Les index sont des boosters de vitesse dans les bases de données SQL. Ils peuvent être groupés ou non groupés. Mais qu'est-ce que cela signifie et où devez-vous les appliquer ?
Je connais cette sensation. J'ai été là. Les débutants ne savent souvent pas quel index utiliser sur quelles colonnes. Cependant, même les experts doivent réfléchir à cette question avant de prendre une décision, et des situations différentes nécessitent des décisions différentes. Comme vous le verrez plus tard, il existe des requêtes où un index clusterisé brillera par rapport à un index non clusterisé, et vice-versa.
Pourtant, d'abord, nous devons connaître chacun d'eux. Si vous recherchez les mêmes informations, aujourd'hui est votre jour de chance.
Cet article vous expliquera ce que sont ces index et quand les utiliser. Bien sûr, il y aura des exemples de code que vous pourrez essayer dans la pratique. Alors, prenez vos frites ou votre pizza et un soda ou un café, et préparez-vous à vous immerger dans ce voyage instructif.
Prêt ?
Qu'est-ce qu'un index clusterisé
Un index clusterisé est un index qui définit l'ordre de tri physique des lignes dans une table ou une vue.
Pour voir cela sous sa forme réelle, prenons l'Employé tableau dans AdventureWorks2017 base de données.
La clé primaire est également un index clusterisé et la clé est basée sur BusinessEntityID colonne. Lorsque vous faites un SELECT sur cette table sans ORDER BY, vous verrez qu'elle est triée par la clé primaire.
Essayez-le vous-même en utilisant le code ci-dessous :
USE AdventureWorks2017
GO
SELECT TOP 10 * FROM HumanResources.Employee
GO
Maintenant, voyez le résultat dans la figure 1 :
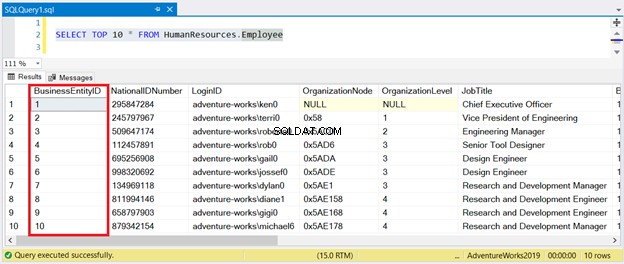
Comme vous pouvez le voir, vous n'avez pas besoin de trier le jeu de résultats avec BusinessEntityID . L'index clusterisé s'en charge.
Contrairement aux index non clusterisés, vous ne pouvez avoir qu'un seul index clusterisé par table. Et si on essayait ça sur Employee tableau ?
CREATE CLUSTERED INDEX IX_Employee_NationalID
ON HumanResources.Employee (NationalIDNumber)
GO
Nous avons une erreur similaire ci-dessous :
Msg 1902, Level 16, State 3, Line 4
Cannot create more than one clustered index on table 'HumanResources.Employee'. Drop the existing clustered index 'PK_Employee_BusinessEntityID' before creating another.
Quand utiliser un index cluster ?
Une colonne est le meilleur candidat pour un index clusterisé si l'une des conditions suivantes est vraie :
- Il est utilisé dans un grand nombre de requêtes dans la clause WHERE et les jointures.
- Il sera utilisé comme clé étrangère vers une autre table et, en fin de compte, pour les jointures.
- Valeurs de colonne uniques.
- La valeur sera moins susceptible de changer.
- Cette colonne est utilisée pour interroger une plage de valeurs. Des opérateurs tels que>, <,>=, <=ou BETWEEN sont utilisés avec la colonne dans la clause WHERE.
Mais les index clusterisés ne sont pas bons si la colonne ou les colonnes
- modifier fréquemment
- sont des clés larges ou une combinaison de colonnes avec une grande taille de clé.
Exemples
Les index clusterisés peuvent être créés à l'aide du code T-SQL ou de tout outil d'interface graphique SQL Server. Vous pouvez le faire dans T-SQL lors de la création de la table, comme ceci :
CREATE TABLE [Person].[Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)
GO
Ou, vous pouvez le faire en utilisant ALTER TABLE après création de la table sans index cluster :
ALTER TABLE Person.Person ADD CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED (BusinessEntityID)
GO
Une autre méthode consiste à utiliser CREATE CLUSTERED INDEX :
CREATE CLUSTERED INDEX [PK_Person_BusinessEntityID] ON Person.Person (BusinessEntityID)
GO
Une autre alternative consiste à utiliser un outil SQL Server comme SQL Server Management Studio ou dbForge Studio pour SQL Server.
