Avez-vous déjà rencontré une situation où vous devez gérer l'état d'une entité qui change au fil du temps ? Il existe de nombreux exemples. Commençons par une tâche simple :fusionner les enregistrements des clients.
Supposons que nous fusionnions des listes de clients provenant de deux sources différentes. Nous pourrions avoir l'un des états suivants :Doublons identifiés – le système a trouvé deux entités potentiellement en double; Doublons confirmés – un utilisateur valide que les deux entités sont bien des doublons; ou Unique confirmé – l'utilisateur décide que les deux entités sont uniques. Dans chacune de ces situations, l'utilisateur n'a qu'une décision oui-non à prendre.
Mais qu'en est-il des situations plus complexes ? Existe-t-il un moyen de définir le flux de travail réel entre les États ? Lisez la suite…
Comment les choses peuvent facilement mal tourner
De nombreuses organisations ont besoin de gérer des demandes d'emploi. Dans un modèle simple, vous pourriez avoir une table appelée JOB_APPLICATION , et vous pouvez suivre l'état de l'application à l'aide d'un tableau de données de référence contenant des valeurs comme celles-ci :
| Statut de la candidature |
|---|
APPLICATION_RECEIVED |
APPLICATION_UNDER_REVIEW |
APPLICATION_REJECTED |
INVITED_TO_INTERVIEW |
INVITATION_DECLINED |
INVITATION_ACCEPTED |
INTERVIEW_PASSED |
INTERVIEW_FAILED |
REFERENCES_SOUGHT |
REFERENCES_ACCEPTABLE |
REFERENCES_UNACCEPTABLE |
JOB_OFFER_MADE |
JOB_OFFER_ACCEPTED |
JOB_OFFER_DECLINED |
APPLICATION_CLOSED |
Ces valeurs peuvent être sélectionnées dans n'importe quel ordre à tout moment. Il s'appuie sur les utilisateurs finaux pour s'assurer qu'une sélection logique et correcte est effectuée à chaque étape. Rien n'interdit une suite illogique d'états.
Par exemple, disons qu'une candidature a été rejetée. Le statut actuel serait évidemment APPLICATION_REJECTED . Rien ne peut être fait au niveau de l'application pour empêcher un utilisateur inexpérimenté de sélectionner ultérieurement INVITED_TO_INTERVIEW ou un autre état illogique.
Ce qu'il faut, c'est quelque chose pour guider l'utilisateur dans la sélection de l'état logique suivant, quelque chose qui définit un flux de travail logique .
Et si vous avez des exigences différentes pour différents types de candidatures ? Par exemple, certains emplois peuvent exiger que le candidat passe un test d'aptitude. Bien sûr, vous pouvez ajouter plus de valeurs à la liste pour les couvrir, mais rien dans la conception actuelle n'empêche l'utilisateur final de faire une sélection incorrecte pour le type d'application en question. La réalité est qu'il existe différents workflows pour différents contextes .
Autre point à considérer :les options répertoriées sont-elles vraiment toutes états ? ? Ou y a-t-il en fait des résultats ? Par exemple, l'offre d'emploi peut être acceptée ou rejetée par le candidat. Par conséquent, JOB_OFFER_MADE a vraiment deux résultats :JOB_OFFER_ACCEPTED et JOB_OFFER_DECLINED .
Un autre résultat pourrait être qu'une offre d'emploi soit retirée. Vous voudrez peut-être enregistrer la raison pour laquelle il a été retiré à l'aide d'un qualificatif. Si vous ajoutez simplement ces raisons à la liste ci-dessus, rien ne guide l'utilisateur final pour faire des sélections logiques.
Donc, vraiment, plus les états, les résultats et les qualificatifs deviennent complexes, plus vous devez définir le flux de travail d'un processus .
Organiser les processus, les états et les résultats
Il est important de comprendre ce qui se passe avec vos données avant d'essayer de les modéliser. Vous pourriez d'abord être enclin à penser qu'il existe ici une hiérarchie stricte des types :
Lorsque nous regardons de plus près l'exemple ci-dessus, nous voyons que le INVITED_TO_INTERVIEW et le JOB_OFFER_MADE les états partagent les mêmes résultats possibles, à savoir ACCEPTED et DECLINED . Cela nous indique qu'il existe une relation plusieurs à plusieurs entre les états et les résultats. Cela est souvent vrai pour d'autres états, résultats et qualificatifs.
