les opérateurs d'égalité (=) et d'inégalité (<>,>, <,>=, <=, etc.), vous êtes maintenant à la merci de la logique des prédicats à trois valeurs. Si, dans une comparaison donnée, les deux opérandes se trouvent être des valeurs non NULL, vous obtenez toujours TRUE ou FALSE comme résultat. Cependant, si l'un des opérandes est NULL, vous obtenez une troisième valeur logique appelée UNKNOWN. Notez que c'est le cas même lors de la comparaison de deux valeurs NULL. Le traitement de TRUE et FALSE par la plupart des éléments de SQL est assez intuitif. Le traitement de UNKNOWN n'est pas toujours aussi intuitif. De plus, différents éléments de SQL gèrent différemment le cas UNKNOWN, comme je l'expliquerai en détail plus loin dans l'article sous "Incohérences de traitement NULL".
Par exemple, supposons que vous deviez interroger la table Sales.Orders dans l'exemple de base de données TSQLV5 et renvoyer les commandes expédiées le 2 janvier 2019. Vous utilisez la requête suivante :
USE TSQLV5; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = '20190102';
Il est clair que le prédicat de filtre prend la valeur TRUE pour les lignes dont la date d'expédition est le 2 janvier 2019 et que ces lignes doivent être renvoyées. Il est également clair que le prédicat est évalué à FALSE pour les lignes où la date d'expédition est présente, mais n'est pas le 2 janvier 2019, et que ces lignes doivent être supprimées. Mais qu'en est-il des lignes avec une date d'expédition NULL ? N'oubliez pas que les prédicats basés sur l'égalité et les prédicats basés sur l'inégalité renvoient UNKNOWN si l'un des opérandes est NULL. Le filtre WHERE est conçu pour supprimer ces lignes. Vous devez vous rappeler que le filtre WHERE renvoie les lignes pour lesquelles le prédicat de filtre est évalué à TRUE et ignore les lignes pour lesquelles le prédicat est évalué à FALSE ou UNKNOWN.
Cette requête génère la sortie suivante :
orderid shippeddate ----------- ----------- 10771 2019-01-02 10794 2019-01-02 10802 2019-01-02
Supposons que vous deviez retourner des commandes qui n'ont pas été expédiées le 2 janvier 2019. En ce qui vous concerne, les commandes qui n'ont pas encore été expédiées sont censées être incluses dans la sortie. Vous utilisez une requête similaire à la précédente, en annulant uniquement le prédicat, comme ceci :
SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate = '20190102');
Cette requête renvoie le résultat suivant :
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
La sortie exclut naturellement les lignes avec la date d'expédition du 2 janvier 2019, mais exclut également les lignes avec une date d'expédition NULL. Ce qui pourrait être contre-intuitif ici, c'est ce qui se passe lorsque vous utilisez l'opérateur NOT pour nier un prédicat qui prend la valeur UNKNOWN. Évidemment, PAS VRAI est FAUX et PAS FAUX est VRAI. Cependant, NOT INKNOWN reste INCONNU. La logique de SQL derrière cette conception est que si vous ne savez pas si une proposition est vraie, vous ne savez pas non plus si la proposition n'est pas vraie. Cela signifie que lors de l'utilisation d'opérateurs d'égalité et d'inégalité dans le prédicat de filtre, ni les formes positives ni négatives du prédicat ne renvoient les lignes avec les valeurs NULL.
Cet exemple est assez simple. Il existe des cas plus délicats impliquant des sous-requêtes. Il existe un bogue courant lorsque vous utilisez le prédicat NOT IN avec une sous-requête, lorsque la sous-requête renvoie un NULL parmi les valeurs renvoyées. La requête renvoie toujours un résultat vide. La raison en est que la forme positive du prédicat (la partie IN) renvoie un TRUE lorsque la valeur externe est trouvée, et UNKNOWN lorsqu'elle n'est pas trouvée en raison de la comparaison avec le NULL. Ensuite, la négation du prédicat avec l'opérateur NOT renvoie toujours FALSE ou UNKNOWN, respectivement, jamais un TRUE. Je couvre ce bogue en détail dans les bogues T-SQL, les pièges et les meilleures pratiques - sous-requêtes, y compris les solutions suggérées, les considérations d'optimisation et les meilleures pratiques. Si vous n'êtes pas déjà familier avec ce bogue classique, assurez-vous de consulter cet article car le bogue est assez courant et il existe des mesures simples que vous pouvez prendre pour l'éviter.