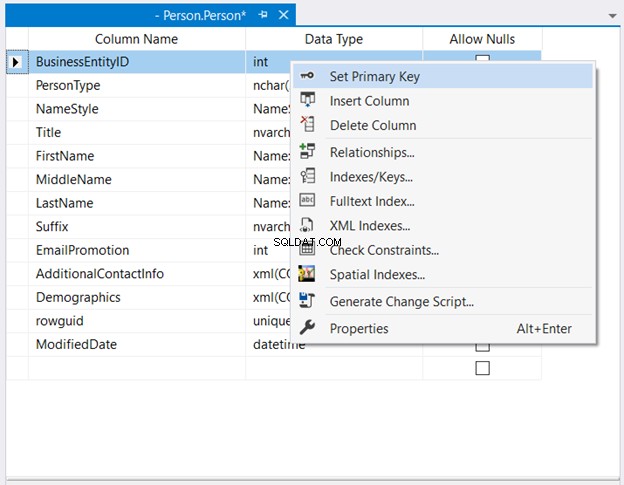
Dans Explorateur d'objets , développez les nœuds de la base de données et de la table. Ensuite, faites un clic droit sur le tableau souhaité et sélectionnez Design . Enfin, faites un clic droit sur la colonne que vous voulez utiliser comme clé primaire> Définir la clé primaire> Enregistrez les modifications apportées au tableau.
La figure 2 ci-dessous montre où BusinessEntityID est définie comme clé primaire.
Outre la création d'un index clusterisé à une seule colonne, vous pouvez utiliser plusieurs colonnes. Voir un exemple en T-SQL :
CREATE CLUSTERED INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC
)
GO
Après avoir créé cet index clusterisé, la personne le tableau sera physiquement trié par Nom de famille , Prénom , et Deuxième prénom .
L'un des avantages de cette approche est l'amélioration des performances des requêtes basées sur le nom. De plus, il trie les résultats par nom sans spécifier ORDER BY. Mais notez que si le nom change, le tableau devra être réorganisé. Bien que cela ne se produise pas tous les jours, l'impact peut être énorme si la table est très grande.
Qu'est-ce qu'un index non clusterisé
Un index non clusterisé est un index avec une clé et un pointeur vers les lignes ou les clés d'index clusterisé. Cet index peut s'appliquer à la fois aux tables et aux vues.
Contrairement aux index clusterisés, ici la structure est séparée de la table. Puisqu'il est séparé, il a besoin d'un pointeur vers les lignes du tableau, également appelé localisateur de lignes. Ainsi, chaque entrée d'un index non clusterisé contient un localisateur et une valeur de clé.
Les index non clusterisés ne trient pas physiquement la table en fonction de la clé.
Les clés d'index pour les index non clusterisés ont une taille maximale de 1700 octets. Vous pouvez contourner cette limite en ajoutant des colonnes incluses. Cette méthode est utile si votre requête doit couvrir plus de colonnes sans augmenter la taille de la clé.
Vous pouvez également créer des index filtrés non clusterisés. Cela réduira les coûts de maintenance et de stockage de l'index tout en améliorant les performances des requêtes.
Quand utiliser un index non cluster ?
Une ou plusieurs colonnes sont de bons candidats pour les index non clusterisés si les conditions suivantes sont remplies :
- La ou les colonnes sont utilisées dans une clause WHERE ou une jointure.
- La requête ne renverra pas un ensemble de résultats volumineux.
- La correspondance exacte dans la clause WHERE utilisant l'opérateur d'égalité est nécessaire.
Exemples
Cette commande créera un index unique et non clusterisé dans Employee tableau :
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON [HumanResources].[Employee]
(
[NationalIDNumber] ASC
)
GO
Outre une table, vous pouvez créer un index non clusterisé pour une vue :
CREATE NONCLUSTERED INDEX [IDX_vProductAndDescription_ProductModel] ON [Production].[vProductAndDescription]
(
[ProductModel] ASC
)
GO
Autres questions courantes et réponses satisfaisantes
Quelles sont les différences entre l'index clusterisé et non clusterisé ?
