L'un des cas d'utilisation d'index filtrés mentionnés dans la documentation en ligne concerne une colonne qui contient principalement NULLs valeurs. L'idée est de créer un index filtré qui exclut les NULLs , ce qui donne un index non cluster plus petit qui nécessite moins de maintenance que l'index non filtré équivalent. Une autre utilisation courante des index filtrés consiste à filtrer les NULLs d'un UNIQUE index, donnant le comportement que les utilisateurs d'autres moteurs de base de données pourraient attendre d'un UNIQUE par défaut index ou contrainte :l'unicité n'est appliquée que pour le non-NULLs valeurs.
Malheureusement, l'optimiseur de requête a des limites en ce qui concerne les index filtrés. Cet article examine quelques exemples moins connus.
Tableaux d'exemple
Nous allons utiliser deux tables (A &B) qui ont la même structure :une clé primaire clusterisée de substitution, un NULLs principalement colonne qui est unique (indépendamment des NULLs ) et une colonne de remplissage qui représente les autres colonnes pouvant se trouver dans une vraie table.
La colonne d'intérêt est principalement-NULLs un, que j'ai déclaré comme SPARSE . L'option clairsemée n'est pas requise, je l'inclus simplement parce que je n'ai pas beaucoup de chance de l'utiliser. Dans tous les cas, SPARSE est probablement logique dans de nombreux scénarios où les données de la colonne devraient être principalement NULLs . N'hésitez pas à supprimer l'attribut sparse des exemples si vous le souhaitez.
CREATE TABLE dbo.TableA( pk integer IDENTITY PRIMARY KEY, data bigint SPARSE NULL, padding binary(250) NOT NULL DEFAULT 0x); CREATE TABLE dbo.TableB( pk integer IDENTITY PRIMARY KEY, data bigint SPARSE NULL, padding binary(250) NOT NULL DEFAULT 0x);
Chaque tableau contient les nombres de 1 à 2 000 dans la colonne de données avec 40 000 lignes supplémentaires où la colonne de données est NULLs :
-- Nombres 1 - 2,000INSERT dbo.TableA WITH (TABLOCKX) (data)SELECT TOP (2000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL))FROM sys.columns AS cCROSS JOIN sys.columns AS c2ORDER BY ROW_NUMBER() SUR (ORDER PAR (SELECT NULL)); -- NULLsINSERT TOP (40000) dbo.TableA WITH (TABLOCKX) (data)SELECT CONVERT(bigint, NULL)FROM sys.columns AS cCROSS JOIN sys.columns AS c2 ; -- Copier dans TableBINSERT dbo.TableB WITH (TABLOCKX) (data)SELECT ta.dataFROM dbo.TableA AS ta;
Les deux tables obtiennent un UNIQUE index filtré pour les 2 000 non-NULLs valeurs de données :
CREATE UNIQUE NONCLUSTERED INDEX uqAON dbo.TableA (data) WHERE data IS NOT NULL; CREATE INDEX NON CLUSTERE UNIQUE uqBON dbo.TableB (data) WHERE data IS NOT NULL;
La sortie de DBCC SHOW_STATISTICS résume la situation :
DBCC SHOW_STATISTICS (TableA, uqA) AVEC STAT_HEADER ;DBCC SHOW_STATISTICS (TableB, uqB) AVEC STAT_HEADER ;

Exemple de requête
La requête ci-dessous effectue une simple jointure des deux tables - imaginez que les tables sont dans une sorte de relation parent-enfant et que de nombreuses clés étrangères sont NULL. Quelque chose dans ce sens en tout cas.
SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data;
Plan d'exécution par défaut
Avec SQL Server dans sa configuration par défaut, l'optimiseur choisit un plan d'exécution comportant une jointure de boucles imbriquées parallèles :
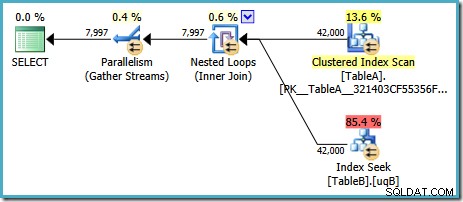
Ce forfait a un coût estimé à 7,7768 unités d'optimisation magiques™.