Pour en revenir à notre besoin, que diriez-vous d'essayer de retourner des commandes avec une date d'expédition différente du 2 janvier 2019, en utilisant l'opérateur différent de (<>) :
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> '20190102';
Malheureusement, les opérateurs d'égalité et d'inégalité renvoient UNKNOWN lorsque l'un des opérandes est NULL, donc cette requête génère la sortie suivante comme la requête précédente, à l'exclusion des NULL :
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
Pour isoler le problème des comparaisons avec des valeurs NULL produisant UNKNOWN en utilisant l'égalité, l'inégalité et la négation des deux types d'opérateurs, toutes les requêtes suivantes renvoient un jeu de résultats vide :
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate = NULL); SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate <> NULL);
Selon SQL, vous n'êtes pas censé vérifier si quelque chose est égal à NULL ou différent de NULL, mais plutôt si quelque chose est NULL ou n'est pas NULL, en utilisant respectivement les opérateurs spéciaux IS NULL et IS NOT NULL. Ces opérateurs utilisent une logique à deux valeurs, renvoyant toujours TRUE ou FALSE. Par exemple, utilisez l'opérateur IS NULL pour renvoyer les commandes non expédiées, comme ceci :
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NULL;
Cette requête génère la sortie suivante :
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... (21 rows affected)
Utilisez l'opérateur IS NOT NULL pour renvoyer les commandes expédiées, comme ceci :
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT NULL;
Cette requête génère la sortie suivante :
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (809 rows affected)
Utilisez le code suivant pour renvoyer les commandes qui ont été expédiées à une date différente du 2 janvier 2019, ainsi que les commandes non expédiées :
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> '20190102' OR shippeddate IS NULL;
Cette requête génère la sortie suivante :
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (827 rows affected)
Dans une partie ultérieure de la série, je couvre les fonctionnalités standard pour le traitement NULL qui manquent actuellement dans T-SQL, y compris le prédicat DISTINCT , qui ont le potentiel de simplifier considérablement la gestion de NULL.
Comparaisons avec des variables, des paramètres et des colonnes
La section précédente s'est concentrée sur les prédicats qui comparent une colonne à une constante. En réalité, cependant, vous comparerez principalement une colonne avec des variables/paramètres ou avec d'autres colonnes. De telles comparaisons impliquent d'autres complexités.
Du point de vue de la gestion de NULL, les variables et les paramètres sont traités de la même manière. J'utiliserai des variables dans mes exemples, mais les remarques que je fais sur leur gestion sont tout aussi pertinentes pour les paramètres.
Considérez la requête de base suivante (je l'appellerai Requête 1), qui filtre les commandes expédiées à une date donnée :
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
J'utilise une variable dans cet exemple et je l'initialise avec un exemple de date, mais cela aurait tout aussi bien pu être une requête paramétrée dans une procédure stockée ou une fonction définie par l'utilisateur.
Cette exécution de requête génère la sortie suivante :
orderid shippeddate ----------- ----------- 10865 2019-02-12 10866 2019-02-12 10876 2019-02-12 10878 2019-02-12 10879 2019-02-12
Le plan pour la requête 1 est illustré à la figure 1.
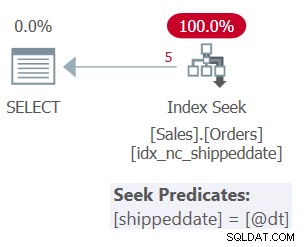 Figure 1 :Plan pour la requête 1
Figure 1 :Plan pour la requête 1
La table a un index couvrant pour prendre en charge cette requête. L'index est appelé idx_nc_shippeddate, et il est défini avec la liste de clés (shippeddate, orderid). Le prédicat de filtre de la requête est exprimé sous la forme d'un argument de recherche (SARG) , ce qui signifie qu'il permet à l'optimiseur d'envisager d'appliquer une opération de recherche dans l'index de prise en charge, en allant directement à la plage de lignes qualifiantes. Ce qui rend le prédicat de filtre SARGable, c'est qu'il utilise un opérateur qui représente une plage consécutive de lignes qualifiantes dans l'index, et qu'il n'applique pas de manipulation à la colonne filtrée. Le plan que vous obtenez est le plan optimal pour cette requête.