D'après ce que vous avez vu précédemment, vous pouvez déjà vous faire une idée de la différence entre les index clusterisés et non clusterisés. Mais mettons-le sur une table pour une référence facile.
| Informations | Index clusterisé | Index non clusterisé |
| S'applique à | Tableaux et vues | Tableaux et vues |
| Autorisé par table | 1 | 999 |
| Taille de la clé | 900 octets | 1700 octets |
| Colonnes par clé d'index | 32 | 32 |
| Bon pour | Requêtes de plage (>,<,>=, <=, BETWEEN) | Correspondances exactes (=) |
| Colonnes incluses non clés | Non autorisé | Autorisé |
| Filtrer avec condition | Non autorisé | Autorisé |
Les clés primaires doivent-elles être indexées en cluster ou non ?
Une clé primaire est une contrainte. Une fois que vous faites d'une colonne une clé primaire, un index clusterisé est automatiquement créé à partir de celle-ci, à moins qu'un index clusterisé existant ne soit déjà en place.
Ne confondez pas une clé primaire avec un index cluster ! Une clé primaire peut également être la clé d'index clusterisé. Mais une clé d'index clusterisé peut être une autre colonne autre que la clé primaire.
Prenons un autre exemple. Dans la Personne tableau de AdventureWorks201 7, nous avons le BusinessEntityID clé primaire. Il s'agit également de la clé d'index clusterisé. Vous pouvez supprimer cet index clusterisé. Ensuite, créez un index clusterisé basé sur Lastname , Prénom , et Deuxième prénom . La clé primaire est toujours le BusinessEntityID colonne.
Mais vos clés primaires doivent-elles toujours être mises en cluster ?
Ça dépend. Revoyez la question sur quand utiliser un index clusterisé.
Si une ou plusieurs colonnes apparaissent dans votre clause WHERE dans de nombreuses requêtes, il s'agit d'un candidat pour un index clusterisé. Mais une autre considération est la largeur de la clé d'index clusterisée. Trop large - et la taille de chaque index non clusterisé augmentera s'ils existent. N'oubliez pas que les index non clusterisés utilisent également la clé d'index clusterisé comme pointeur. Alors, gardez votre clé d'index cluster aussi étroite que possible.
Si un grand nombre de requêtes utilisent la clé primaire dans la clause WHERE, laissez-la également comme clé d'index clusterisé. Sinon, créez votre clé primaire en tant qu'index non clusterisé.
Mais que faire si vous n'êtes toujours pas sûr? Ensuite, vous pouvez évaluer l'avantage des performances d'une colonne lorsqu'elle est en cluster ou non en cluster. Alors, connectez-vous à la section suivante à ce sujet.
Lequel est le plus rapide :index clusterisé ou non clusterisé ?
Bonne question. Il n'y a pas de règle générale. Vous devez vérifier les lectures logiques et le plan d'exécution de vos requêtes.
Notre courte expérience inclura des copies des tableaux suivants de AdventureWorks2017 base de données :
- Personne
- BusinessEntityAddress
- Adresse
- Type d'adresse
Voici le script :
IF NOT EXISTS(SELECT name FROM sys.databases WHERE name = 'TestDatabase')
BEGIN
CREATE DATABASE TestDatabase
END
USE TestDatabase
GO
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkClustered FROM AdventureWorks2017.Person.Person
ALTER TABLE Person_pkClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID2] PRIMARY KEY CLUSTERED (BusinessEntityID)
CREATE NONCLUSTERED INDEX [IX_Person_Name2] ON Person_pkClustered (LastName, FirstName, MiddleName, Suffix)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkNonClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkNonClustered FROM AdventureWorks2017.Person.Person
CREATE CLUSTERED INDEX [IX_Person_Name1] ON Person_pkNonClustered (LastName, FirstName, MiddleName, Suffix)
ALTER TABLE Person_pkNonClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID1] PRIMARY KEY NONCLUSTERED (BusinessEntityID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'AddressType')
BEGIN
SELECT * INTO AddressType FROM AdventureWorks2017.Person.AddressType
ALTER TABLE AddressType
ADD CONSTRAINT [PK_AddressType] PRIMARY KEY CLUSTERED (AddressTypeID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Address')
BEGIN
SELECT * INTO Address FROM AdventureWorks2017.Person.Address
ALTER TABLE Address
ADD CONSTRAINT [PK_Address] PRIMARY KEY CLUSTERED (AddressID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'BusinessEntityAddress')
BEGIN
SELECT * INTO BusinessEntityAddress FROM AdventureWorks2017.Person.BusinessEntityAddress
ALTER TABLE BusinessEntityAddress
ADD CONSTRAINT [PK_BusinessEntityAddress] PRIMARY KEY CLUSTERED (BusinessEntityID, AddressID, AddressTypeID)
END
GO
En utilisant la structure ci-dessus, nous comparerons les vitesses de requête pour les index clusterisés et non clusterisés.