Il y a cependant des choses étranges à propos de ce plan. La recherche d'index utilise notre index filtré sur la table B, mais la requête est pilotée par un balayage d'index clusterisé de la table A. Le prédicat de jointure est un test d'égalité sur les colonnes de données, qui rejette les NULLs (quel que soit le ANSI_NULLS paramètre). Nous aurions pu espérer que l'optimiseur effectuerait un raisonnement avancé basé sur cette observation, mais non. Ce plan lit chaque ligne de la table A (y compris les 40 000 NULLs ), effectue une recherche dans l'index filtré de la table B pour chacun, en s'appuyant sur le fait que NULLs ne correspondra pas à NULLs dans cette recherche. C'est un énorme gaspillage d'efforts.
La chose étrange est que l'optimiseur doit avoir réalisé que la jointure rejette les NULLs afin de choisir l'index filtré pour la table B seek, mais il n'a pas pensé à filtrer les NULLs du tableau A d'abord - ou mieux encore, de scanner simplement le NULLs -index filtré gratuit sur la table A. Vous vous demandez peut-être s'il s'agit d'une décision basée sur les coûts, peut-être que les statistiques ne sont pas très bonnes ? Peut-être faudrait-il forcer l'utilisation de l'index filtré avec un indice ? L'indication de l'index filtré sur la table A entraîne simplement le même plan avec les rôles inversés :analyser la table B et rechercher dans la table A. Forcer l'index filtré pour les deux tables produit l'erreur 8622 :le processeur de requêtes n'a pas pu produire de plan de requête.
Ajout d'un prédicat NOT NULL
Suspecter que la cause soit quelque chose à voir avec le NULLs implicite -rejet du prédicat de jointure, on ajoute un NOT NULL explicite prédicat au ON clause (ou la clause WHERE clause si vous préférez, ça revient au même ici) :
SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data AND ta.data IS NOT NULL ;
Nous avons ajouté le NOT NULL vérifiez dans la colonne de la table A car le plan d'origine a analysé l'index clusterisé de cette table plutôt que d'utiliser notre index filtré (la recherche dans la table B était correcte - elle utilisait l'index filtré). La nouvelle requête est sémantiquement exactement la même que la précédente, mais le plan d'exécution est différent :
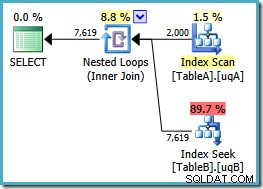
Nous avons maintenant l'analyse espérée de l'index filtré sur la table A, produisant 2 000 non-NULLs lignes pour conduire la boucle imbriquée cherche dans la table B. Les deux tables utilisent nos index filtrés apparemment de manière optimale maintenant :le nouveau plan ne coûte que 0,362835 unités (contre 7,7768). Nous pouvons cependant faire mieux.
Ajout de deux prédicats NOT NULL
Le NOT NULL redondant le prédicat pour la table A a fait des merveilles; que se passe-t-il si nous en ajoutons également un pour le tableau B ?
SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data AND ta.data IS NOT NULL AND tb.data IS NOT NULL ;
Cette requête est toujours logiquement la même que les deux efforts précédents, mais le plan d'exécution est encore différent :
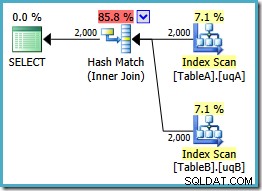
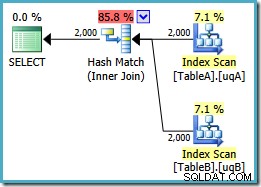
Ce plan construit une table de hachage pour les 2 000 lignes de la table A, puis recherche des correspondances à l'aide des 2 000 lignes de la table B. Le nombre estimé de lignes renvoyées est bien meilleur que le plan précédent (avez-vous remarqué l'estimation de 7 619 ici ?) et le coût d'exécution estimé a de nouveau baissé, passant de 0,362835 à 0,0772056 .