Au niveau conceptuel, voici ce qui se passe réellement avec nos métadonnées :
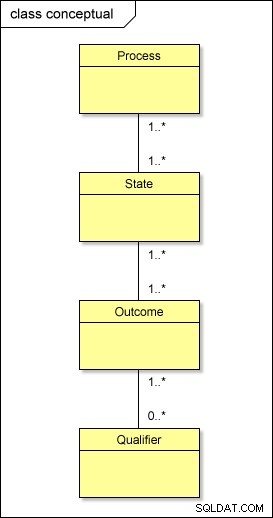
Si vous deviez transformer ce modèle dans le monde physique en utilisant l'approche standard, vous auriez des tables appelées PROCESS , STATE , OUTCOME , et QUALIFIER; vous auriez également besoin d'avoir des tables intermédiaires entre eux – PROCESS_STATE , STATE_OUTCOME , et OUTCOME_QUALIFIER – pour résoudre les relations plusieurs à plusieurs . Cela complique la conception.
Alors que la hiérarchie logique des niveaux (processus → état → résultat → qualificatif) doit être maintenue, il existe un moyen plus simple d'organiser physiquement nos métadonnées.
Le modèle de flux de travail
Le schéma ci-dessous définit les principaux composants d'un modèle de base de données de workflow :
Les tableaux jaunes à gauche contiennent des métadonnées de flux de travail et les tableaux bleus à droite contiennent des données commerciales.
La première chose à souligner est que n'importe quelle entité peut être gérée sans nécessiter de changements majeurs à ce modèle. Le YOUR_ENTITIY_TO_MANAGE table est celle sous la gestion du flux de travail. En termes de notre exemple, ce serait le JOB_APPLICATION table.
Ensuite, nous devons simplement ajouter le wf_state_type_process_id colonne à la table que nous voulons gérer. Cette colonne pointe vers le processus de workflow réel utilisé pour gérer l'entité. Ce n'est pas strictement une colonne de clé étrangère, mais cela nous permet d'interroger rapidement WORKFLOW_STATE_TYPE pour le bon processus. La table qui contiendra l'historique d'état est MANAGED_ENTITY_STATE . Encore une fois, vous choisirez ici votre propre nom de table spécifique et le modifierez selon vos propres besoins.
Les métadonnées
Les différents niveaux de workflow sont définis dans WORKFLOW_LEVEL_TYPE . Ce tableau contient les éléments suivants :
| Clé de saisie | Description |
|---|---|
| PROCESSUS | Processus de workflow de haut niveau. |
| ÉTAT | Un état dans le processus. |
| RÉSULTAT | Comment un état se termine, son résultat. |
| QUALIFICATEUR | Un qualificateur facultatif et plus détaillé pour un résultat. |
WORKFLOW_STATE_TYPE et WORKFLOW_STATE_HIERARCHY former une structure de nomenclature (BOM) classique . Cette structure, qui est très descriptive d'une nomenclature de fabrication réelle, est assez courante dans la modélisation des données. Il peut définir des hiérarchies ou être appliqué à de nombreuses situations récursives. Nous allons l'utiliser ici pour définir notre hiérarchie logique de processus, d'états, de résultats et de qualificatifs facultatifs.
Avant de pouvoir définir une hiérarchie, nous devons définir les composants individuels. Ce sont nos blocs de construction de base. Je vais juste les référencer par TYPE_KEY (qui est unique) par souci de brièveté. Pour notre exemple, nous avons :
| Type de niveau de workflow | Type d'état de workflow.Clé de type |
|---|---|
| RÉSULTAT | RÉUSSI |
| RÉSULTAT | ÉCHEC |
| RÉSULTAT | ACCEPTÉ |
| RÉSULTAT | REFUSE |
| RÉSULTAT | CANDIDATE_CANCELLED |
| RÉSULTAT | EMPLOYER_CANCELLED |
| RÉSULTAT | REFUSE |
| RÉSULTAT | EMPLOYER_WITHDRAWN |
| RÉSULTAT | NO_SHOW |
| RÉSULTAT | EMBAUCHÉ |
| RÉSULTAT | NOT_HIRED |
| ÉTAT | APPLICATION_RECEIVED |
| ÉTAT | APPLICATION_REVIEW |
| ÉTAT | INVITED_TO_INTERVIEW |
| ÉTAT | ENTRETIEN |
| ÉTAT | TEST_APTITUDE |
| ÉTAT | SEEK_REFERENCES |
| ÉTAT | FAIRE_OFFRE |
| ÉTAT | APPLICATION_CLOSED |
| PROCESSUS | STANDARD_JOB_APPLICATION |
| PROCESSUS | APPLICATION_TECHNIQUE_JOB |