Nous avons 2 copies de la Personne table. Le premier utilisera BusinessEntityID comme clé d'index primaire et clusterisée. Le second utilise toujours BusinessEntityID comme clé primaire. L'index clusterisé est basé sur Lastname , Prénom , Deuxième prénom , et Suffixe .
Commençons.
RECHERCHEZ LES CORRESPONDANCES EXACTES EN FONCTION DU NOM DE FAMILLE
Commençons par une requête simple. En outre, vous devez activer STATISTICS IO. Ensuite, nous collons les résultats dans statisticsparser.com pour une présentation tabulaire.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, p.Title
FROM Person_pkClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SET STATISTICS IO OFF
GO
L'attente est que le premier SELECT sera plus lent car la clause WHERE ne correspond pas à la clé d'index cluster. Mais vérifions les lectures logiques.
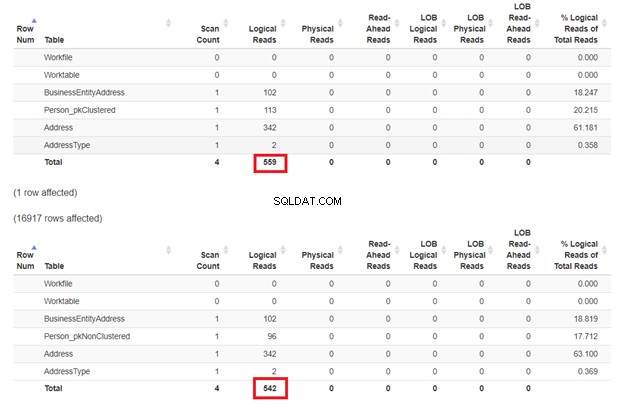
Comme prévu dans la figure 3, Person_pkClustered avait des lectures plus logiques. Par conséquent, la requête nécessite plus d'E/S. La raison? Le tableau est trié par BusinessEntityID . Pourtant, la deuxième table a l'index clusterisé basé sur le nom. Puisque la requête veut un résultat basé sur le nom, Person_pkNonClustered gagne. Moins les lectures sont logiques, plus la requête est rapide.
Que se passe-t-il d'autre ? Consultez la figure 4.
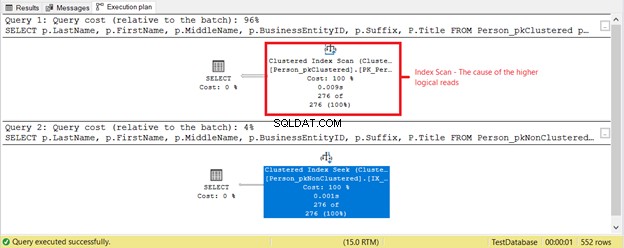
Quelque chose d'autre s'est produit sur la base du plan d'exécution de la figure 4. Pourquoi une analyse d'index clusterisée se trouve-t-elle dans le premier SELECT au lieu d'une recherche d'index ? Le coupable est le Titre colonne dans le SELECT. Il n'est couvert par aucun des index existants. L'optimiseur SQL Server a estimé qu'il était plus rapide d'utiliser l'index clusterisé basé sur BusinessEntityID. Ensuite, SQL Server l'a scanné pour trouver les bons noms de famille et a obtenu le prénom, le deuxième prénom et le titre.
Supprimer le Titre colonne, et l'opérateur utilisé sera Index Seek . Pourquoi? Parce que le reste des champs est couvert par l'index non clusterisé basé sur Nom , Prénom , Deuxième prénom , et Suffixe . Il inclut également BusinessEntityID comme localisateur de clé d'index clusterisé.