Mais que se passe-t-il si vous souhaitez autoriser les utilisateurs à demander des commandes non expédiées ? Ces commandes ont une date d'expédition NULL. Voici une tentative de passer un NULL comme date d'entrée :
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Comme vous le savez déjà, un prédicat utilisant un opérateur d'égalité produit UNKNOWN lorsque l'un des opérandes est un NULL. Par conséquent, cette requête renvoie un résultat vide :
orderid shippeddate ----------- ----------- (0 rows affected)
Même si T-SQL prend en charge un opérateur IS NULL, il ne prend pas en charge un opérateur IS
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE ISNULL(shippeddate, '99991231') = ISNULL(@dt, '99991231');
Cette requête génère la sortie correcte :
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 11075 NULL 11076 NULL 11077 NULL (21 rows affected)
Mais le plan pour cette requête, comme le montre la figure 2, n'est pas optimal.
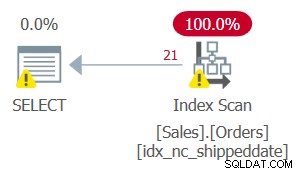 Figure 2 :Plan pour la requête 2
Figure 2 :Plan pour la requête 2
Depuis que vous avez appliqué la manipulation à la colonne filtrée, le prédicat de filtre n'est plus considéré comme un SARG. L'index est toujours couvrant, il peut donc être utilisé; mais au lieu d'appliquer une recherche dans l'index allant directement à la plage de lignes de qualification, la feuille d'index entière est scannée. Supposons que la table contienne 50 000 000 de commandes, dont seulement 1 000 étant des commandes non expédiées. Ce plan analyserait les 50 000 000 lignes au lieu d'effectuer une recherche qui va directement aux 1 000 lignes éligibles.
Une forme de prédicat de filtre qui a la signification correcte que nous recherchons et qui est considérée comme un argument de recherche est (shippeddate =@dt OR (shippeddate IS NULL AND @dt IS NULL)). Voici une requête utilisant ce prédicat SARGable (nous l'appellerons Requête 3) :
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE (shippeddate = @dt OR (shippeddate IS NULL AND @dt IS NULL));
Le plan de cette requête est illustré à la figure 3.
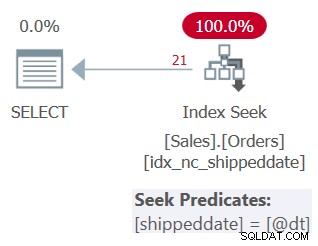 Figure 3 :Plan pour la requête 3
Figure 3 :Plan pour la requête 3
Comme vous pouvez le voir, le plan applique une recherche dans l'index de support. Le prédicat de recherche indique shipdate =@dt, mais il est conçu en interne pour gérer les valeurs NULL comme des valeurs non NULL à des fins de comparaison.
Cette solution est généralement considérée comme raisonnable. C'est standard, optimal et correct. Son principal inconvénient est qu'il est verbeux. Et si vous aviez plusieurs prédicats de filtre basés sur des colonnes NULLable ? Vous vous retrouveriez rapidement avec une clause WHERE longue et encombrante. Et cela devient bien pire lorsque vous devez écrire un prédicat de filtre impliquant une colonne NULLable à la recherche de lignes où la colonne est différente du paramètre d'entrée. Le prédicat devient alors :(shippeddate <> @dt AND ((shippeddate IS NULL AND @dt IS NOT NULL) OR (shippeddate IS NOT NULL and @dt IS NULL))).
Vous voyez clairement le besoin d'une solution plus élégante, à la fois concise et optimale. Malheureusement, certains ont recours à une solution non standard où vous désactivez l'option de session ANSI_NULLS. Cette option oblige SQL Server à utiliser une gestion non standard des opérateurs d'égalité (=) et différent de (<>) avec une logique à deux valeurs au lieu d'une logique à trois valeurs, traitant les valeurs NULL comme des valeurs non NULL à des fins de comparaison. C'est au moins le cas tant que l'un des opérandes est un paramètre/variable ou un littéral.