Nous pouvons maintenant commencer à définir notre hiérarchie. C'est là que nous prenons nos éléments de base et définissons notre structure. Pour chaque état, nous définissons les résultats possibles. En fait, c'est une règle de ce système de workflow que chaque état doit se terminer avec un résultat :
| Type de parent – ÉTATS | Type d'enfant - RÉSULTATS |
|---|---|
| APPLICATION_RECEIVED | ACCEPTÉ |
| APPLICATION_RECEIVED | REFUSE |
| APPLICATION_REVIEW | RÉUSSI |
| APPLICATION_REVIEW | ÉCHEC |
| INVITED_TO_INTERVIEW | ACCEPTÉ |
| INVITED_TO_INTERVIEW | REFUSE |
| ENTRETIEN | RÉUSSI |
| ENTRETIEN | ÉCHEC |
| ENTRETIEN | CANDIDATE_CANCELLED |
| ENTRETIEN | NO_SHOW |
| FAIRE_OFFRE | ACCEPTÉ |
| FAIRE_OFFRE | REFUSE |
| SEEK_REFERENCES | RÉUSSI |
| SEEK_REFERENCES | ÉCHEC |
| APPLICATION_CLOSED | EMBAUCHÉ |
| APPLICATION_CLOSED | NOT_HIRED |
| TEST_APTITUDE | RÉUSSI |
| TEST_APTITUDE | ÉCHEC |
Nos processus sont simplement un ensemble d'états qui existent chacun pendant une période de temps. Dans le tableau ci-dessous, ils sont présentés dans un ordre logique, mais cela ne définit pas l'ordre réel de traitement.
| Type parent – PROCESSUS | Type d'enfant – ÉTATS |
|---|---|
| STANDARD_JOB_APPLICATION | APPLICATION_RECEIVED |
| STANDARD_JOB_APPLICATION | APPLICATION_REVIEW |
| STANDARD_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| STANDARD_JOB_APPLICATION | ENTRETIEN |
| STANDARD_JOB_APPLICATION | FAIRE_OFFRE |
| STANDARD_JOB_APPLICATION | SEEK_REFERENCES |
| STANDARD_JOB_APPLICATION | APPLICATION_CLOSED |
| APPLICATION_TECHNIQUE_JOB | APPLICATION_RECEIVED |
| APPLICATION_TECHNIQUE_JOB | APPLICATION_REVIEW |
| APPLICATION_TECHNIQUE_JOB | INVITED_TO_INTERVIEW |
| APPLICATION_TECHNIQUE_JOB | TEST_APTITUDE |
| APPLICATION_TECHNIQUE_JOB | ENTRETIEN |
| APPLICATION_TECHNIQUE_JOB | FAIRE_OFFRE |
| APPLICATION_TECHNIQUE_JOB | SEEK_REFERENCES |
| APPLICATION_TECHNIQUE_JOB | APPLICATION_CLOSED |
Il y a un point important à faire concernant une hiérarchie de nomenclature. Tout comme une nomenclature physique définit les assemblages et les sous-assemblages jusqu'aux plus petits composants, nous avons un arrangement similaire dans notre hiérarchie. Cela signifie que nous pouvons réutiliser des "assemblages" et des "sous-assemblages".
A titre d'exemple :à la fois le STANDARD_JOB_APPLICATION et TECHNICAL_JOB_APPLICATION processus avoir l'INTERVIEW état . À son tour, l'INTERVIEW état a le PASSED , FAILED , CANDIDATE_CANCELLED , et NO_SHOW résultats défini pour cela.
Lorsque vous utilisez un état dans un processus, vous obtenez automatiquement ses résultats enfants avec lui, car il s'agit déjà d'un assembly. Cela signifie que les mêmes résultats existent pour les deux types de candidatures à l'INTERVIEW organiser. Si vous souhaitez des résultats d'entretien différents pour différents types de candidatures, vous devez définir, par exemple, TECHNICAL_INTERVIEW et STANDARD_INTERVIEW déclare que chacun a ses propres résultats spécifiques.
Dans cet exemple, la seule différence entre les deux types de candidatures est qu'une candidature technique comprend un test d'aptitude.
Avant de partir
La partie 1 de cet article en deux parties a présenté le modèle de base de données de workflow. Il a montré comment vous pouvez l'intégrer pour gérer le cycle de vie de n'importe quelle entité dans votre base de données.
La partie 2 vous montrera comment définir le flux de travail réel à l'aide de tables de configuration supplémentaires. C'est là que l'utilisateur sera présenté avec les prochaines étapes autorisées. Nous démontrerons également une technique permettant de contourner la réutilisation stricte des "assemblages" et des "sous-assemblages" dans les nomenclatures.