REQUETE DE PLAGE BASÉE SUR L'ID D'ENTITÉ COMMERCIALE
Les index clusterisés peuvent être utiles pour les requêtes de plage. Est-ce toujours le cas ? Découvrons-le en utilisant le code ci-dessous.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SET STATISTICS IO OFF
GO
La liste a besoin de lignes basées sur une plage de BusinessEntityIDs de 285 à 290. Encore une fois, les index clusterisés et non clusterisés des 2 tables sont intacts. Passons maintenant aux lectures logiques de la figure 5. Le gagnant attendu est Person_pkClustered car la clé primaire est également la clé d'index cluster.

Voyez-vous des lectures logiques inférieures sur Person_pkClustered ? Les index clusterisés ont fait leurs preuves sur les requêtes de plage dans ce scénario. Voyons ce que le plan d'exécution révélera de plus dans la figure 6.
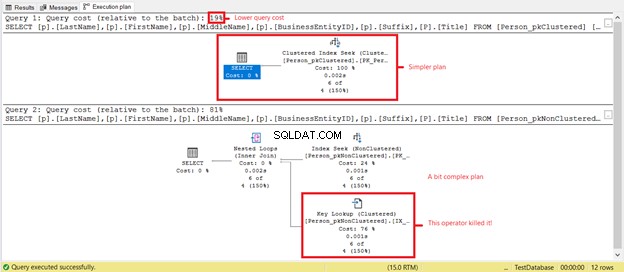
Le premier SELECT a un plan plus simple et un coût de requête inférieur basé sur la figure 7. Cela prend également en charge des lectures logiques inférieures. Pendant ce temps, le deuxième SELECT a un opérateur Key Lookup qui ralentit la requête. Le coupable? Encore une fois, c'est le Titre colonne. Supprimez la colonne dans la requête ou ajoutez-la en tant que colonne incluse dans l'index non clusterisé. Ensuite, vous aurez un meilleur plan et des lectures logiques plus faibles.
CHERCHEZ DES CORRESPONDANCES EXACTES AVEC UNE JOINTURE
De nombreuses instructions SELECT incluent des jointures. Faisons quelques tests. Ici, nous commençons avec des correspondances exactes :
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SET STATISTICS IO OFF
GO
Nous nous attendons à ce que le deuxième SELECT de Person_pkNonClustered avec un index clusterisé sur le nom aura moins de lectures logiques. Mais est-ce? Voir Figure 7.
On dirait que l'index non clusterisé sur le nom a très bien fonctionné. Les lectures logiques sont les mêmes. Si vous vérifiez le plan d'exécution, la différence dans les opérateurs est la recherche d'index clusterisée sur Person_pkNonClustered , et la recherche d'index sur Person_pkClustered .
Nous devons donc vérifier les lectures logiques et le plan d'exécution pour en être sûrs.
REQUETE DE PLAGE AVEC JOINS
Puisque nos attentes peuvent être différentes de la réalité, essayons avec des requêtes de plage. Les index clusterisés sont généralement bons avec cela. Mais que se passe-t-il si vous incluez une jointure ?
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SET STATISTICS IO OFF
GO
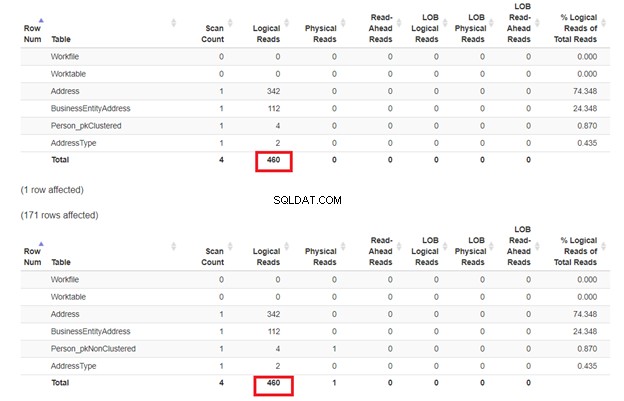
Maintenant, inspectez les lectures logiques de ces 2 requêtes dans la figure 8 :
Ce qui s'est passé? Dans la figure 9, la réalité mord à Person_pkClustered . Plus de coûts d'E/S y ont été observés par rapport à Person_pkNonClustered . C'est différent de ce que nous attendons. Mais sur la base de cette réponse du forum, une recherche d'index non clusterisé peut être plus rapide qu'une recherche d'index clusterisé lorsque toutes les colonnes de la requête sont couvertes à 100% dans l'index. Dans notre cas, la requête pour Person_pkNonClustered couvert les colonnes à l'aide de l'index non clusterisé (BusinessEntityID - clé; Nom de famille , Prénom , Deuxième prénom , Suffixe – pointeur vers la clé d'index cluster).