Exécutez le code suivant pour désactiver l'option ANSI_NULLS dans la session :
SET ANSI_NULLS OFF;
Exécutez la requête suivante à l'aide d'un simple prédicat basé sur l'égalité :
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Cette requête renvoie les 21 commandes non expédiées. Vous obtenez le même plan illustré plus tôt dans la figure 3, montrant une recherche dans l'index.
Exécutez le code suivant pour revenir au comportement standard où ANSI_NULLS est activé :
SET ANSI_NULLS ON;
S'appuyer sur un tel comportement non standard est fortement déconseillé. La documentation indique également que la prise en charge de cette option sera supprimée dans certaines futures versions de SQL Server. De plus, beaucoup ne réalisent pas que cette option n'est applicable que lorsqu'au moins un des opérandes est un paramètre/variable ou une constante, même si la documentation est assez claire à ce sujet. Cela ne s'applique pas lors de la comparaison de deux colonnes, comme dans une jointure.
Alors, comment gérez-vous les jointures impliquant des colonnes de jointure NULLable si vous voulez obtenir une correspondance lorsque les deux côtés sont NULL ? Par exemple, utilisez le code suivant pour créer et remplir les tables T1 et T2 :
DROP TABLE IF EXISTS dbo.T1, dbo.T2; GO CREATE TABLE dbo.T1(k1 INT NULL, k2 INT NULL, k3 INT NULL, val1 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T1 UNIQUE CLUSTERED(k1, k2, k3)); CREATE TABLE dbo.T2(k1 INT NULL, k2 INT NULL, k3 INT NULL, val2 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T2 UNIQUE CLUSTERED(k1, k2, k3)); INSERT INTO dbo.T1(k1, k2, k3, val1) VALUES (1, NULL, 0, 'A'),(NULL, NULL, 1, 'B'),(0, NULL, NULL, 'C'),(1, 1, 0, 'D'),(0, NULL, 1, 'F'); INSERT INTO dbo.T2(k1, k2, k3, val2) VALUES (0, 0, 0, 'G'),(1, 1, 1, 'H'),(0, NULL, NULL, 'I'),(NULL, NULL, NULL, 'J'),(0, NULL, 1, 'K');
Le code crée des index de couverture sur les deux tables pour prendre en charge une jointure basée sur les clés de jointure (k1, k2, k3) des deux côtés.
Utilisez le code suivant pour mettre à jour les statistiques de cardinalité, en gonflant les chiffres afin que l'optimiseur pense que vous avez affaire à des tables plus grandes :
UPDATE STATISTICS dbo.T1(UNQ_T1) WITH ROWCOUNT = 1000000; UPDATE STATISTICS dbo.T2(UNQ_T2) WITH ROWCOUNT = 1000000;
Utilisez le code suivant pour tenter de joindre les deux tables à l'aide de simples prédicats basés sur l'égalité :
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON T1.k1 = T2.k1
AND T1.k2 = T2.k2
AND T1.k3 = T2.k3; Tout comme avec les exemples de filtrage précédents, ici aussi, les comparaisons entre NULL utilisant un opérateur d'égalité donnent UNKNOWN, ce qui entraîne des non-correspondances. Cette requête génère une sortie vide :
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- (0 rows affected)
L'utilisation de ISNULL ou COALESCE comme dans un exemple de filtrage précédent, le remplacement d'un NULL par une valeur qui ne peut normalement pas apparaître dans les données des deux côtés, aboutit à une requête correcte (je ferai référence à cette requête comme requête 4):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON ISNULL(T1.k1, -2147483648) = ISNULL(T2.k1, -2147483648)
AND ISNULL(T1.k2, -2147483648) = ISNULL(T2.k2, -2147483648)
AND ISNULL(T1.k3, -2147483648) = ISNULL(T2.k3, -2147483648); Cette requête génère la sortie suivante :
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
Cependant, tout comme la manipulation d'une colonne filtrée rompt la SARGabilité du prédicat de filtre, la manipulation d'une colonne de jointure empêche la possibilité de s'appuyer sur l'ordre de l'index. Cela peut être vu dans le plan de cette requête, comme illustré à la figure 4.