Vous pouvez essayer de forcer une jointure par hachage en utilisant un indice sur le NOT NULL original ou unique requêtes, mais vous n'obtiendrez pas le plan à faible coût indiqué ci-dessus. L'optimiseur n'a tout simplement pas la capacité de raisonner pleinement sur le NULLs -comportement de rejet de la jointure telle qu'elle s'applique à nos index filtrés sans les deux prédicats redondants.
Vous avez le droit d'être surpris par cela - même si c'est juste l'idée qu'un prédicat redondant n'était pas suffisant (sûrement si ta.data est NOT NULL et ta.data = tb.data , il s'ensuit que tb.data est aussi NOT NULL , n'est-ce pas ?)
Toujours pas parfait
C'est un peu surprenant de voir un hachage s'y joindre. Si vous connaissez les principales différences entre les trois opérateurs de jointure physique, vous savez probablement que la jointure par hachage est un excellent candidat où :
- L'entrée pré-triée n'est pas disponible
- L'entrée de construction de hachage est plus petite que l'entrée de sonde
- L'entrée de la sonde est assez grande
Aucune de ces choses n'est vraie ici. Nous nous attendons à ce que le meilleur plan pour cette requête et cet ensemble de données soit une jointure par fusion, exploitant l'entrée ordonnée disponible à partir de nos deux index filtrés. Nous pouvons essayer de suggérer une jointure de fusion, en conservant les deux ON supplémentaires prédicats de clause :
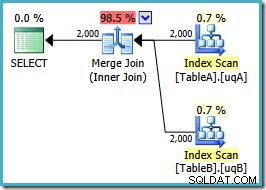
SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data AND ta.data IS NOT NULL AND tb.data IS NOT NULLOPTION (MERGE JOIN);La forme du plan est comme nous l'espérions :
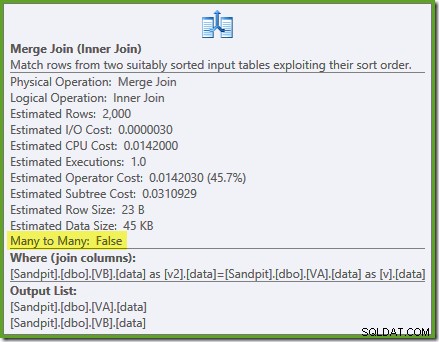
Une analyse ordonnée des deux index filtrés, de bonnes estimations de cardinalité, fantastique. Juste un petit problème :ce plan d'exécution est bien pire; le coût estimé est passé de 0,0772056 à 0,741527 . La raison de la hausse du coût estimé est révélée en vérifiant les propriétés de l'opérateur de jointure par fusion :
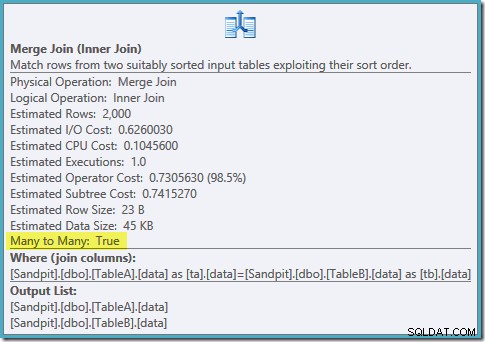
Il s'agit d'une jointure plusieurs à plusieurs coûteuse, où le moteur d'exécution doit garder une trace des doublons à partir de l'entrée externe dans une table de travail et rembobiner si nécessaire. Doublons ? Nous scannons un index unique ! Il s'avère l'optimiseur ne sait pas qu'un index unique filtré produit des valeurs uniques (connecter l'article ici). En fait, il s'agit d'une jointure un-à-un, mais l'optimiseur la facture comme s'il s'agissait d'une jointure plusieurs-à-plusieurs, expliquant pourquoi il préfère le plan de jointure par hachage.