INSÉRER LES PERFORMANCES
Ensuite, essayez de tester les performances d'INSERT sur les mêmes tables.
SET STATISTICS IO ON
GO
INSERT INTO Person_pkClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
INSERT INTO Person_pkNonClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
SET STATISTICS IO OFF
GO
La figure 9 montre les lectures logiques INSERT :

Les deux ont généré les mêmes E/S. Ainsi, les deux ont fait la même chose.
SUPPRIMER UNE PERFORMANCE
Notre dernier test implique DELETE :
SET STATISTICS IO ON
GO
DELETE FROM Person_pkClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
DELETE FROM Person_pkNonClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
SET STATISTICS IO OFF
GO
La figure 10 montre les lectures logiques. Notez la différence.

Pourquoi avons-nous des lectures logiques plus élevées sur Person_pkClustered ? Le fait est que la condition de l'instruction DELETE est basée sur une correspondance exacte d'un nom. L'optimiseur devra d'abord recourir à l'index non clusterisé. Cela signifie plus d'E/S. Confirmons en utilisant le plan d'exécution de la figure 11.
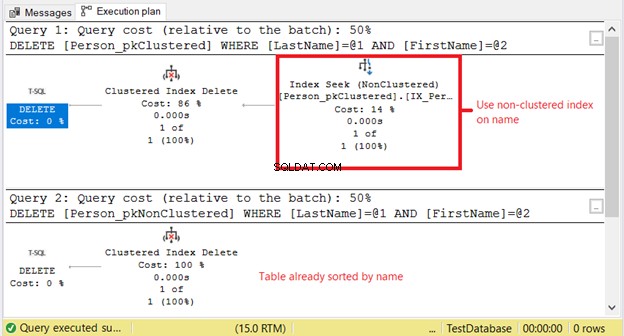
Le premier SELECT nécessite une recherche d'index sur l'index non clusterisé. La raison est la clause WHERE sur Lastname et Prénom . Pendant ce temps, Person_pkNonClustered est déjà physiquement trié par nom en raison de l'index clusterisé.
À emporter
Former des requêtes performantes n'est pas une question de chance. Vous ne pouvez pas simplement mettre un index clusterisé et un index non clusterisé et puis soudainement, vos requêtes ont la force de vitesse. Vous devez continuer à utiliser les outils comme objectif pour vous concentrer sur les petits détails autres que l'ensemble de résultats.
Mais parfois, vous n'avez tout simplement pas le temps de faire tout cela. Je pense que c'est normal. Mais tant que vous ne vous trompez pas trop, vous avez votre travail le lendemain et vous pouvez vous en sortir. Ce ne sera pas facile au début. Ce sera en fait déroutant. Vous aurez aussi beaucoup de questions. Mais avec une pratique constante, vous pouvez y parvenir. Alors, gardez la tête haute.
N'oubliez pas que les index clusterisés et non clusterisés servent à booster les requêtes. Connaître les principales différences, les scénarios d'utilisation et les outils vous aidera dans votre quête de codage de requêtes hautes performances.
J'espère que cet article répond à vos questions les plus pressantes sur les index clusterisés et non clusterisés. Avez-vous autre chose à ajouter pour nos lecteurs ? La section Commentaires est ouverte.
Et si vous trouvez cet article instructif, partagez-le sur vos plateformes de médias sociaux préférées.
Vous trouverez plus d'informations sur les index et les performances des requêtes dans les articles ci-dessous :
- 22 exemples astucieux d'index SQL pour accélérer vos requêtes
- Optimisation des requêtes SQL :5 faits essentiels pour optimiser vos requêtes