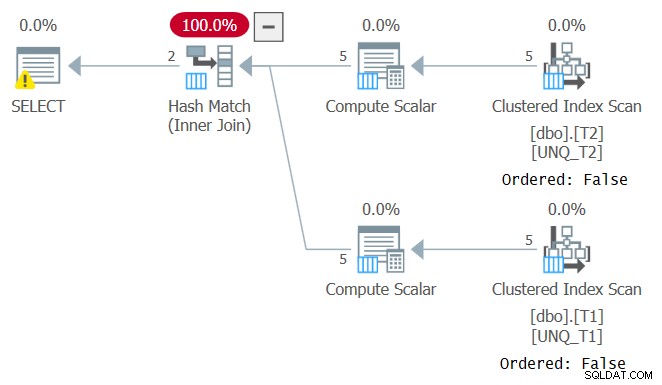 Figure 4 :Planifier la requête 4
Figure 4 :Planifier la requête 4
Un plan optimal pour cette requête est celui qui applique des balayages ordonnés des deux index de couverture suivis d'un algorithme Merge Join, sans tri explicite. L'optimiseur a choisi un plan différent car il ne pouvait pas s'appuyer sur l'ordre des index. Si vous tentez de forcer un algorithme Merge Join à l'aide de INNER MERGE JOIN, le plan s'appuiera toujours sur des analyses non ordonnées des index, suivies d'un tri explicite. Essayez !
Bien sûr, vous pouvez utiliser les longs prédicats similaires aux prédicats SARGable présentés précédemment pour les tâches de filtrage :
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON (T1.k1 = T2.k1 OR (T1.k1 IS NULL AND T2.K1 IS NULL))
AND (T1.k2 = T2.k2 OR (T1.k2 IS NULL AND T2.K2 IS NULL))
AND (T1.k3 = T2.k3 OR (T1.k3 IS NULL AND T2.K3 IS NULL)); Cette requête produit le résultat souhaité et permet à l'optimiseur de s'appuyer sur l'ordre de l'index. Cependant, notre espoir est de trouver une solution à la fois optimale et concise.
Il existe une technique élégante et concise peu connue que vous pouvez utiliser à la fois dans les jointures et les filtres, à la fois pour identifier les correspondances et pour identifier les non-correspondances. Cette technique a été découverte et documentée il y a déjà des années, comme dans l'excellent article de Paul White sur les plans de requête non documentés :comparaisons d'égalité de 2011. Mais pour une raison quelconque, il semble que beaucoup de gens l'ignorent encore et finissent malheureusement par utiliser solutions non standard. Il mérite certainement plus d'exposition et d'amour.
La technique repose sur le fait que les opérateurs d'ensemble tels que INTERSECT et EXCEPT utilisent une approche de comparaison basée sur la distinction lors de la comparaison de valeurs, et non une approche de comparaison basée sur l'égalité ou l'inégalité.
Considérez notre tâche de jointure comme exemple. Si nous n'avions pas eu besoin de retourner des colonnes autres que les clés de jointure, nous aurions utilisé une requête simple (je l'appellerai Requête 5) avec un opérateur INTERSECT, comme ceci :
SELECT k1, k2, k3 FROM dbo.T1 INTERSECT SELECT k1, k2, k3 FROM dbo.T2;
Cette requête génère la sortie suivante :
k1 k2 k3 ----------- ----------- ----------- 0 NULL NULL 0 NULL 1
Le plan de cette requête est illustré à la figure 5, confirmant que l'optimiseur a pu s'appuyer sur l'ordre de l'index et utiliser un algorithme Merge Join.