Une stratégie alternative
Il semble que nous rencontrions sans cesse des limitations de l'optimiseur lors de l'utilisation d'index filtrés ici (bien qu'il s'agisse d'un cas d'utilisation mis en évidence dans la documentation en ligne). Que se passe-t-il si nous essayons d'utiliser des vues à la place ?
Utiliser les vues
Les deux vues suivantes filtrent simplement les tables de base pour afficher les lignes où la colonne de données est
NOT NULL:CREATE VIEW dbo.VAWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableWHERE data IS NOT NULL;GOCREATE VIEW dbo.VBWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableBWHERE data IS NOT NULL;Réécrire la requête d'origine pour utiliser les vues est trivial :
SELECT v.data, v2.dataFROM dbo.VA AS vJOIN dbo.VB AS v2 ON v.data =v2.data;Rappelez-vous que cette requête produisait à l'origine un plan de boucles imbriquées parallèles dont le coût était de 7,7768 unités. Avec les références de vue, nous obtenons ce plan d'exécution :
C'est exactement le même plan de jointure de hachage que nous avons dû ajouter redondant
NOT NULLprédicats à obtenir avec les index filtrés (le coût est de 0,0772056 unités comme avant). Ceci est normal, car tout ce que nous avons essentiellement fait ici est de pousser le supplémentNOT NULLprédicats de la requête à une vue.Indexation des vues
On peut aussi essayer de matérialiser les vues en créant un index clusterisé unique sur la colonne pk :
CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.VA (pk);CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.VB (pk);Nous pouvons maintenant ajouter des index uniques non clusterisés sur la colonne de données filtrée dans la vue indexée :
CREATE UNIQUE NONCLUSTERED INDEX ix ON dbo.VA (data);CREATE UNIQUE NONCLUSTERED INDEX ix ON dbo.VB (data);Remarquez que le filtrage est effectué dans la vue, ces index non clusterisés ne sont pas eux-mêmes filtrés.
Le plan parfait
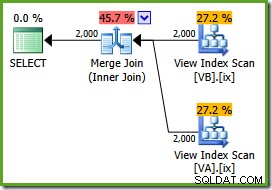
Nous sommes maintenant prêts à exécuter notre requête sur la vue, en utilisant le
NOEXPANDindice de tableau :SELECT v.data, v2.dataFROM dbo.VA AS v WITH (NOEXPAND)JOIN dbo.VB AS v2 WITH (NOEXPAND) ON v.data =v2.data;Le plan d'exécution est :
L'optimiseur peut voir le non filtré les index de vue non clusterisés sont uniques, de sorte qu'une jointure de fusion plusieurs-à-plusieurs n'est pas nécessaire. Ce plan d'exécution final a un coût estimé à 0,0310929 unités - encore plus faible que le plan de jointure par hachage (0,0772056 unités). Cela confirme notre attente selon laquelle une jointure par fusion devrait avoir le coût estimé le plus bas pour cette requête et cet exemple d'ensemble de données.
Le
NOEXPANDdes indications sont nécessaires même dans Enterprise Edition pour s'assurer que la garantie d'unicité fournie par les index de vue est utilisée par l'optimiseur.Résumé
Cet article met en évidence deux limitations importantes de l'optimiseur avec les index filtrés :
- Des prédicats de jointure redondants peuvent être nécessaires pour faire correspondre les index filtrés
- Les index uniques filtrés ne fournissent pas d'informations d'unicité à l'optimiseur
Dans certains cas, il peut être pratique d'ajouter simplement les prédicats redondants à chaque requête. L'alternative est d'encapsuler les prédicats implicites souhaités dans une vue non indexée. Le plan de correspondance de hachage dans cet article était bien meilleur que le plan par défaut, même si l'optimiseur devrait être en mesure de trouver le plan de jointure de fusion légèrement meilleur. Parfois, vous devrez peut-être indexer la vue et utiliser NOEXPAND conseils (requis de toute façon pour les instances de l'édition Standard). Dans d'autres circonstances encore, aucune de ces approches ne conviendra. Désolé pour ça :)