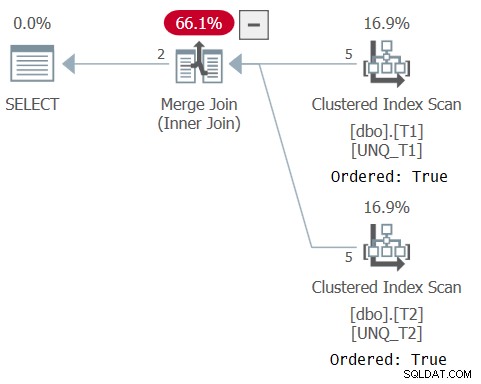 Figure 5 :Plan pour la requête 5
Figure 5 :Plan pour la requête 5
Comme le note Paul dans son article, le plan XML pour l'opérateur d'ensemble utilise un opérateur de comparaison IS implicite (CompareOp="IS" ) par opposition à l'opérateur de comparaison EQ utilisé dans une jointure normale (CompareOp="EQ" ). Le problème avec une solution qui repose uniquement sur un opérateur d'ensemble est qu'elle vous limite à renvoyer uniquement les colonnes que vous comparez. Ce dont nous avons vraiment besoin est une sorte d'hybride entre une jointure et un opérateur d'ensemble, vous permettant de comparer un sous-ensemble d'éléments tout en renvoyant des éléments supplémentaires comme le fait une jointure, et en utilisant une comparaison basée sur la distinction (IS) comme le fait un opérateur d'ensemble. Ceci est réalisable en utilisant une jointure comme construction externe et un prédicat EXISTS dans la clause ON de la jointure basée sur une requête avec un opérateur INTERSECT comparant les clés de jointure des deux côtés, comme ceci (je ferai référence à cette solution comme Query 6):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
L'opérateur INTERSECT opère sur deux requêtes, chacune formant un ensemble d'une ligne basée sur les clés de jointure de chaque côté. Lorsque les deux lignes sont identiques, la requête INTERSECT renvoie une ligne; le prédicat EXISTS renvoie TRUE, ce qui donne une correspondance. Lorsque les deux lignes ne sont pas identiques, la requête INTERSECT renvoie un ensemble vide; le prédicat EXISTS renvoie FALSE, ce qui entraîne une non-correspondance.
Cette solution génère la sortie souhaitée :
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
Le plan de cette requête est illustré à la figure 6, confirmant que l'optimiseur a pu s'appuyer sur l'ordre de l'index.
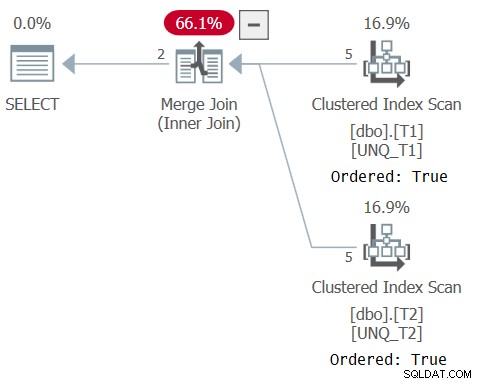 Figure 6 :Plan pour la requête 6
Figure 6 :Plan pour la requête 6
Vous pouvez utiliser une construction similaire en tant que prédicat de filtre impliquant une colonne et un paramètre/variable pour rechercher des correspondances basées sur la distinction, comme ceci :
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Le plan est le même que celui illustré précédemment à la figure 3.
Vous pouvez également nier le prédicat pour rechercher les non-correspondances, comme ceci :
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Cette requête génère la sortie suivante :
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10847 2019-02-10 10856 2019-02-10 10871 2019-02-10 10867 2019-02-11 10874 2019-02-11 10870 2019-02-13 10884 2019-02-13 10840 2019-02-16 10887 2019-02-16 ... (825 rows affected)
Alternativement, vous pouvez utiliser un prédicat positif, mais remplacez INTERSECT par EXCEPT, comme ceci :
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
Notez que les plans dans les deux cas peuvent être différents, alors assurez-vous d'expérimenter dans les deux sens avec de grandes quantités de données.
Conclusion
Les valeurs NULL ajoutent leur part de complexité à l'écriture de votre code SQL. Vous voulez toujours penser au potentiel de présence de NULL dans les données, vous assurer que vous utilisez les bonnes constructions de requête et ajouter la logique appropriée à vos solutions pour gérer correctement les NULL. Les ignorer est un moyen sûr de se retrouver avec des bogues dans votre code. Ce mois-ci, je me suis concentré sur ce que sont les valeurs NULL et sur la manière dont elles sont gérées dans les comparaisons impliquant des constantes, des variables, des paramètres et des colonnes. Le mois prochain, je continuerai la couverture en discutant des incohérences de traitement NULL dans différents éléments de langage et des fonctionnalités standard manquantes pour la gestion NULL.